
La réunion annuelle de l'Association for Computational Linguistics (ACL) est la principale conférence sur le traitement du langage naturel. Il est organisé depuis 1962. Après le Canada et l'Australie, elle retourne en Europe et marche à Florence. Ainsi, cette année, il a été plus populaire auprès des chercheurs européens que EMNLP similaire.
Cette année, 660 articles sur 2900 soumis ont été publiés. Une énorme somme. Il n'est guère possible de faire une sorte de révision objective de ce qui était à la conférence. Par conséquent, je vais dire mes sentiments subjectifs de cet événement.
Je suis venu à la conférence pour montrer dans une session d'affiches
notre décision du concours Kaggle sur la résolution des pronoms genrés de Google. Notre solution reposait largement sur l'utilisation de
modèles BERT pré-
formés . Et, il s'est avéré que nous n'étions pas seuls dans ce domaine.
Bertologie

Il y avait tellement d'ouvrages basés sur BERT, décrivant ses propriétés et l'utilisant comme sous-sol, que même le terme Bertologie est apparu. En effet, les modèles BERT se sont avérés si efficaces que même de grands groupes de recherche comparent leurs modèles avec le BERT.
Ainsi, début juin, des travaux sont apparus sur
XLNet . Et juste avant la conférence -
ERNIE 2.0 et
RoBERTaFacebook RoBERTa
Lorsque le modèle XLNet a été introduit pour la première fois, certains chercheurs ont suggéré qu'il obtenait de meilleurs résultats non seulement en raison de son architecture et de ses principes de formation. Elle a également étudié sur un corps plus grand (près de 10 fois) que BERT et plus long (4 fois plus d'itérations).
Les chercheurs de Facebook ont montré que le BERT n'a pas encore atteint son maximum. Ils ont présenté une approche optimisée de l'enseignement du modèle BERT - RoBERTa (approche BERT robuste et optimisée).
Ne changeant rien dans l'architecture du modèle, ils ont changé la procédure de formation:
- Nous avons augmenté le corps pour l'entraînement, la taille du lot, la durée de la séquence et la durée de l'entraînement.
- La tâche de prédire la phrase suivante a été supprimée de la formation.
- Ils ont commencé à générer dynamiquement des jetons MASK (jetons que le modèle essaie de prédire lors de la pré-formation).
ERNIE 2.0 de Baidu
Comme tous les modèles récents populaires (BERT, GPT, XLM, RoBERTa, XLNet), ERNIE est basé sur le concept d'un transformateur avec un mécanisme d'auto-attention. Ce qui le distingue des autres modèles, ce sont les concepts d'apprentissage multi-tâches et d'apprentissage continu.
ERNIE apprend sur différentes tâches, mettant constamment à jour la représentation interne de son modèle de langage. Ces tâches ont, comme d'autres modèles, des objectifs d'auto-apprentissage (auto-supervisé et faiblement supervisé). Exemples de telles tâches:
- Récupérez l'ordre des mots correct dans une phrase.
- Capitalisation des mots.
- Définition des mots masqués.
Sur ces tâches, le modèle apprend de manière séquentielle, revenant aux tâches sur lesquelles il a été formé précédemment.
RoBERTa vs ERNIE
Dans les publications, RoBERTa et ERNIE ne sont pas comparés, car ils sont apparus presque simultanément. Ils sont comparés à BERT et XLNet. Mais ici, il n'est pas si facile de faire une comparaison. Par exemple, dans le
benchmark populaire,
GLUE XLNet est représenté par un ensemble de modèles. Et les chercheurs de Baidu sont plus intéressés à comparer des modèles uniques. En outre, étant donné que Baidu est une entreprise chinoise, ils souhaitent également comparer les résultats du travail avec la langue chinoise. Plus récemment, un nouveau benchmark est apparu:
SuperGLUE . Il n'y a pas encore beaucoup de solutions, mais RoBERTa est en premier lieu ici.
Mais dans l'ensemble, RoBERTa et ERNIE fonctionnent mieux que XLNet et nettement mieux que BERT. RoBERTa, à son tour, fonctionne légèrement mieux que ERNIE.
Graphes de connaissances
De nombreux travaux ont été consacrés à la combinaison de deux approches: les réseaux pré-formés et l'utilisation de règles sous forme de graphes de connaissances (Knowledge Graphs, KG).
Par exemple:
ERNIE: représentation linguistique améliorée avec des entités informatives . Cet article met en évidence l'utilisation de graphiques de connaissances en plus du modèle de langage BERT. Cela vous permet d'obtenir de meilleurs résultats sur des tâches telles que la détermination du type d'entité (
Typage d'entité) et classification des relations .
