Objectif du système
Prise en charge de l'accès à distance aux fichiers sur les ordinateurs du réseau. Le système prend en charge «virtuellement» toutes les opérations de base des fichiers (création, suppression, lecture, écriture, etc.) en échangeant des transactions (messages) à l'aide du protocole TCP.
Domaines d'application
La fonctionnalité du système est efficace dans les cas suivants:
- dans les applications natives pour les appareils mobiles et embarqués (smartphones, systèmes de contrôle embarqués, etc.) qui nécessitent un accès rapide aux fichiers sur des serveurs distants dans les conditions d'interruptions temporaires probables de connexion (avec mise hors ligne);
- dans les SGBD chargés, si les demandes sont traitées sur certains serveurs et le stockage de données sur d'autres;
- dans les réseaux d'entreprise distribués pour la collecte et le traitement d'informations qui nécessitent un échange de données à haute vitesse, une redondance et une fiabilité;
- dans les systèmes complexes avec une architecture de microservices, où les retards dans l'échange d'informations entre les modules sont critiques.
La structure
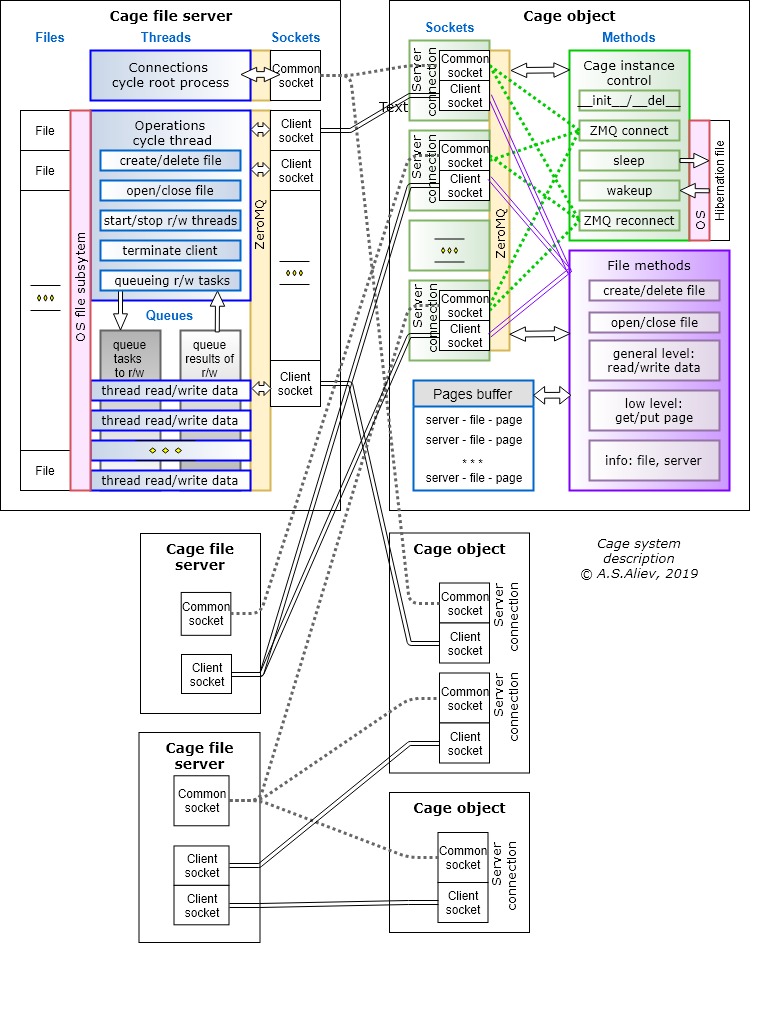
Le système Cage (il existe une implémentation - version bêta sur Python 3.7 dans Windows OS) comprend deux parties principales:
- Cageserver - un programme de serveur de fichiers (ensemble de fonctions) qui s'exécute sur les ordinateurs du réseau qui ont besoin d'un accès à distance aux fichiers;
- Classe Cage avec une bibliothèque de méthodes pour les logiciels clients qui simplifie le codage des interactions serveur.
Utilisation du système côté client
Les méthodes de la classe Cage remplacent les opérations habituelles du système de fichiers «de routine»: création, ouverture, fermeture, suppression de fichiers, mais aussi lecture / écriture de données au format binaire (indiquant la position et la taille des données). Conceptuellement, ces méthodes sont proches des fonctions fichier du langage C, où l'ouverture / fermeture des fichiers s'effectue «sur les canaux» d'entrée-sortie.
En d'autres termes, le programmeur ne fonctionne pas avec les méthodes des objets "file" (classe _io en Python), mais avec les méthodes de la classe Cage.
