Les deux précédentes séries d'articles se sont concentrées sur l'
isolement, le multiversionisme et la
journalisation .
Dans cette série, nous parlerons des serrures. J'adhérerai à ce terme, mais dans la littérature il peut aussi y en avoir un autre:
château .
Le cycle comprendra quatre parties:
- Verrous de relation (cet article);
- Serrures de rangées ;
- Serrures d'autres objets et verrous de prédicat;
- Verrous en RAM .
Le matériel de tous les articles est basé sur
des cours de formation administrative que Pavel
pluzanov et moi
faisons , mais ne les répètent pas textuellement et sont destinés à une lecture réfléchie et à une expérimentation indépendante.
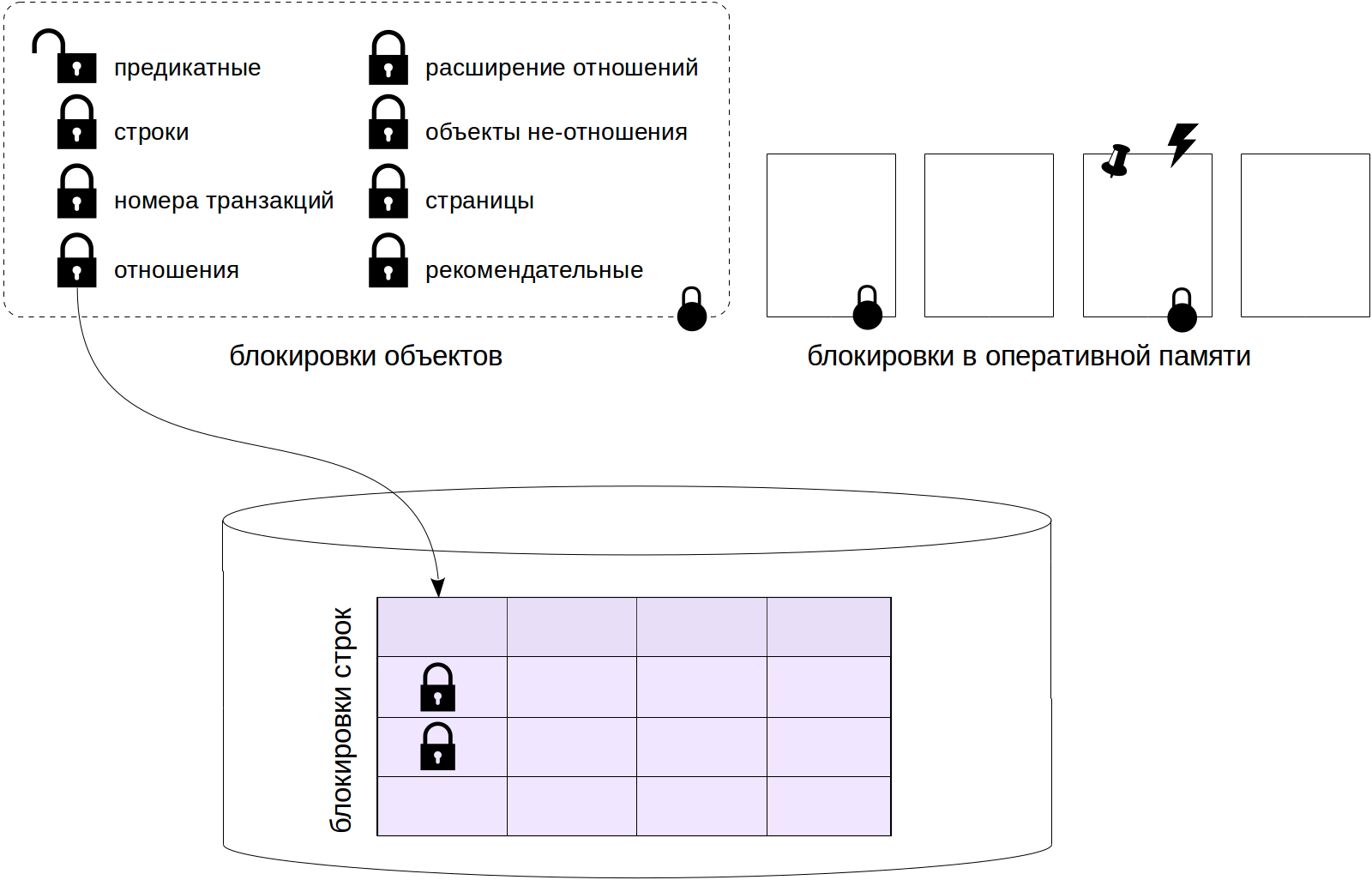
Informations générales sur les serrures
PostgreSQL utilise de nombreux mécanismes différents qui sont utilisés pour bloquer quelque chose (ou du moins sont appelés ainsi). Par conséquent, je vais commencer par les mots les plus généraux expliquant pourquoi les verrous sont nécessaires, ce qu'ils sont et comment ils diffèrent les uns des autres. Ensuite, nous verrons ce que l'on trouve de cette variété dans PostgreSQL et ce n'est qu'après que nous commencerons à traiter en détail les différents types de verrous.
