CleverDATA développe une plate-forme pour travailler avec les mégadonnées. En particulier, sur notre plate-forme, il est possible de travailler avec des informations provenant de contrôles d'achats en ligne. Notre tâche était d'apprendre à traiter les données textuelles des contrôles et à tirer des conclusions sur les consommateurs à leur sujet pour créer les caractéristiques correspondantes sur l'échange de données. Il était naturel d'aborder l'apprentissage automatique pour résoudre ce problème. Dans cet article, nous voulons parler des problèmes que nous avons rencontrés dans la classification des textes des chèques en ligne.
SourceNotre entreprise développe des solutions de monétisation des données. L'un de nos produits est l'échange de données 1DMC, qui vous permet d'enrichir les données de sources externes (plus de 9000 sources, son audience quotidienne est d'environ 100 millions de profils). Les tâches que 1DMC aide à résoudre sont bien connues des spécialistes du marketing: création de segments similaires, sociétés de médias à large assise, campagnes publicitaires ciblées pour un public hautement spécialisé, etc. Si votre comportement est proche de celui du public cible d'un magasin, vous risquez de tomber dans le segment des sosies. Si des informations sur votre dépendance à un domaine d'intérêt ont été enregistrées, vous pouvez vous lancer dans une campagne de publicité ciblée hautement spécialisée. Dans le même temps, toutes les lois sur les données personnelles sont mises en œuvre, vous recevez des publicités plus adaptées à vos intérêts et les entreprises utilisent efficacement leur budget pour attirer des clients.
Les informations sur les profils sont stockées sur l'échange sous la forme de divers attributs interprétés par l'homme:
Il peut s'agir d'informations indiquant qu'une personne possède un équipement moteur, par exemple un hachoir à moto. Ou qu'une personne s'intéresse à la nourriture d'un certain type, par exemple, elle est végétarienne.
Énoncé du problème et moyens de le résoudre
Récemment, 1DMC a reçu des données d'un des opérateurs de données fiscales. Afin de les présenter sous forme d'attributs de profil d'échange, il est devenu nécessaire de travailler avec des textes de contrôle sous forme brute. Voici un texte de contrôle typique pour l'un des clients:
Ainsi, la tâche consiste à faire correspondre la vérification avec les attributs. Attirer l'apprentissage automatique pour résoudre le problème décrit, tout d'abord, il y a un désir d'essayer
des méthodes d'
enseignement sans enseignant (apprentissage non supervisé). L'enseignant est une information sur les bonnes réponses, et comme nous ne disposons pas de cette information, les méthodes d'enseignement sans enseignant pourraient bien convenir au cas à résoudre. Une méthode typique d'enseignement sans enseignant est le clustering, grâce auquel l'échantillon de formation est divisé en groupes ou grappes stables. Dans notre cas, après avoir regroupé les textes en fonction des mots, nous devrons comparer les clusters résultants avec des attributs. Le nombre d'attributs uniques est assez important, il était donc souhaitable d'éviter le balisage manuel. Une autre approche de l'enseignement sans enseignant pour les textes est appelée modélisation de sujet, qui vous permet d'identifier les principaux sujets dans les textes non placés. Après avoir utilisé la modélisation thématique, il sera nécessaire de comparer les sujets obtenus avec des attributs, ce que je voulais également éviter. De plus, il est possible d'utiliser la proximité sémantique entre le texte du chèque et la description textuelle de l'attribut sur la base de n'importe quel modèle de langage. Cependant, les expériences ont montré que la qualité des modèles basés sur la proximité sémantique ne convient pas à nos tâches. D'un point de vue commercial, vous devez être sûr qu'une personne aime le jujitsu et c'est pourquoi elle achète des articles de sport. Il est plus rentable de ne pas utiliser de conclusions intermédiaires, controversées et douteuses. Ainsi, malheureusement, les méthodes d'apprentissage non supervisées ne conviennent pas à la tâche.
