Nous aimons et utilisons tous les fonctionnalités étonnantes du groupe de disponibilité sur les répliques secondaires, telles que les contrôles d'intégrité, les sauvegardes, etc.
En fait, l'impossibilité d'enregistrer ces informations dans une base de données sur une réplique est toujours un casse-tête (et pensez à des choses comme CDC pour encore plus d'inconfort).
Mais arrêtez de vous plaindre, voici l'idée principale: cher Microsoft, utilisons nos indices pour mettre à jour les statistiques ... eh bien, faisons-en beaucoup plus.
Il y a toujours * un moyen, ou quelque chose comme ça
* presque toujoursÉnumérons les détails de base connus d'une solution possible sur Enterprise Edition MS SQL Server:
- nous pouvons rendre les répliques lisibles et en lire les données (pas que vous deviez toujours le faire, mais si vous savez vraiment ce que vous faites ...);
- nous pouvons copier nos objets dans Tempdb (oui, vos tables multi-téraoctets ne sont probablement pas très adaptées à une telle opération), ou dans une autre base de données accessible en écriture;
- nous pouvons écrire les résultats dans un dossier partagé accessible aux deux répliques (que ce soit un fichier texte dans un partage de fichiers);
- nous pouvons exporter des statistiques sous forme de blob depuis SQL Server;
- nous pouvons importer le blob téléchargé dans les statistiques.
Faisons-le
J'ai un test AG sur une paire de machines virtuelles avec SQL Server 2017 (vous pouvez utiliser n'importe quelle version) et je vais créer un tableau simple dans lequel je souhaite mettre à jour les statistiques.
Voici un script pour créer une table et y insérer un million de lignes:
DROP TABLE IF EXISTS dbo.SampleDataTable; CREATE TABLE dbo.SampleDataTable ( C1 BIGINT NOT NULL, C2 BIGINT NOT NULL, CONSTRAINT PK_SampleDataTable PRIMARY KEY (C1) ); INSERT INTO dbo.SampleDataTable WITH (TABLOCK) SELECT t.RN, t.RN FROM ( SELECT TOP (1000000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) RN FROM sys.objects t1 CROSS JOIN sys.objects t2 CROSS JOIN sys.objects t3 CROSS JOIN sys.objects t4 CROSS JOIN sys.objects t5 ) t OPTION (MAXDOP 1);
Créons maintenant les statistiques ST_SampleDataTable_C2 pour la colonne c2
CREATE STATISTICS ST_SampleDataTable_C2 ON dbo.SampleDataTable(C2);
Et puis je vais insérer 1000 lignes, ce qui sera très important et à cause de cela j'ai vraiment besoin de mettre à jour les statistiques.
set nocount on; INSERT INTO dbo.SampleDataTable WITH (TABLOCK) SELECT 10000000 + t.RN, 999999999 FROM ( SELECT TOP (1000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) RN FROM sys.objects t1 CROSS JOIN sys.objects t2 CROSS JOIN sys.objects t3 CROSS JOIN sys.objects t4 CROSS JOIN sys.objects t5 ) t OPTION (MAXDOP 1);
Maintenant, j'ai 1000 entrées dans lesquelles, dans la colonne C2, la valeur est 999999999. Et cela signifie certainement le problème de la clé ascendante et j'ai vraiment besoin de mettre à jour les statistiques ... sur la réplique afin de ne pas forcer le serveur principal avec les calculs et l'a empêché de servir les clients.
En utilisant la bonne vieille commande DBCC SHOW_STATISTICS, examinons nos statistiques.