Les verrous sont utilisés pour rationaliser l'accès simultané aux ressources partagées.
L'accès concurrentiel fait référence à l'accès simultané de plusieurs processus. Les processus eux-mêmes peuvent être effectués à la fois en parallèle (si l'équipement le permet) et séquentiellement en mode de partage de temps - ce n'est pas important.
S'il n'y a pas de concurrence, il n'y a pas besoin de verrous (par exemple, un cache de tampon partagé nécessite des verrous, mais pas un local).
Avant d'accéder à une ressource, un processus doit acquérir le verrou associé à cette ressource. Autrement dit, nous parlons d'une certaine discipline: tout fonctionne tant que tous les processus sont conformes aux règles établies pour accéder à une ressource partagée. Si le SGBD gère les verrous, il surveille lui-même la commande; si le blocage est fixé par l'application, cette obligation lui incombe.
À un niveau bas, un verrou est représenté par une section de mémoire partagée, dans laquelle il est noté d'une certaine manière si le verrou est libre ou capturé (et, éventuellement, des informations supplémentaires sont enregistrées: numéro de processus, temps de capture, etc.).
Vous remarquerez peut-être qu'un tel morceau de mémoire partagée est en soi une ressource à laquelle un accès concurrentiel est possible. Si nous descendons un niveau plus bas, nous verrons que les primitives accessoires spéciales (telles que les sémaphores ou les mutex) fournies par le système d'exploitation sont utilisées pour organiser l'accès. Leur signification est que le code accédant à la ressource partagée doit être exécuté en un seul processus à la fois. Au niveau le plus bas, ces primitives sont implémentées sur la base des instructions du processeur atomique (telles que test-and-set ou compare-and-swap).
Une fois que la ressource n'est plus nécessaire au processus, elle
libère le verrou pour que d'autres puissent l'utiliser.
Bien sûr, le verrouillage du verrou n'est pas toujours possible: la ressource peut déjà être prise par quelqu'un d'autre. Ensuite, le processus entre dans la file d'attente (si le mécanisme de verrouillage donne cette possibilité), ou réessaye de capturer le verrou après un certain temps. D'une manière ou d'une autre, cela conduit au fait que le processus est obligé de rester inactif en prévision de la libération de la ressource.
Il est parfois possible d'appliquer d'autres stratégies non bloquantes. Par exemple, le mécanisme de multi- version permet à plusieurs processus dans certains cas de fonctionner simultanément avec différentes versions de données sans se bloquer les uns les autres.
En principe, une ressource protégée peut être n'importe quoi, si seulement cette ressource pouvait être identifiée sans ambiguïté et mise en correspondance avec une adresse de blocage.
Par exemple, la ressource peut être l'objet avec lequel le SGBD travaille, comme une page de données (identifiée par le nom et la position du fichier dans le fichier), une table (oid dans le répertoire système), une ligne de table (page et décalage à l'intérieur de la page). Une ressource peut être une structure en mémoire, telle qu'une table de hachage, un tampon, etc. (identifiée par un numéro pré-attribué). Parfois, il est même pratique d'utiliser des ressources abstraites qui n'ont aucune signification physique (elles sont identifiées simplement par un numéro unique).
