Bonjour à tous. Je vais vous parler des microservices, mais d'un point de vue légèrement différent de Vadim Madison dans le post "Que savons-nous des microservices" . En général, je me considère comme un développeur de base de données. Qu'est-ce que les microservices ont à voir avec cela? Avito utilise: Vertica, PostgreSQL, Redis, MongoDB, Tarantool, VoltDB, SQLite ... Au total, nous avons 456+ bases de données pour 849+ services. Et vous devez en quelque sorte vivre avec.
Dans cet article, je vais vous expliquer comment nous avons implémenté la découverte de données dans l'architecture de microservices. Cet article est une transcription gratuite de mon rapport avec Highload ++ 2018 , la vidéo peut être consultée ici .

Tout le monde devrait savoir comment une architecture de microservices doit être construite en termes de bases. Voici le modèle avec lequel tout le monde commence habituellement. Il existe une base commune entre les services. Sur la diapositive, les rectangles orange sont des services, il y a une base commune entre eux.
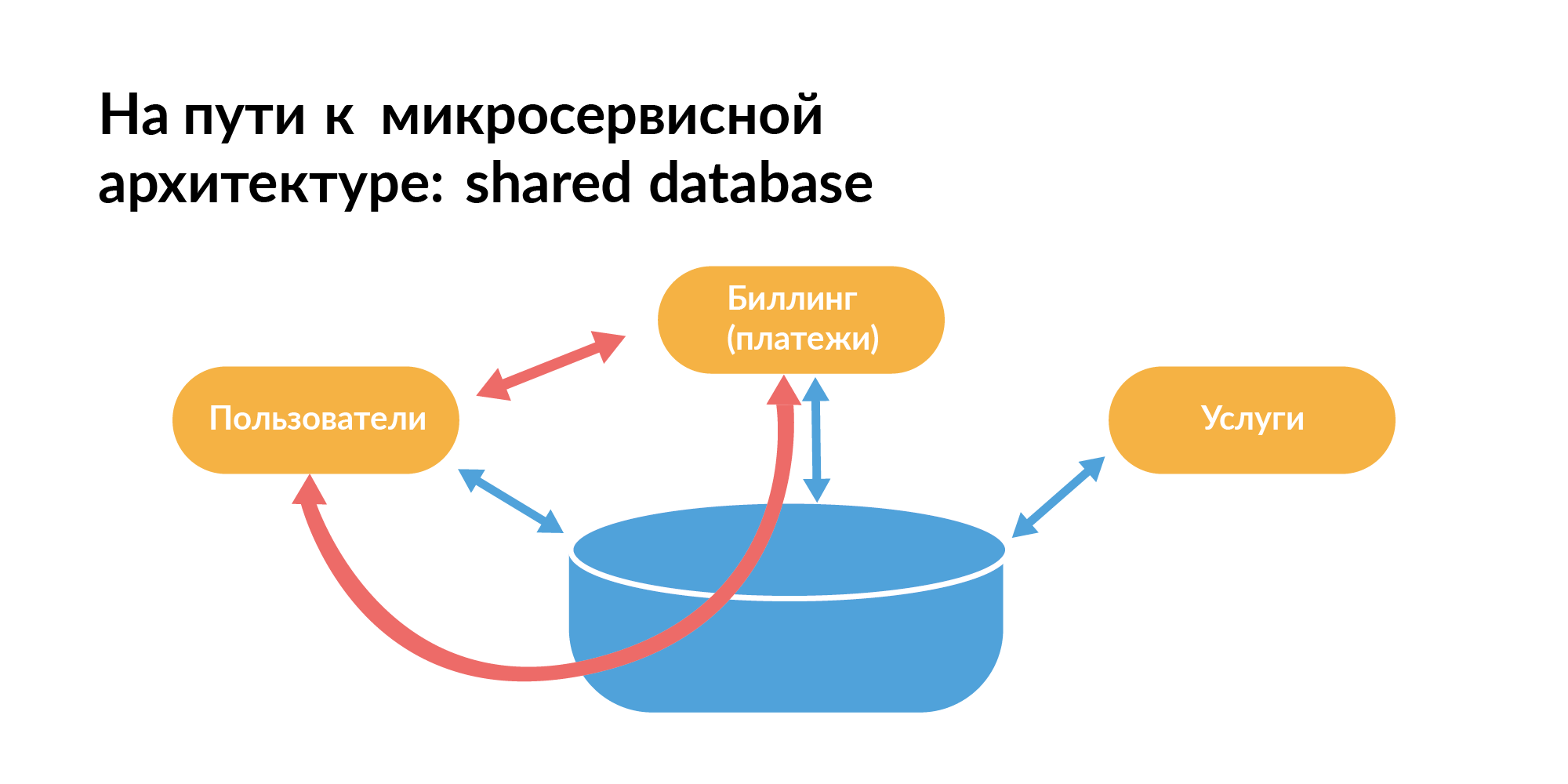
Vous ne pouvez pas vivre comme ça, car vous ne pouvez pas tester les services de manière isolée lorsque, en plus de la communication directe entre eux, il existe également une communication via la base de données. Une demande de service peut ralentir un autre service. C'est mauvais.

Du point de vue de l'utilisation de bases de données pour l'architecture de microservices, le modèle DataBase-per-Service doit être utilisé - chaque service a sa propre base de données. S'il y a beaucoup d'éclats dans la base de données, la base doit être partagée afin qu'ils se synchronisent. C'est une théorie, mais en réalité ce n'est pas le cas.

Dans les entreprises réelles, ils utilisent non seulement des microservices, mais aussi un monolithe. Il y a des services écrits correctement. Et il existe d'anciens services qui utilisent toujours un modèle de base commun.
Vadim Madison lors de sa présentation a montré cette image avec connectivité. Seulement, il l'a montré sans un seul composant, et le réseau était uniforme. Dans ce réseau au centre, il y a un point qui est connecté à de nombreux points (microservices). Ceci est un monolithe. C'est petit dans le diagramme. Mais en fait, le monolithe est grand. Lorsque nous parlons d'une véritable entreprise, vous devez comprendre les nuances de la coexistence d'un microservice, né et sortant, mais d'une architecture monolithique toujours importante.
Comment un monolithe réécrit-il dans une architecture de microservice au niveau de la planification? Bien sûr, c'est la modélisation de domaine. Partout, il est indiqué que vous devez effectuer une modélisation de domaine. Mais, par exemple, chez Avito, nous avons créé pendant plusieurs années des microservices sans modélisation de domaine. Ensuite, je l'ai repris et les développeurs de bases de données. Nous connaissons les flux de données complets. Ces connaissances aident à concevoir un modèle de domaine.

La découverte de données a une interprétation classique - c'est comment travailler avec des données dispersées sur différents stockages afin de conduire à des conclusions agrégées et de tirer des conclusions correctes. Ce sont en fait toutes des conneries marketing. Ces définitions expliquent comment télécharger toutes les données des microservices vers le stockage. À ce sujet, j'ai eu des rapports il y a plusieurs années, nous ne nous attarderons pas là-dessus.
Je vais vous parler d'un autre processus, qui est plus proche du processus de passage aux microservices. Je veux montrer comment vous pouvez comprendre la complexité d'un système en constante évolution en termes de données, en termes de microservices. Où voir l'image complète de centaines de services, bases, équipes, personnes? En fait, cette question est l'idée principale du rapport.

Pour ne pas mourir dans cette architecture de microservices, vous avez besoin d'un jumeau numérique. Votre entreprise est la totalité de tout ce qui fournit l'infrastructure technologique. Vous devez créer une image adéquate de toutes ces difficultés, sur la base de laquelle vous pouvez résoudre rapidement les problèmes. Et ce n'est pas un référentiel analytique.

