Avant de commencer à implémenter une nouvelle fonctionnalité, vous devez vous casser la tête.
Le développement de fonctionnalités complexes nécessite une coordination fine des efforts d'une équipe d'ingénieurs.
Et l'un des points les plus importants est la question de la parallélisation des tâches.
Est-il possible de sauver les soldats de première ligne d'avoir à attendre une mise en œuvre en arrière-plan? Existe-t-il un moyen de paralléliser le développement de fragments individuels de l'interface utilisateur?
Le sujet de la parallélisation des tâches dans le développement Web sera abordé dans cet article.
Le problème
Commençons donc par identifier le problème. Imaginez que vous ayez un produit chevronné (service Internet), dans lequel plusieurs microservices différents sont collectés. Chaque microservice de votre système est une sorte de mini-application intégrée à l'architecture générale et résolvant certains problèmes spécifiques de l'utilisateur du service. Imaginez que ce matin (le dernier jour du sprint), le propriétaire du produit appelé Vasily vous a adressé la parole et a annoncé: "Au prochain sprint, nous commencerons à scier l'importation de données, ce qui rendra les utilisateurs du service encore plus heureux. Cela permettra à l'utilisateur de remplir le service immédiatement. dense 1C! ".
Imaginez que vous êtes un gestionnaire ou un chef d'équipe et que vous n'écoutez pas toutes ces descriptions enthousiastes d'utilisateurs satisfaits d'un point de vue commercial. Vous estimez combien de travail tout cela exigera. En bon gestionnaire, vous vous efforcez de réduire l'appétit de Vasily pour les tâches de notation pour MVP (ci-après, produit minimum viable). Dans le même temps, les deux principales exigences de MVP - la capacité du système d'importation à résister à une charge importante et à fonctionner en arrière-plan, ne peuvent pas être supprimées.
Vous comprenez que l'approche traditionnelle, lorsque toutes les données sont traitées dans la même demande de l'utilisateur, ne fonctionnera pas. Ici, vous devez clôturer le jardin de tous les travailleurs de fond. Vous devrez vous accrocher au bus d'événements, réfléchir au fonctionnement de l'équilibreur de charge, de la base de données distribuée, etc. En général, tous les plaisirs de l'architecture de microservices. En conséquence, vous concluez que le développement du backend pour cette fonctionnalité se prolongera, ne vous rendez pas aux diseurs de bonne aventure.
La question se pose automatiquement: "Que feront les soldats de première ligne pendant tout ce temps sans API?".
De plus, il s'avère que les données ne doivent pas être importées immédiatement. Vous devez d'abord les valider et laisser l'utilisateur corriger toutes les erreurs trouvées. Il s'avère également un workflow astucieux sur le front-end. Et il est nécessaire d'entailler la fonctionnalité, comme d'habitude, "hier". Par conséquent, les anciens combattants doivent être en quelque sorte coordonnés afin de ne pas se bousculer dans un navet, de ne pas provoquer de conflits et d'en voir calmement chaque morceau (voir KDPV au début de l'article).
Dans une situation différente, nous pourrions commencer à scier de l'arrière vers l'avant. Tout d'abord, implémentez le backend et vérifiez qu'il maintient la charge, puis accrochez calmement l'extrémité avant dessus. Mais le problème est que les spécifications décrivent la nouvelle fonctionnalité en termes généraux, présentent des lacunes et des points controversés en termes de convivialité. Mais que se passe-t-il si à la fin de la mise en œuvre frontale, il s'avère que sous cette forme, la fonctionnalité ne satisfera pas l'utilisateur? Les changements d'utilisabilité peuvent nécessiter des modifications du modèle de données. Nous devrons refaire à la fois l'avant et l'arrière, ce qui sera très cher.
Agile essaie de nous aider.