L'efficacité des serrures est influencée par de nombreux facteurs, dont nous distinguons deux.
- La granularité (granularité) est importante si les ressources forment une hiérarchie.
Par exemple, un tableau se compose de pages contenant des lignes de tableau. Tous ces objets peuvent agir comme des ressources. Si les processus ne sont généralement intéressés que par quelques lignes et que le verrou est défini au niveau de la table, les autres processus ne pourront pas travailler avec différentes lignes en même temps. Par conséquent, plus la granularité est élevée, meilleure est la possibilité de parallélisation.
Mais cela conduit à une augmentation du nombre de verrous (dont les informations doivent être stockées en mémoire). Dans ce cas, une augmentation du niveau (escalade) des verrous peut être appliquée: lorsque le nombre de verrous granulaires de bas niveau dépasse une certaine limite, ils sont remplacés par un verrou de niveau supérieur.
- Les verrous peuvent être capturés dans différents modes .
Les noms des modes peuvent être absolument arbitraires, seule la matrice de leur compatibilité les uns avec les autres est importante. Un mode incompatible avec n'importe quel mode (y compris avec lui-même) est généralement appelé exclusif ou exclusif. Si les modes sont compatibles, le verrou peut être capturé par plusieurs processus simultanément; ces modes sont appelés partagés. En général, plus les modes compatibles les uns avec les autres peuvent être distingués, plus les opportunités de parallélisme sont créées.
Selon le temps d'utilisation, les serrures peuvent être divisées en longues et courtes.
- Les verrous à long terme sont capturés pendant une période potentiellement longue (généralement jusqu'à la fin de la transaction) et concernent le plus souvent des ressources telles que des tables (relations) et des lignes. PostgreSQL gère généralement ces verrous automatiquement, mais l'utilisateur a néanmoins un certain contrôle sur ce processus.
Les verrouillages longs sont caractérisés par un grand nombre de modes afin que le plus d'actions simultanées possible puissent être effectuées sur les données. En règle générale, pour de tels verrous, il existe une infrastructure développée (par exemple, la prise en charge des files d'attente et la détection des interblocages) et des outils de surveillance, car les coûts de maintenance de toutes ces commodités sont toujours incomparablement inférieurs au coût des opérations sur les données protégées.
- Les verrous à court terme sont capturés pendant une courte période (de quelques instructions de processeur à des fractions de seconde) et font généralement référence à des structures de données dans la mémoire partagée. PostgreSQL gère ces verrous de manière entièrement automatique - il vous suffit de connaître leur existence.
Les serrures courtes se caractérisent par un minimum de modes (exclusifs et partagés) et une infrastructure simple. Dans certains cas, même les outils de surveillance peuvent ne pas être disponibles.
PostgreSQL utilise différents types de verrous.
Les verrous au niveau de l'objet sont des
verrous à long terme «lourds». Les ressources ici sont des relations et d'autres objets. Si le mot blocage apparaît dans le texte sans clarification, alors il désigne exactement un tel blocage «normal».
Parmi les verrous à long terme, les verrous de
niveau ligne se distinguent séparément. Leur implémentation diffère des autres verrous à long terme en raison de leur nombre potentiellement énorme (imaginez la mise à jour d'un million de lignes en une seule transaction). Ces verrous seront discutés dans le prochain article.
Le troisième article de la série sera consacré aux verrous restants au niveau de l'objet, ainsi qu'aux
verrous de prédicat (puisque les informations sur tous ces verrous sont stockées dans la RAM de la même manière).
Les verrous courts comprennent divers
verrous de structures RAM . Nous les examinerons dans le dernier article du cycle.
Verrous d'objets
Donc, nous commençons avec des verrous au niveau de l'objet. Ici, un objet est d'abord compris comme des
relations , c'est-à-dire des tableaux, des index, des séquences, des représentations matérialisées, mais aussi d'autres entités. Ces verrous protègent généralement les objets d'être modifiés en même temps ou d'être utilisés pendant que l'objet change, mais aussi pour d'autres besoins.