Quelles tâches pouvons-nous définir pour un tel jumeau numérique? Après tout, tout a commencé avec la découverte de données la plus simple.
Questions:
- Quels services stockent des données importantes?
- Dans quelles données personnelles ne sont pas stockées?
- Vous avez des centaines de bases. Quelles données personnelles existe-t-il? Et dans lequel non?
- Comment les données importantes circulent-elles entre les services?
- Par exemple, le service n'avait pas de données personnelles, puis il a commencé à écouter le bus, et ils sont apparus. Où sont copiées les données lorsqu'elles sont effacées?
- Qui peut travailler avec quelles données?
- Qui peut accéder directement via le service, certains via la base de données, certains via le bus?
- Qui, via un autre service, peut extraire la poignée de l'API (demande) et télécharger quelque chose?
La réponse à ces questions est presque toujours un graphe d'éléments, un graphe de relations. Ce graphique doit être rempli, mis à jour et maintenu avec de nouvelles données. Nous avons décidé d'appeler ce graphe Persistent Fabric (en traduction - souvenir du tissu). Voici sa visualisation.
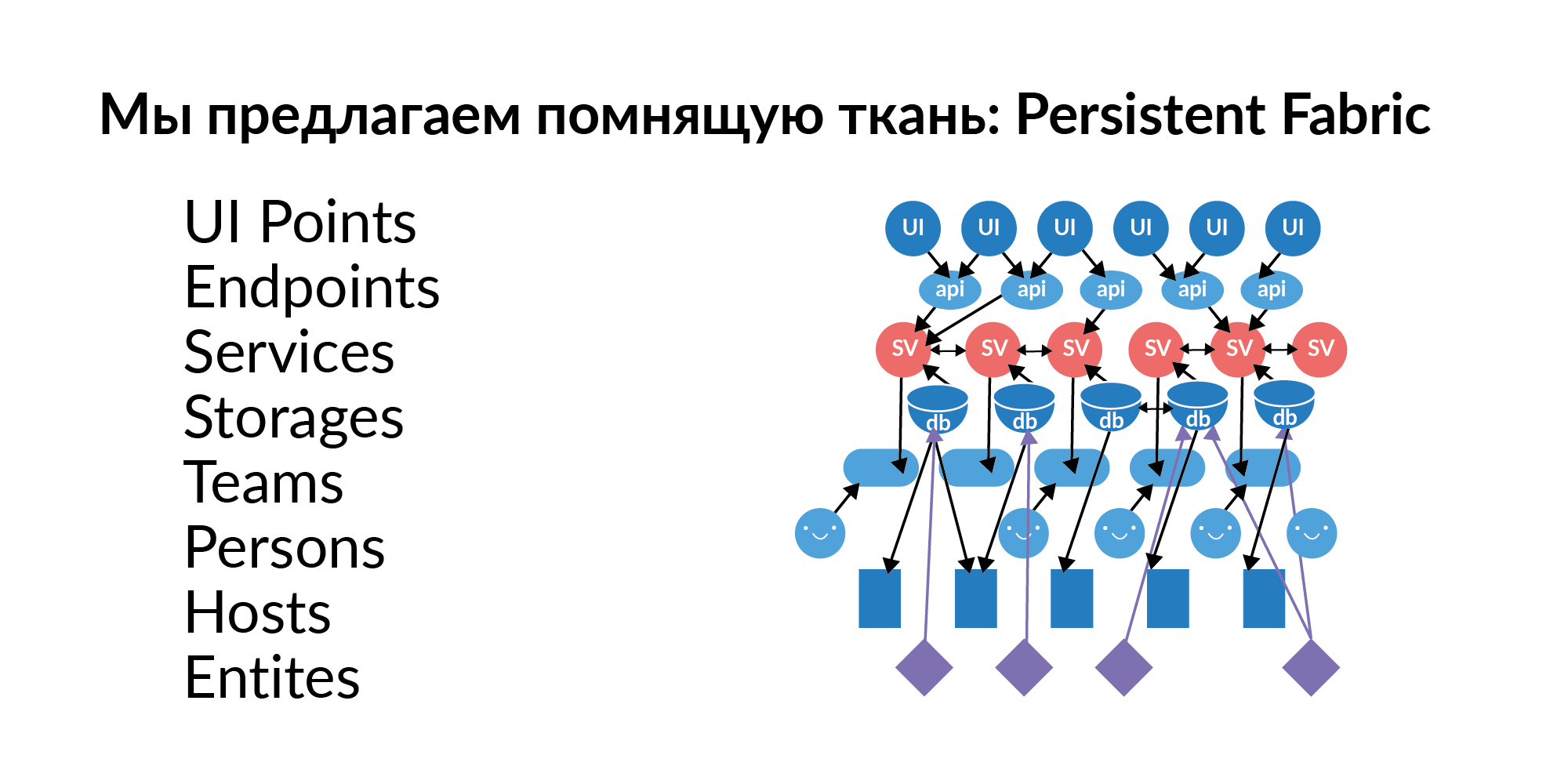
Voyons ce que peut contenir ce tissu de souvenir.
Points d'interface . Ce sont des éléments d'interaction de l'utilisateur avec l'interface graphique. Il peut y avoir plusieurs points d'interface utilisateur sur une seule page. Il s'agit, relativement parlant, d'actions clés personnalisées.
Points de terminaison . Points d'interface jerk Endpoints. Dans la tradition russe, cela s'appelle des stylos. Poignées de services. Les points d'extrémité tirent des services.
Les services Des centaines de services. Les services sont connectés les uns aux autres. Nous comprenons quel service peut tirer le service. Nous comprenons quel appel vers des points d'interface utilisateur peut appeler quels services de la chaîne.
Bases (dans un sens logique) . La base en tant que terme de stockage semble mauvaise, car ce terme fait référence à quelque chose d'analyse. Nous considérons maintenant la base de données comme un stockage. Par exemple, Redis, PostgreSQL, Tarantool. Si un service utilise une base de données, il utilise généralement plusieurs bases de données.
- Pour le stockage de données à long terme, par exemple, PostgreSQL.
- Redis est utilisé comme cache.
- Tarantool, qui peut rapidement calculer quelque chose dans le flux de données.
Hôtes La base de données a un déploiement sur les hôtes. Une base, un Redis peut réellement vivre sur 16 machines (anneau maître) et un autre 16 esclaves vivants. Cela permet de comprendre à quels serveurs vous devez restreindre l'accès afin que certaines données importantes ne fuient pas.
Entités . Les entités sont stockées dans les bases de données. Exemples d'entités: utilisateur, annonce, paiement. Les entités peuvent être stockées dans plusieurs bases de données. Et ici, il est important non seulement de savoir que cette entité est là. Il est important de savoir que cette entité possède un stockage étant Golden Source. Golden Source est la base où une entité est créée et modifiée. Toutes les autres bases sont des caches fonctionnels. Un point important. Si, à Dieu ne plaise, une entité a deux sources d'or, alors une coordination laborieuse des sources séparées est nécessaire. Les entités qui se trouvent dans la base de données doivent avoir accès au service si nous voulons enrichir ce service avec de nouvelles fonctionnalités.
Des équipes . Équipes propriétaires des services. Un service qui n'appartient pas aux équipes est un service médiocre. Il lui est difficile de trouver quelqu'un responsable.
Maintenant, je vais fortement corréler avec le rapport de Vadim Madison, car il a mentionné que la personne qui a été la dernière à s'y engager se reflète dans les services. C'est un bon point de départ. Mais à long terme, c'est mauvais, car la dernière personne qui s'y est engagée peut démissionner.
Par conséquent, vous devez connaître l'équipe, les personnes qui la composent et leur rôle. Nous avons un graphique si simple, où sur chaque couche il y a plusieurs centaines d'éléments. Connaissez-vous un système où tout cela peut être stocké?
Le point clé. Pour que ce tissu persistant vive, il ne doit pas simplement se remplir une fois. Les services sont créés, ils meurent, le stockage est alloué, ils se déplacent sur les serveurs, les équipes sont créées, cassées, les gens passent à d'autres équipes. Les entités sont nouvelles, ajoutées à de nouveaux services, supprimées. Les points de terminaison sont créés, enregistrés, les trajectoires des utilisateurs du point de vue de l'interface graphique sont également refaites. La chose la plus importante n'est pas que vous ayez besoin de le stocker techniquement. La chose la plus importante est de rendre chaque couche de tissu persistant fraîche et à jour. Qu'il est mis à jour.
Je propose de parcourir les couches. Je vais illustrer comment nous procédons. Je vais montrer comment cela peut être fait au niveau des couches individuelles.

Les informations sur l'équipe peuvent être extraites de la structure organisationnelle de 1C. Ici, je veux illustrer que Persistent Fabric n'a pas besoin de remplir l'intégralité du graphique géant pour se remplir. Chaque couche doit être remplie correctement.

