
Le World Wide Web est un océan de données. Ici, vous pouvez voir presque toutes les informations qui vous intéressent. Cependant, «extraire» ces informations d'Internet est déjà plus difficile. Il existe plusieurs façons d'obtenir des données et le web-scraping en fait partie.
Qu'est-ce que le raclage Web? En bref, c'est une technologie qui vous permet de récupérer des données à partir de pages HTML. Lors de l'utilisation du grattage, il n'est pas nécessaire de copier-coller les informations nécessaires ou de les transférer de l'écran vers le bloc-notes. Les informations apparaîtront sur votre ordinateur sous une forme qui vous convient.
Web-scraping sur l'exemple du site Kinopoisk.ru
C’est une bonne idée de vous fixer un objectif afin de ne pas faire de grattage pour le grattage. J'ai décidé que ce serait une comparaison des classements des films sur Kinopoisk.ru et IMDB.com, ainsi que des classements moyens des films par genre . Pour l'analyse, des films ont été tournés et sortis de 2010 à 2018, avec un nombre de votes d'au moins 500.
Pour commencer, chargez les bibliothèques dont nous avons besoin:
# library(rvest) library(selectr) library(xml2) library(jsonlite) library(tidyverse)
Ensuite, j'obtiens le nombre de films dans une année qui remplissent la condition de sélection (plus de 500 votes). Ceci est fait afin de connaître le nombre total de pages contenant des données et de «générer» des liens vers celles-ci, car les liens sont similaires dans leur structure.
# 2018 url <- "https://www.kinopoisk.ru/top/navigator/m_act[year]/2018/m_act[rating]/1%3A/order/rating/page/1/#results"
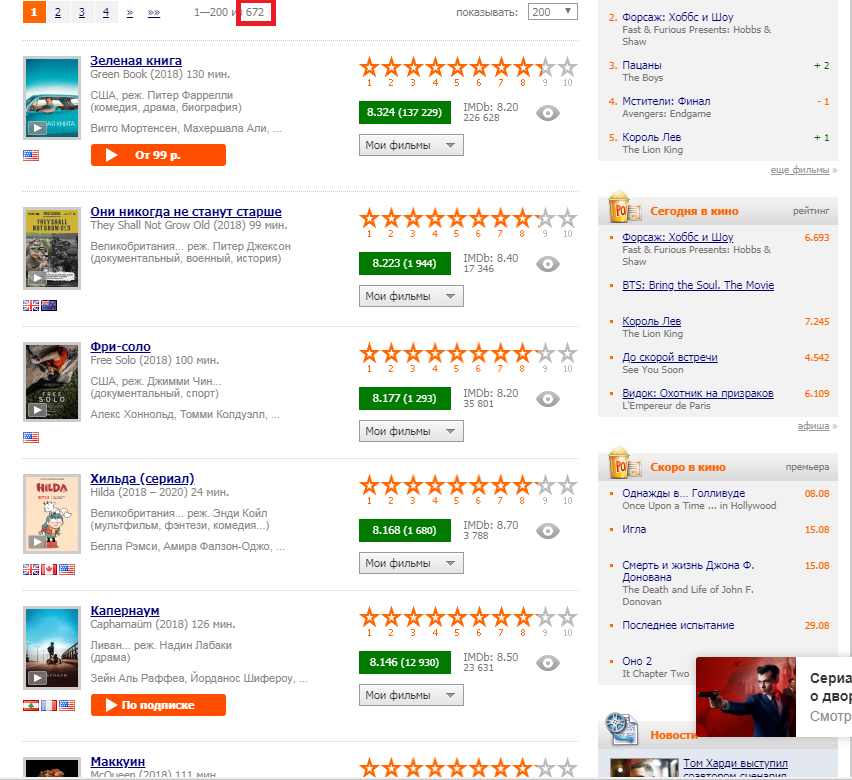
Notre tâche consiste à "retirer" le numéro 672, mis en évidence dans l'image par un rectangle rouge. Pour cela, nous avons besoin de web-scraping.