Libellé flou? C'est parce que les verrous de ce groupe sont utilisés à diverses fins. Ce qui les unit, c'est la façon dont ils sont organisés.
Périphérique
Les verrous d'objets se trouvent dans la mémoire partagée du serveur. Leur nombre est limité par le produit des valeurs de deux paramètres:
max_locks_per_transaction ×
max_connections .
Le pool de verrous est commun à toutes les transactions, c'est-à-dire qu'une transaction peut capturer plus de verrous que
max_locks_per_transaction : il est seulement important que le nombre total de verrous dans le système ne dépasse pas la limite définie. Le pool est créé au démarrage, donc la modification de l'une des deux options indiquées nécessite un redémarrage du serveur.
Tous les verrous peuvent être affichés dans la vue pg_locks.
Si une ressource est déjà verrouillée en mode incompatible, une transaction essayant de capturer cette ressource est mise en file d'attente et attend que le verrou soit libéré. Les transactions en attente ne consomment pas de ressources processeur: les processus de service correspondants «s'endorment» et se réveillent par le système d'exploitation lorsque la ressource est libérée.
Une situation de
blocage est possible dans laquelle une transaction nécessite une ressource occupée par la deuxième transaction pour continuer, et la seconde nécessite une ressource occupée par la première (dans le cas général, un blocage et plus de deux transactions peuvent se produire). Dans ce cas, l'attente se poursuivra indéfiniment, donc PostgreSQL détecte automatiquement de telles situations et abandonne l'une des transactions afin que d'autres puissent continuer à fonctionner. (Nous parlerons plus des blocages dans le prochain article.)
Types d'objets
Voici une liste des types de verrous (ou, si vous le souhaitez, les types d'objets) que nous traiterons dans cet article et le suivant. Les noms sont donnés conformément à la colonne locktype de la vue pg_locks.
- relation
Verrous de relation.
- transactionid et virtualxid
Blocage d'un numéro de transaction (réel ou virtuel). Chaque transaction elle-même détient un verrou exclusif de son propre numéro, de sorte que ces verrous sont pratiques à utiliser lorsque vous devez attendre la fin d'une autre transaction.
- tuple
Verrou de version de chaîne. Il est utilisé dans certains cas pour définir la priorité parmi plusieurs transactions qui s'attendent à verrouiller la même ligne.
Nous reporterons la discussion des types de verrous restants au troisième article du cycle. Tous sont capturés soit uniquement en mode exceptionnel, soit en mode exclusif et partagé.
- étendre
Utilisé lors de l'ajout de pages à un fichier de toute relation.
- objet
Verrouillage d'objets qui ne sont pas des relations (bases de données, schémas, abonnements, etc.).
- page
Le verrouillage de page est utilisé rarement et uniquement par certains types d'index.
- conseil
Blocage recommandé, défini manuellement par l'utilisateur.
Verrous de relation
Afin de ne pas perdre le contexte, je marquerai sur une telle image les types de verrous qui seront discutés plus tard.