DBCC SHOW_STATISTICS('dbo.SampleDataTable', 'ST_SampleDataTable_C2')
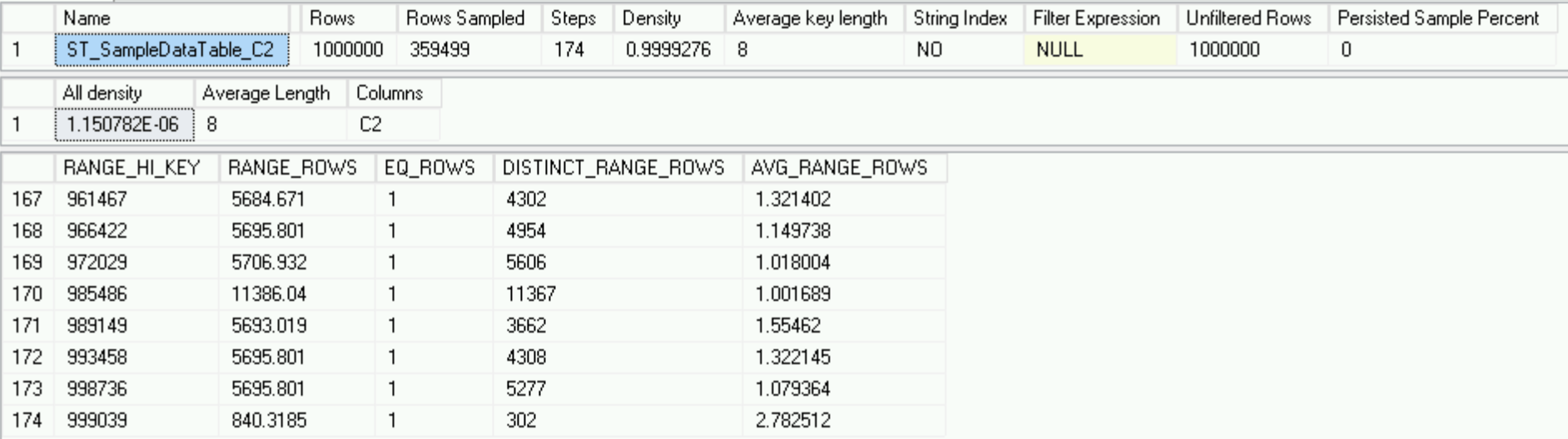
Tout est parfait dans notre royaume et nos statistiques sont en parfait ordre, bien qu'il ne prenne en compte qu'un million de lignes et qu'il n'y ait pas ce millier de lignes nuisibles, qui, en fin de compte, devraient faire partie de ces statistiques.
En outre, nous pouvons voir le flux de statistiques à l'aide du paramètre STATS_STREAM de la commande DBCC SHOW_STATISTICS:
DBCC SHOW_STATISTICS('dbo.SampleDataTable', 'ST_SampleDataTable_C2') WITH STATS_STREAM;

C'est juste un jeu de caractères sur lequel les blogs écrivent depuis des années, mais je ne sais toujours pas si c'est une fonctionnalité entièrement documentée (même si cela n'a jamais empêché les gens de l'utiliser).
Au bon moment
Copions notre table sur une réplique vers tempdb (bien que mon AG soit en mode synchrone, la même chose peut être faite en asynchrone, seules les données peuvent venir avec un léger retard).
use TempDB; DROP TABLE IF EXISTS dbo.SampleDataTable; CREATE TABLE dbo.SampleDataTable ( C1 BIGINT NOT NULL, C2 BIGINT NOT NULL, CONSTRAINT PK_SampleDataTable PRIMARY KEY (C1) ); INSERT INTO dbo.SampleDataTable SELECT C1, C2 FROM AvGroupDb.dbo.SampleDataTable;
Nous sommes maintenant prêts à mettre à jour les statistiques avec une analyse complète dans tempdb sur la réplique.
use TempDB; UPDATE STATISTICS ST_SampleDataTable_C2 ON dbo.SampleDataTable(C2) WITH FULLSCAN;
(
Note du traducteur - Nico a oublié de créer des statistiques et utilise la syntaxe incorrecte de l'opération UPDATE STATISTICS, au lieu de UPDATE, elle devrait être CREATE, c'est-à-dire que les statistiques ne sont pas mises à jour, mais créées )
Revenez à DBCC SHOW_STATISTICS et regardez-le:
DBCC SHOW_STATISTICS('dbo.SampleDataTable', 'ST_SampleDataTable_C2')
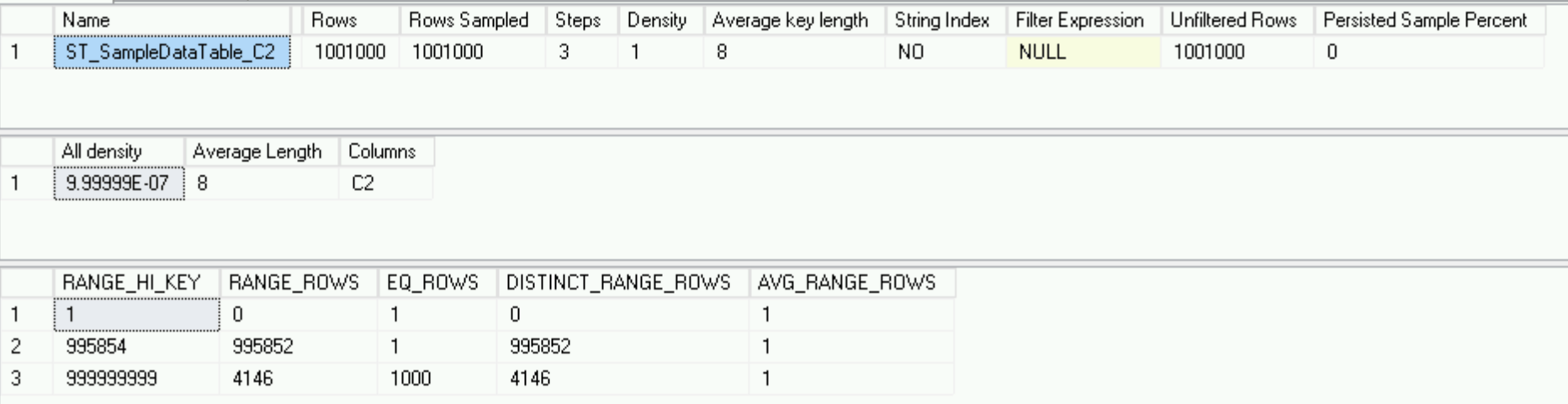
Il semble complètement différent de ce qu'il était sur le serveur principal - seulement 3 lignes contre 178, mais il décrit parfaitement les données - nous avons un million de lignes uniques et 1000 lignes avec la même valeur de colonne C2 - l'histogramme est aussi bon que possible .
Regardons le flux de statistiques:
DBCC SHOW_STATISTICS('dbo.SampleDataTable', 'ST_SampleDataTable_C2') WITH STATS_STREAM;