En général, la mode de choix des noms de modèles par les noms des personnages de Sesame Street entraîne des conséquences amusantes. Par exemple, cet ERNIE n'a rien à voir avec ERNIE 2.0 de Baidu, à propos duquel j'ai écrit ci-dessus.

Un autre travail intéressant sur la génération de nouvelles connaissances:
COMET: Commonsense Transformers for Automatic Knowledge Graph Construction . L'article examine la possibilité d'utiliser de nouvelles architectures basées sur des transformateurs pour la formation de réseaux basés sur la connaissance. Les bases de connaissances sous une forme simplifiée sont de nombreux triplets: sujet, attitude, objet. Ils ont pris deux ensembles de données de la base de connaissances: ATOMIC et ConceptNet. Et ils ont formé un réseau basé sur le modèle GPT (Generative Pre-formés Transformer). Le sujet et l'attitude ont été saisis et ont essayé de prédire l'objet. Ainsi, ils ont obtenu un modèle qui génère des objets par des sujets et des relations d'entrée.
Mesures
Un autre sujet intéressant lors de la conférence était la question du choix des métriques. Il est souvent difficile d'évaluer la qualité d'un modèle dans les tâches de traitement du langage naturel, ce qui ralentit les progrès dans ce domaine de l'apprentissage automatique.
Dans un article sur l'
étude des métriques d'évaluation de récapitulation dans l' article
Plage de notation appropriée , Maxim Peyar discute de l'utilisation de diverses métriques dans un problème de récapitulation de texte. Ces métriques ne sont pas toujours bien corrélées entre elles, ce qui interfère avec la comparaison objective de divers algorithmes.
Ou voici un travail intéressant:
l'évaluation automatique des textes multi-phrases . Dans ce document, les auteurs présentent une métrique qui peut remplacer BLEU et ROUGE sur des tâches où vous devez évaluer des textes de plusieurs phrases.
La métrique BLEU peut être représentée en tant que précision - combien de mots (ou n-grammes) de la réponse du modèle sont contenus dans la cible. ROUGE is Recall - combien de mots (ou n-grammes) de la cible sont contenus dans la réponse du modèle.
La métrique proposée dans l'article est basée sur la métrique WMD (Word Mover's Distance) - la distance entre deux documents. Elle est égale à la distance minimale entre les mots en deux phrases dans l'espace de la représentation vectorielle de ces mots. Plus d'informations sur WMD peuvent être trouvées dans le tutoriel, qui utilise
WMD de Word2Vec et
de GloVe .
Dans leur article, ils proposent une nouvelle métrique: WMS (Word Mover's Similarity).
WMS(A, B) = exp(−WMD(A, B))
Ils définissent ensuite le SMS (Similarité du moteur de phrase). Il utilise une approche similaire à l'approche avec WMS. En tant que représentation vectorielle de la phrase, ils prennent le vecteur moyen des mots de la phrase.
Lors du calcul du WMS, les mots sont normalisés par leur fréquence dans le document. Lors du calcul des phrases SMS sont normalisées par le nombre de mots dans la phrase.
Enfin, la métrique S + WMS est une combinaison de WMS et SMS. Dans leur article, ils soulignent que leurs mesures sont mieux corrélées avec l'évaluation manuelle d'une personne.
Chatbots
À mon avis, la partie la plus utile de la conférence a été les séances d'affiches. Tous les reportages n'étaient pas intéressants, mais si vous avez commencé à en écouter certains, vous ne partirez pas pour un autre au milieu du reportage. Les affiches sont une autre affaire. Il y en a plusieurs dizaines lors de la session d'affiches. Vous choisissez ceux que vous aimez et vous pouvez, en règle générale, parler directement avec le développeur des détails techniques. À propos, il y a un site intéressant avec des
affiches de conférences . Certes, il y a des affiches de deux conférences là-bas, et on ne sait pas si le site sera mis à jour.