Si nous abandonnons les méthodes d'apprentissage non supervisées, il est logique de se tourner vers les méthodes d'apprentissage supervisées et, en particulier, vers la classification. L'enseignant dispose d'informations sur les vraies classes, et une approche typique consiste à effectuer une classification multiclasse, mais dans ce cas, la tâche est compliquée par le fait que nous obtenons trop de classes (par le nombre d'attributs uniques). Il existe une autre caractéristique: les attributs peuvent travailler sur les mêmes textes dans plusieurs groupes, c'est-à-dire la classification doit être multilabel. Par exemple, les informations selon lesquelles une personne a acheté une coque pour smartphone peuvent contenir des attributs tels que: une personne qui possède un appareil comme Samsung avec un téléphone Galaxy, achète les attributs d'une coque Sky Deppa et achète généralement des accessoires pour téléphones. C'est-à-dire que plusieurs attributs d'une personne donnée doivent être enregistrés dans le profil à la fois.
Pour traduire la tâche dans la catégorie "formation avec un enseignant", vous devez obtenir un balisage. Lorsque les gens rencontrent un tel problème, ils engagent des évaluateurs et, en échange d'argent et de temps, obtiennent un bon balisage et construisent des modèles prédictifs à partir du balisage. Ensuite, il s'avère souvent que le balisage était incorrect et que les évaluateurs doivent être connectés pour travailler régulièrement, car de nouveaux attributs et de nouveaux fournisseurs de données apparaissent. Une autre façon consiste à utiliser Yandex. Toloki. " Il vous permet de réduire les coûts pour les évaluateurs, mais ne garantit pas la qualité.
Il y a toujours une option pour trouver une nouvelle approche, et il a été décidé de suivre cette voie. S'il y avait un ensemble de textes pour un attribut, il serait alors possible de construire un modèle de classification binaire. Les textes de chaque attribut peuvent être obtenus à partir des requêtes de recherche, et pour la recherche, vous pouvez utiliser la description textuelle de l'attribut, qui se trouve dans la taxonomie. À ce stade, nous rencontrons la caractéristique suivante: les textes de sortie ne sont pas assez divers pour en construire un modèle solide, et il est logique de recourir à l'augmentation de texte pour obtenir une variété de textes.
Augmentation du texte
Pour l'augmentation de texte, il est logique d'utiliser le modèle de langage. Le résultat du travail du modèle de langage est des plongements - c'est une cartographie de l'espace des mots dans l'espace des vecteurs d'une longueur fixe spécifique, et les vecteurs correspondant aux mots qui ont un sens proche seront situés les uns à côté des autres dans le nouvel espace, et très loin dans le sens. Pour la tâche d'extension de texte, cette propriété est la clé, car dans ce cas, il est nécessaire de rechercher des synonymes. Pour un ensemble aléatoire de mots au nom d'un attribut de taxonomie, nous échantillonnons un sous-ensemble aléatoire d'éléments similaires de l'espace de représentation de texte.