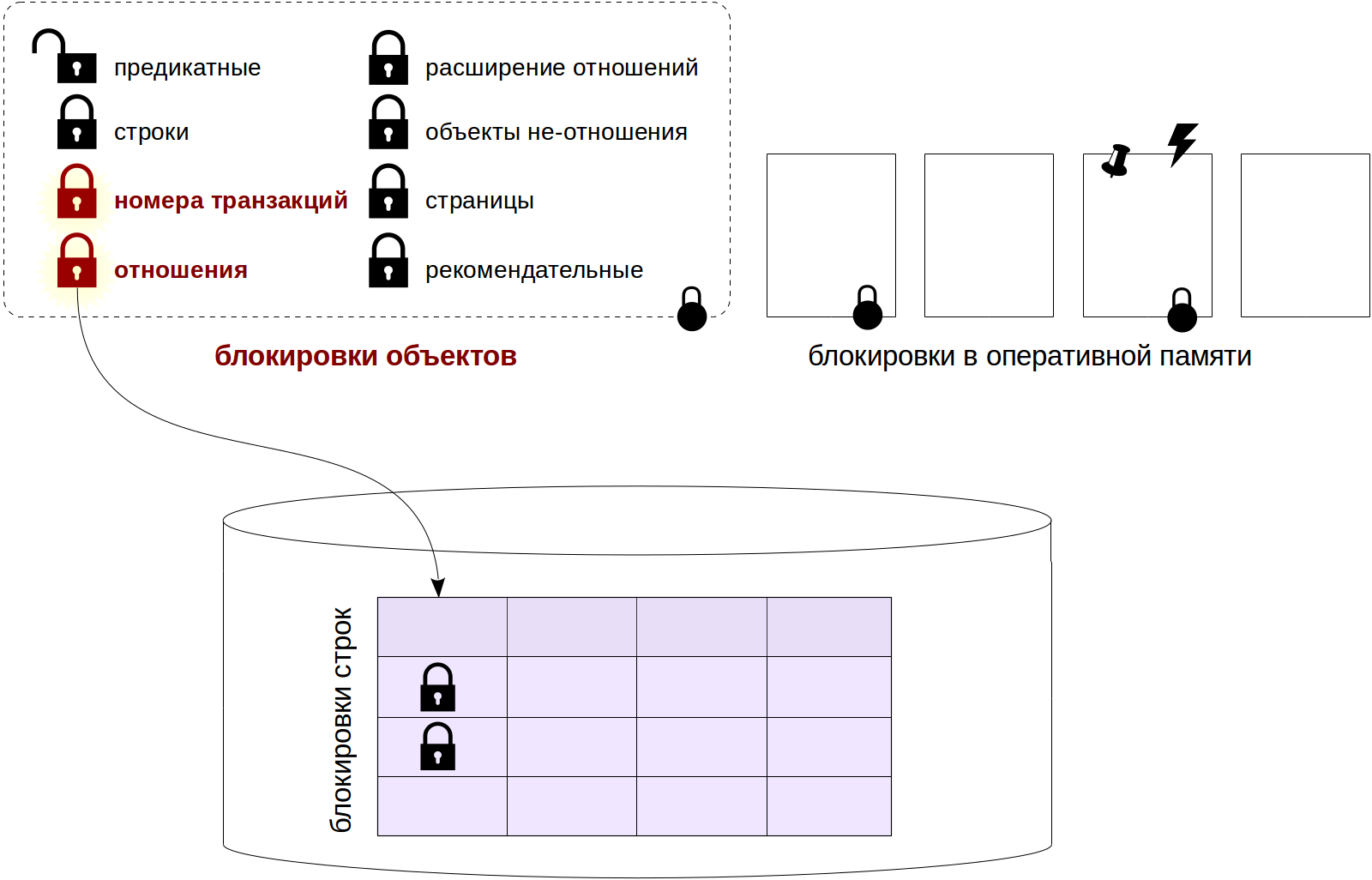
Les modes
Si ce n'est pas le plus important, alors certainement le blocage le plus «ramifié» - les relations de blocage. Pour elle, jusqu'à 8 modes différents sont définis. Une telle quantité est nécessaire pour que le plus grand nombre possible d'instructions appartenant à une table puissent être exécutées simultanément.
Cela n'a aucun sens d'apprendre ces modes par cœur ou d'essayer de comprendre la signification de leurs noms; l'essentiel est d'avoir une
matrice devant vos yeux au bon moment, qui montre quelles serrures entrent en conflit les unes avec les autres. Pour plus de commodité, il est reproduit ici avec des exemples de commandes qui nécessitent des niveaux de verrouillage appropriés:
Quelques commentaires:
- Les 4 premiers modes permettent des changements de données simultanés dans le tableau, et les 4 suivants ne le permettent pas.
- Le premier mode (Access Share) est le plus faible, il est compatible avec tout autre que le dernier (Access Exclusive). Ce dernier mode est exclusif, il n'est compatible avec aucun mode.