Pages de grattage du site Kinopoisk.ru à l'aide du package rvest
Nous devons d'abord "lire" l'URL que nous avons reçue. Pour ce faire, utilisez la fonction read_html() du package read_html() .
# XML HTML webpage <- read_html(url)
Et puis, en utilisant les fonctions du paquet rvest nous «extrayons» d'abord la partie du document HTML dont nous avons besoin (la fonction html_nodes() ), puis de cette partie nous extrayons les informations dont nous avons besoin sous une forme qui nous convient (les fonctions html_text() , html_table() , html_attr() autre)
Mais comment comprendre quel élément nous devons extraire? Pour ce faire, nous devons survoler les informations qui nous intéressent, cliquer sur LMB et sélectionner "voir le code". Dans notre cas, nous obtenons l'image suivante:
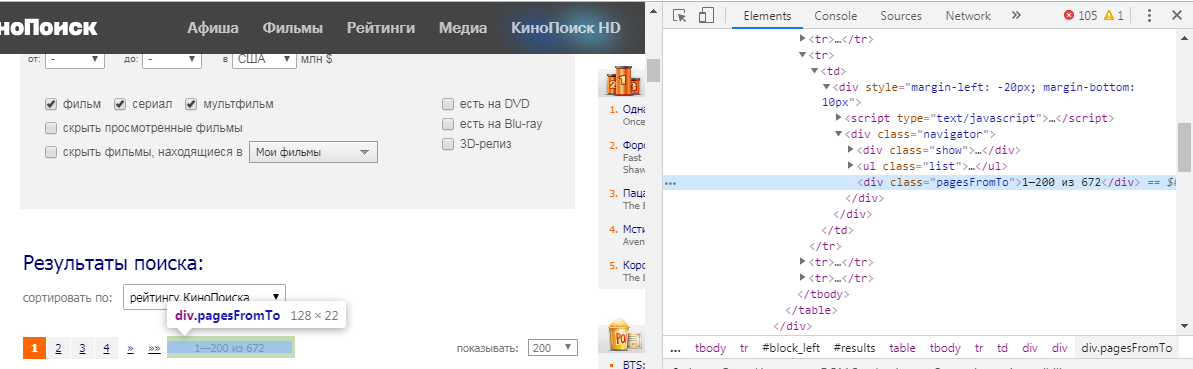
La fonction html_nodes() a la forme html_nodes(x, css) . x est la page Web définie précédemment, mais en css, nous écrivons la classe id ou element. Dans notre cas, c'est:
number_html <- html_nodes(webpage, ".pagesFromTo")
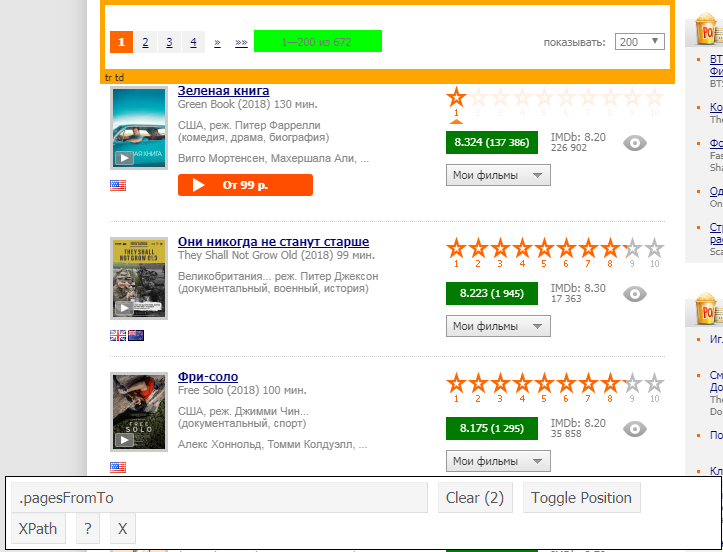
De plus, pour "détecter" l'élément souhaité, vous pouvez utiliser l'extension selectorGadget , qui montre ce que nous devons saisir explicitement:
Ensuite, avec la fonction html_text, nous extrayons la partie texte de l'élément sélectionné:
number <- html_text(number_html) [1] "1—50 672" "1—50 672"
Nous avons obtenu le numéro dont nous avions besoin sur la page HTML de Kinopoisk, mais maintenant nous devons le «vider». Il s'agit d'une procédure standard de raclage, car très rarement nous avons besoin de l'élément dont nous avons besoin sous la forme dont nous avons besoin.
