Dans cet article, nous traiterons de l'alignement des données et résoudrons également la 17e tâche à partir du site
pwnable.kr .
Information organisationnelleSurtout pour ceux qui veulent apprendre quelque chose de nouveau et se développer dans l'un des domaines de l'information et de la sécurité informatique, j'écrirai et parlerai des catégories suivantes:
- PWN;
- cryptographie (Crypto);
- technologies de réseau (réseau);
- reverse (Reverse Engineering);
- stéganographie (Stegano);
- recherche et exploitation des vulnérabilités WEB.
En plus de cela, je partagerai mon expérience en criminalistique informatique, analyse de logiciels malveillants et micrologiciels, attaques sur les réseaux sans fil et les réseaux locaux, réalisation de pentests et écriture d'exploits.
Afin que vous puissiez vous renseigner sur les nouveaux articles, logiciels et autres informations, j'ai créé une
chaîne dans Telegram et un
groupe pour discuter de tout problème dans le domaine de l'ICD. Aussi, je considérerai personnellement vos demandes, questions, suggestions et recommandations
personnelles et répondrai à tout le monde .
Toutes les informations sont fournies à des fins éducatives uniquement. L'auteur de ce document n'assume aucune responsabilité pour tout dommage causé à quelqu'un du fait de l'utilisation des connaissances et des méthodes obtenues à la suite de l'étude de ce document.
Alignement des données
L'alignement des données dans la mémoire à accès aléatoire de l'ordinateur est un arrangement spécial de données en mémoire pour un accès plus rapide. Lorsque vous travaillez avec de la mémoire, les processus utilisent le mot machine comme unité principale. Différents types de processeurs peuvent avoir différentes tailles: un, deux, quatre, huit, etc. octets. Lors de la sauvegarde d'objets en mémoire, il peut arriver que certains champs dépassent ces limites de mots. Certains processeurs peuvent travailler avec des données non alignées plus longtemps qu'avec des données alignées. Et les processeurs non sophistiqués ne peuvent généralement pas fonctionner avec des données non alignées.
Afin de mieux imaginer un modèle de données alignées et non alignées, considérons un exemple sur l'objet suivant - la structure de données.
struct Data{ int var1; void* mas[4]; };
Étant donné que la taille d'une variable int dans les processeurs x32 et x64 n'est pas de 4 octets et que la valeur d'une variable void * est respectivement de 4 et 8 octets, cette structure pour les processeurs x32 et x64 sera représentée en mémoire comme suit.

Les processeurs X64 avec une telle structure ne fonctionneront pas, car les données ne sont pas alignées. Pour l'alignement des données, il est nécessaire d'ajouter un autre champ de 4 octets à la structure.
struct Data{ int var1; int addition; void* mas[4]; };
Ainsi, les données de structure de données pour les processeurs x64 seront alignées en mémoire.

Solution d'emploi Memcpy
Nous cliquons sur l'icône de signature memcpy et on nous dit que nous devons nous connecter via SSH avec le mot de passe guest.
Ils fournissent également du code source. 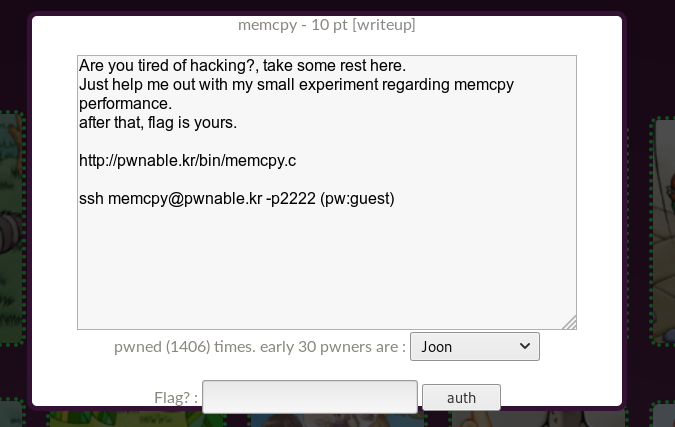
Une fois connecté, nous voyons la bannière correspondante.
Voyons quels fichiers se trouvent sur le serveur, ainsi que les droits dont nous disposons.

Nous avons un fichier Lisez-moi. Après l'avoir lu, nous apprenons que le programme s'exécute sur le port 9022.

