Il y a quelques mois, j'ai rencontré un problème, mon modèle basé sur des algorithmes d'apprentissage automatique ne fonctionnait tout simplement pas. J'ai longtemps réfléchi à la manière de résoudre ce problème et à un moment donné, j'ai réalisé que mes connaissances étaient très limitées et mes idées rares. Je connais quelques dizaines de modèles, et c'est une très petite partie de ces travaux qui peuvent être très utiles.
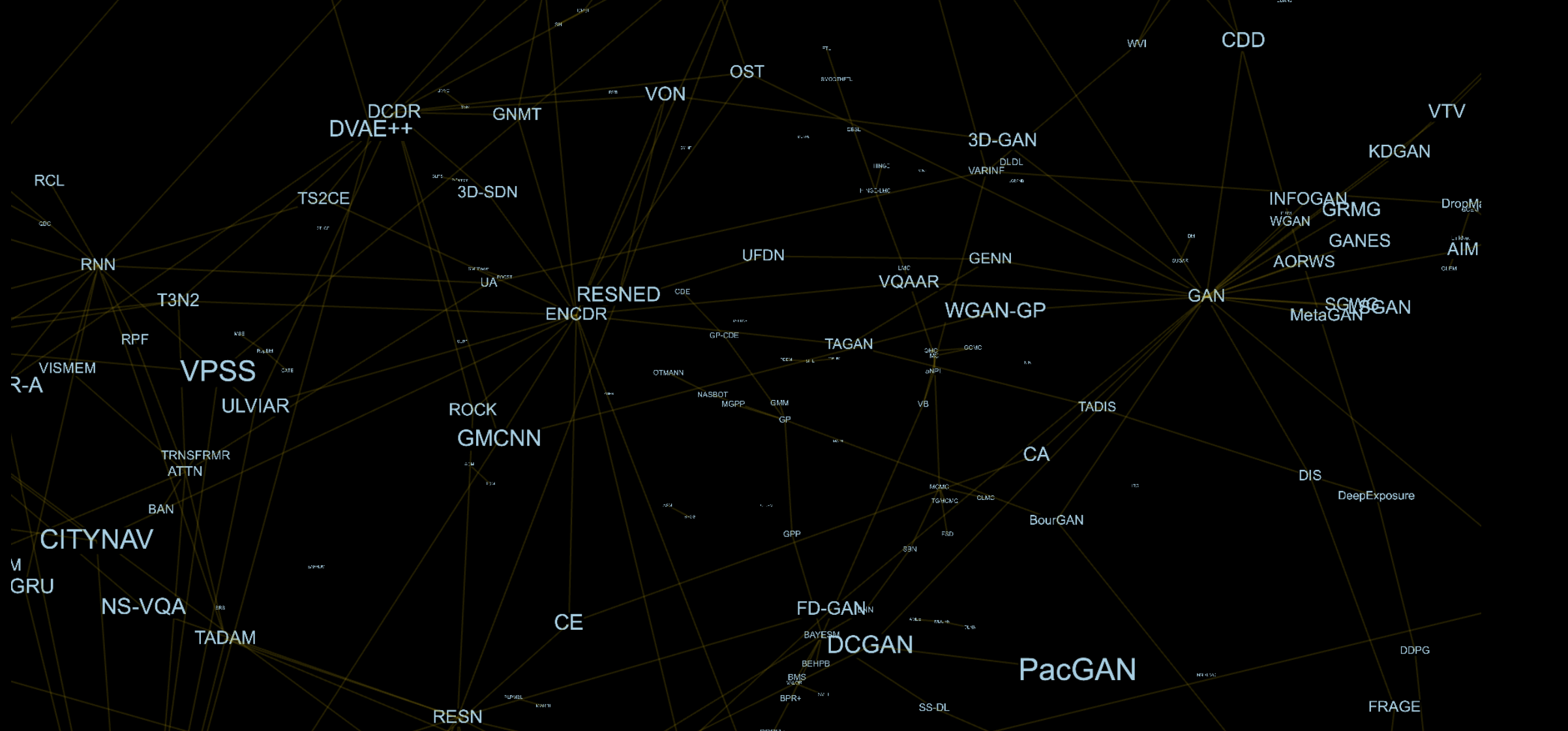
La première pensée qui m'est venue à l'esprit est que si je connais et comprends plus de modèles, mes qualités de chercheur et d'ingénieur dans leur ensemble augmenteront. Cette idée m'a incité à étudier les articles des récentes conférences d'apprentissage automatique. La structuration de ces informations est assez difficile, et il est nécessaire d'enregistrer les dépendances et les relations entre les méthodes. Je ne voulais pas présenter les dépendances sous forme de tableau ou de liste, mais je voulais quelque chose de plus naturel. En conséquence, je me suis rendu compte qu'avoir un graphique en trois dimensions avec des arêtes entre les modèles et leurs composants me semblait assez intéressant.
