L'idée de l'article est née spontanément d'une discussion dans les commentaires sur l'article
«Quelque chose sur l'inode» .
Le fait est que les spécificités internes de nos services sont le stockage d'un grand nombre de petits fichiers. À l'heure actuelle, nous avons environ des centaines de téraoctets de ces données. Et nous sommes tombés sur des râteaux évidents et peu marquants et nous avons marché avec succès dessus.
Par conséquent, je partage notre expérience, peut-être que quelqu'un vous sera utile.
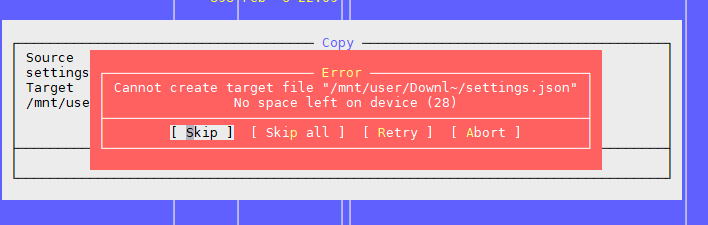
Problème 1: «Il n'y a plus d'espace sur l'appareil»
Comme mentionné dans l'article ci-dessus, le problème est qu'il y a des blocs libres sur le système de fichiers, mais l'inode est terminé.
Vous pouvez vérifier le nombre d'inodes libres et utilisés avec la
df -ih :
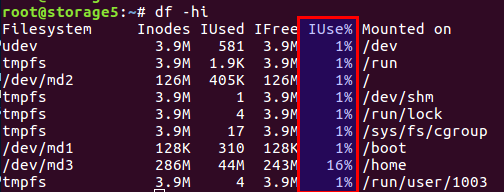
Je ne reviendrai pas sur l'article, bref, il y a à la fois des blocs de données directement sur le disque et des blocs de méta-informations, ce sont aussi des inodes (nœud d'index). Leur nombre est défini lors de l'initialisation du système de fichiers (nous parlons d'ext2 et de ses descendants) et ne change plus. L'équilibre des blocs de données et des inodes est calculé à partir des données statistiques moyennes, dans notre cas, quand il y a beaucoup de petits fichiers, l'équilibre devrait se déplacer vers le nombre d'inodes - il devrait y en avoir plus.
Linux a déjà fourni des options avec différents équilibres, et toutes ces configurations pré-calculées se trouvent dans le fichier
/etc/mke2fs.conf .
Par conséquent, lors de l'initialisation initiale du système de fichiers via mke2fs, vous pouvez spécifier le profil souhaité.
Voici quelques exemples du fichier:
small = { blocksize = 1024 inode_size = 128 inode_ratio = 4096 } big = { inode_ratio = 32768 } largefile = { inode_ratio = 1048576 blocksize = -1 }
Vous pouvez sélectionner le cas d'utilisation souhaité avec l'option -T lors de l'appel de mke2fs. Vous pouvez également définir manuellement les paramètres nécessaires s'il n'y a pas de solution prête à l'emploi.
Plus de détails sont décrits dans les manuels de
mke2fs.conf et
mke2fs .
Une fonctionnalité non mentionnée dans l'article susmentionné - vous pouvez définir la taille du bloc de données. Évidemment, pour les gros fichiers, il est logique d'avoir une taille de bloc plus grande, pour les petits fichiers - dans un plus petit.
Cependant, il vaut la peine d'envisager une fonctionnalité aussi intéressante que l'architecture du processeur.
J'ai pensé une fois que j'avais besoin d'une taille de bloc plus grande pour les gros fichiers photo. C'était à la maison, sur le nom de fichier d'accueil WD sur l'architecture ARM. Sans hésitation, j'ai réglé la taille du bloc à 8k ou 16k au lieu du 4k standard, après avoir mesuré les économies. Et tout était merveilleux jusqu'au moment où le stockage lui-même n'a pas échoué, alors que le disque était vivant. Après avoir mis le disque dans un ordinateur ordinaire avec un processeur Intel ordinaire, j'ai eu une surprise: la taille des blocs non pris en charge. Navigué. Il y a des données, tout va bien, mais impossible à lire. Les processeurs i386 et similaires ne savent pas comment travailler avec des tailles de bloc qui ne correspondent pas à la taille de la page mémoire, mais c'est exactement 4k. En général, l'affaire s'est terminée avec l'utilisation d'utilitaires depuis l'espace utilisateur, tout était lent et triste, mais les données ont été enregistrées.
fuseext2 importe - google le nom de l'utilitaire
fuseext2 . Moralité: réfléchissez à l'avance à tous les cas ou ne créez pas un super-héros et utilisez les paramètres standard pour les femmes au foyer.
UPD Selon la remarque de l'utilisateur,
Berez précise que pour i386, la taille de bloc ne doit pas dépasser 4k, mais elle ne doit pas être exactement 4k, c'est-à-dire valide 1k et 2k.
Alors, comment nous avons résolu les problèmes.