Connectez-vous au port 9022. On nous propose une expérience - comparez la version lente et rapide de memcpy. Ensuite, le programme entrera un nombre dans un certain intervalle et émettra un rapport sur la comparaison des versions lente et rapide de la fonction. Il y a une chose: les expériences 10 et les rapports - 5.
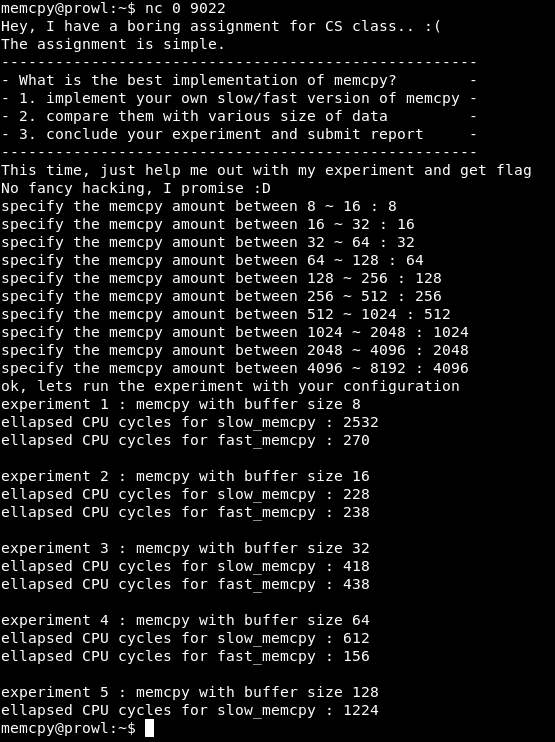
Voyons pourquoi. Trouvez l'endroit dans le code pour comparer les résultats.
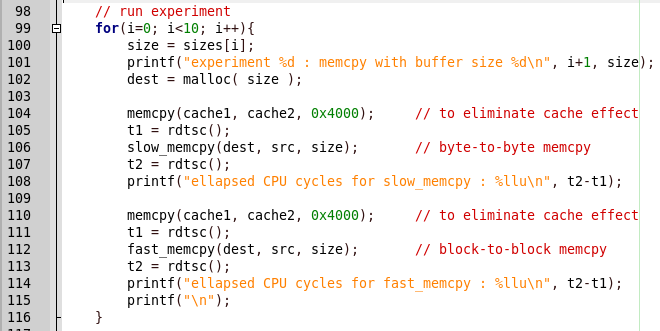
Tout est simple, d'abord slow_memcpy est appelé, puis fast_memcpy. Mais dans le rapport du programme, il y a une conclusion sur la libération lente de la fonction, et lorsque la mise en œuvre rapide est appelée, le programme plante. Voyons le code d'implémentation rapide.
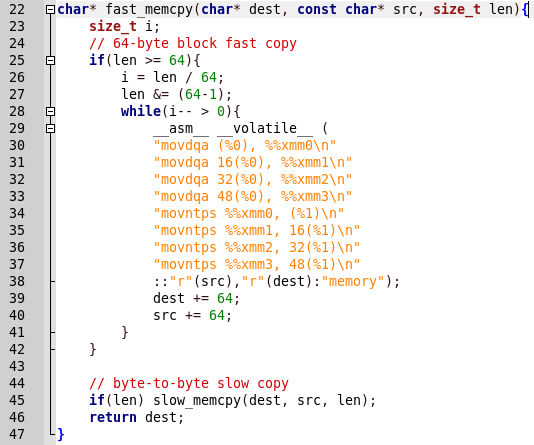
La copie se fait à l'aide des fonctions d'assembleur. Nous déterminons par des commandes qu'il s'agit de SSE2. Comme indiqué
ici : SSE2 utilise huit registres 128 bits (xmm0 à xmm7) inclus dans l'architecture x86 avec l'introduction de l'extension SSE, chacun étant traité comme 2 valeurs à virgule flottante double précision consécutives. De plus, ce code fonctionne avec des données alignées.