Lors de la création d'une instance de l'objet Cage, il établit la connexion initiale avec le serveur (ou plusieurs serveurs), passe l'autorisation par l'ID du client et reçoit une confirmation avec le numéro de port dédié pour toutes les opérations sur les fichiers. Lorsqu'un objet Cage est supprimé, il demande au serveur de mettre fin à la connexion et de fermer les fichiers. La fin de la communication peut initier les serveurs eux-mêmes.
Le système améliore les performances de lecture / écriture sur la base de la mise en mémoire tampon des fragments de fichiers fréquemment utilisés des programmes clients dans le cache (tampon) de la RAM.
Le logiciel client peut utiliser n'importe quel nombre d'objets Cage avec différents paramètres (la quantité de mémoire tampon, la taille des blocs lors de l'échange avec le serveur, etc.).
Un seul objet Cage peut échanger des données avec plusieurs fichiers sur plusieurs serveurs. Les paramètres de communication (adresse IP ou serveur DNS, port principal pour l'autorisation, chemin et nom de fichier) sont définis lors de la création de l'objet.
Étant donné que chaque objet Cage peut fonctionner avec plusieurs fichiers en même temps, l'espace de mémoire partagée est utilisé pour la mise en mémoire tampon. Taille du cache - le nombre de pages et leur taille sont définis dynamiquement lors de la création d'un objet Cage. Par exemple, un cache de 1 Go représente 1 000 pages de 1 Mo chacune, ou 10 000 pages de 100 Ko chacune, ou 1 million de pages de 1 Ko chacune. Le choix de la taille de la page et du nombre de pages est une tâche spécifique pour chaque application.
Vous pouvez utiliser plusieurs objets Cage en même temps pour définir différents paramètres de mémoire tampon en fonction des fonctionnalités d'accès aux informations dans différents fichiers. En tant que base, l'algorithme de mise en mémoire tampon le plus simple est utilisé: une fois la quantité de mémoire spécifiée épuisée, les nouvelles pages remplacent les anciennes pages sur le principe de la suppression avec un nombre minimum de hits. La mise en mémoire tampon est particulièrement efficace dans le cas d'un partage inégal (au sens statistique), d'une part, sur différents fichiers, et d'autre part, sur des fragments de chaque fichier.
La classe Cage prend en charge les entrées / sorties non seulement aux adresses de données (indiquant la position et la longueur du tableau, «remplaçant» les opérations du système de fichiers), mais également à un niveau «physique» inférieur - par des numéros de page dans la mémoire tampon.
Pour les objets Cage, la fonction d'origine de «mise en veille prolongée» («veille») est prise en charge - ils peuvent être «minimisés» (par exemple, en cas de déconnexion du serveur, ou lorsque l'application est arrêtée, etc.) vers un fichier de vidage local côté client et rapidement restaurer à partir de ce fichier (après la reprise de la communication, lorsque vous redémarrez l'application). Cela permet de réduire considérablement le trafic lors de l'activation du programme client après une «connexion hors ligne» temporaire, car des fragments de fichiers fréquemment utilisés seront déjà dans le cache.
Cage représente environ 3 600 lignes de code.
Principes de création de serveurs
Les serveurs de fichiers Cageserver peuvent être lancés avec un nombre arbitraire de ports, dont l'un (le «principal») est utilisé uniquement pour l'autorisation de tous les clients, le reste pour l'échange de données. Le programme serveur Cage ne nécessite que Python. En parallèle, un ordinateur avec un serveur de fichiers peut effectuer tout autre travail.
Le serveur démarre initialement comme une combinaison de deux processus principaux:
- «Connexions» - un processus pour effectuer des opérations d'établissement de communication avec les clients et sa résiliation à l'initiative du serveur;
- «Opérations» - un processus pour terminer les tâches (opérations) des clients sur l'utilisation des fichiers, ainsi que pour fermer les sessions de communication sur les commandes client.
Les deux processus ne sont pas synchronisés et organisés comme des cycles sans fin de réception et d'envoi de messages basés sur des files d'attente multiprocessus, des objets proxy, des verrous et des sockets.
Le processus «Connexions» fournit à chaque client un port pour recevoir et transmettre des données. Le nombre de ports est défini au démarrage du serveur. La correspondance entre les ports et les clients est stockée dans une mémoire proxy partagée entre les processus.
Le processus d'exploitation prend en charge la séparation des ressources de fichiers et plusieurs clients différents peuvent lire les données d'un fichier ensemble ( quasi-parallèlement , car l'accès est contrôlé par des verrous), si cela était autorisé lors de sa première ouverture par le "premier" client.