Vous n'avez pas besoin d'être un génie pour remarquer que le flux est complètement différent - nous voyons les 5689A0C6 caractères dans le flux mis à jour, tandis que dans l'original, entre tous ces zéros que nous avons vus EDF10EB4.
Concentrons-nous sur l'exportation de ces données vers un fichier texte quelque part en dehors de SQL Server et faisons-le à l'aide de la merveilleuse commande BCP, qui nécessite l'activation de CMDSHELL (remarque: vous ne voulez probablement pas cela sur votre serveur de production):
EXEC xp_cmdshell 'BCP "DBCC SHOW_STATISTICS(''AvGroupDb.dbo.SampleDataTable'', ''ST_SampleDataTable_C2'') WITH STATS_STREAM" queryout \\SharedServer\Tempdb\stats.txt -c -T';
Et voici la taille du fichier stats.txt dans notre boule:

Juste quelques kilo-octets! Facile à transmettre, facile à gérer.
Retour au serveur principal
Sur le serveur principal, nous devrons créer une table temporaire qui stockera le flux de statistiques avant de pouvoir en mettre à jour les statistiques dans notre table SampleDataTable principale (en pratique, nous pouvons développer cette table pour de nombreuses bases de données, tables, statistiques).
CREATE TABLE dbo.TempStats( Stats_Stream VARBINARY(MAX), Rows BIGINT, DataPages BIGINT );
Importons les données de notre fichier texte dans notre nouvelle table temporaire et voyons ce que nous avons importé:
BULK INSERT dbo.TempStats FROM '\\SharedServer\Tempdb\stats.txt' SELECT * FROM dbo.TempStats;

Nous pouvons voir les mêmes données que nous avons calculées sur la réplique, mais ces données sont déjà sur notre serveur principal et tout ce qui nous reste à faire est de mettre à jour nos statistiques à partir d'eux dans le tableau. Cette opération peut être effectuée à l'aide de l'opération UPDATE STATISTICS à l'aide du paramètre WITH STATS_STREAM = ...
DECLARE @script NVARCHAR(MAX) SELECT @script = 'UPDATE STATISTICS dbo.SampleDataTable(ST_SampleDataTable_C2) WITH STATS_STREAM = ' + CONVERT(nvarchar(max), [Stats_Stream],1) FROM dbo.TempStats PRINT @script; EXECUTE sp_executesql @script;
Ce script lit la valeur importée ci-dessus (oui, je sais - j'ai fait cet exemple pour une table et je n'ai pas pris la peine de plusieurs statistiques, tables, bases de données, etc.), génère une instruction UPDATE STATISTICS, l'affiche à l'écran et, à la fin, le remplit.