Ainsi, en travaillant avec des données non alignées, le programme peut se bloquer. L'alignement est effectué sur 128 bits, soit 16 octets, donc les blocs doivent être égaux à 16. Nous devons savoir combien d'octets sont déjà dans le premier bloc du tas (soit X), puis nous devons chacun transférer le programme autant d'octets (soit Y) pour que ( X + Y)% 16 était 0.
Étant donné que toutes les opérations occupent des blocs de tas qui sont des multiples de deux, itérez sur X comme 2, 4, 8, etc. jusqu'au 16.
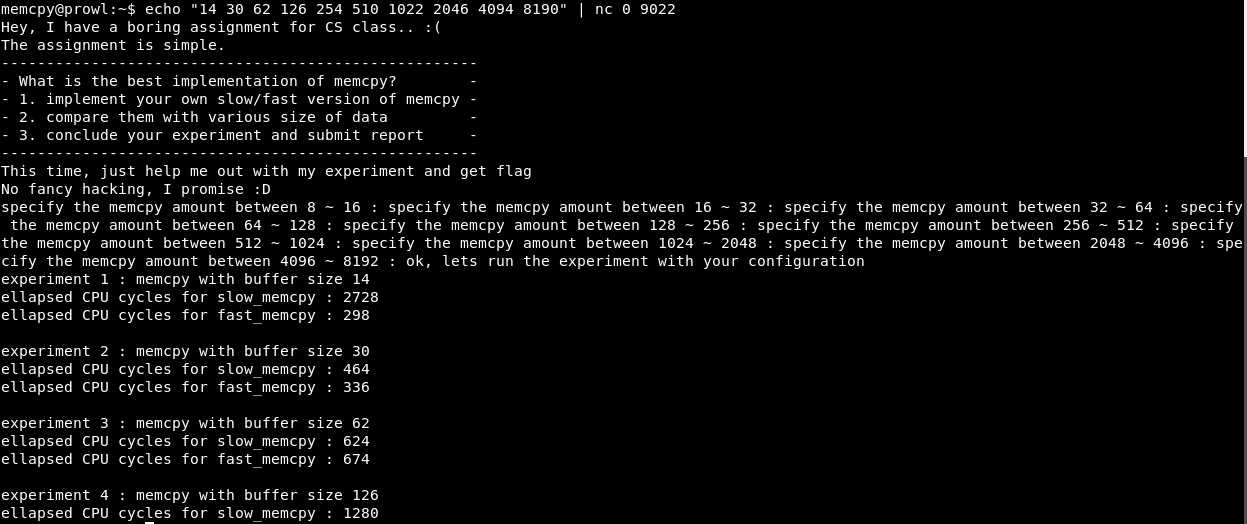
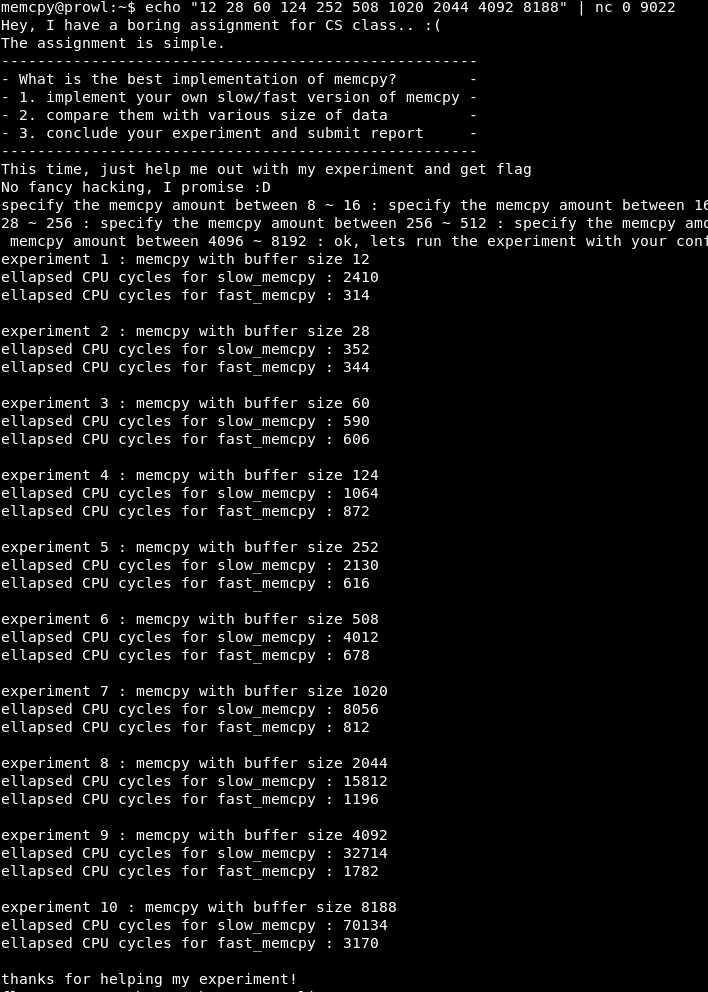
Comme vous pouvez le voir, avec X = 4, le programme s'exécute correctement.

Nous obtenons la coquille, lisons le drapeau, obtenons 10 points.
Vous pouvez nous rejoindre sur
Telegram . La prochaine fois, nous traiterons du débordement de tas.