Les informations sur les personnes peuvent être extraites de LDAP. Une personne peut jouer différents rôles dans différentes équipes. C'est tout à fait normal. Maintenant, nous avons créé le système Avito People et à partir de là, nous prenons la liaison des personnes aux équipes et à leurs rôles. La chose la plus importante est que de telles données simples vont au moins pour qu'elles conservent des liens vers les extrémités des liens, de sorte que les noms des équipes correspondent aux équipes de la structure organisationnelle 1C.
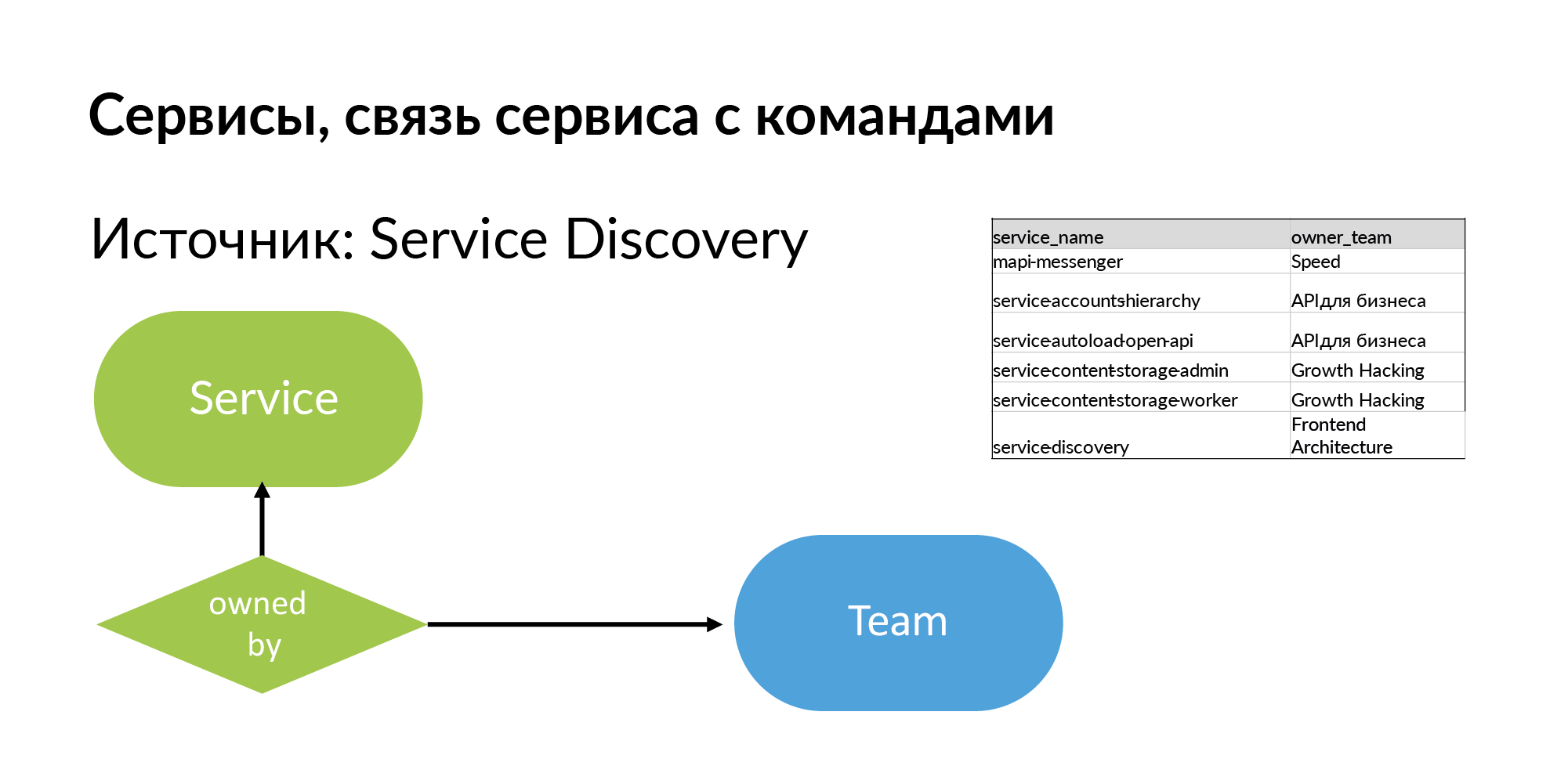
Les services Pour le service, vous devez obtenir le nom et l'équipe qui en est propriétaire. La source est Service Discovery. C'est le système que Vadim Madison a mentionné sous le nom d'Atlas. Atlas est un registre général des services.
Il est utile de comprendre que presque tous ces systèmes comme Atlas stockent des informations sur 95% des services. 5% des services dans ces systèmes sont absents, car anciens services créés sans inscription dans Atlas. Et lorsque vous commencez à travailler avec ce schéma, vous sentez ce qui vous manque.