Nous avons obtenu 2 éléments identiques car le nombre total de films est indiqué en haut et en bas de la page et leur sélecteur css est exactement le même. Par conséquent, pour commencer, nous supprimons l'élément en excès:
number <- number[1] [1] "1—50 672"
Ensuite, nous devons nous débarrasser de la partie du vecteur qui va jusqu'au nombre 672. Vous pouvez le faire de différentes manières, mais la base de toutes les méthodes est d'écrire une expression régulière. Dans ce cas, je «remplace» la partie «1-50 de» par un vide (vous pouvez utiliser str_remove au lieu de str_replace ), puis str_trim supprime les espaces supplémentaires (fonction str_trim ) et finalement str_trim traduis le vecteur de caractère en type numérique. J'obtiens le nombre 672. À la sortie, tellement de films de 2018 ont plus de 500 votes d'utilisateurs sur Kinopoisk.
number <- str_replace(number, ".{2,}", "") number <- as.numeric(str_trim(number)) [1] 672
Que faisons-nous ensuite? Si vous parcourez les pages de Kinopoisk, vous verrez que les adresses des pages de recherche ont la même structure et ne diffèrent qu'en nombre. Par conséquent, afin de ne pas saisir manuellement l'adresse de la page à chaque fois, nous allons calculer le nombre de pages et «générer» le nombre requis d'adresses. C'est fait comme ceci:
# page_number <- ceiling(number/50) # page <- sapply(seq(1:page_number), function(n){ list_page <- paste0("https://www.kinopoisk.ru/top/navigator/m_act[year]/2018/m_act[rating]/1%3A/order/rating/page/", n, "/#results") })
La sortie est de 14 adresses. Dans cet exemple, la fonction de ceiling arrondit un nombre à un GRAND entier.
Et puis nous utilisons la fonction lapply à l'entrée dont les adresses des pages sont alimentées, et la fonction "extrait" des informations des pages de Kinopoisk sur le nom, la note, le nombre de votes et les genres principaux (maximum 3) du film. Le code de fonction peut être trouvé dans le référentiel sur Github .
En conséquence, nous obtenons une table avec 8111 films.
Il convient de noter l'utilisation de la fonction Sys.sleep. En l'utilisant, vous pouvez définir le temps de retard entre les expressions. Pourquoi est-ce nécessaire? Si vous souhaitez recevoir des informations sur un an, il n'est pas nécessaire. Mais si vous êtes intéressé par un grand nombre de films / années, après un certain nombre de demandes, Kinopoisk vous considérera comme un robot et vous recevrez une liste vide pour votre demande. Pour éviter cela, vous devez entrer le temps de retard.
De même, "scrap" le site IMDB.com.
Analyse des données
Nous avons deux tableaux, dans une information sur les films avec IMDB, dans l'autre de Kinopoisk. Maintenant, nous devons les combiner. Nous nous unirons selon les colonnes NOM et ANNÉE. Afin de réduire le nombre de divergences dans les noms, même au stade du grattage, j'ai supprimé tous les signes de ponctuation et converti les lettres en minuscules. En conséquence, après toutes les connexions et suppressions, nous obtenons 3450 films qui contiennent les informations dont nous avons besoin sur les deux sites.
Je m'intéresse à la différence dans les notes des films sur deux sites, nous allons donc créer la variable DELTA, qui est la différence entre les estimations de l'IMDB et de Kinopoisk. Si DELTA est positif, alors le score IMDB est plus élevé; s'il est négatif, plus bas.