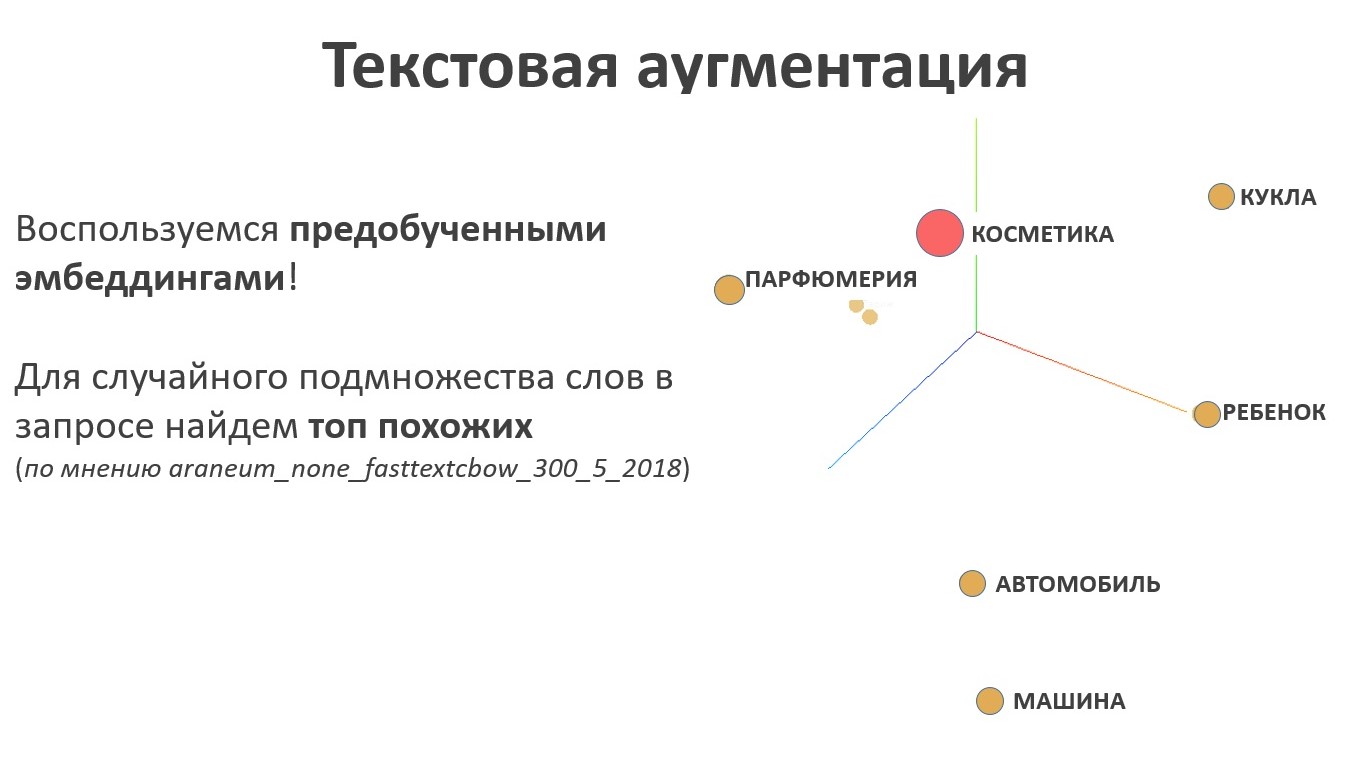
Regardons l'augmentation avec un exemple. Une personne s'intéresse au genre mystique du cinéma. Nous échantillonnons l'échantillon, nous obtenons un ensemble diversifié de textes qui peuvent être envoyés au robot et collecter les résultats de la recherche. Ce sera un échantillon positif pour la formation des classificateurs.
Et nous sélectionnons l'échantillon négatif plus facilement, nous échantillonnons le même nombre d'attributs qui ne sont pas liés au thème du film:
Formation modèle
Lorsque vous utilisez l'approche TF-IDF (par exemple
ici ) avec un filtre par fréquences et régression logistique, vous pouvez déjà obtenir d'excellents résultats: au départ, des textes très différents ont été envoyés au robot, et le modèle s'adapte bien. Bien sûr, il est nécessaire de vérifier le fonctionnement du modèle sur des données réelles, nous présentons ci-dessous le résultat du fonctionnement du modèle selon l'attribut «intérêt à acheter des équipements AEG».
Chaque ligne contient les mots AEG, le modèle fait face sans faux positifs. Cependant, si nous prenons un cas plus compliqué, par exemple une voiture GAZ, nous rencontrerons un problème: le modèle se concentre sur les mots clés et n'utilise pas de contexte.
Gestion des erreurs
Nous nous appuierons sur un modèle d'intérêt pour la formation continue - les cours de recyclage professionnel.
Le cours de leçons de magie pour un chat ordinaire est également un cas difficile, qui peut être trompeur pour une personne.
Pour filtrer les faux positifs, nous utilisons des plongements: nous calculons le centre de l'échantillon positif dans l'espace d'intégration et mesurons la distance à celui-ci pour chaque ligne.
La différence de distance pour les cours de magie et l'acquisition de résumés est visible à l'œil nu.
Un autre exemple: les propriétaires de marques Audi. La distance dans l'espace des plongements dans ce cas permet également d'éviter les faux positifs.
Problème d'évolutivité
À ce jour, l'échange de données exploite environ 30 000 attributs, et de nouveaux apparaissent régulièrement. Le besoin d'automatiser la formation de nouveaux modèles et de baliser avec de nouveaux attributs est assez évident. La séquence d'étapes pour construire un modèle d'un nouvel attribut est la suivante:
- prendre le nom d'attribut de la taxonomie;
- créer une liste de requêtes au moteur de recherche en utilisant l'augmentation de texte;
- sélection du texte kraulim;
- nous formons le modèle de classification sur l'échantillon obtenu;
- disons un modèle formé de données d'achat brutes;
- filtrer le résultat par word2vec au centre de la classe positive.