Les stockages sont des référentiels génériques. Il peut s'agir de PostgreSQL, MongoDB, Memcache, Vertica. Nous avons plusieurs sources pour Storage Discovery. Les bases de données NoSQL utilisent leur propre moitié de l'Atlas. Pour plus d'informations sur les bases de données PostgreSQL, l'analyse par yaml est utilisée. Mais ils veulent rendre leur découverte de stockage plus correcte.
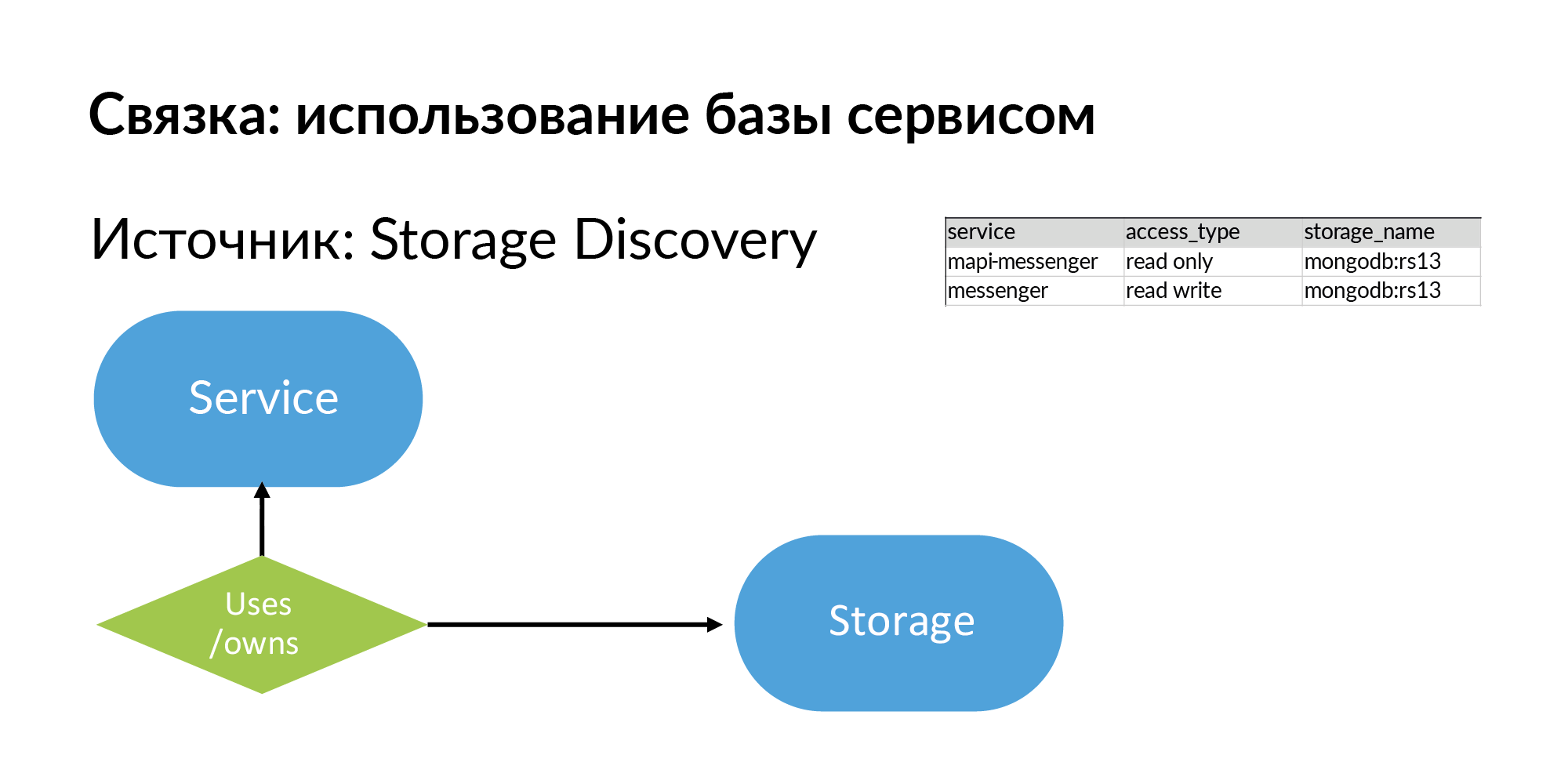
Ainsi, les stockages et les informations sur ce que le service utilise, bien ou possède (ce sont différents types) de stockage. Vous voyez, tout ce que j'ai décrit est, en principe, assez simple, il peut être rempli même dans Google Sheets.
Que peut-on faire avec ça? Imaginons que ce soit un graphique. Comment travailler avec le graphique? Ajoutez-le à la base du graphique. Par exemple, dans Neo4j. Ce sont déjà des exemples de requêtes réelles et des exemples des résultats de ces requêtes.
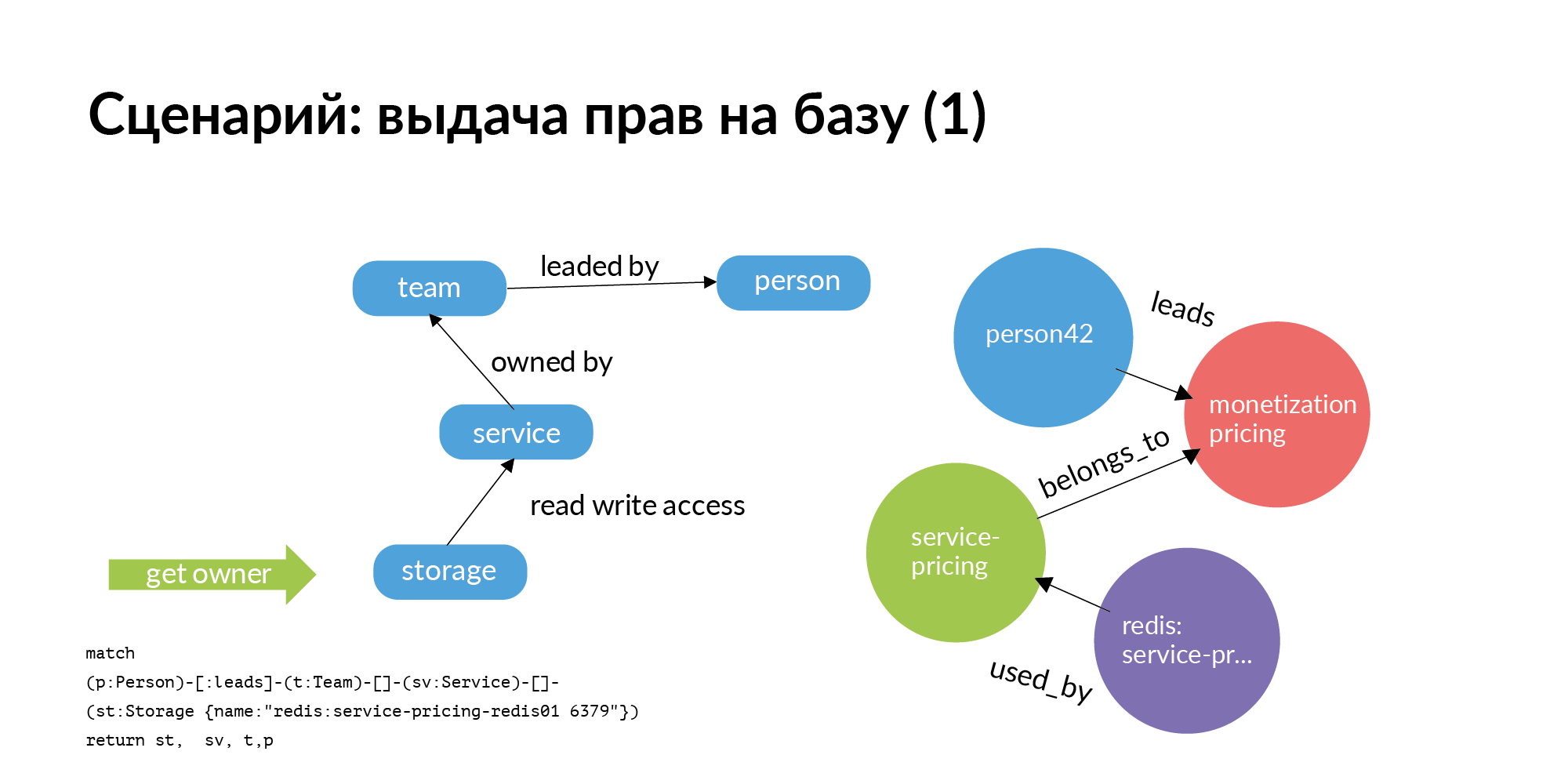
Le premier scénario. Nous devons accorder des droits à la base. La base doit être strictement en service. Il ne doit inclure que ce service et uniquement les membres de l'équipe propriétaire du service. Mais nous vivons dans le monde réel. Très souvent, d'autres équipes trouvent utile de se rendre à la base d'un autre service. Question: à qui s'adresser pour l'octroi de droits? Le très gros problème est que des centaines de bases comprennent qui est en charge. Malgré le fait que celui qui l'a créé, a quitté depuis longtemps, ou a été transféré à un autre poste, ou ne se souvient pas du tout qui travaille avec lui.
Et voici la requête de graphe la plus simple (Neo4j). Vous devez avoir accès au stockage. Vous passez du stockage au service qui en est propriétaire. Accédez à l'équipe propriétaire du service. Plus loin pour le service, vous découvrirez qui a cette équipe TechLead. Chez Avito, les équipes produit ont un responsable technique et un responsable produit qui ne peuvent pas aider avec les bases. Seule la moitié de la demande est réellement affichée sur la diapositive. L'accès au stockage n'est pas une opération atomique. Pour accéder au stockage, vous devez accéder aux serveurs sur lesquels il est installé. Il s'agit d'une tâche distincte plutôt intéressante.
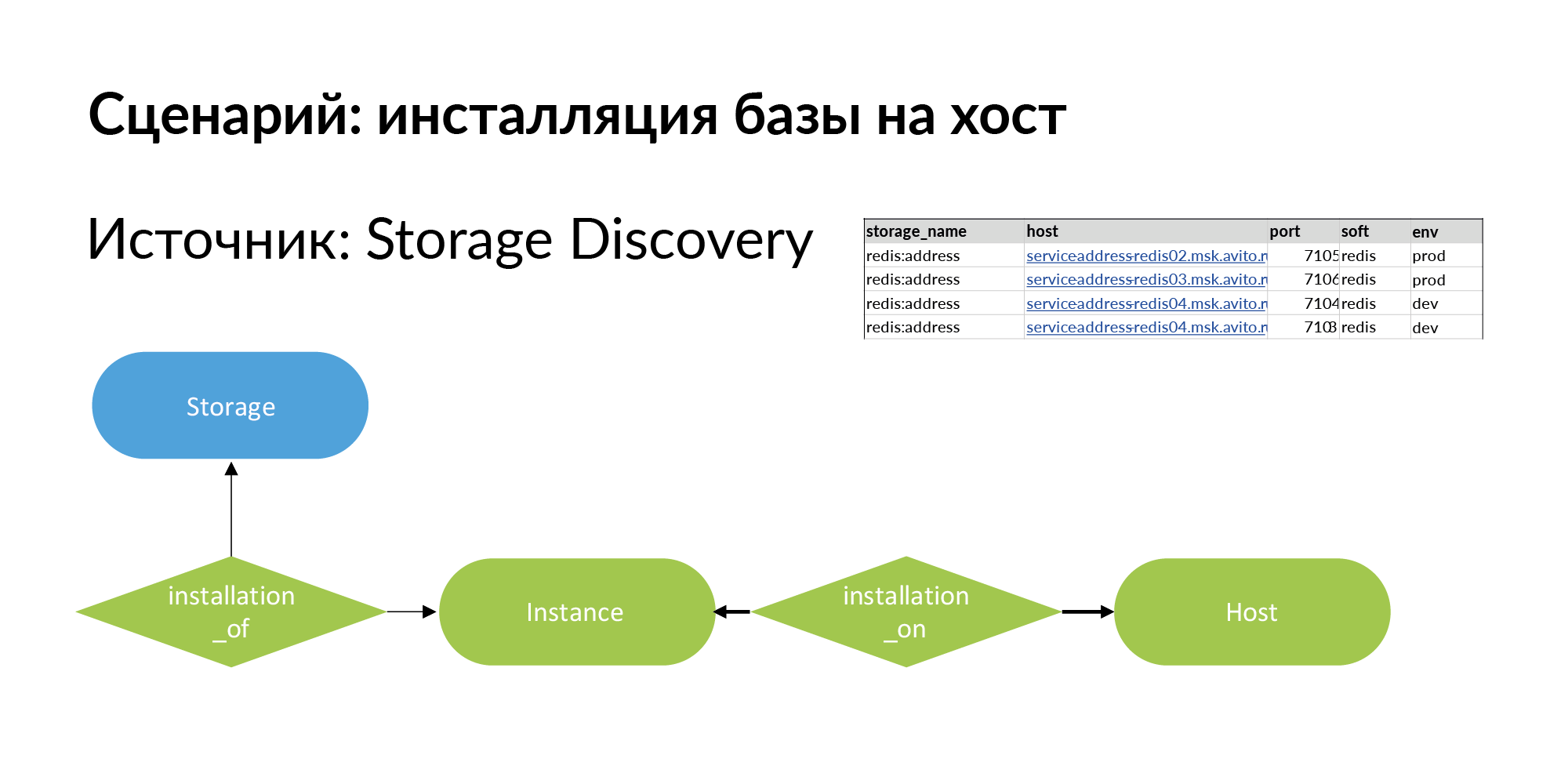
Pour le résoudre, nous ajoutons une nouvelle entité. Ceci est une installation. Voici le problème terminologique. Il y a du stockage, par exemple la base Redis (redis: adresse). Il existe un hôte - il peut s'agir d'une machine physique, d'un conteneur lxc, de kubernetes. Installation de stockage sur l'hôte que nous appelons Instance.
Il peut avoir quatre installations sur trois hôtes, comme illustré dans l'exemple ci-dessus. Le stockage pour la production est judicieux à installer sur des machines physiques distinctes pour augmenter les performances. Pour un environnement de développement, tout ce que vous avez à faire est d'installer sur un hôte et d'attribuer différents ports à Redis.