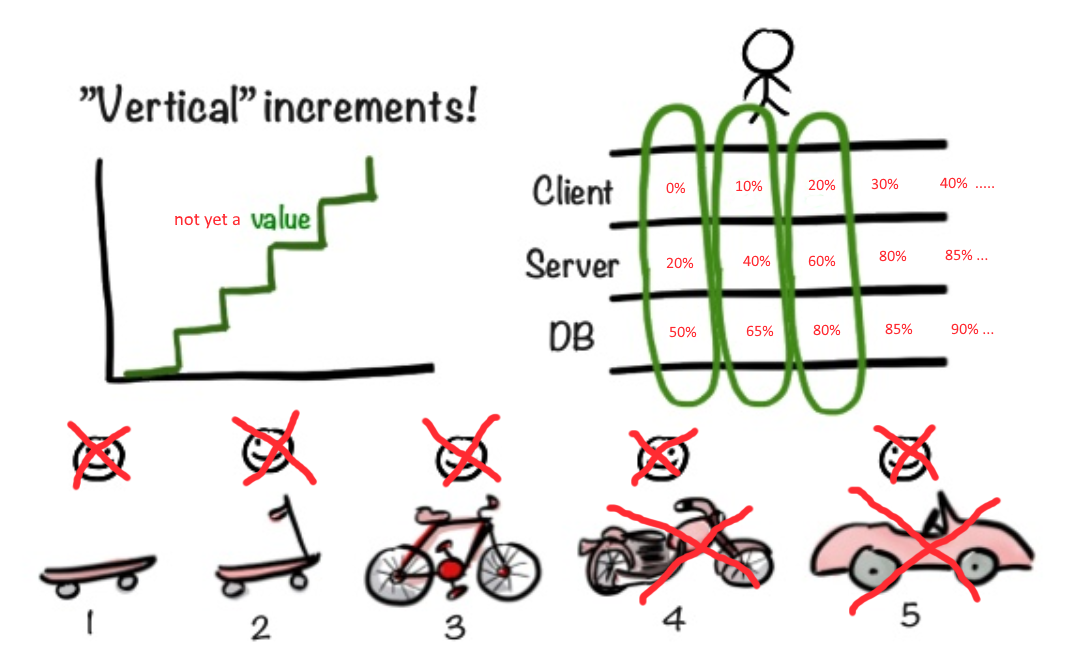
Des méthodologies flexibles fournissent des conseils judicieux. "Commencez par la planche à roulettes et montrez à l'utilisateur. Soudain, il l'aimera. Si vous l'aimez, continuez dans la même veine, vissez de nouvelles puces."
Mais que se passe-t-il si l'utilisateur a immédiatement besoin d'au moins une moto et dans deux à trois semaines? Et si pour commencer à travailler sur la façade de la moto, vous devez au moins décider des dimensions du moteur et de la taille du châssis?
Comment s'assurer que la mise en œuvre de la façade ne soit pas retardée tant qu'il n'y a pas de certitude avec les autres couches de l'application?
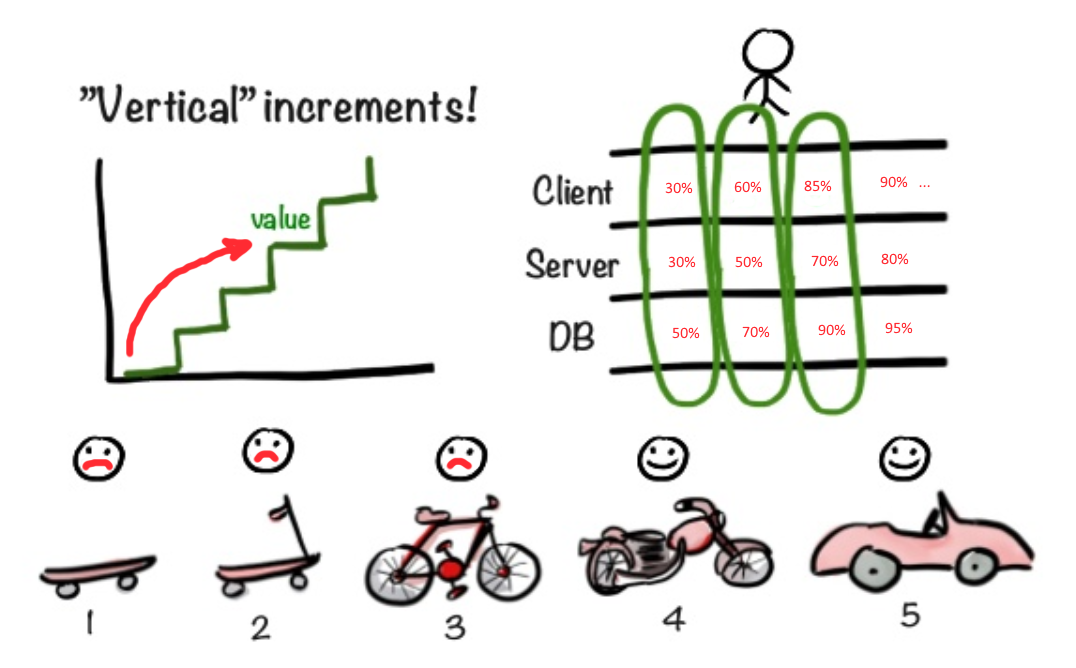
Dans notre situation, il vaut mieux utiliser une approche différente. Il est préférable de commencer immédiatement à faire une façade (avant) pour vous assurer que l'idée initiale de MVP est correcte. D'une part, faire glisser une façade décorative au propriétaire du produit Vasily, derrière laquelle il n'y a rien, semble être de la triche, une escroquerie. D'un autre côté, nous obtenons ainsi très rapidement des commentaires sur la partie des fonctionnalités que l'utilisateur rencontrera en premier lieu. Vous pouvez avoir une architecture incroyablement cool, mais s'il n'y a pas d'utilisation, alors l'application entière sera jetée sur le bord de l'application, sans comprendre les détails. Par conséquent, il me semble plus important de donner l'interface utilisateur la plus fonctionnelle le plus rapidement possible, au lieu de synchroniser la progression du front avec le backend. Il est inutile d'émettre une interface utilisateur inachevée et un support pour les tests, dont la fonctionnalité ne satisfait pas aux exigences principales. Dans le même temps, l'émission de 80% des fonctionnalités d'interface utilisateur requises, mais sans back-end fonctionnel, pourrait bien s'avérer rentable.
Quelques détails techniques
J'ai donc déjà décrit brièvement quelle fonctionnalité nous allons mettre en œuvre. Ajoutez quelques détails techniques.