- La commande ALTER TABLE possède de nombreuses options, dont différentes nécessitent différents niveaux de verrouillage. Par conséquent, dans la matrice, cette commande apparaît sur différentes lignes et est marquée d'un astérisque.
Par exemple, par exemple
donnez un exemple. Que se passe-t-il si j'exécute la commande CREATE INDEX?
Nous constatons dans la documentation que cette commande définit le verrou en mode Partage. Selon la matrice, nous déterminons que la commande est compatible avec elle-même (c'est-à-dire que vous pouvez créer simultanément plusieurs index) et avec les commandes de lecture. Ainsi, les commandes SELECT continueront de fonctionner, mais les commandes UPDATE, DELETE, INSERT seront bloquées.
Et vice versa - les transactions incomplètes qui modifient les données du tableau bloqueront le fonctionnement de la commande CREATE INDEX. Par conséquent, il existe une variante de la commande - CREATE INDEX CONCURRENTLY. Cela fonctionne plus longtemps (et peut même tomber avec une erreur), mais permet des changements de données simultanés.
Cela se voit dans la pratique. Pour les expérimentations, nous utiliserons
le tableau des comptes «bancaires» familiers du
premier cycle , dans lequel nous enregistrerons le numéro et le montant du compte.
=> CREATE TABLE accounts( acc_no integer PRIMARY KEY, amount numeric ); => INSERT INTO accounts VALUES (1,1000.00), (2,2000.00), (3,3000.00);
Dans la deuxième session, démarrez la transaction. Nous avons besoin d'un numéro de processus de service.
| => SELECT pg_backend_pid();
| pg_backend_pid | ---------------- | 4746 | (1 row)
Quels verrous la nouvelle transaction démarre-t-elle? Nous regardons dans pg_locks:
=> SELECT locktype, relation::REGCLASS, virtualxid AS virtxid, transactionid AS xid, mode, granted FROM pg_locks WHERE pid = 4746;
locktype | relation | virtxid | xid | mode | granted ------------+----------+---------+-----+---------------+--------- virtualxid | | 5/15 | | ExclusiveLock | t (1 row)
Comme je l'ai déjà dit, une transaction contient toujours un verrou exclusif (ExclusiveLock) de son propre numéro, dans ce cas, virtuel. Il n'y a pas d'autres verrous sur ce processus.
Mettez à jour la ligne du tableau. Comment la situation va-t-elle changer?
| => UPDATE accounts SET amount = amount + 100 WHERE acc_no = 1;
=> \g
locktype | relation | virtxid | xid | mode | granted ---------------+---------------+---------+--------+------------------+--------- relation | accounts_pkey | | | RowExclusiveLock | t relation | accounts | | | RowExclusiveLock | t virtualxid | | 5/15 | | ExclusiveLock | t transactionid | | | 529404 | ExclusiveLock | t (4 rows)
Il y a maintenant des verrous sur la table et l'index modifiables (créés pour la clé primaire), qui sont utilisés par la commande UPDATE. Les deux verrous sont pris en mode RowExclusiveLock. De plus, un blocage exclusif du numéro de transaction réel a été ajouté (qui est apparu dès que la transaction a commencé à modifier les données).
Maintenant, dans une autre session, nous allons essayer de créer un index sur une table.
|| => SELECT pg_backend_pid();
|| pg_backend_pid || ---------------- || 4782 || (1 row)
|| => CREATE INDEX ON accounts(acc_no);
La commande se bloque en prévision de la libération de la ressource. Quel genre de verrou essaie-t-elle de capturer? Vérifier:
=> SELECT locktype, relation::REGCLASS, virtualxid AS virtxid, transactionid AS xid, mode, granted FROM pg_locks WHERE pid = 4782;
locktype | relation | virtxid | xid | mode | granted ------------+----------+---------+-----+---------------+--------- virtualxid | | 6/15 | | ExclusiveLock | t relation | accounts | | | ShareLock | f (2 rows)
Nous voyons que la transaction tente d'obtenir le verrou de table en mode ShareLock, mais ne peut pas (accordé = f).