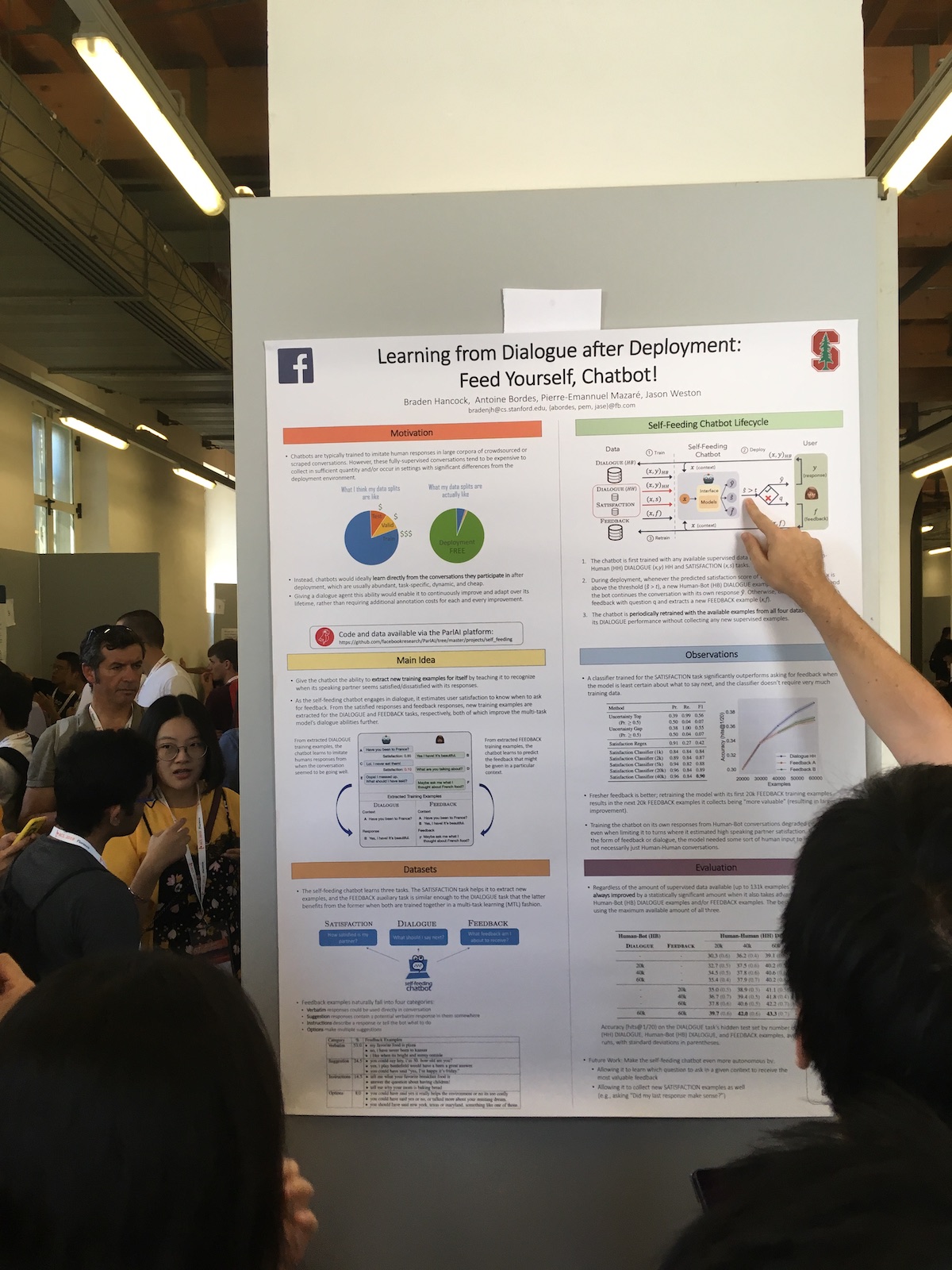
Lors des séances d'affiches, les grandes entreprises ont souvent présenté des travaux intéressants. Par exemple, voici un article Facebook
Apprendre du dialogue après le déploiement: nourrissez-vous, Chatbot! .
La particularité de leur système est l'utilisation accrue des réponses des utilisateurs. Ils ont un classificateur qui évalue la satisfaction de l'utilisateur avec le dialogue. Ils utilisent ces informations pour différentes tâches:
- Utilisez une mesure de satisfaction comme mesure de la qualité.
- Ils forment le modèle, appliquant ainsi l'approche de l'apprentissage continu (apprentissage continu).
- Utilisez directement dans le dialogue. Exprimer une réaction humaine si l'utilisateur est satisfait. Ou ils demandent ce qui ne va pas si l'utilisateur n'est pas satisfait.
D'après les rapports, il y avait une histoire intéressante sur le chatbot chinois de Microsoft.
La conception et la mise en œuvre de XiaoIce, un chatbot social empathiqueLa Chine est déjà l'un des leaders dans l'introduction de technologies d'intelligence artificielle. Mais souvent, ce qui se passe en Chine n'est pas bien connu en Europe. Et XiaoIce est un projet incroyable. Il existe déjà depuis cinq ans. Peu de chatbots de cet âge travaillent actuellement. En 2018, il comptait déjà 660 millions d'utilisateurs.