Construisez d'abord un histogramme pour l'indicateur DELTA:
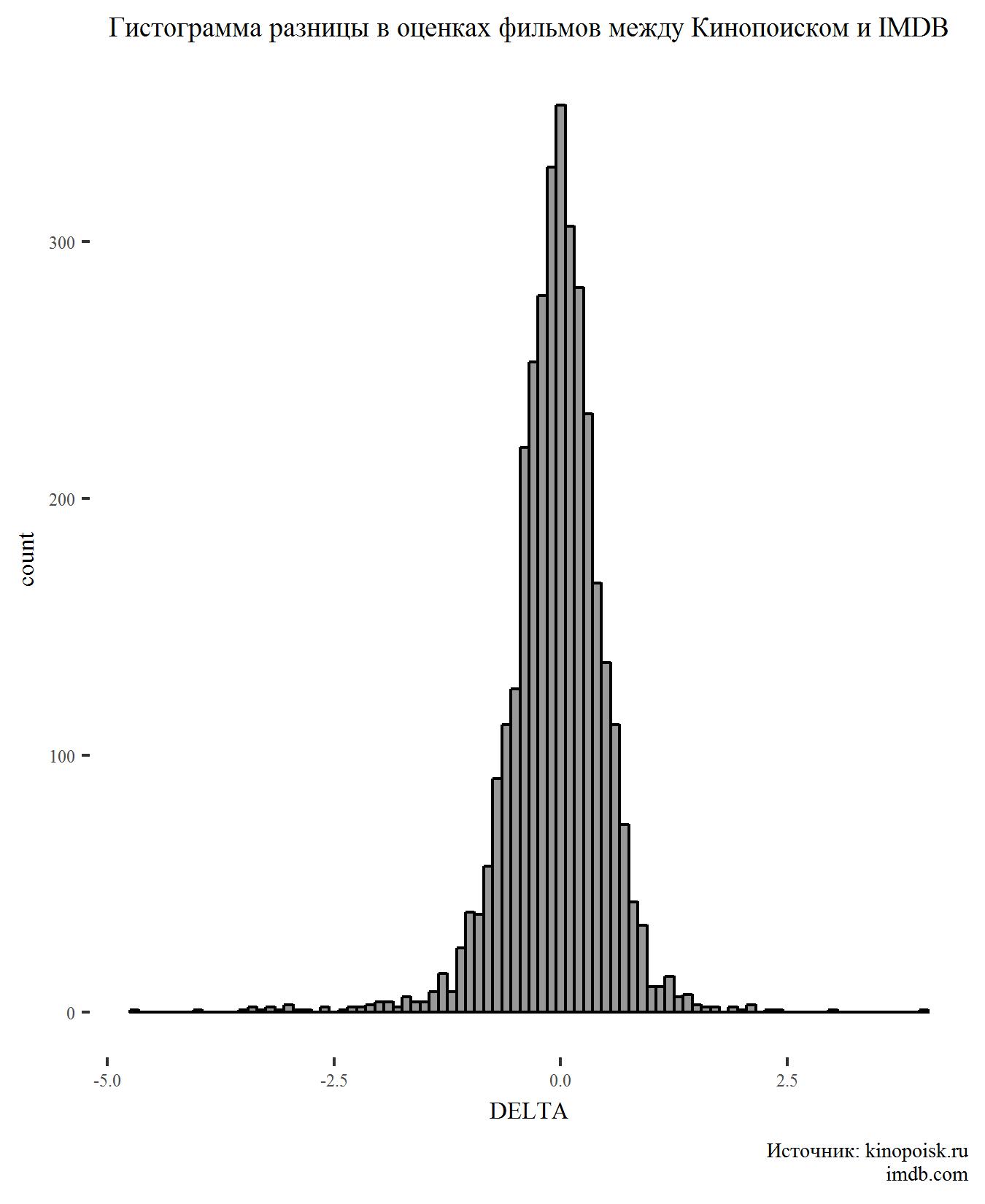
Il n'y a rien de surprenant sur le graphique. La différence de classement a une distribution normale et un pic de l'ordre de zéro, ce qui suggère que les utilisateurs des deux sites sont généralement d'accord sur le classement des films.