La première demande d'octroi de droits à la base est allée à la tête. Le chef a confirmé que les droits pouvaient être accordés.
Vient ensuite la deuxième partie de la demande. La deuxième demande du stockage va à l'instance et à l'hôte. Cette demande prend en compte toutes les installations pour l'environnement correspondant. Sur la diapositive est un exemple pour un environnement de production. Sur cette base, les droits de connexion à des hôtes et ports spécifiques sont déjà accordés. Il s'agit d'un exemple de demande de subvention pour un employé ne faisant pas partie de l'équipe.

Prenons un exemple lorsqu'une équipe doit prendre un nouvel employé. Il doit avoir un accès (pour les débutants - en lecture seule) à tous les services, à tout le stockage de cette commande. Sur la diapositive, la vraie équipe avec une sélection incomplète. Les cercles verts sont des chefs d'équipe. Les cercles roses sont des équipes. Les services sont jaunes. Un certain nombre de services jaunes ont un stockage bleu. Les gris sont des hôtes. Violet est l'installation de stockage sur les hôtes. Ceci est un exemple pour une petite unité. Mais il existe de nombreuses unités dont les services ne sont pas 7, mais 27. Pour de telles unités, l'image sera grande. Si vous utilisez Persistent Fabric, vous pouvez y faire des demandes et obtenir des réponses dans une liste.

Continuons à remplir notre tissu intelligent et parlons d'entités commerciales. Les entités dans Avito sont les annonces, les utilisateurs, les paiements, etc. À partir de mes publications ( HP Vertica, conception d'un entrepôt de données, big data , Vertica + Anchor Modeling = commencez à développer votre champignon ) sur les entrepôts de données, vous savez qu'il existe des centaines de ces entités dans Avito. En fait, tous n'ont pas besoin d'être enregistrés. D'où puis-je obtenir une liste des entités? Depuis le référentiel analytique. Vous pouvez télécharger des informations sur l'origine de cette entité. Dans la première étape, cela suffit.
Nous développons ensuite ces connaissances: pour chaque entité, nous établissons une liste de référentiels où elle se trouve. Nous indiquons également que le stockage stocke l'entité en tant que cache ou que le stockage stocke l'entité en tant que Golden Source, c'est-à-dire qu'il s'agit de sa source principale.