Le traitement des commandes pour créer / supprimer / ouvrir / fermer des fichiers sur le serveur est effectué dans le processus "Opérations" de manière strictement séquentielle en utilisant le sous-système de fichiers du système d'exploitation du serveur.
Pour l'accélération générale en lecture / écriture, ces opérations sont effectuées dans des threads générés par le processus "Opérations". Le nombre de threads est généralement égal au nombre de fichiers ouverts. Les tâches de lecture / écriture des clients sont soumises à la file d'attente générale et le premier thread libéré sort la tâche de sa tête. Une logique spéciale élimine l'écrasement des données dans la RAM du serveur.
Le processus «Opérations» surveille l'activité des clients et arrête leur service à la fois par leurs commandes et lorsque le délai d'inactivité est dépassé.
Pour garantir la fiabilité, Cageserver enregistre toutes les transactions. Un journal général contient des copies des messages des clients avec des tâches pour créer / ouvrir / renommer / supprimer des fichiers. Un journal distinct est créé pour chaque fichier de travail, dans lequel des copies des messages sont écrites avec des tâches de lecture et d'écriture de données dans ce fichier de travail, ainsi que des tableaux de données (nouvelles) enregistrées et des tableaux de données qui ont été détruits lors de l'écrasement (écriture de nouvelles données «par-dessus» l'ancien )
Ces journaux fournissent une opportunité de restaurer de nouveaux changements dans les sauvegardes, ainsi que de «restaurer» du contenu actuel au bon moment dans le passé.
Cageserver, c'est environ 3 100 lignes de code.
Démarrage du programme de serveur de fichiers Cageserver
Lors du démarrage dans la boîte de dialogue, vous devez déterminer:
- port principal pour autorisation;
- le nombre de ports pour l'échange de transactions avec les clients autorisés (à partir de 1 ou plus, le pool de numéros commence par le suivant suivant le numéro du port principal).
Utilisation de la classe Cage
cage de classe . Cage ( cage_name = "", pagesize = 0, numpages = 0, maxstrlen = 0, server_ip = {}, wait = 0, awake = False, cache_file = "" )
À partir de cette classe, des objets sont créés qui interagissent avec les serveurs de fichiers et contiennent de la mémoire tampon.
Paramètres
- cage_name ( str ) - le nom conditionnel de l'objet utilisé pour identifier les clients côté serveur
- pagesize ( int ) - taille d'une page de mémoire tampon (en octets)
- numpages ( int ) - nombre de pages de mémoire tampon
- maxstrlen ( int ) - longueur maximale de chaîne d'octets dans les opérations d'écriture et de lecture
- server_ip ( dict ) - un dictionnaire avec les adresses des serveurs utilisés, où la clé est le nom conditionnel du serveur (id du serveur à l'intérieur de l'application), et la valeur est une chaîne avec l'adresse: "ip address: port" ou "DNS: port" (les noms et adresses réelles correspondants sont temporaires , il peut être changé)
- wait ( int ) - temps d'attente d'une réponse du serveur lors de la réception des ports (en secondes)
- awake ( boolean ) - indicateur de la méthode de création de l'objet ( False - si un nouvel objet est créé, True - si l'objet est créé à partir d'un objet précédemment "minimisé" - en utilisant l'opération "hibernation", par défaut False)
- cache_file ( str ) - nom de fichier pour l'hibernation
Les méthodes
Cage. file_create ( serveur, chemin ) - crée un nouveau fichier
Cage. file_rename ( server, path, new_name ) - renommer le fichier
Cage. file_remove ( serveur, chemin ) - supprime le fichier
Cage. open ( serveur, chemin, mod ) - ouvrir un fichier
Renvoie le numéro de canal fchannel . Le paramètre mod est le mode d'ouverture de fichier: «wm» est exclusif (lecture / écriture), «rs» est en lecture seule et partagé uniquement par d'autres clients, ws est en lecture / écriture et partagé uniquement par d'autres clients.
Cage. close ( fchannel ) - ferme le fichier
Cage. write ( fchannel, begin, data ) - écrit une chaîne d'octets dans un fichier
Cage. read ( fchannel, begin, len_data ) - lit une chaîne d'octets dans un fichier
Cage. put_pages ( fchannel ) - "pousse" du tampon vers le serveur toutes les pages du canal spécifié qui ont été modifiées. Il est utilisé à ces points de l'algorithme lorsque vous devez vous assurer que toutes les opérations sur le canal sont physiquement stockées dans un fichier sur le serveur.
Cage. push_all () - "pousse" du tampon vers le serveur toutes les pages de tous les canaux de l'instance de classe Cage qui ont été modifiées. Il est utilisé lorsque vous devez vous assurer que toutes les opérations sur tous les canaux sont stockées sur le serveur.