Converger, mais pas tout à fait. Le test t de deux échantillons indépendants nous permet de dire que les notes sur Kinopoisk sont plus élevées et cette différence est statistiquement significative (valeur p <0,05).
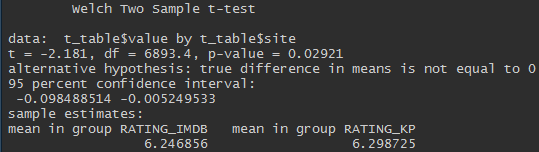
Bien que la différence soit significative, elle est très faible.
Ensuite, voyons comment la différence de notes dépend du nombre de votes.
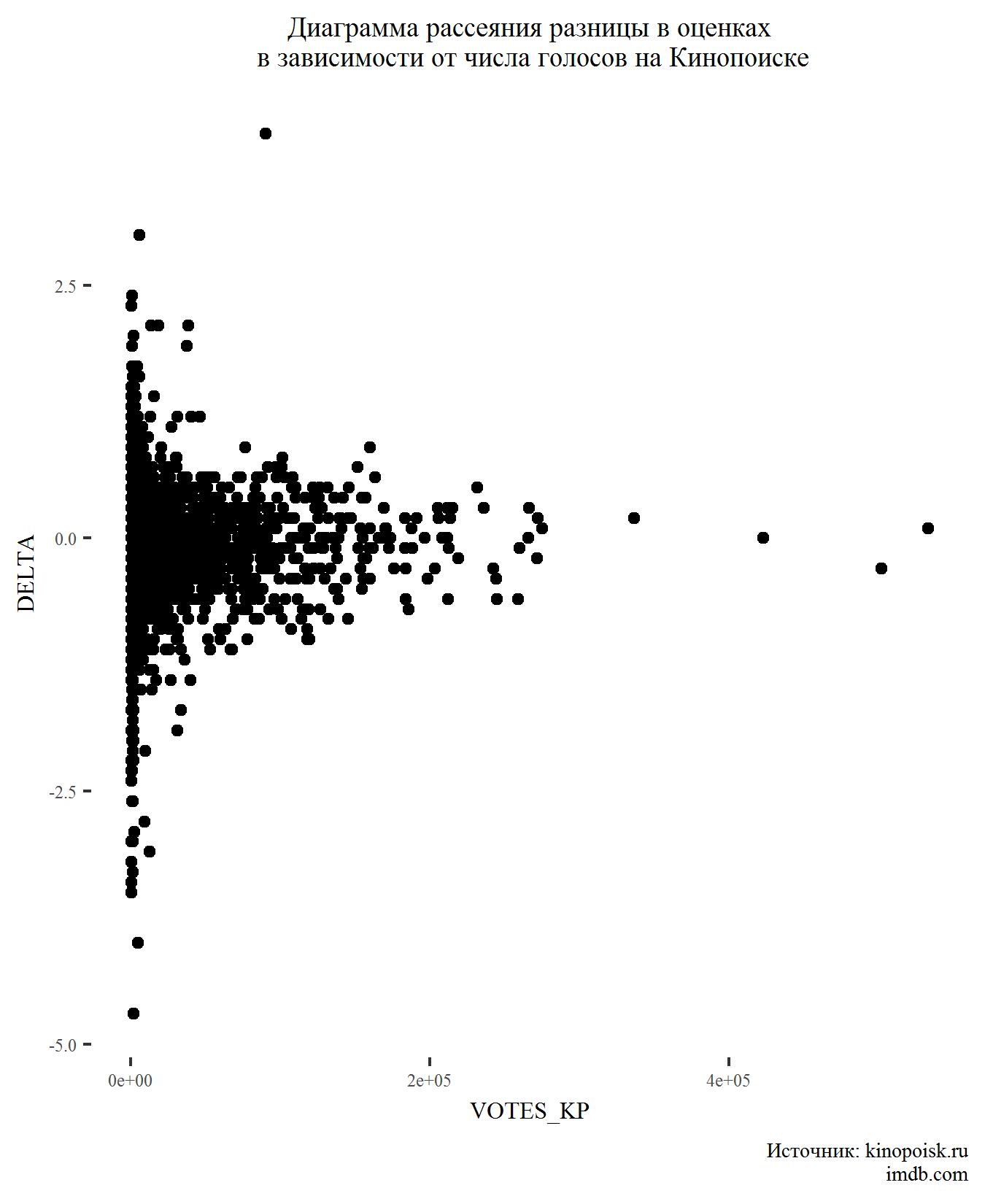
Rien d'inattendu ici non plus. Les films avec un grand nombre de votes ont généralement très peu de différences de cotes.
