Dans un
article précédent, j'ai parlé de notre grande infrastructure de test de charge. En moyenne, nous créons environ 100 serveurs pour fournir la charge et environ 150 serveurs pour notre service. Tous ces serveurs doivent être créés, supprimés, configurés et exécutés. Pour ce faire, nous utilisons les mêmes outils que sur le prod pour réduire la quantité de travail manuel:
- Pour créer et supprimer un environnement de test - scripts Terraform;
- Pour configurer, mettre à jour et exécuter - des scripts Ansible;
- Pour une mise à l'échelle dynamique en fonction de la charge - scripts Python auto-écrits.
Grâce aux scripts Terraform et Ansible, toutes les opérations, de la création d'instances au démarrage du serveur, sont effectuées par seulement six commandes:
# aws ansible-playbook deploy-config.yml # ansible-playbook start-application.yml # ansible-playbook update-test-scenario.yml --ask-vault-pass # Jmeter , infrastructure-aws-cluster/jmeter_clients:~# terraform apply # jmeter ansible-playbook start-jmeter-server-cluster.yml # jmeter ansible-playbook start-stress-test.yml #
Mise à l'échelle dynamique du serveur
Aux heures de pointe de la production, nous avons plus de 20 000 utilisateurs en ligne en même temps, et à d'autres heures, il peut y en avoir 6 000. Cela n'a aucun sens de garder constamment le volume complet des serveurs, nous avons donc mis en place une mise à l'échelle automatique pour les serveurs de cartes sur lesquels les cartes s'ouvrent au moment où les utilisateurs les entrent, et pour les serveurs d'API qui traitent les demandes d'API. Désormais, les serveurs sont créés et supprimés si nécessaire.
Un tel mécanisme est très efficace dans les tests de charge: par défaut, nous pouvons avoir le nombre minimum de serveurs, et au moment du test, ils augmenteront automatiquement de la bonne quantité. Au début, nous pouvons avoir 4 serveurs de carte, et au maximum - jusqu'à 40. En même temps, de nouveaux serveurs ne sont pas créés immédiatement, mais seulement après le chargement des serveurs actuels. Par exemple, le critère de création de nouvelles instances peut être de 50% d'utilisation du processeur. Cela vous permet de ne pas ralentir la croissance des utilisateurs virtuels dans le script et de ne pas créer de serveurs inutiles.
Un avantage de cette approche est que grâce à la mise à l'échelle dynamique, nous apprenons la capacité dont nous avons besoin pour un nombre différent d'utilisateurs, ce que nous n'avions pas encore à la vente.
Collection de métriques comme sur prod
Il existe de nombreuses approches et outils pour surveiller les tests de résistance, mais nous avons suivi notre propre chemin.
Nous surveillons la production avec une pile standard: Logstash, Elasticsearch, Kibana, Prometheus et Grafana. Notre cluster de tests est similaire au produit, nous avons donc décidé de faire le même suivi que le prod, avec les mêmes métriques. Il y a deux raisons à cela:
- Pas besoin de construire un système de surveillance à partir de zéro, nous l'avons déjà complet et immédiatement;
- Nous testons en outre le suivi des ventes: si lors du suivi du test nous comprenons que nous n'avons pas suffisamment de données pour analyser le problème, alors elles ne seront pas suffisantes pour la production, lorsqu'un tel problème apparaîtra là.
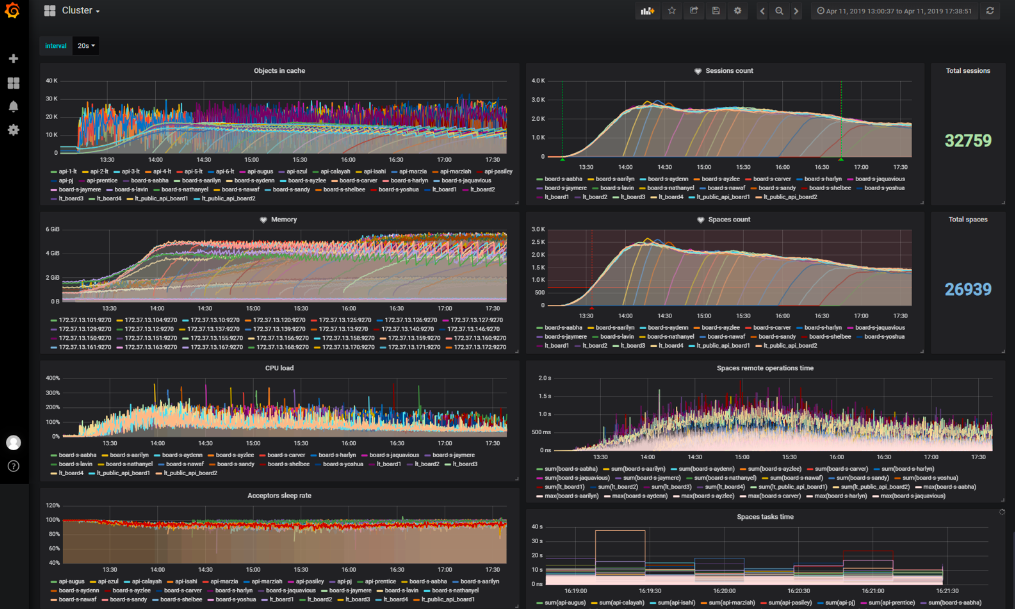
Ce que nous montrons dans les rapports
- Caractéristiques techniques du stand;
- Le script lui-même, décrit en mots, pas en code;
- Un résultat compréhensible pour tous les membres de l'équipe, développeurs et managers;
- Graphiques de l'état général du stand;
- Graphiques qui montrent un goulot d'étranglement ou qui sont affectés par l'optimisation vérifiée dans le test.