Premièrement, nous avons rencontré un problème lorsqu'un disque de plusieurs téraoctets était plein de données et nous n'avons pas pu refaire la configuration du système de fichiers.
Deuxièmement, la décision était urgente.
En conséquence, nous sommes arrivés à la conclusion que nous devons modifier l'équilibre en réduisant le nombre de fichiers.
Pour réduire le nombre de fichiers, il a été décidé de placer les fichiers dans une archive commune. Compte tenu de nos spécificités, nous avons mis tous les fichiers dans une archive pendant une certaine période de temps, et archivé la tâche cron quotidiennement la nuit.
Sélection d'une archive zip. Dans les commentaires de l'article précédent, tar a été proposé, mais il y a une complication: il n'a pas de table des matières et les fichiers y sont enfilés (pour une raison, «tar» est l'abréviation de «Tape Archive», un héritage de lecteurs de bande), c'est-à-dire . si vous devez lire le fichier à la fin de l'archive, vous devez lire l'archive entière, car il n'y a pas de décalage pour chaque fichier par rapport au début de l'archive. Et donc c'est une longue opération. En zip, tout va bien mieux: il a la même table des matières et les mêmes décalages de fichiers à l'intérieur de l'archive, et le temps d'accès à chaque fichier ne dépend pas de son emplacement. Eh bien, dans notre cas, il était possible de régler l'option de compression sur «0», car tous les fichiers avaient déjà été compressés dans gzip au préalable.
Les clients prennent des fichiers via nginx, et selon l'ancienne API, seul le nom de fichier est spécifié, par exemple comme ceci:
http://www.server.com/hydra/20170416/0453/3bd24ae7-1df4-4d76-9d28-5b7fcb7fd8e5
Pour décompresser les fichiers à la volée, nous avons trouvé et connecté le module nginx-unzip-module (
https://github.com/youzee/nginx-unzip-module ) et mis en place deux en amont.
Le résultat est cette configuration:

Deux hôtes dans les paramètres ressemblaient à ceci:
server { listen *:8081; location / { root /home/filestorage; } }
server { listen *:8082; location ~ ^/hydra/(\d+)/(\d+)/(.*)$ { root /home/filestorage; file_in_unzip_archivefile "/home/filestorage/hydra/$1/$2.zip"; file_in_unzip_extract "$2/$3"; file_in_unzip; } }
Et la configuration en amont sur le nginx en amont:
upstream storage { server server.com:8081; server server.com:8082; }
Comment ça marche:
- Le client passe devant nginx
- Front nginx essaie de donner le fichier du premier en amont, c'est-à-dire directement depuis le système de fichiers
- S'il n'y a pas de fichier, il essaie de le donner depuis le second en amont, qui essaie de trouver le fichier à l'intérieur de l'archive
Le deuxième problème: encore une fois, "Il n'y a plus d'espace sur l'appareil"
C'est le deuxième problème que nous avons rencontré quand il y a beaucoup de fichiers dans le répertoire.
Nous essayons de créer un fichier, le système jure qu'il n'y a pas d'espace. Modifiez le nom du fichier et essayez de le recréer.
Cela s'avère.
Cela ressemble à ceci:

Vérifier les inodes n'a rien donné - il y en a beaucoup gratuitement.
Vérifier l'endroit est le même.
Nous pensions qu'il y avait trop de fichiers dans le répertoire, mais il y a une limite à cela, mais encore une fois pas: Nombre maximum de fichiers par répertoire: ~ 1,3 × 10 ^ 20
Oui, et vous pouvez créer un fichier si vous changez le nom.
La conclusion est un problème dans le nom du fichier.
Des recherches supplémentaires ont montré que le problème est dans l'algorithme de hachage lors de la construction de l'index de répertoire, avec un grand nombre de fichiers, il y a des collisions avec toutes les conséquences qui en découlent. Plus de détails peuvent être trouvés ici:
https://ext4.wiki.kernel.org/index.php/Ext4_Disk_Layout#Hash_Tree_DirectoriesVous pouvez désactiver cette option, mais ... la recherche d'un fichier par son nom peut devenir imprévisible lors du tri de tous les fichiers.
tune2fs -O "^dir_index" /dev/sdb3
En général, comment une solution de contournement pourrait fonctionner.
Moralité: de nombreux fichiers dans un répertoire sont généralement mauvais. Ce n'est pas nécessaire.
Habituellement, dans de tels cas, ils créent des sous-répertoires, par les premières lettres du nom de fichier ou par certains autres paramètres, par exemple, par dates, dans la plupart des cas, cela enregistre.
Mais le nombre total de petits fichiers est toujours mauvais, même s'ils sont divisés en répertoires - alors voyez le premier problème.
Le troisième problème: comment voir la liste des fichiers, s'il y en a beaucoup
Dans notre situation, lorsque nous avons beaucoup de fichiers, d'une manière ou d'une autre, nous avons été confrontés au problème de la façon d'afficher le contenu du répertoire.
La solution standard est la
ls .