L'utilisateur doit pouvoir télécharger un fichier de données volumineux sur le service. Le contenu de ce fichier doit être dans un format spécifique (par exemple, CSV). Le fichier doit avoir une certaine structure de données et certains champs obligatoires ne doivent pas être vides. En d'autres termes, après le déchargement dans le backend, vous devrez valider les données. La validation peut durer un temps considérable. Vous ne pouvez pas garder la connexion au backend ouverte (elle tombera par timeout). Par conséquent, nous devons accepter rapidement le fichier et commencer le traitement en arrière-plan. À la fin de la validation, nous devons informer l'utilisateur qu'il peut commencer à éditer les données. L'utilisateur doit corriger les erreurs détectées lors de la validation.
Une fois toutes les erreurs corrigées, l'utilisateur clique sur le bouton d'importation. Les données corrigées sont renvoyées au backend. pour terminer la procédure d'importation. Nous devons informer le front-end de l'avancement de toutes les étapes de l'importation.
Le moyen le plus efficace d'alerter est WebSockets. De face, via Websocket avec une certaine période, des demandes seront envoyées pour obtenir l'état actuel du traitement des données en arrière-plan. Pour le traitement des données d'arrière-plan, nous avons besoin de gestionnaires d'arrière-plan, d'une file d'attente de commandes distribuée, d'un bus d'événements, etc.
Le flux de données est vu comme suit (pour référence):
- Grâce à l'API du navigateur de fichiers, nous demandons à l'utilisateur de sélectionner le fichier souhaité sur le disque.
- Grâce à AJAX, nous envoyons le fichier au backend.
- Nous attendons la fin de la validation et de l'analyse du fichier de données (nous interrogeons l'état de l'opération en arrière-plan via Websocket).
- Une fois la validation terminée, nous chargerons les données préparées pour l'importation et les rendrons dans le tableau de la page d'importation.
- L'utilisateur modifie les données, corrige les erreurs. En cliquant sur le bouton en bas de la page, nous envoyons les données corrigées au backend.
- Toujours du côté client, nous exécutons un sondage périodique de l'état de l'opération en arrière-plan.
- Jusqu'à la fin de l'importation en cours, l'utilisateur ne devrait pas pouvoir démarrer une nouvelle importation (même dans la fenêtre du navigateur voisin ou sur l'ordinateur voisin).
Plan de développement
Interface utilisateur Mocap vs. Interface utilisateur du prototype

Soulignons immédiatement la différence entre Wireframe, Mockup, Prototype.