Lorsque vous remplissez cette colonne, vous avez la possibilité de faire des demandes. Vous avez une entité et vous devez comprendre: dans quels services l'entité réside-t-elle, où se reflète-t-elle, dans quel stockage, sur quels hôtes est-elle installée? Par exemple, lors du traitement des données personnelles, vous devez détruire les fichiers journaux. Pour ce faire, il est très important de comprendre sur quelles machines physiques les fichiers journaux peuvent rester.
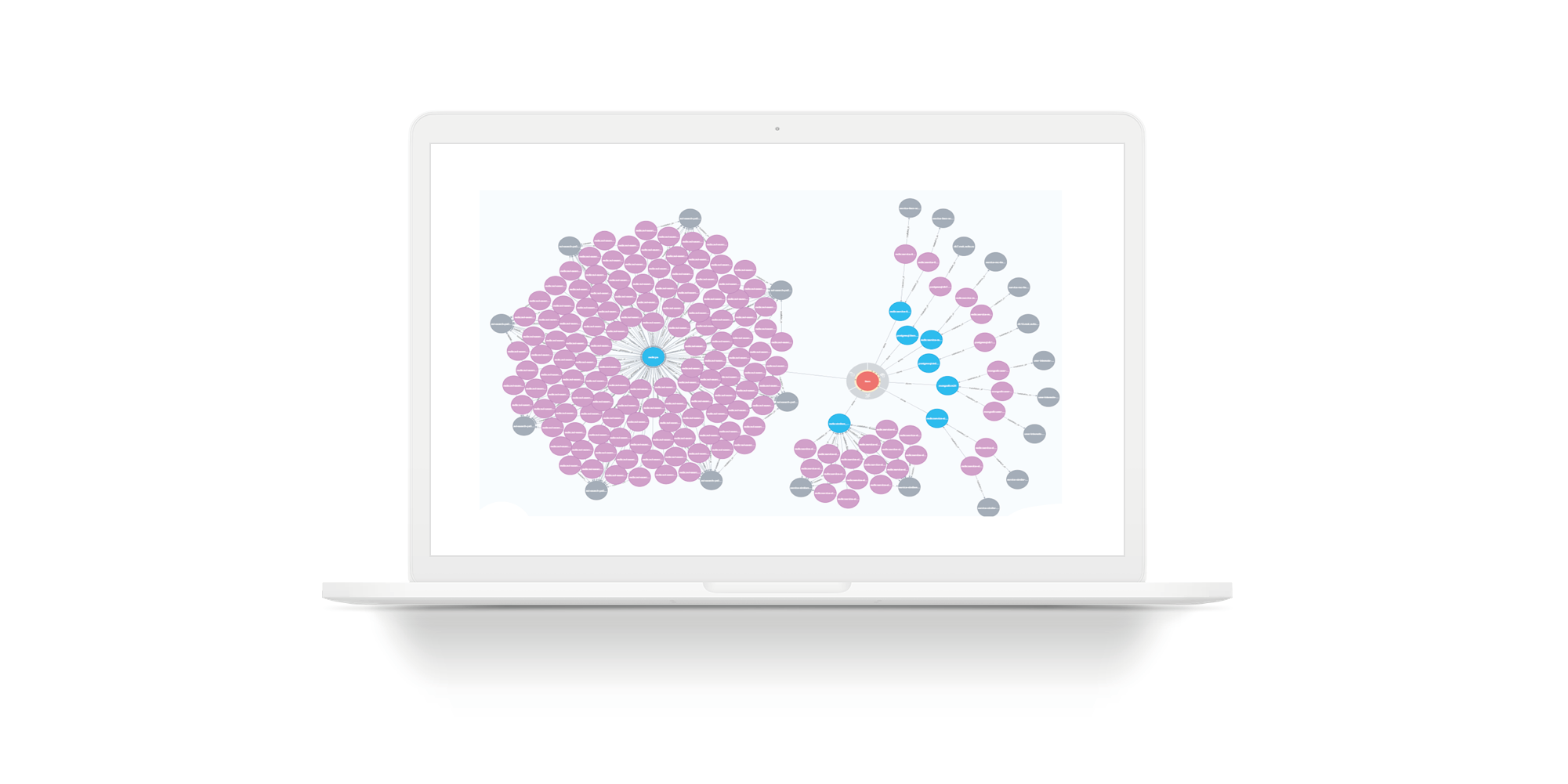
La diapositive illustre une requête simple pour une entité imaginaire. La quantité de stockage est réduite de sorte que le graphique s'adapte sur la diapositive. Les cercles rouges sont des entités. Les cercles bleus sont les bases où se trouve cette entité. Le reste est comme sur les diapositives précédentes: les cercles gris sont des hôtes, les cercles violets sont des installations de stockage sur les hôtes.
Par conséquent, si vous souhaitez passer par PCI DSS, vous devez restreindre l'accès à certaines entités. Pour ce faire, vous devez restreindre l'accès aux cercles gris. Si vous avez besoin d'un accès en temps réel, nous fermons l'accès aux cercles violets. Il s'agit d'informations statiques.
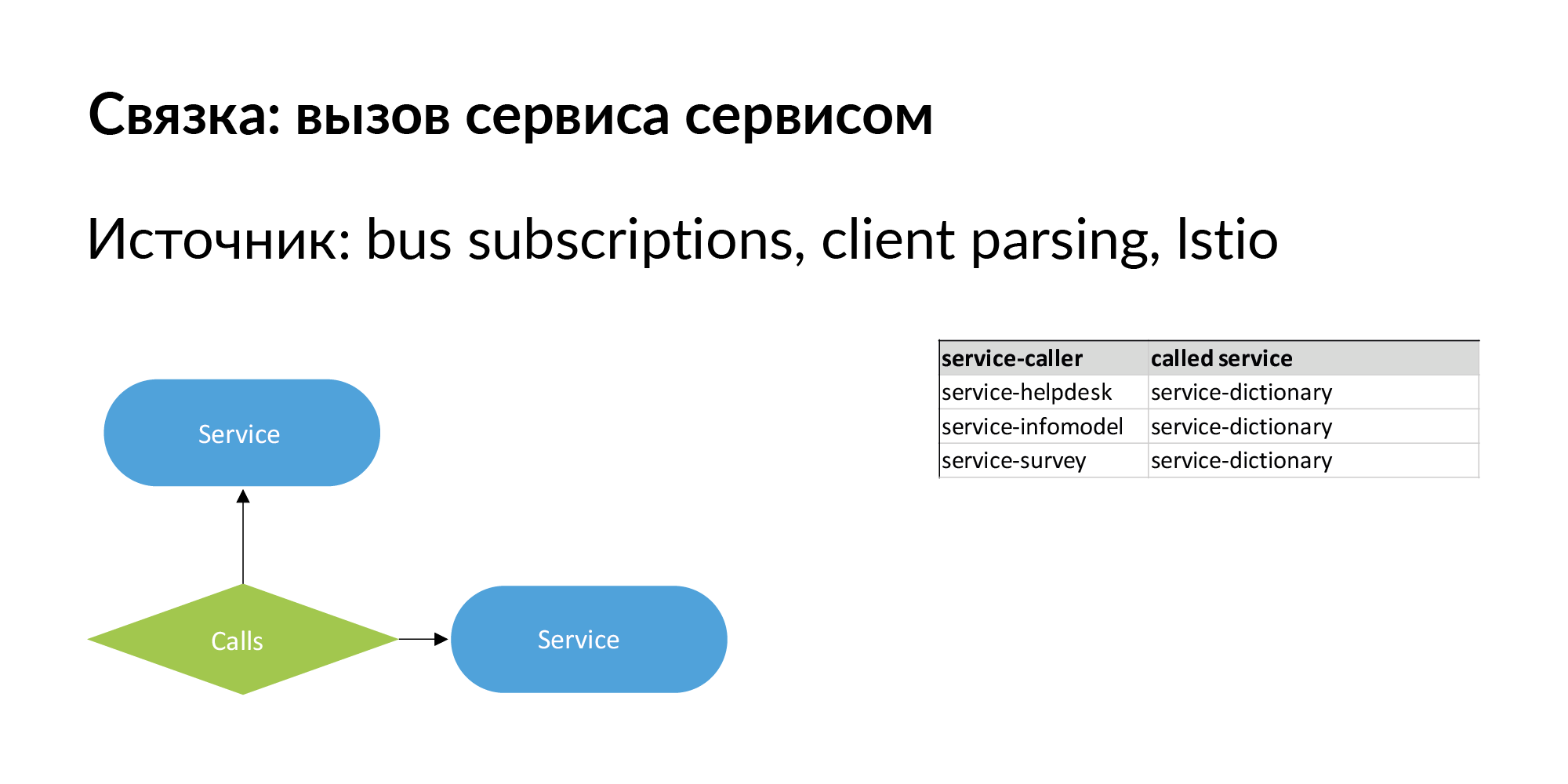
Lorsque nous parlons d'architecture de microservices, la chose la plus importante est qu'elle change. Il est important d'avoir non seulement une relation hiérarchique entre les entités, mais aussi des relations fraternelles. Un ensemble de services est un exemple de connexions à un seul niveau, que nous avons bien pompées et utilisées. Un bundle du formulaire «service appelle service». Il existe des informations sur les appels directs - le service appelle l'API d'un autre service.
Il devrait également y avoir des informations sur la connexion du formulaire: le service n ° 1 envoie des événements au bus (file d'attente), et le service n ° 2 est abonné à cet événement. C'est comme une connexion lente asynchrone passant par un bus. Cette relation est également importante en termes de mouvement de données. À l'aide de ces liens, vous pouvez vérifier le fonctionnement des services si la version du service auquel ils sont abonnés a changé.
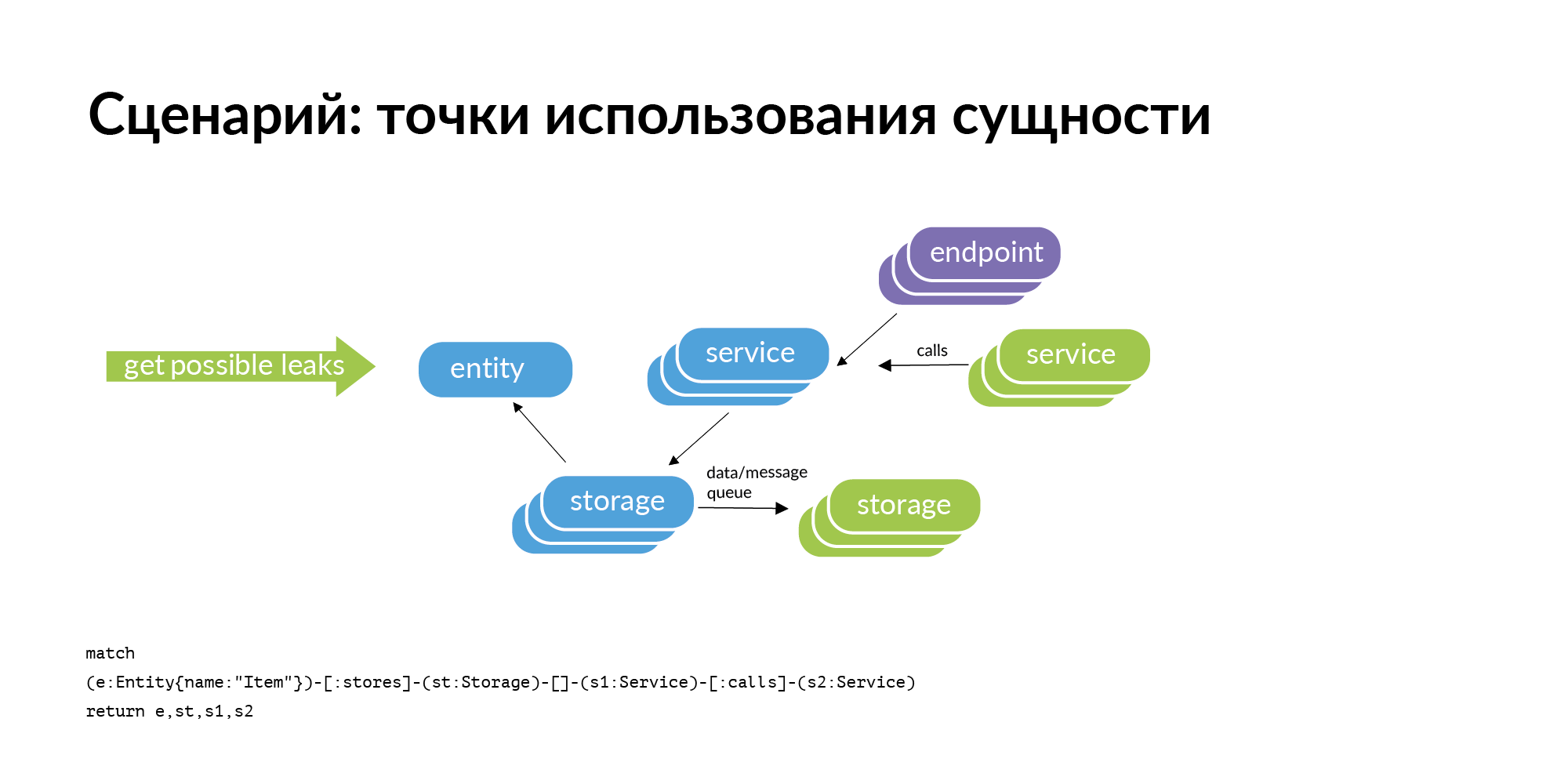
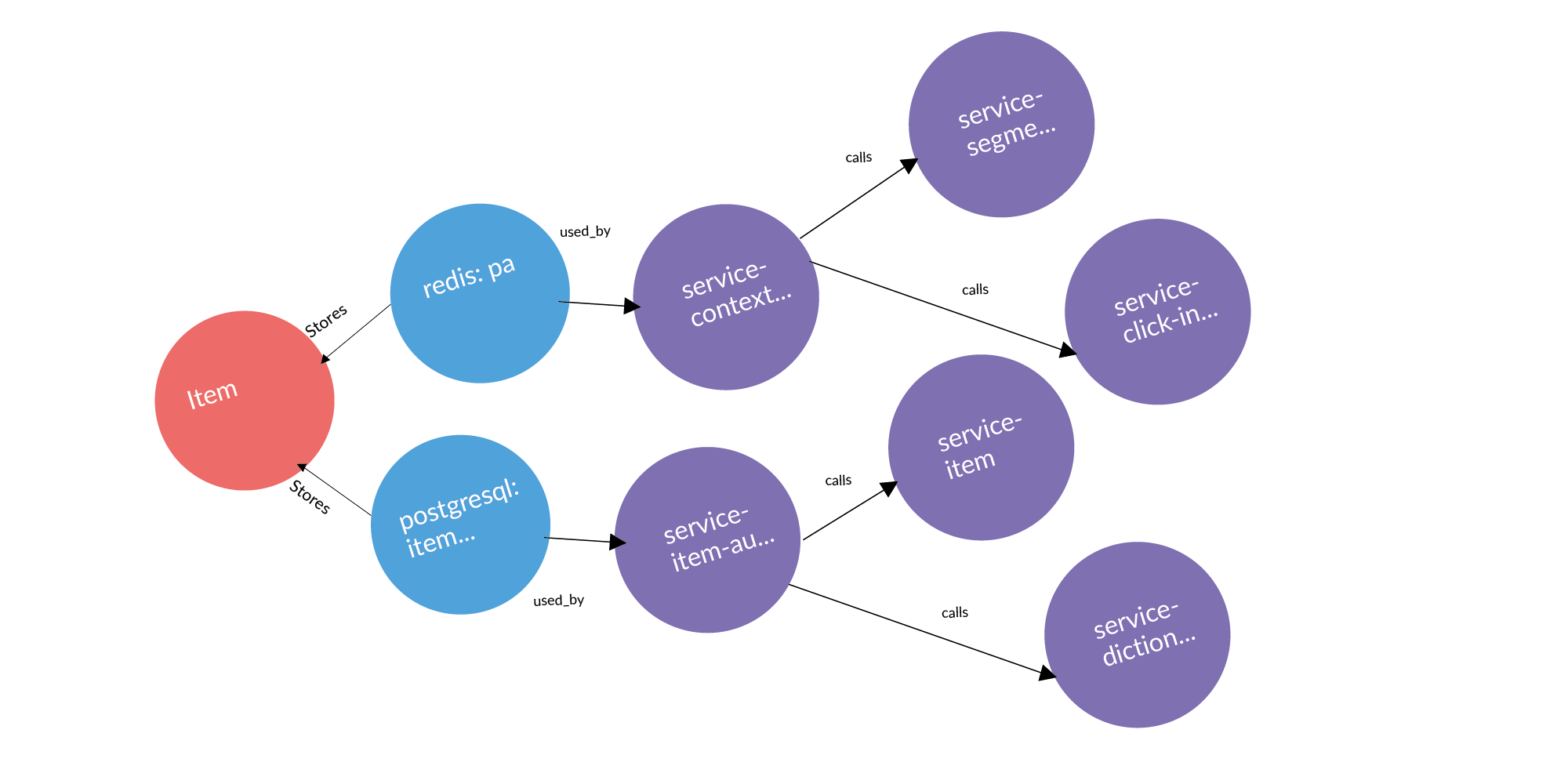
Il existe une entité et nous savons qu'elle est stockée dans un certain stockage. Si nous considérons le problème de trouver des points d'utilisation de l'entité, alors la question évidente qui se pose avec nous est la vérification du périmètre. Le stockage appartient à certains services. Où cette entité peut-elle fuir (être copiée) du périmètre? Il peut fuir lors d'appels de service. Le service a contacté, reçu et retenu l'utilisateur. Il peut fuir à travers les pneus. Les pneus peuvent vous connecter les uns aux autres en utilisant RabbitMQ, Londiste. Sur la diapositive Londiste, nous ne l'avons pas encore chargée. Mais les appels sont déjà chargés.
Voici un exemple de demande réelle: une annonce, deux bases de données où elle est stockée, deux services propriétaires de ces bases de données. Après trois colonnes, les services fonctionnent avec les services propriétaires de cette entité. Ce sont des points de fuite potentiels qui méritent d'être ajoutés.