Ok, voyons ce qui se passe sur les fichiers 4772098:
$ time ls /home/app/express.repository/offercache/ >/dev/null real 0m30.203s user 0m28.327s sys 0m1.876s
30 secondes ... ce sera trop. Et la plupart du temps, il faut traiter les fichiers dans l'espace utilisateur, et pas du tout vers le noyau.
Mais il y a une solution:
$ time find /home/app/express.repository/offercache/ >/dev/null real 0m3.714s user 0m1.998s sys 0m1.717s
3 secondes 10 fois plus rapide.
Hourra!
UPDUne solution encore plus rapide de l'utilisateur de
Berez est de désactiver le tri
LS time ls -U /home/app/express.repository/offercache/ >/dev/null real 0m2.985s user 0m1.377s sys 0m1.608s
Le quatrième problème: un grand LA lors de l'utilisation de fichiers
Périodiquement, une situation se produit lorsque vous devez copier un tas de fichiers d'une machine à une autre. Dans le même temps, LA se développe souvent de manière irréaliste, car tout dépend des performances des disques eux-mêmes.
La chose la plus raisonnable que vous souhaitez est d'utiliser un SSD. Vraiment cool. La seule question est le coût des SSD multi-téraoctets.
Mais si les disques sont ordinaires, vous devez copier les fichiers, et c'est aussi un système de production, où la surcharge conduit à des exclamations insatisfaites des clients? Il existe au moins deux outils utiles:
nice et
ionice .
nice - réduit la priorité du processus, respectivement, le sheduler distribue plus de tranches de temps à d'autres processus plus prioritaires.
Dans notre pratique, cela a aidé à définir nice au maximum (19 est la priorité minimum, -20 (moins 20) est le maximum).
ionice - ajuste en conséquence la priorité des entrées / sorties (planification des E / S)
Si vous utilisez RAID et devez synchroniser soudainement (après un redémarrage infructueux ou devez restaurer la matrice RAID après avoir remplacé le disque), alors dans certaines situations, il est logique de réduire la vitesse de synchronisation afin que d'autres processus puissent fonctionner plus ou moins adéquatement. Pour ce faire, la commande suivante vous aidera:
echo 1000 > /proc/sys/dev/raid/speed_limit_max
Le cinquième problème: comment synchroniser des fichiers en temps réel
Nous avons tous le même nombre énorme de fichiers qui doivent être sauvegardés sur un deuxième serveur afin d'éviter ... Les fichiers sont constamment écrits, donc, pour avoir un minimum de pertes, vous devez les copier le plus rapidement possible.
Solution standard: Rsync sur SSH.
C'est une bonne option, sauf si vous devez le faire une fois toutes les quelques secondes. Et il y a beaucoup de fichiers. Même si vous ne les copiez pas, vous devez tout de même comprendre ce qui a changé, et comparer plusieurs millions de fichiers, c'est le temps et la charge sur les disques.
C'est-à-dire nous devons immédiatement savoir quoi copier, sans lancer la comparaison à chaque fois.
Salut -
lsyncd .
Lsyncd -
Lsyncd synchronisation en direct (miroir) . Il fonctionne également via rsync, mais il surveille également le système de fichiers pour les modifications en utilisant inotify et fsevents et commence à copier uniquement pour les fichiers qui sont apparus ou modifiés.
Le sixième problème: comment comprendre qui charge les disques
Tout le monde le sait probablement, mais néanmoins par
iotop exhaustivité: pour surveiller le sous-système de disque, il y a la commande
iotop - comme
top , mais montre les processus qui utilisent les disques le plus activement.

Soit dit en passant, le bon vieux haut indique également clairement qu'il y a des problèmes avec les disques ou non. Il existe deux paramètres les plus appropriés pour cela:
Load Average et
IOwait .
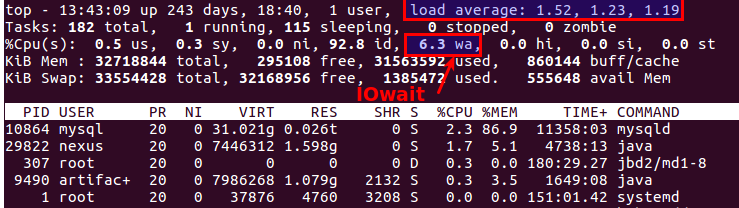
Le premier indique le nombre de processus dans la file d'attente de service, généralement plus de 2 - quelque chose ne va pas. Avec la copie active sur des serveurs de sauvegarde, nous autorisons jusqu'à 6-8, après quoi la situation est considérée comme anormale.
La seconde est la quantité d'occupation du processeur avec les opérations sur disque. IOwait> 10% est une source de préoccupation, bien que sur les serveurs avec un profil de charge spécifique, il soit stable de 40 à 50%, et c'est vraiment la norme.
Je terminerai ici, bien qu'il y ait probablement beaucoup de points que nous n'avons pas dû affronter, je serai heureux d'attendre les commentaires et les descriptions de cas réels intéressants.