L'analyse de texte commence toujours par une analyse lexicale ou une tokenisation. Il existe un moyen simple de résoudre ce problème pour presque toutes les langues à l'aide d'expressions régulières. Une autre utilisation du bon vieux regexp.
Je rencontre souvent la tâche d'analyser des textes. Pour les tâches simples, telles que l'analyse d'une valeur entrée par l'utilisateur, la fonctionnalité d'expression régulière de base est suffisante. Pour les tâches complexes et lourdes comme l'écriture d'un compilateur ou l'analyse de code statique, vous pouvez utiliser des outils spécialisés (AntLR, JavaCC, Yacc). Mais je rencontre souvent des tâches de niveau intermédiaire, quand il n'y a pas assez d'expressions régulières, mais je n'ai pas envie de tirer des outils lourds dans le projet. De plus, ces outils fonctionnent généralement au stade de la compilation et au moment de l'exécution ne permettent pas de modifier les paramètres d'analyse (par exemple, former une liste de mots clés à partir d'un fichier ou d'une table de base de données).
À titre d'exemple, je vais vous donner une tâche qui a surgi au cours du processus d' accélération des requêtes SQL . Nous avons analysé les journaux de nos requêtes SQL et avons voulu trouver de "mauvaises" requêtes selon certaines règles. Par exemple, les requêtes dans lesquelles le même champ est vérifié pour un ensemble de valeurs à l'aide de OU
name = 'John' OR name = 'Michael' OR name = 'Bob'
Nous voulions remplacer ces demandes par
name IN ('John', 'Michael', 'Bob')
Les expressions régulières ne peuvent plus faire face, mais je ne voulais pas non plus créer un analyseur SQL à part entière à l'aide d'AntLR. Il serait possible de diviser le texte de la demande en jetons et d'utiliser du code simple pour effectuer une analyse sans aucun outil spécialisé.
Ce problème peut être résolu en utilisant la fonctionnalité de base des expressions régulières. Essayons de diviser la requête SQL en jetons. Nous allons examiner une version simplifiée de SQL afin de ne pas surcharger le texte avec des détails. Pour créer un lexer SQL à part entière, vous devrez écrire des expressions régulières légèrement plus complexes.
Voici un ensemble d'expressions pour les jetons de langage SQL de base:
1. keyword : \b(?:select|from|where|group|by|order|or|and|not|exists|having|join|left|right|inner)\b 2. id : [A-Za-z][A-Za-z0-9]* 3. real_number : [0-9]+\.[0-9]* 4. number : [0-9]+ 5. string : '[^']*' 6. space : \s+ 7. comment : \-\-[^\n\r]* 8. operation : [+\-\*/.=\(\)]
Je veux faire attention à l'expression régulière du mot clé
keyword : \b(?:select|from|where|group|by|order|or|and|not|exists|having|join|left|right|inner)\b
Il a deux caractéristiques.
- L'opérateur \ b est utilisé au début et à la fin, par exemple, pour ne pas couper le préfixe or du mot organisation , qui est un mot-clé et que certains moteurs d'expression régulière sépareront en un jeton séparé sans utiliser l'opérateur \ b.
- tous les mots sont regroupés par des crochets non capturants (? :) qui ne capturent pas la correspondance. Cela sera utilisé à l'avenir afin de ne pas violer l'indexation des expressions régulières partielles dans l'expression générale.
Vous pouvez maintenant combiner toutes ces expressions en un seul ensemble, en utilisant le regroupement et l'opérateur |
(\b(?:select|from|where|group|by|order|or|and|not|exists|having|join|left|right|inner)\b)|([A-Za-z][A-Za-z0-9]*)|([0-9]+\.[0-9]*)|([0-9]+)|('[^']*')|(\s+)|(\-\-[^\n\r]*)|([+\-\*/.=\(\)])
Vous pouvez maintenant essayer d'appliquer cette expression à une expression SQL, par exemple à
SELECT count(id)
Voici le résultat sur le testeur Regex. En cliquant sur le lien, vous pouvez jouer avec l'expression et le résultat de l'analyse. On peut voir que, par exemple, SELECT correspond immédiatement à un groupe 1, ce qui correspond au type de mot clé .