Voici ce que j'obtiens dans la sortie:
UPDATE STATISTICS dbo.SampleDataTable(ST_SampleDataTable_C2) WITH STATS_STREAM =
L'exécution de DBCC SHOW_STATISTICS sur le serveur principal me donne le résultat que j'espérais - le même que ce que nous avons vu sur la réplique. Le cercle est fermé.
DBCC SHOW_STATISTICS('dbo.SampleDataTable', 'ST_SampleDataTable_C2');
La partie vraiment impressionnante de cette histoire est que la taille de l'objet avec des statistiques est très petite et nous pouvons le transférer très facilement / instantanément sur le serveur principal.
Scénario pas si basique.
Si vous avez plusieurs AG entre les mêmes répliques, où une réplique est la principale dans une AG et l'autre dans la seconde, alors vous pouvez insérer des données BLOB dans le flux de données entre les répliques et ajouter une petite base de données avec les données transmises.
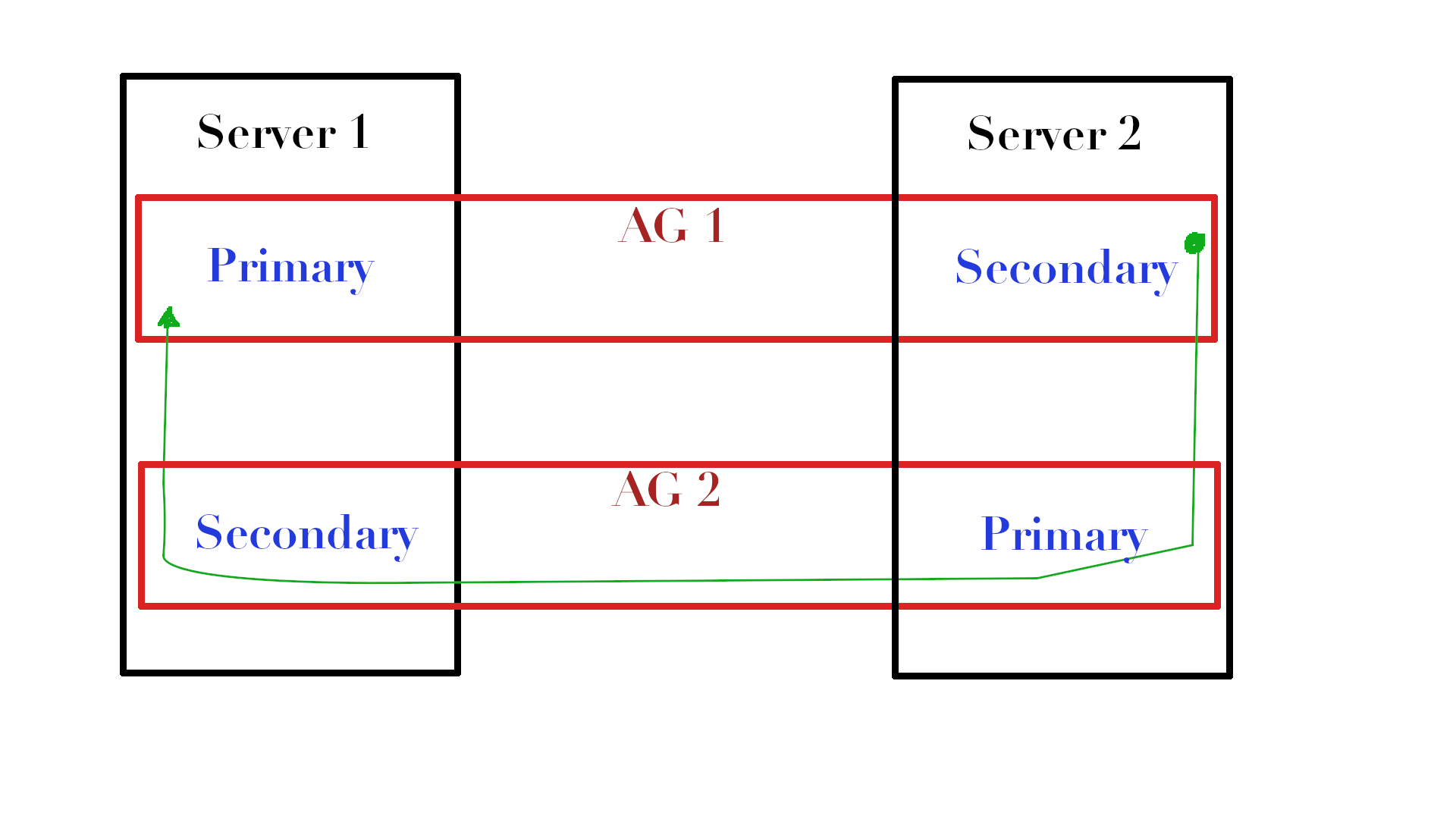
Regardez l'image. Si nous avons deux AG (AG1 et AG2) qui sont situés sur des serveurs différents et que nous avons une table spécifique sur Server1 dans AG1 pour laquelle nous voulons mettre à jour les statistiques, alors sur Server2 nous pouvons copier cette table (appelons-la dbo.MyTable ) dans tempdb, mettez à jour et utilisez AG2 renvoyez l'objet avec le flux de statistiques vers Server1, où vous importez simplement les statistiques de ce flux dans les statistiques dont nous avons besoin.