Passons maintenant à l'évaluation des films par genre. Il convient de noter tout de suite qu'un film peut avoir jusqu'à trois genres, mais une seule note, de sorte qu'un film peut aller "dans le test" et la comédie, et le mélodrame.
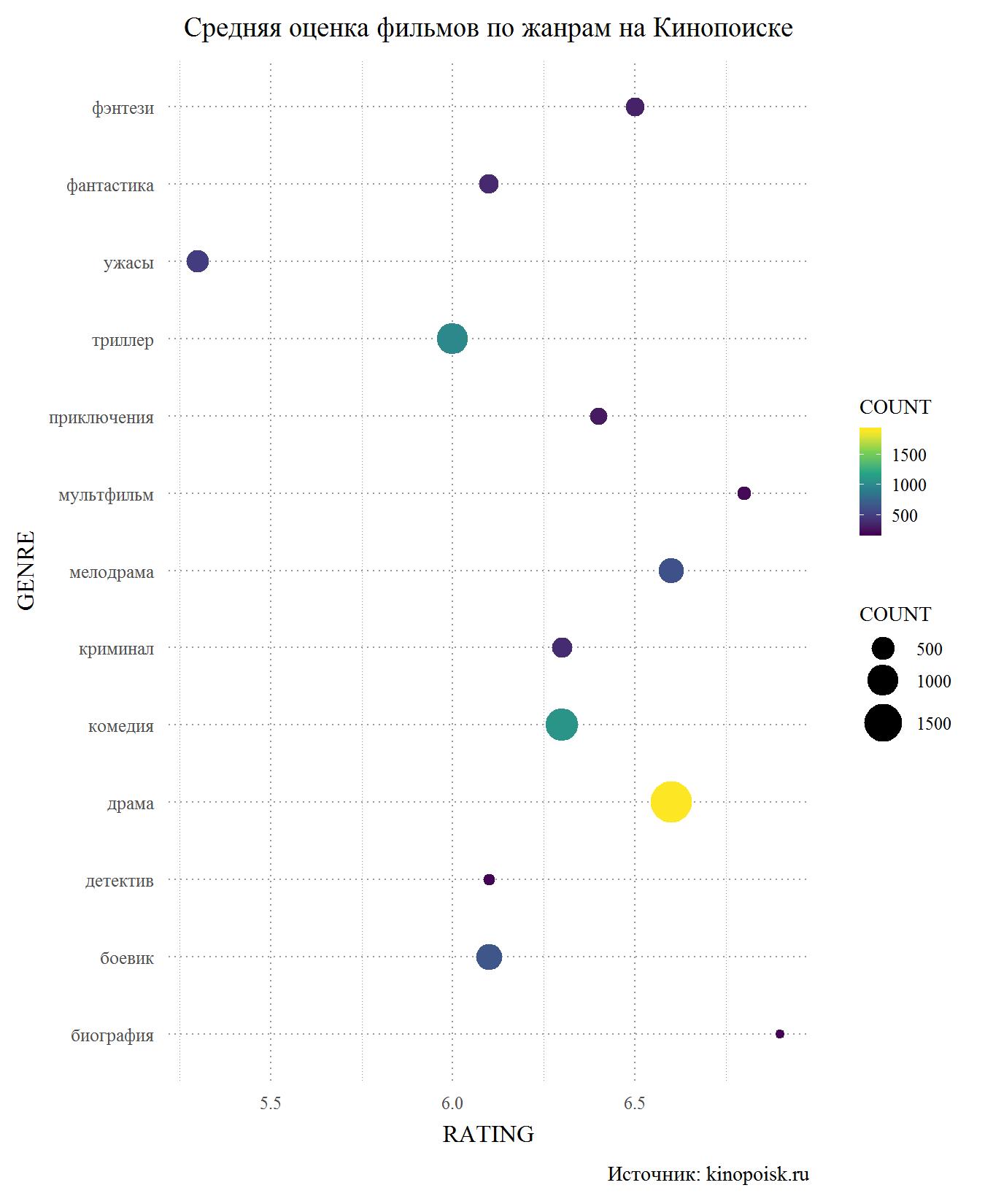
Commençons par Kinopoisk. Parmi les genres avec au moins 150 apparitions dans la base de données, l'horreur est un outsider évident. Les utilisateurs faibles apprécient également les thrillers, les détectives d'action et, ce qui m'a surpris, la science-fiction. D'un autre côté, les films mélodramatiques sur Kinopoisk ont un coup, ayant une note moyenne supérieure à 6,5 et la deuxième seulement aux dessins animés et au biopic, qui sont beaucoup plus petits dans la base de données.
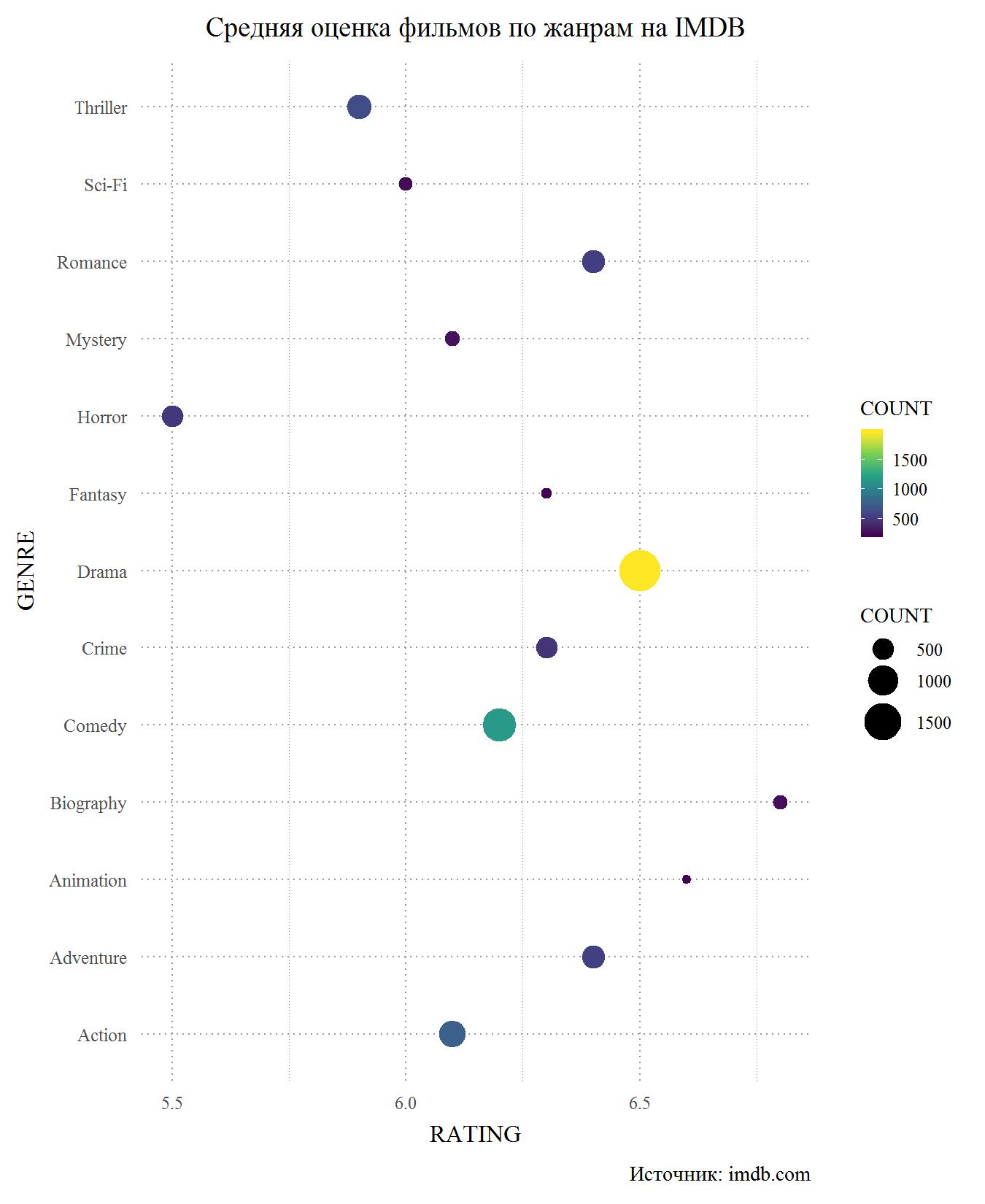
Considérons maintenant le même graphique, mais pour IMDB. En principe, il confirme à nouveau que la différence de notes entre les sites est négligeable. Cela n'est pas surprenant, car de nombreux utilisateurs ont des comptes