L'image ci-dessus montre le filaire. Ce n'est qu'un dessin (en chiffres ou sur papier - peu importe). Les deux autres concepts sont plus compliqués.
Mocap est une forme de présentation de la future interface qui n'est utilisée qu'en tant que présentation et sera par la suite complètement remplacée. Ce formulaire sera archivé comme échantillon à l'avenir. L'interface réelle se fera à l'aide d'autres outils. Un mocap peut être fait dans un éditeur de vecteur avec suffisamment de détails de conception, mais les développeurs frontaux le mettront simplement de côté et le regarderont comme un modèle. Mocap peut être créé même dans des constructeurs de navigateurs spécialisés et est livré avec une interactivité limitée. Mais son sort est inchangé. Il deviendra un modèle dans l'album Design Guide.
Le prototype est créé à l'aide des mêmes outils que la future interface utilisateur (par exemple, React). Le code prototype est hébergé dans le référentiel d'applications général. Il ne sera pas remplacé, comme c'est le cas avec mocap. Tout d'abord, il est utilisé pour tester le concept (Proof of Concept, PoC). Ensuite, s'il réussit le test, ils commenceront à le développer, en le transformant progressivement en une interface utilisateur à part entière.
Maintenant plus près du point ...
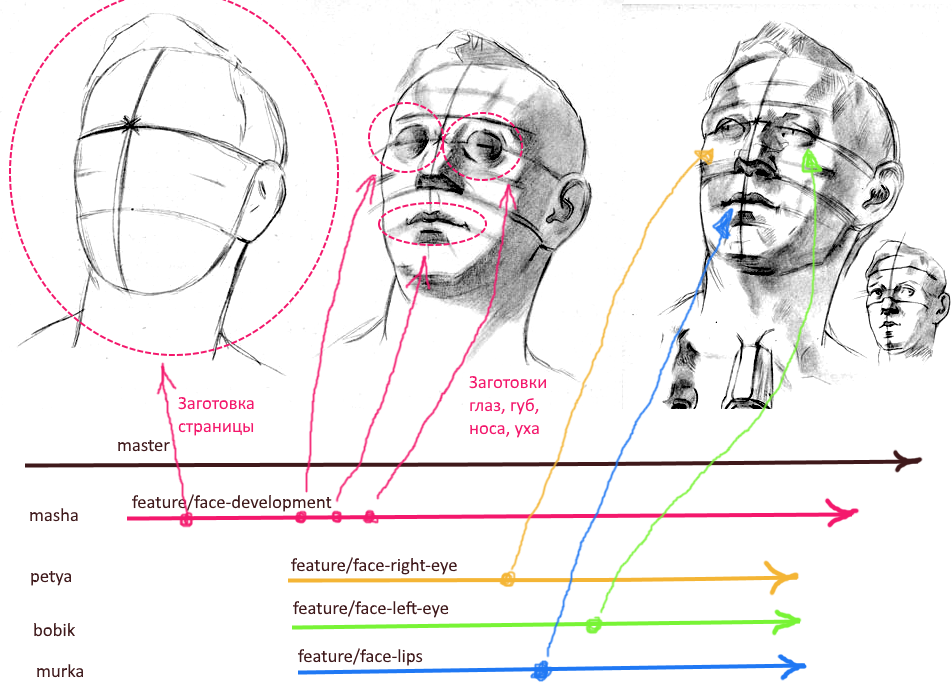
Imaginez que des collègues de l'atelier de conception nous ont présenté des artefacts de leur processus créatif: des maquettes de la future interface. Notre tâche est de planifier le travail de manière à rendre le plus rapidement possible le travail parallèle des anciens combattants.
Comme la compilation de l'algorithme commence par un organigramme, nous commençons la création d'un prototype avec un filaire minimaliste (voir la figure ci-dessus). Sur ce Wireframe, nous divisons les fonctionnalités futures en gros blocs. Le principe principal ici est de focaliser la responsabilité. Vous ne devez pas diviser un élément de fonctionnalité en différents blocs. Les mouches vont dans un bloc et les côtelettes dans un autre.