Oui, je sais, cela semble déroutant, mais pensez-y simplement comme un canal de rétroaction à travers lequel les résultats sont livrés, au lieu de les mettre dans des fichiers.
Place au doute
Vous pouvez avoir quelques objections, par exemple:
- pourquoi devrais-je le faire sur une réplique si je peux le faire en toute sécurité sur le serveur principal? (enfin, l'idée est de décharger le serveur principal)
- mais nous ne chargeons pas potentiellement la réplique (oui, mais si elle est inactive, c'est pourquoi nous voulons utiliser sa puissance)
- et nous ne pouvons pas agir sur le serveur principal en quelque sorte? (non, nous lisons simplement les données de la réplique et renvoyons quelques kilo-octets, ce qui, dans notre siècle, des gigaoctets et des téraoctets sonne comme "shtoa?")
- Que se passe-t-il si au milieu du processus, le serveur principal commence à mettre à jour les statistiques de son propre chef? (dans ce cas, il peut soit interrompre le deuxième processus, soit redémarrer avec les données mises à jour).
AG Feedback Channel
Il s'agit d'un canal avec des commentaires de la réplique sur le serveur principal - après avoir promis la transaction dans l'AG synchrone, le serveur principal attendra la confirmation de la réplique - et je pense que ce canal peut être utilisé pour implémenter cette amélioration. Regardez la photo prise dans un post par
Simon Su .
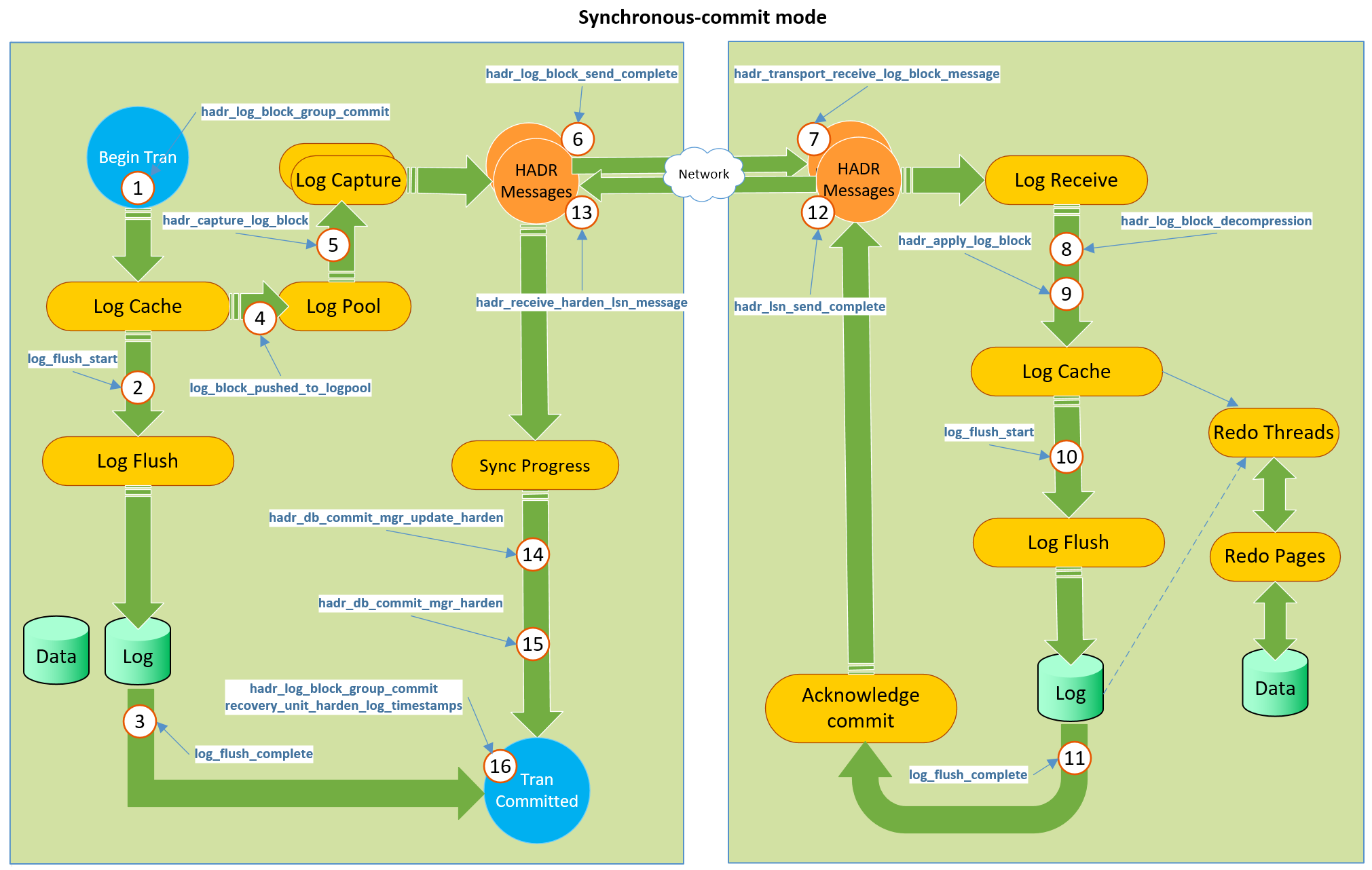
Ce qui représente tout le mécanisme du canal de rétroaction existant. La réplique, à l'aide des étapes 12 et suivantes, confirme au serveur principal que les informations ont été enregistrées. Le même canal peut être utilisé pour envoyer un objet de flux de statistiques après le recomptage sur une réplique. Bien sûr, nous n'aurons pas à utiliser tempdb à cette