Il est pratique de trouver le numéro du processus de blocage, et en général plusieurs numéros, en utilisant la fonction qui est apparue dans la version 9.6 (avant cela, je devais tirer des conclusions en regardant attentivement tout le contenu de pg_locks):
=> SELECT pg_blocking_pids(4782);
pg_blocking_pids ------------------ {4746} (1 row)
Et puis, pour comprendre la situation, vous pouvez obtenir des informations sur les sessions, notamment les nombres trouvés:
=> SELECT * FROM pg_stat_activity WHERE pid = ANY(pg_blocking_pids(4782)) \gx
-[ RECORD 1 ]----+------------------------------------------------------------ datid | 16386 datname | test pid | 4746 usesysid | 16384 usename | student application_name | psql client_addr | client_hostname | client_port | -1 backend_start | 2019-08-07 15:02:53.811842+03 xact_start | 2019-08-07 15:02:54.090672+03 query_start | 2019-08-07 15:02:54.10621+03 state_change | 2019-08-07 15:02:54.106965+03 wait_event_type | Client wait_event | ClientRead state | idle in transaction backend_xid | 529404 backend_xmin | query | UPDATE accounts SET amount = amount + 100 WHERE acc_no = 1; backend_type | client backend
Une fois la transaction terminée, les verrous sont libérés et l'index est créé.
| => COMMIT;
| COMMIT
|| CREATE INDEX
Dans la file d'attente! ..
Afin de mieux imaginer à quoi conduit l'apparition d'un verrou incompatible, nous verrons ce qui se passe si la commande VACUUM FULL est exécutée pendant le fonctionnement du système.
Laissez la commande SELECT s'exécuter en premier sur notre table. Elle obtient un verrou sur le niveau le plus faible de partage d'accès. Pour contrôler le temps de libération du verrou, nous exécutons cette commande dans la transaction - jusqu'à la fin de la transaction, le verrou ne sera pas libéré. En réalité, plusieurs commandes peuvent lire (et modifier) la table, et certaines requêtes peuvent prendre un certain temps.
=> BEGIN; => SELECT * FROM accounts;
acc_no | amount --------+--------- 2 | 2000.00 3 | 3000.00 1 | 1100.00 (3 rows)
=> SELECT locktype, mode, granted, pid, pg_blocking_pids(pid) AS wait_for FROM pg_locks WHERE relation = 'accounts'::regclass;
locktype | mode | granted | pid | wait_for ----------+-----------------+---------+------+---------- relation | AccessShareLock | t | 4710 | {} (1 row)
Ensuite, l'administrateur exécute la commande VACUUM FULL, qui nécessite un verrou de niveau Access Exclusive, incompatible avec quoi que ce soit, même avec Access Share. (La commande LOCK TABLE requiert également le même verrou.) Les files d'attente de transactions.
| => BEGIN; | => LOCK TABLE accounts;
=> SELECT locktype, mode, granted, pid, pg_blocking_pids(pid) AS wait_for FROM pg_locks WHERE relation = 'accounts'::regclass;
locktype | mode | granted | pid | wait_for ----------+---------------------+---------+------+---------- relation | AccessShareLock | t | 4710 | {} relation | AccessExclusiveLock | f | 4746 | {4710} (2 rows)
Mais l'application continue d'émettre des demandes, et maintenant la commande SELECT apparaît dans le système. En théorie, elle aurait pu «glisser» pendant que VACUUM FULL attend, mais non - elle prend honnêtement une place dans la file d'attente pour VACUUM FULL.
|| => SELECT * FROM accounts;
=> SELECT locktype, mode, granted, pid, pg_blocking_pids(pid) AS wait_for FROM pg_locks WHERE relation = 'accounts'::regclass;
locktype | mode | granted | pid | wait_for ----------+---------------------+---------+------+---------- relation | AccessShareLock | t | 4710 | {} relation | AccessExclusiveLock | f | 4746 | {4710} relation | AccessShareLock | f | 4782 | {4746} (3 rows)
Une fois la première transaction avec la commande SELECT terminée et libérée, la commande VACUUM FULL commence (que nous avons simulée avec la commande LOCK TABLE).