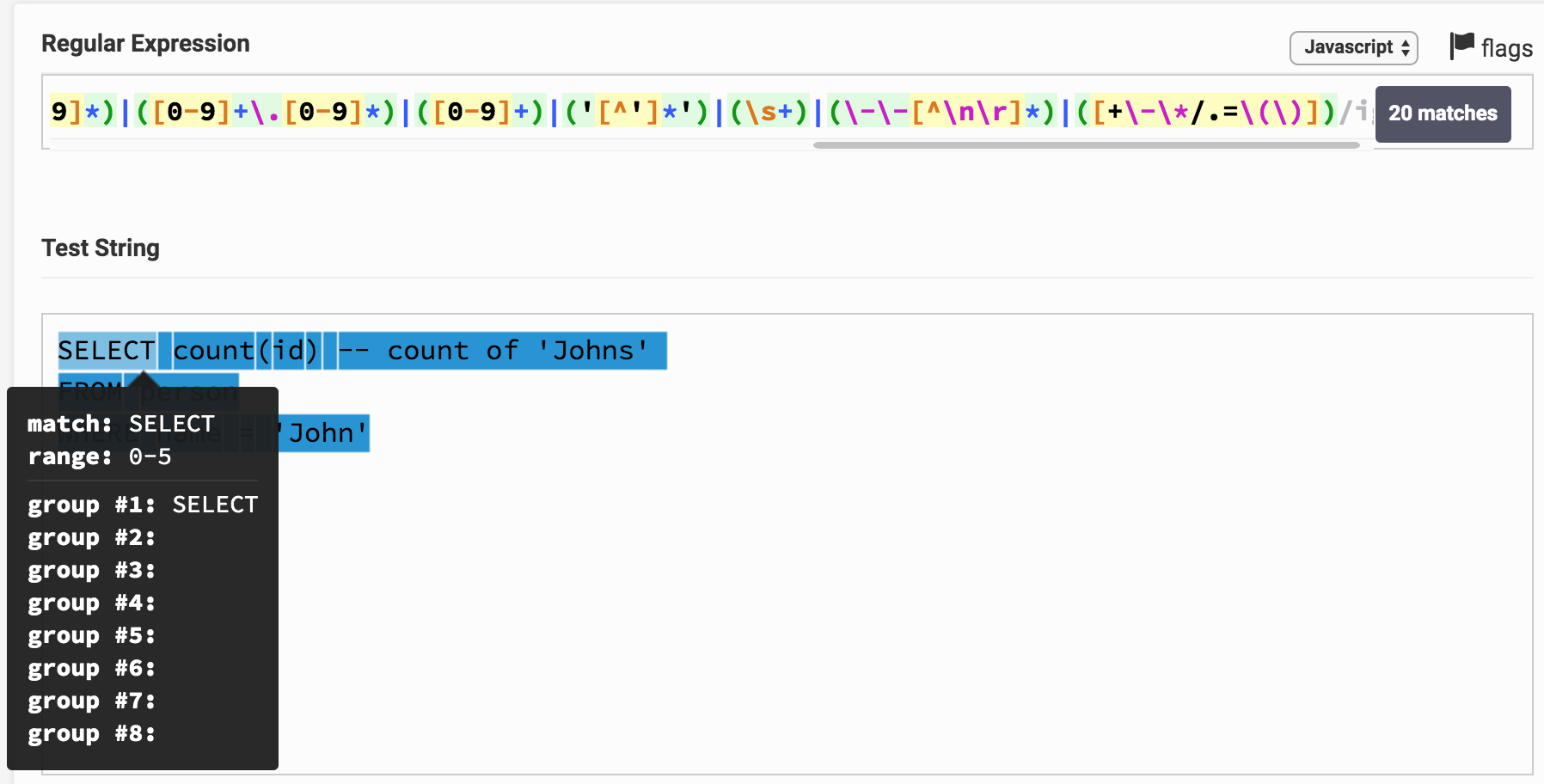
Vous pouvez remarquer que le texte entier de la demande s'est avéré être divisé en sous-chaînes et chacune correspond à un certain groupe. Par le numéro de groupe, vous pouvez le corréler avec le type de jeton (token).