Ensuite, vous devez créer une page vierge (factice) dès que possible, configurer le routage et placer un lien vers cette page dans le menu. Ensuite, vous devez créer des blancs pour les composants de base (un pour chaque bloc dans le prototype Wireframe). Et pour alimenter ce cadre particulier dans la branche de développement d'une nouvelle fonctionnalité.
Nous obtenons la hiérarchie de branches suivante dans git:
master ---------------------- > └ feature/import-dev ------ >
La branche "import-dev" jouera le rôle de brunch de développement pour l'ensemble de la fonctionnalité. Il est conseillé de fixer une personne responsable (mainteneur) dans cette branche qui tient en parallèle les changements atomiques de tous les collègues travaillant sur la fonctionnalité. Il est également conseillé de ne pas effectuer de commits directs sur cette branche afin de réduire les risques de conflits et de changements inattendus lors de fusions dans cette branche de demandes d'attraction atomique.
Parce que À ce moment, nous avons déjà créé des composants pour les blocs principaux de la page, puis vous pouvez immédiatement créer des branches distinctes pour chaque bloc d'interface utilisateur. La hiérarchie finale peut ressembler à ceci:
master ----------------------- > └ feature/import-dev ------- > ├ feature/import-head ---- > ├ feature/import-filter -- > ├ feature/import-table --- > ├ feature/import-pager --- > └ feature/import-footer -- >
Remarque: peu importe à quel moment créer ces brunchs atomiques et la convention de dénomination présentée ci-dessus n'est pas la seule appropriée. Le brunch peut être créé immédiatement avant le début des travaux. Et les noms des brunchs doivent être clairs pour tous les participants au développement. Le nom doit être aussi court que possible et en même temps indiquer explicitement de quelle partie de la fonctionnalité la branche est responsable.
Par l'approche décrite ci-dessus, nous garantissons le fonctionnement sans conflit de plusieurs développeurs d'interface utilisateur. Chaque fragment d'interface utilisateur a son propre répertoire dans la hiérarchie du projet. Le catalogue de fragments contient le composant principal, son ensemble de styles et son propre ensemble de composants enfants. Chaque fragment peut également avoir son propre gestionnaire d'état (MobX, Redux, Parties VueX). Peut-être que les composants du fragment utilisent certains styles globaux. Cependant, la modification des styles globaux lors du développement d'un fragment d'une nouvelle page est interdite. Changer le comportement et le style par défaut de l'atome général du design n'en vaut pas la peine.
Remarque: «atome de conception» signifie un élément de l'ensemble des composants standard de notre service - voir Conception atomique ; dans notre cas, on suppose que le système de conception atomique a déjà été implémenté.
Nous avons donc physiquement séparé les soldats de première ligne les uns des autres. Désormais, chacun peut travailler tranquillement, sans crainte de conflits avec la fusion. De plus, n'importe qui peut à tout moment créer une demande de pull depuis sa branche dans feature / import-dev . Déjà maintenant, il est possible de lancer calmement du contenu statique et même de former des éléments interactifs dans un seul stockage d'état.
Mais comment s'assurer que les fragments d'interface utilisateur peuvent interagir les uns avec les autres?
Nous devons implémenter le lien entre les fragments. Le service JS, agissant comme une passerelle pour l'échange de données avec le support, convient au rôle de lien entre les fragments. Grâce au même service, vous pouvez implémenter la notification des événements. En souscrivant à certains événements, les fragments incluront implicitement le cycle de vie global du microservice. Les modifications apportées aux données d'un fragment nécessiteront de mettre à jour l'état d'un autre fragment. En d'autres termes, nous avons fait l'intégration de fragments à travers des données et un modèle d'événement.
Pour créer ce service, nous avons besoin d'une branche supplémentaire dans git:
master --------------------------- > └ feature/import-dev ----------- > ├ feature/import-js-service -- > ├ feature/import-head -------- > ├ feature/import-filter ------ > ├ feature/import-table ------- > ├ feature/import-pager ------- > └ feature/import-footer ------ >
Remarque: n'ayez pas peur du nombre de branches et n'hésitez pas à produire des branches. Git vous permet de travailler efficacement avec un grand nombre de succursales. Lorsqu'une habitude se développe, il devient facile de se ramifier:
$/> git checkout -b feature/import-service $/> git commit . $/> git push origin HEAD $/> git checkout feature/import-dev $/> git merge feature/import-service
Cela peut sembler tendu pour certains, mais le bénéfice de la minimisation des conflits est plus important. De plus, pendant que vous êtes le propriétaire exclusif de la branche, vous pouvez pousser -f en toute sécurité sans risquer d'endommager l'historique local des commits de quelqu'un.