sur les deux sites et sont peu susceptibles de donner des notes différentes sur différents sites. Encore une fois, le principal perdant est les horreurs, et nous pouvons dire que ce sont les genres de films les moins bien notés. J'ai du mal à comprendre pourquoi cela se produit, car le seul film d'horreur que j'ai vu dans ma vie est Gremlins. Ce sont peut-être les horreurs qui sont le genre à budget le plus bas, d'où le jeu faible des acteurs bon marché et des scénarios franchement mauvais. Les thrillers de science-fiction et sur IMDB sont parmi les retardataires, mais les militants s'en sortent mieux. Parmi les leaders, on retrouve des films biographiques et des dessins animés. Le drame tient la troisième place, mais le score des mélodrames est tombé en dessous de 6,5, au niveau des films d'aventure. Aussi sur IMDB ci-dessous les comédies.
Conclusion et un peu sur les "facteurs externes"
Bien qu'il y ait une différence dans les estimations (sur Kinopoisk, elles sont légèrement plus élevées), mais c'est ça, un peu. Selon les différents genres, la grande différence est également imperceptible. Blockbusters qui ont des dizaines, voire des centaines de milliers de votes, s'ils ont des différences, alors à 0,5 point près.
Les films avec un petit nombre de votes (en particulier sur Kinopoisk), jusqu'à 10 000, ont généralement une grande différence de notes. Cependant, la plus grande différence dans la cote en faveur de l'IMDB est le film avec 30 000 votes sur un site étranger et plus de 90 000 sur Kinopoisk. Il s'agit de la création d'Alexei Pimanov "Crimée". Le film est-il si apprécié des téléspectateurs étrangers? À peine. Très probablement, les cinéastes ont utilisé la même "politique marketing" en ce qui concerne IMDB que dans Kinopoisk. C’est juste que si Kinopoisk «nettoyait» ces estimations, elles restaient sur IMDB. Je pense que c'est la raison pour laquelle «la Crimée» est un «bon petit kinchik».
Je serais reconnaissant pour tous commentaires, suggestions, plaintes
Lien vers le référentiel Github
Profil de mon cercle