Par exemple, du point de vue architectural, GAN [1] se compose d'un générateur (GEN) et d'un discriminateur (DIS), l'Adversarial Auto-Encoder (AAE) [2] se compose de Auto-Encoder (AE) [3] et DIS,. Chaque composant est un sommet distinct dans ce graphique, donc pour AAE, nous aurons une arête avec AE et DIS.
Étape par étape, j'ai analysé les articles, écrit en quoi ils consistent, dans quel domaine ils sont appliqués, sur quelles données ils ont été testés, etc. Dans le processus, j'ai réalisé combien de solutions très intéressantes restent inconnues et ne trouvent pas leur application.
L'apprentissage automatique est divisé en domaines, chaque domaine essayant de résoudre un problème spécifique en utilisant des méthodes spécifiques. Ces dernières années, les frontières ont été presque effacées et il est pratiquement difficile d'identifier les composants qui ne sont utilisés que dans une certaine zone. Cette tendance conduit généralement à de meilleurs résultats, mais le problème est qu'avec l'augmentation du nombre d'articles, de nombreuses méthodes intéressantes passent inaperçues. Il y a plusieurs raisons à cela, et la vulgarisation par les grandes entreprises de certains domaines seulement joue un rôle important à cet égard. Conscient de cela, le graphique, qui était auparavant développé comme quelque chose de strictement personnel, est devenu public et ouvert.
Naturellement, j'ai mené des recherches et essayé de trouver des analogues à ce que je faisais. Il y a suffisamment de services qui vous permettent de suivre l'émergence de nouveaux articles dans ce domaine. Mais toutes ces méthodes visent avant tout à simplifier l'acquisition de connaissances, et non à contribuer à créer de nouvelles idées. La créativité est plus importante que l'expérience, et des outils qui peuvent vous aider à penser dans des directions différentes et à voir une image plus complète, il me semble que cela devrait devenir une partie intégrante du processus de recherche.
Nous avons des outils qui facilitent l'expérimentation, le lancement et l'évaluation de modèles, mais nous n'avons pas de méthodes qui nous permettent de générer et d'évaluer rapidement des idées.
En quelques mois, j'ai trié environ 250 articles de la dernière conférence NeurIPS et environ 250 autres articles sur lesquels ils sont basés. La plupart des zones m'étaient totalement inconnues, il a fallu plusieurs jours pour les comprendre. Parfois, je ne pouvais tout simplement pas trouver la description correcte des modèles et de leurs composants. À partir de là, la deuxième étape logique a été de créer la possibilité pour les auteurs d'ajouter et de modifier des méthodes dans le graphique eux-mêmes, car personne, à l'exception des auteurs de l'article, ne sait comment analyser et décrire leur méthode de la meilleure façon.
Un exemple de ce qui s'est produit en conséquence est présenté ici.
J'espère que ce projet sera utile à quelqu'un, ne serait-ce que parce qu'il permettra peut-être à quelqu'un d'avoir des associations qui pourront mener à une nouvelle idée intéressante. J'ai été surpris quand j'ai entendu comment l'idée de réseaux compétitifs génératifs est basée. Lors du podcast Intelligence du MIT [4], Yan Goodfellow a déclaré que l'idée de réseaux contradictoires est associée aux phases «positive» et «négative» de la formation pour la machine Boltzman [5].
Ce projet est mené par la communauté. Je voudrais le développer et motiver davantage de personnes à y ajouter des informations sur leurs méthodes ou à modifier ce qui a déjà été fait. Je crois que des informations de méthode plus précises et de meilleures technologies de visualisation aideront vraiment à en faire un outil utile.
Il y a beaucoup d'espace pour le développement du projet, à commencer par l'amélioration de la visualisation elle-même, pour finir par la possibilité de construire un graphique individuel avec la possibilité d'obtenir des recommandations pour les méthodes d'amélioration.
Quelques
détails techniques
peuvent être trouvés ici .
[1] Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio. Filets adverses génératifs.[2] Alireza Makhzani, Jonathon Shlens, Navdeep Jaitly, Ian Goodfellow, Brendan Frey. Autoencoders Adversarial.[3] Dana H. Ballard. Autoencoder.[4] Ian J. Goodfellow: podcast sur l'intelligence artificielle au MIT.[5] Ruslan Salakhutdinov, Geoffrey Hinton. Machines Boltzmann profondes