Il y a un certain nombre de points faibles dans l'algorithme décrit ci-dessus:
- il est difficile de contrôler le corpus de textes qui est accroupi;
- difficile de contrôler la qualité de l'échantillon de formation;
- il n'y a aucun moyen de déterminer si un modèle bien formé fait son travail.
Il est important de comprendre que les métriques classiques ne conviennent pas au contrôle qualité d'un modèle formé, car informations manquantes sur les vraies classes dans les textes de contrôle. L'apprentissage et la prédiction ont lieu sur différentes données, la qualité du modèle peut être mesurée sur un échantillon d'apprentissage et il n'y a pas de balisage sur le corps des principaux textes, ce qui signifie que vous ne pouvez pas utiliser les méthodes habituelles pour évaluer la qualité.
Évaluation de la qualité du modèle
Pour évaluer la qualité du modèle formé, nous prenons deux populations: l'une se réfère aux objets en dessous du seuil de réponse du modèle, la seconde se réfère aux objets sur lesquels le modèle est évalué au-dessus du seuil.
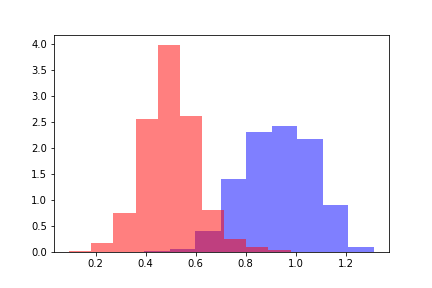
Pour chacune des populations, nous calculons la distance word2vec au centre de l'échantillon d'apprentissage positif. Nous obtenons deux distributions de distance qui ressemblent à ceci.
La couleur rouge indique la distribution des distances pour les objets qui ont franchi le seuil, et le bleu indique les objets en dessous du seuil selon l'évaluation du modèle. Les distributions peuvent être divisées, et pour estimer la distance entre les distributions, il est tout d'abord logique de se référer à la divergence de Kullback-Leibler (DKL). Un DCL est une fonction asymétrique; l'inégalité du triangle n'y est pas satisfaite. Cette restriction complique l'utilisation de DCL en tant que métrique, mais elle peut être utilisée si elle reflète la dépendance nécessaire. Dans notre cas, DCL a supposé des valeurs constantes sur tous les modèles indépendamment des valeurs de seuil, il est donc devenu nécessaire de rechercher d'autres méthodes.
Pour estimer les distances entre les distributions, nous calculons la différence entre les valeurs moyennes des distributions. La différence qui en résulte est mesurable dans les écarts-types de la distribution initiale des distances. Notons la valeur obtenue par la métrique Z par analogie avec la valeur Z, et la valeur de la métrique Z sera fonction de la valeur seuil du modèle prédictif. Pour chaque seuil fixe du modèle, la fonction métrique Z renvoie la différence entre les distributions en sigma de la distribution de distance initiale.
Parmi les nombreuses approches testées, c'est la métrique Z qui a donné la dépendance nécessaire pour déterminer la qualité du modèle construit.
Considérez le comportement de la métrique Z: plus la métrique Z est grande, meilleur est le modèle, car plus la distance entre les distributions caractérise la classification qualitative. Cependant, aucune règle de décision clairement définie pour déterminer la classification qualitative n'a pu être dérivée. Par exemple, un modèle avec une métrique Z dans le coin inférieur gauche de la figure obtient une valeur constante égale à 10. Ce modèle détermine l'intérêt de voyager en Thaïlande. L'échantillon de formation a été principalement annoncé par divers spas et le modèle a été formé sur des textes qui n'étaient pas directement liés aux voyages en Thaïlande. Autrement dit, le modèle a bien fonctionné, mais il ne reflète pas l'intérêt pour les voyages en Thaïlande.
Z-metic pour un certain nombre de modèles prédictifs. Les modèles dans la moitié droite de l'image sont bons et les cinq modèles dans la moitié gauche sont mauvais.Au cours des recherches et expérimentations, 160 modèles avec balisage selon le critère «bon / mauvais» se sont accumulés. Sur la base des signes de la métrique z, un méta-modèle basé sur l'augmentation du gradient a été construit qui détermine la qualité du modèle construit. Ainsi, il a été possible de configurer la surveillance de la qualité des modèles construits en mode automatique.