fin, mais créer un objet en mémoire dans la base de données qui ne devrait pas être stocké en permanence (regardez vos tables de schéma OLTP en mémoire uniquement, ou pensez aux tables NOLOGGING dans Oracle), et devrait être retiré à la fin de l'opération - ce serait vraiment cool.
Réflexions générales
Cela ne devrait pas dépendre du fait que la réplique synchrone ou non - la plupart du temps, les statistiques ne sont pas mises à jour toutes les deux secondes et cela nous amène à la deuxième partie de l'idée - pour effectuer un appel pour mettre à jour les statistiques sur le serveur principal avec un paramètre, tel que
UPDATE STATISTICS dbo.MyAwesomeTable(HugeImportantStatOnC17) WITH FULLSCAN, SECONDARY
où le paramètre SECONDARY indique où l'opération doit être effectuée.
Et tout comme pour les sauvegardes, nous devrions être en mesure de spécifier la réplique préférée pour effectuer des MISES À JOUR DE STATISTIQUES (ou toute autre opération à l'avenir) dans les paramètres.
Je suis sûr que cette fonctionnalité encouragera de nombreux utilisateurs Enterprise Edition à migrer vers la nouvelle version de SQL Server, ce qui permettra de répartir les opérations lourdes entre les répliques.
Quant à la situation actuelle - je vois exactement comment vous pouvez automatiser cette solution en utilisant Powershell.
Microsoft, c'est ton tour! ;)
Votez pour la fonctionnalité proposée
ici .
Note du traducteur: Toutes les suggestions et commentaires sur la traduction et le style sont les bienvenus, comme d'habitude.
J'ai généralement appelé réplique principale dans la traduction «serveur principal» et réplique secondaire - simplement une réplique. Ce n'est peut-être pas tout à fait correct, mais mon oreille me fait moins mal que les répliques "primaire" et "secondaire" sur msdn.