Le système possède à la fois un bot de discussion et un système de compétences. Le bot a déjà 230 compétences, c'est-à-dire qu'il ajoute environ une compétence par semaine.
Pour évaluer la qualité du bot de bavardage, ils utilisent la durée du dialogue. Et pas en quelques minutes, comme cela se fait souvent, mais en nombre de répliques dans une conversation. Ils appellent cette métrique Conversation-tours par session (CPS) et écrivent qu'à l'heure actuelle sa valeur moyenne est de 23, ce qui est le meilleur indicateur parmi des systèmes similaires.
En général, le projet est très populaire en Chine. En plus du bot lui-même, le système écrit de la poésie, dessine des images,
sort une collection de vêtements , chante des chansons.
Traduction automatique
De tous les discours auxquels j'ai assisté, le plus vivant était le rapport d'
interprétation simultanée de Liang Huang, représentant Baidu Research.
Il a parlé de ces difficultés dans la traduction simultanée moderne:
- Il n'y a que 3 000 interprètes simultanés certifiés dans le monde.
- Les traducteurs ne peuvent travailler que 15 à 20 minutes en continu.
- Environ 60% seulement du texte source est traduit.
La traduction de phrases entières a déjà atteint un bon niveau, mais pour la traduction simultanée, il y a encore place à amélioration. À titre d'exemple, il a cité leur système d'interprétation simultanée, qui a fonctionné à la Conférence mondiale de Baidu. Le délai de traduction en 2018 par rapport à 2017 est passé de 10 à 3 secondes.
Peu d'équipes le font et peu de systèmes de travail existent. Par exemple, lorsque Google traduit la phrase que vous écrivez en ligne, il refait constamment la dernière phrase. Et ce n'est pas de la traduction simultanée, car avec la traduction simultanée nous ne pouvons pas changer les mots déjà dits.

Dans leur système, ils utilisent la traduction de préfixe - partie d'une phrase. Autrement dit, ils attendent quelques mots et commencent à traduire, essayant de deviner ce qui apparaîtra dans la source. La taille de ce décalage est mesurée en mots et est adaptative. Après chaque étape, le système décide s'il vaut la peine d'attendre ou s'il peut déjà être traduit. Pour évaluer ce retard, ils introduisent la métrique suivante:
métrique de retard
moyen (AL) .
La principale difficulté de la traduction simultanée est l'ordre différent des mots dans les langues. Et le contexte aide à lutter contre cela. Par exemple, vous devez souvent traduire les discours des politiciens, et ils sont assez stéréotypés. Mais il y a aussi des problèmes. Puis l'orateur a plaisanté sur Trump. Donc, dit-il, si Bush s'est envolé pour Moscou, il est fort probable que pour rencontrer Poutine. Et si Trump s'est envolé, alors il peut se rencontrer et jouer au golf. En général, lors de la traduction, les gens inventent souvent, ajoutent quelque chose d'eux-mêmes. Et disons, si vous avez besoin de traduire une sorte de blague, et qu'ils ne peuvent pas le faire tout de suite, ils peuvent dire: "Une blague a été dite ici, juste rire."
Il y avait aussi un article sur la traduction automatique qui a reçu le prix «Le meilleur long papier»:
Combler l'écart entre la formation et l'inférence pour la traduction automatique neuronale .
Il décrit un tel problème de traduction automatique. Dans le processus d'apprentissage, nous générons une traduction mot à mot basée sur le contexte des mots connus. Dans le processus d'utilisation du modèle, nous nous appuyons sur le contexte des mots nouvellement générés. Il existe un écart entre la formation du modèle et son utilisation.
Pour réduire cet écart, les auteurs proposent au stade de la formation dans le contexte de mélanger les mots prédits par le modèle en cours de formation. L'article discute du choix optimal de ces mots générés.
Conclusion
Bien sûr, une conférence n'est pas seulement des articles et des rapports. C'est aussi la communication, les rencontres et autres réseaux. De plus, les organisateurs de la conférence tentent en quelque sorte de divertir les participants. À l'ACL, lors de la fête principale, il y avait une représentation de ténors, l'Italie après tout. Et pour résumer, il y a eu des annonces des organisateurs d'autres conférences. Et la réaction la plus violente parmi les participants a été provoquée par les messages des organisateurs de l'EMNLP que cette année, la fête principale se tiendra à Hong Kong Disneyland, et en 2020, la conférence se tiendra en République dominicaine.