Fake data
Ainsi, à l'étape précédente, nous avons préparé le service d'intégration JS (importService) et préparé les fragments d'interface utilisateur. Mais sans données, notre prototype ne fonctionnera pas. Rien n'est dessiné sauf pour les décorations statiques.
Nous devons maintenant décider d'un modèle de données approximatif et créer ces données sous forme de fichiers JSON ou JS (le choix en faveur de l'un ou l'autre dépend des paramètres d'importation de votre projet; est configuré json-loader). Notre importService, ainsi que ses tests (nous y réfléchirons plus tard), importent de ces fichiers les données nécessaires pour simuler les réponses d'un vrai backend (il n'a pas encore été implémenté). Où placer ces données n'est pas important. L'essentiel est qu'ils peuvent être facilement importés dans importService lui-même et testés dans notre microservice.
Il est conseillé de discuter immédiatement du format des données, de la convention de dénomination des champs avec les développeurs de l'arrière. Vous pouvez, par exemple, accepter d'utiliser un format conforme à la spécification OpenAPI . Quelles que soient les spécifications du format de support qui suivent, nous créons de fausses données en conformité exacte avec le format de données de support.
Remarque: n'ayez pas peur de vous tromper avec le faux modèle de données; Votre tâche consiste à créer une version préliminaire du contrat de données, qui sera ensuite convenue avec les développeurs backend.
Contrats
Les fausses données peuvent être un bon début pour commencer à travailler sur la spécification de la future API dans le back-end. Et ici, peu importe qui et comment la qualité met en œuvre le projet de modèle. Crucial est la discussion et la coordination conjointes avec la participation des développeurs avant et arrière.
Vous pouvez utiliser des outils spécialisés pour décrire les contrats (spécifications API). Par exemple, OpenAPI / Swagger . Dans le bon sens, lors de la description d'une API avec un tel outil, il n'est pas nécessaire que tous les développeurs soient présents. Cela peut être fait par un développeur (éditeur de spécifications). Le résultat d'une discussion collective sur la nouvelle API devait être des artefacts comme MFU (Meeting Follow Up), selon lesquels l'éditeur de spécifications construit également une référence pour la future API.
À la fin du projet de spécification, la vérification de l'exactitude ne devrait pas prendre longtemps. Chaque participant à la discussion collective pourra, indépendamment des autres, effectuer une inspection rapide pour vérifier que son avis a bien été pris en compte. Si quelque chose semble incorrect, il sera possible de clarifier les spécifications de l'éditeur (communications de travail normales). Si tout le monde est satisfait de la spécification, elle peut être publiée et utilisée comme documentation pour le service.
Tests unitaires
Remarque: Pour moi, la valeur des tests unitaires est assez faible. Ici, je suis d'accord avec David Heinemeier Hansson @ RailsConf . "Les tests unitaires sont un excellent moyen de s'assurer que votre programme fait ce que vous pouvez faire ... comme prévu." Mais j'admets des cas particuliers où les tests unitaires apportent beaucoup d'avantages.
Maintenant que nous avons décidé des fausses données, nous pouvons commencer à tester les fonctionnalités de base. Pour tester les composants frontaux, vous pouvez utiliser des outils tels que karma, jest, mocha, chai, jasmine. Habituellement, le fichier avec le même nom avec le suffixe "spec" ou "test" est placé à côté de la ressource JS sous test:
importService ├ importService.js └ importService.test.js
La valeur spécifique du suffixe dépend des paramètres du collecteur de packages JS dans votre projet.
Bien sûr, dans une situation où le dos est dans un état «contraceptif», il est très difficile de couvrir tous les cas possibles par des tests unitaires. Mais le but des tests unitaires est un peu différent. Ils sont conçus pour tester le fonctionnement de pièces logiques individuelles.
Par exemple, il est bon de couvrir différents types d’aides avec des tests unitaires, à travers lesquels des éléments de logique ou certains algorithmes sont partagés entre les composants et les services JS. En outre, ces tests peuvent couvrir le comportement des composants et des magasins de MobX, Redux, VueX en réponse aux modifications des données utilisateur.