Points de terminaison. Vadim a mentionné que vous pouvez utiliser la documentation pour créer un registre des services de noeuds finaux. Vous pouvez également obtenir ces informations de la surveillance. Si Endpoint est important, les développeurs eux-mêmes l'ajouteront à la surveillance. Si Endpoint n'est pas surveillé, nous n'en avons pas besoin.
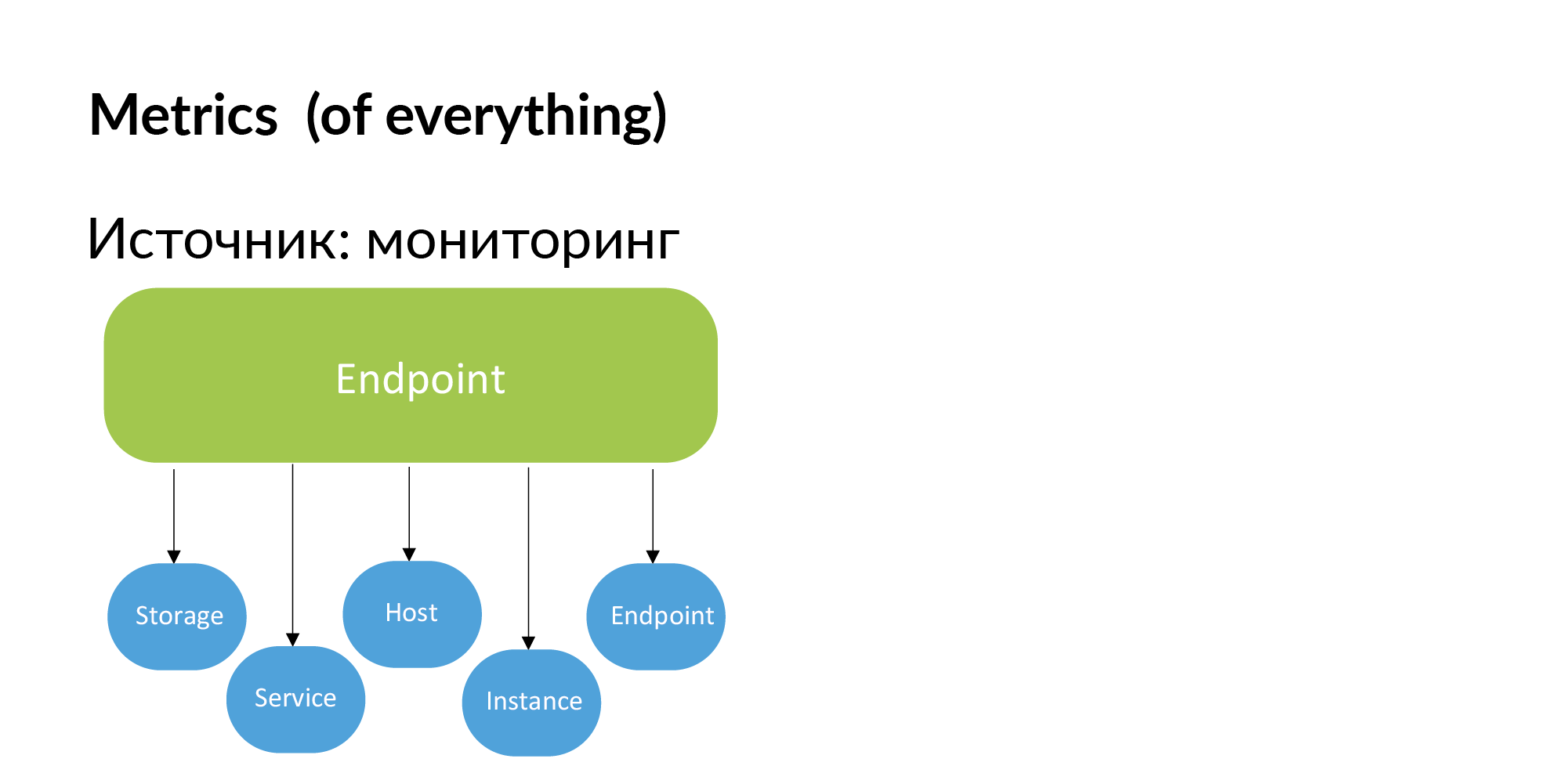
Par conséquent, des mesures peuvent être obtenues à partir de la surveillance. Liaison des métriques au stockage, aux services, aux hôtes, à l'instance (fragments de base de données) et au point de terminaison.