Il est important que tous les résultats soient stockés au même endroit. Il sera donc pratique de les comparer les uns aux autres d'un lancement à l'autre.
Nous réalisons des rapports dans notre produit
(exemple d'un tableau blanc avec un rapport) :
La création d'un rapport prend beaucoup de temps. Par conséquent, nous prévoyons d'automatiser la collecte d'informations générales à l'aide de
notre API publique .
L'infrastructure comme code
Nous sommes responsables de la qualité du produit n'est pas des ingénieurs QA, mais toute l'équipe. Les tests de résistance sont l'un des outils d'assurance qualité. Cool, si l'équipe comprend qu'il est important de vérifier sous charge les modifications qu'elle a apportées. Pour commencer à y penser, elle doit devenir responsable de la production. Ici, nous sommes aidés par les principes de la culture DevOps, que nous avons commencé à mettre en œuvre dans notre travail.
Mais commencer à penser à la réalisation de tests de résistance n'est que la première étape. L'équipe ne pourra pas réfléchir aux tests sans comprendre le dispositif de production. Nous avons rencontré un tel problème lorsque nous avons commencé à mettre en place le processus de réalisation des tests de charge en équipe. A cette époque, les équipes n'avaient aucun moyen de comprendre le dispositif de production, il leur était donc difficile de travailler sur la conception des tests. Il y avait plusieurs raisons: le manque de documentation à jour ou une personne qui garderait l'image entière dans la tête; croissance multiple de l'équipe de développement.
Pour aider les équipes à comprendre le travail de vente, l'approche Infrastructure peut être utilisée comme code, que nous avons commencé à utiliser dans l'équipe de développement.
Quels problèmes nous avons déjà commencé à résoudre en utilisant cette approche:
- Tout doit être scénarisé et peut être levé à tout moment. Cela réduit considérablement le temps de récupération des ventes en cas d'accident de centre de données et vous permet de conserver la bonne quantité d'environnements de test pertinents;
- Économies raisonnables: nous déployons des environnements sur Openstack lorsqu'il peut remplacer des plateformes coûteuses comme AWS;
- Les équipes elles-mêmes créent des tests de résistance parce qu'elles comprennent que l'appareil se vend;
- Le code remplace la documentation, il n'est donc pas nécessaire de la mettre à jour à l'infini, elle est toujours complète et à jour;
- Vous n'avez pas besoin d'un expert distinct dans un domaine étroit pour résoudre des problèmes ordinaires. Tout ingénieur peut comprendre le code;
- Avec une structure de vente claire, il est beaucoup plus facile de planifier des tests de charge de recherche tels que des tests de chaos de singe ou de longs tests de fuite de mémoire.
Je voudrais étendre cette approche non seulement à la création d'infrastructures, mais aussi au support de différents outils. Par exemple, le test de base de données, dont j'ai
parlé dans un article précédent , nous nous sommes complètement transformés en code. Pour cette raison, au lieu d'un site pré-préparé, nous avons un ensemble de scripts, avec lesquels en 7 minutes nous obtenons l'environnement configuré dans un compte AWS complètement vide et pouvons démarrer le test. Pour la même raison, nous considérons maintenant attentivement
Gatling , que les créateurs positionnent comme un outil pour «Charger le test en tant que code».
L'approche de l'infrastructure en tant que code implique une approche similaire pour la tester et les scripts que l'équipe écrit pour augmenter l'infrastructure de nouvelles fonctionnalités. Tout cela devrait être couvert par des tests. Il existe également divers cadres de test, tels que
Molecule . Il existe des outils pour tester le chaos des singes, pour AWS il y a des outils payants, pour Docker il y a
Pumba , etc. Ils vous permettent de résoudre différents types de tâches:
- Comment vérifier si l'une des instances d'AWS se bloque pour vérifier si la charge sur les serveurs restants est rééquilibrée et si le service survivra à une telle redirection pointue des demandes;
- Comment simuler le fonctionnement lent du réseau, sa rupture et d'autres problèmes techniques, après quoi la logique de l'infrastructure de service ne devrait pas se briser.
La solution de ces problèmes dans nos plans immédiats.
Conclusions
- Cela ne vaut pas le temps d' orchestrer manuellement l'infrastructure de test, il est préférable d'automatiser ces actions pour gérer de manière plus fiable tous les environnements, y compris prod;
- La mise à l'échelle dynamique réduit considérablement le coût de la maintenance des ventes et d'un large environnement de test, et réduit également le facteur humain lors de la mise à l'échelle;
- Vous ne pouvez pas utiliser un système de surveillance séparé pour les tests, mais retirez-le du marché;
- Il est important que les rapports des tests de résistance soient collectés automatiquement en un seul endroit et aient une vue uniforme. Cela leur permettra de comparer et d'analyser facilement les changements;
- Les tests de résistance deviendront un processus dans l'entreprise lorsque les équipes se sentiront responsables des ventes;
- Tests de charge - tests d'infrastructure. Si le test de charge a réussi, il est possible qu'il n'ait pas été compilé correctement. La validation de l'exactitude du test nécessite une compréhension approfondie des ventes. Les équipes devraient avoir la possibilité de comprendre indépendamment le dispositif de vente. Nous résolvons ce problème en utilisant l'infrastructure comme une approche de code;
- Les scripts de préparation d'infrastructure nécessitent également des tests comme tout autre code.