Intégration et tests E2E
Les tests d'intégration signifient la vérification du comportement du système pour la conformité avec la spécification. C'est-à-dire il est vérifié que l'utilisateur verra exactement le comportement décrit dans les spécifications. Il s'agit d'un niveau de test plus élevé que les tests unitaires.
Par exemple, un test qui vérifie une erreur dans le champ obligatoire lorsque l'utilisateur a effacé tout le texte. Ou un test qui vérifie qu'une erreur est générée lors de la tentative de sauvegarde de données non valides.
Les tests E2E (End-to-End) fonctionnent à un niveau encore plus élevé. Ils vérifient que le comportement de l'interface utilisateur est correct. Par exemple, en vérifiant qu'après l'envoi du fichier de données au service, l'utilisateur voit une torsion qui signale un processus asynchrone continu. Ou vérifiez que la visualisation des composants standards du service correspond aux guides des concepteurs.
Ce type de test fonctionne avec un cadre d'automatisation d'interface utilisateur. Par exemple, il pourrait s'agir de sélénium . Ces tests ainsi que Selenium WebDriver s'exécutent dans certains navigateurs (généralement Chrome avec le "mode sans tête"). Ils travaillent depuis longtemps, mais réduisent le fardeau des spécialistes de l'AQ, en faisant un test de fumée pour eux.
L'écriture de ces types de tests prend beaucoup de temps. Le plus tôt nous commencerons à les écrire, mieux ce sera. Malgré le fait que nous n'avons pas de sauvegarde à part entière, nous pouvons déjà commencer à décrire les tests d'intégration. Nous avons déjà une spécification.
Avec une description de l'E2E, il y a encore moins de tests d'obstacles. Nous avons déjà esquissé les composants standard de la bibliothèque d'atomes de conception. Implémentation d'éléments spécifiques de l'interface utilisateur. Rendu interactif en plus de fausses données et API dans importService. Rien ne vous empêche de démarrer l'automatisation de l'interface utilisateur, au moins pour les cas de base.
En écrivant ces tests, vous pouvez à nouveau dérouter les développeurs individuels s'il n'y a pas de gens déconcertés. Et aussi pour décrire les tests, vous pouvez créer une branche distincte (comme décrit ci-dessus). Dans les branches pour les tests, il sera nécessaire de mettre à jour périodiquement les mises à jour de la branche " feature / import-dev ".
La séquence générale des fusions sera la suivante:
- Par exemple, un développeur de la branche " feature / import-filter " a créé un PR. Ce PR est prévisualisé et le mainteneur de la branche " feature / import-dev " injecte ce PR.
- Le responsable annonce que la mise à jour a été versée.
- Le développeur de la branche " feature / import-tests-e2e " tire des changements extrêmes avec la fusion de la branche "-dev.
CI et automatisation des tests
Les tests frontaux sont implémentés à l'aide d'outils qui fonctionnent via la CLI. Dans package.json, les commandes sont écrites pour exécuter différents types de tests. Ces commandes ne sont pas uniquement utilisées par les développeurs dans l'environnement local. Ils sont également nécessaires pour exécuter des tests dans l'environnement CI (intégration continue).
Si maintenant nous exécutons la construction dans CI et qu'il n'y a pas d'erreur, alors notre prototype tant attendu sera livré à l'environnement de test (80% des fonctionnalités à l'avant avec un back-end non encore implémenté). Nous pouvons montrer à Vasily le comportement approximatif du futur microservice. Vasiliy lance ce prototype et, peut-être, fera quelques remarques (peut-être même sérieuses). À ce stade, faire des ajustements n'est pas cher. Dans notre cas, le support nécessite de sérieux changements architecturaux, donc le travail peut être plus lent que sur le devant. Tant que le soutien n'est pas finalisé, les modifications du plan de développement n'entraîneront pas de conséquences désastreuses. Si nécessaire, changez quelque chose à ce stade, nous vous demanderons de faire des ajustements à la spécification API (en swagger). Après cela, les étapes décrites ci-dessus sont répétées. Les travailleurs de première ligne ne dépendent toujours pas des backends. Les spécialistes du frontend sont indépendants les uns des autres.