Lorsque vous rencontrez un échec, par exemple, le point de terminaison émet un code HTTP de 500, puis pour suivre la racine du problème, vous devez faire une demande pour ce point de terminaison. Du point de terminaison, accédez au service, accédez aux services que ce service appelle, des services au stockage, du stockage à l'instance et aux hôtes.
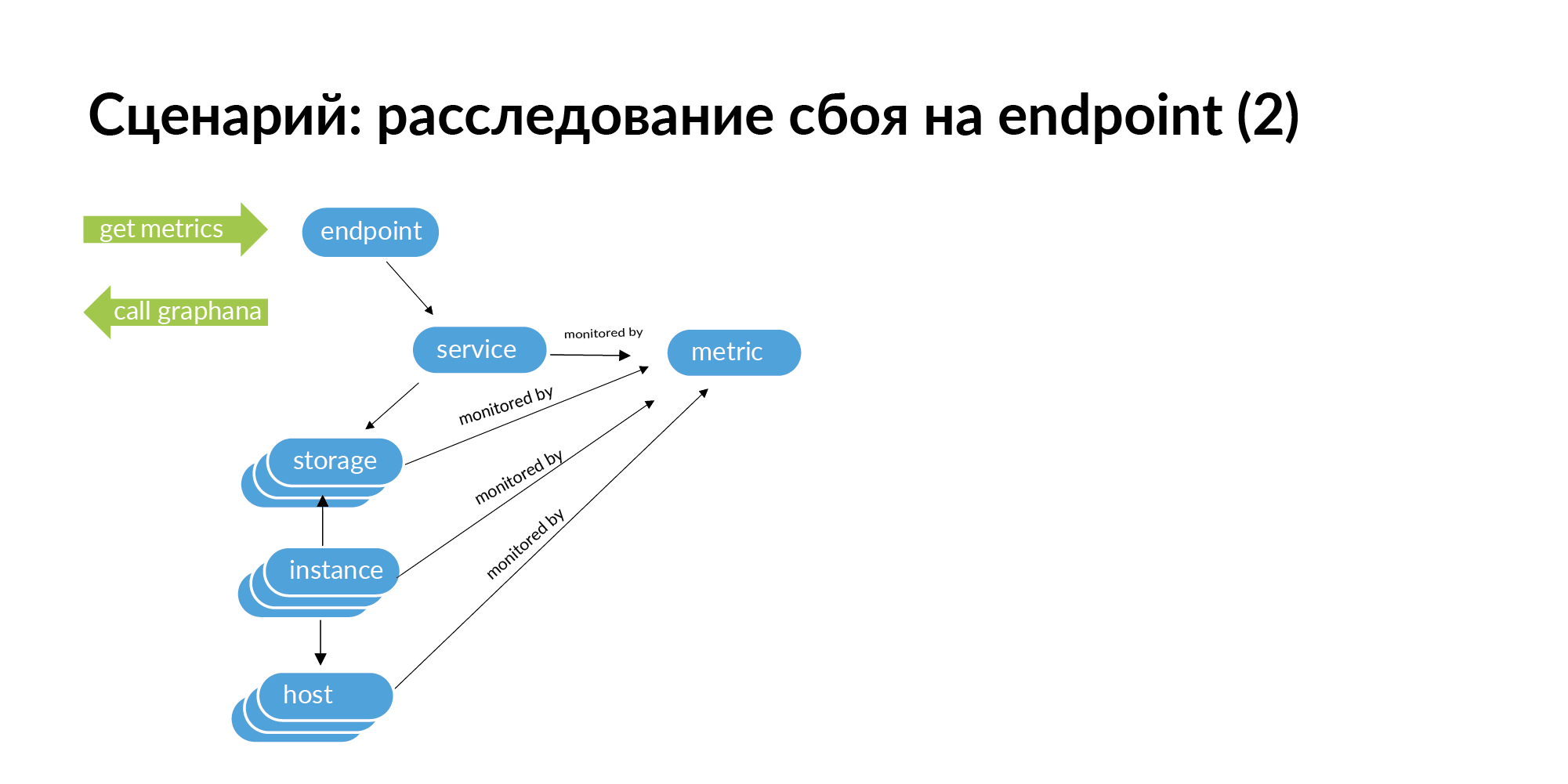
De plus, si vous descendez ce graphique, sur sa base, vous pouvez obtenir une liste d'identifiants à surveiller. Vous pouvez rechercher ce point de terminaison sur toute la chaîne, ce qui peut entraîner une défaillance. Dans l'architecture de microservice, une défaillance au niveau du noeud final peut être provoquée par une défaillance du réseau sur un serveur sur lequel une partition de base de données est déployée. Cela peut être vu dans la surveillance, mais avec une grande structure de services, il est très laborieux de vérifier tous les services dans la surveillance.

Test. Pour tester correctement un microservice, vous devez vérifier le service avec les autres services dont il a besoin pour fonctionner. Vous devez augmenter dans votre environnement de test les services qu'il appelle. Et pour les services appelés, relevez toutes les bases. Dans notre tissu souvenir, nous obtenons un sous-graphique connecté. Dans cette colonne, toutes les connexions ne sont pas nécessaires, certaines peuvent être négligées. Ce sous-graphique peut être testé en charge isolée en tant que système entièrement fermé.
Ce serait formidable maintenant de montrer le graphique d'entité Avito, où des sous-graphiques isolés de microservices qui peuvent être augmentés indépendamment peuvent être testés et déployés en production. En fait, il s'est avéré que le sous-graphique d'appel de presque tous les microservices entre et sort du monolithe. Ceci est une illustration du fait que si vous développez des microservices et ne pensez pas à de telles conséquences, en conséquence, l'architecture de microservices ne fonctionnera toujours pas sans monolithe et ne permettra pas de tests isolés ne le permettra pas.
, . , . . .
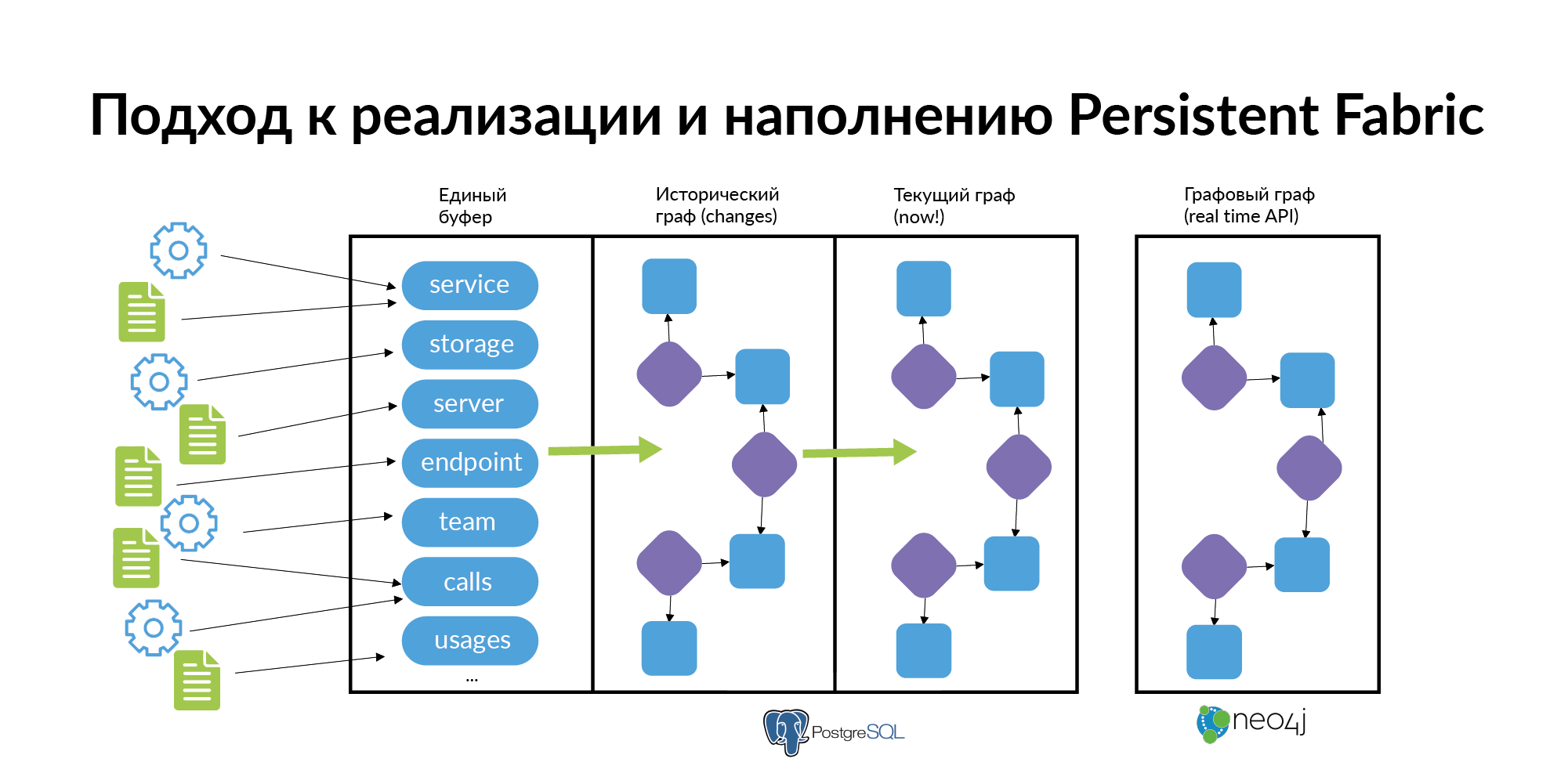
— , . .
- . . . . storage. — . endpoint. , , .. .
- . «» . , , , connection, connection , . , . ( , Anchor Modeling ). . « ». . Neo4j, .
- , . . , UI points frontend , backend , storage DBA, DevOps , .
in-progress
.
(Londiste, PGQ, RabbitMQ).
. UI points . . (Persistent Fabric), UI points, Endpoint, . , , , , .