Transformer l'algorithme donné en programme dans n'importe quel langage de programmation qui prend en charge les expressions régulières n'est pas difficile. Voici une petite classe qui implémente cela en Java.
RegexTokenizer.java (+ quelques autres classes) package org.example; import java.util.ArrayList; import java.util.Enumeration; import java.util.List; import java.util.regex.Matcher; import java.util.regex.Pattern; import java.util.stream.Collectors; public class RegexTokenizer implements Enumeration<Token> {
Dans cette classe, l'algorithme est implémenté à l'aide de groupes nommés, qui ne sont pas présents dans tous les moteurs. Cette fonctionnalité vous permet d'accéder aux groupes non pas par index, mais par nom, ce qui est un peu plus pratique que d'accéder par index.
Sur mon I7 2,3 GHz, cette classe démontre une vitesse d'analyse de 5 à 20 Mo par seconde (selon la complexité des expressions). L'algorithme peut être parallélisé en analysant plusieurs fichiers à la fois, ce qui augmente la vitesse globale de travail.
J'ai trouvé plusieurs algorithmes similaires sur le réseau, mais je suis tombé sur des options qui ne forment pas une expression régulière commune, mais appliquent systématiquement des expressions régulières pour chaque type de jeton au début de la ligne, puis jetez le jeton trouvé depuis le début de la ligne et essayez à nouveau d'appliquer toutes les expressions régulières. Cela fonctionne environ 10 à 20 fois plus lentement, nécessite plus de mémoire et l'algorithme est plus compliqué. J'ai atteint une plus grande vitesse de travail uniquement en utilisant mon implémentation d'expressions régulières basée sur DFA (machine à états finis déterministes ). Dans les moteurs regex, NKA est généralement utilisé - une machine à états finis non déterministe ). DFA est 2 à 3 fois plus rapide, mais les expressions régulières sont plus difficiles à écrire en raison d'un ensemble limité d'opérateurs.
Dans mon exemple pour SQL, j'ai un peu simplifié les expressions régulières et le tokenizer résultant ne peut pas être considéré comme un analyseur lexical à part entière des requêtes SQL, mais le but de l'article est de montrer le principe, et non de créer un véritable tokenizer SQL. J'ai utilisé cette approche dans ma pratique et créé des analyseurs lexicaux à part entière pour SQL, Java, C, XML, HTML, JSON, Pascal et même COBOL (j'ai dû le bricoler).
Voici quelques règles simples pour écrire des expressions régulières pour l'analyse lexicale.
- Si le même jeton peut être attribué à différents types (par exemple, n'importe quel mot clé peut être reconnu comme identifiant), un type plus étroit doit être défini au début. Ensuite, l'expression régulière sera appliquée en premier et déterminera le type de jeton. Par exemple, dans mon exemple, les mots clés sont définis avant id et le jeton de sélection sera reconnu comme mot clé , pas id
- Définissez d'abord des jetons plus longs, puis des jetons plus courts. Par exemple, vous devez d'abord définir <= , > = puis séparer > , < , = Dans ce cas, le texte <= sera correctement reconnu comme un seul jeton de l'opérateur inférieur ou égal, et non pas deux jetons distincts < et =
- Apprenez à utiliser l' anticipation et l' antériorité . Par exemple, le caractère * dans SQL a la signification d'un opérateur de multiplication et une indication de tous les champs d'une table. Vous pouvez séparer ces deux cas avec un simple lookbehind , par exemple, ici regexp (? <=. \ S | select \ s ) * trouve le caractère * uniquement dans la valeur "tous les champs du tableau".
- Il est parfois utile de définir des expressions régulières pour les erreurs qui se produisent dans le texte. Par exemple, si vous effectuez une mise en évidence de la syntaxe, vous pouvez définir le type du jeton de chaîne inachevé comme
'[^\n\r]* . Dans le processus de modification du texte, l'utilisateur peut ne pas avoir le temps de fermer le guillemet dans la chaîne, mais votre tokenizer pourra reconnaître correctement cette situation et la mettre en surbrillance correctement.
En utilisant ces règles et en appliquant cet algorithme, vous pouvez rapidement diviser le texte en jetons pour presque toutes les langues.