Backend. Contrôleurs de talon
Le point de départ pour développer l'API dans le back-end est la spécification approuvée de l'API ( OpenAPI / Swagger ). S'il existe une spécification, le support deviendra également plus facile à paralléliser. L'analyse de la spécification devrait conduire les développeurs à réfléchir aux éléments de base de l'architecture. Quels composants / services communs vous devez créer avant de procéder à la mise en œuvre des appels API individuels. Et là encore, vous pouvez appliquer l'approche comme avec des blancs pour l'interface utilisateur.
Nous pouvons commencer par le haut, c'est-à-dire de la couche externe de notre dos (des contrôleurs). À ce stade, nous commençons par le routage, les blancs du contrôleur et les fausses données. La couche de services (BL) et d'accès aux données (DAL) nous ne le faisons pas encore. Nous transférons simplement les données de JS vers le backend et programmons les contrôleurs afin qu'ils implémentent les réponses attendues pour les cas de base, en distribuant des morceaux à partir des fausses données.
À la fin de cette étape, les soldats de première ligne devraient obtenir un backend fonctionnel sur les données de test statiques. De plus, ce sont précisément les données sur lesquelles les soldats de première ligne écrivent les tests d'intégration. En principe, à ce moment, il ne devrait pas être difficile de commuter la passerelle JS (importService) pour utiliser des blancs de contrôleur à l'arrière.
La partie réponse pour les demandes via Websocket n'est pas conceptuellement différente des contrôleurs d'API Web. Nous faisons également cette «réponse» sur les données de test et nous connectons importService à cette préparation.
En fin de compte, tous les JS doivent être transférés pour fonctionner avec un vrai serveur.
Backend. Finalisation des contrôleurs. Bouts DAO
C'est maintenant au tour de finaliser la couche de support externe. Pour les contrôleurs, les services sont implémentés un par un en BL. Désormais, les services fonctionneront avec de fausses données. L'ajout à ce stade est que dans les services, nous implémentons déjà une véritable logique métier. À ce stade, il est conseillé de commencer à ajouter de nouveaux tests conformément à la logique métier des spécifications. Il est important qu'aucun test d'intégration ne tombe.
Remarque: nous ne dépendons toujours pas de l'implémentation du schéma de données dans la base de données.
Backend. Finalisez DAO. Réel db
Une fois le schéma de données implémenté dans la base de données, nous pouvons y transférer les données de test des étapes précédentes et basculer notre DAL rudimentaire pour qu'il fonctionne avec le vrai serveur de base de données. Parce que nous transférons les données initiales créées pour le front dans la base de données, tous les tests doivent rester pertinents. Si l'un des tests échoue, alors quelque chose s'est mal passé et vous devez comprendre.
Remarque: en général, avec une probabilité très élevée de travailler avec le schéma de données dans la base de données, il y aura peu pour une nouvelle fonctionnalité; peut-être que des modifications à la base de données seront apportées simultanément avec la mise en œuvre des services en BL.
À la fin de cette étape, nous obtenons un microservice complet, version alpha. Cette version peut déjà être montrée aux utilisateurs internes (Product Owner, un technologue de produit ou quelqu'un d'autre) pour évaluation en tant que MVP.
Les itérations standard d'Agile sur le travail de correction des bogues, l'implémentation de puces supplémentaires et le polissage final continueront.
Conclusion
Je pense que vous ne devriez pas utiliser aveuglément ce qui précède comme guide d'action. Vous devez d'abord essayer et vous adapter à votre projet. L'approche décrite ci-dessus est capable de délier les développeurs individuels les uns des autres et de leur permettre de travailler en parallèle dans certaines conditions. Tous les gestes avec brunch et transfert de données, l'implémentation de blancs sur les fausses données semblent être un surcoût important. Le bénéfice de ces frais généraux apparaît en raison d'une concurrence accrue. Si l'équipe de développement est composée un creuseur et demi deux piles complètes ou un freotovik avec un back-end, il y aura probablement beaucoup de profit de cette approche. Bien que dans cette situation, certains points pourraient bien accroître l'efficacité du développement.
Le bénéfice de cette approche apparaît lorsque, au tout début, nous implémentons rapidement des pièces aussi proches que possible de la future implémentation réelle et séparons physiquement le travail sur différentes parties au niveau de la structure des fichiers dans le projet et au niveau du système de gestion de code (git).
J'espère que cet article vous a été utile.
Merci de votre attention!