=> COMMIT;
COMMIT
| LOCK TABLE
=> SELECT locktype, mode, granted, pid, pg_blocking_pids(pid) AS wait_for FROM pg_locks WHERE relation = 'accounts'::regclass;
locktype | mode | granted | pid | wait_for ----------+---------------------+---------+------+---------- relation | AccessExclusiveLock | t | 4746 | {} relation | AccessShareLock | f | 4782 | {4746} (2 rows)
Et ce n'est qu'après que VACUUM FULL aura terminé son travail et supprimé le verrou que toutes les commandes accumulées dans la file d'attente (SELECT dans notre exemple) pourront capturer les verrous correspondants (Access Share) et s'exécuter.
| => COMMIT;
| COMMIT
|| acc_no | amount || --------+--------- || 2 | 2000.00 || 3 | 3000.00 || 1 | 1100.00 || (3 rows)
Ainsi, une commande inexacte peut paralyser le fonctionnement du système pendant un temps nettement plus long que le temps d'exécution de la commande elle-même.
Outils de surveillance
Bien sûr, les verrous sont nécessaires pour un fonctionnement correct, mais peuvent conduire à des attentes indésirables. Ces attentes peuvent être surveillées afin de comprendre leur cause et, si possible, de les éliminer (par exemple, en changeant l'algorithme d'application).
Nous connaissions déjà une méthode: au moment d'un long verrou, nous pouvons exécuter une requête sur la vue pg_locks, regarder les transactions verrouillables et bloquantes (fonction pg_blocking_pids) et les décrypter en utilisant pg_stat_activity.
Une autre façon consiste à activer le paramètre
log_lock_waits . Dans ce cas, des informations apparaîtront dans le journal des messages du serveur si la transaction a attendu plus longtemps que
deadlock_timeout (malgré le fait que le paramètre de deadlocks soit utilisé, nous parlons d'attentes normales).
Essayons.
=> ALTER SYSTEM SET log_lock_waits = on; => SELECT pg_reload_conf();
La valeur par défaut du paramètre
deadlock_timeout est d'une seconde:
=> SHOW deadlock_timeout;
deadlock_timeout ------------------ 1s (1 row)
Jouez la serrure.
=> BEGIN; => UPDATE accounts SET amount = amount - 100.00 WHERE acc_no = 1;
UPDATE 1
| => BEGIN; | => UPDATE accounts SET amount = amount + 100.00 WHERE acc_no = 1;
La deuxième commande UPDATE attend un verrou. Attendez une seconde et terminez la première transaction.
=> SELECT pg_sleep(1); => COMMIT;
COMMIT
Maintenant, la deuxième transaction peut être effectuée.
| UPDATE 1
| => COMMIT;
| COMMIT
Et toutes les informations importantes sont entrées dans le journal:
postgres$ tail -n 7 /var/log/postgresql/postgresql-11-main.log
2019-08-07 15:26:30.827 MSK [5898] student@test LOG: process 5898 still waiting for ShareLock on transaction 529427 after 1000.186 ms 2019-08-07 15:26:30.827 MSK [5898] student@test DETAIL: Process holding the lock: 5862. Wait queue: 5898. 2019-08-07 15:26:30.827 MSK [5898] student@test CONTEXT: while updating tuple (0,4) in relation "accounts" 2019-08-07 15:26:30.827 MSK [5898] student@test STATEMENT: UPDATE accounts SET amount = amount + 100.00 WHERE acc_no = 1;
2019-08-07 15:26:30.836 MSK [5898] student@test LOG: process 5898 acquired ShareLock on transaction 529427 after 1009.536 ms 2019-08-07 15:26:30.836 MSK [5898] student@test CONTEXT: while updating tuple (0,4) in relation "accounts" 2019-08-07 15:26:30.836 MSK [5898] student@test STATEMENT: UPDATE accounts SET amount = amount + 100.00 WHERE acc_no = 1;
À suivre .