Résumé
Pour le moment, la séquence d'actions est la suivante:
- prendre le nom d'attribut de la taxonomie;
- créer une liste de requêtes au moteur de recherche en utilisant l'augmentation de texte;
- sélection du texte kraulim;
- nous formons le modèle de classification sur l'échantillon obtenu;
- disons un modèle formé de données d'achat brutes;
- nous filtrons le résultat par word2vec la distance au centre de la classe positive;
- nous calculons la métrique Z et construisons des signes pour le méta-modèle;
- nous utilisons un méta-modèle et évaluons la qualité du modèle résultant;
- si le modèle est de qualité acceptable, il est ajouté à l'ensemble des modèles utilisés. Sinon, le modèle retourne pour révision.
Selon l'évaluation du méta-modèle en mode automatique, il est décidé de l'introduire en production ou de revenir en révision. Le raffinement est possible de diverses manières qui ont été dérivées pour l'analyste.
- Souvent, les modèles gênent certains mots qui ont plusieurs sens. Une liste noire de mots trompeurs facilite l'utilisation du modèle.
- Une autre approche consiste à créer une règle pour exclure des objets de l'ensemble d'apprentissage. Cette approche est utile si la première méthode ne fonctionne pas.
- Pour les textes complexes et les attributs à valeurs multiples, un dictionnaire spécifique est transféré au modèle, ce qui limite le modèle, mais vous permet de contrôler les erreurs.
Mais qu'en est-il des réseaux de neurones?
Tout d'abord, il y avait un désir d'utiliser des réseaux de neurones pour la tâche décrite. Par exemple, on pourrait former Transformer sur un grand corps de textes, puis effectuer un transfert d'apprentissage sur un ensemble de petits exemples d'apprentissage de chaque attribut. Malheureusement, l'utilisation d'un tel réseau de neurones a dû être abandonnée pour les raisons suivantes.
- Si le modèle d'un attribut cesse de fonctionner correctement, il est nécessaire de pouvoir le désactiver sans perte pour les attributs restants.
- Si le modèle ne fonctionne pas bien pour un attribut, il est nécessaire de régler et de régler le modèle de manière isolée, sans risque de gâcher le résultat pour d'autres attributs.
- Lorsqu'un nouvel attribut apparaît, vous devez obtenir un modèle pour celui-ci dès que possible, sans formation à long terme de tous les modèles (ou d'un grand modèle).
- La résolution du problème de contrôle qualité pour un attribut est plus rapide et plus facile que la résolution du problème de contrôle qualité pour tous les attributs à la fois. Si un grand modèle ne fait pas face à l'un des attributs, vous devrez régler et ajuster l'ensemble du grand modèle, ce qui nécessite plus de temps et d'attention d'un spécialiste.
Ainsi, un ensemble de petits modèles indépendants pour résoudre le problème s'est avéré plus pratique qu'un modèle grand et complexe. De plus, le modèle de langage et les incorporations sont toujours utilisés pour le contrôle de la qualité et l'augmentation de texte, il n'était donc pas possible de s'éloigner complètement de l'utilisation des réseaux de neurones, et il n'y avait pas un tel objectif. L'utilisation des réseaux de neurones est limitée aux tâches dans lesquelles ils sont nécessaires.
À suivre
Le travail sur le projet se poursuit: il est nécessaire d'organiser le suivi, la mise à jour des modèles, le traitement des anomalies, etc. L'un des domaines prioritaires à développer est la tâche de collecter et d'analyser les cas qui n'ont été classés par aucun modèle de l'ensemble. Néanmoins, déjà maintenant, nous voyons les résultats de notre travail: environ 60% des vérifications après application des modèles reçoivent leurs attributs. De toute évidence, il existe une proportion importante de chèques qui ne contiennent pas d'informations sur les intérêts des propriétaires, de sorte qu'un niveau de propriété exclusive est inaccessible. Néanmoins, il est encourageant de constater que le résultat obtenu jusqu'ici dépasse déjà nos attentes et nous continuons à travailler dans ce sens.
Cet article a été co-écrit avec
samy1010 .
Et des métiers traditionnels!