En général, en utilisant la commande shell, vous pouvez obtenir n'importe quelle métrique sans écrire de code ou d'intégrations. Ainsi, dans la console, il devrait y avoir un outil de visualisation simple et pratique.
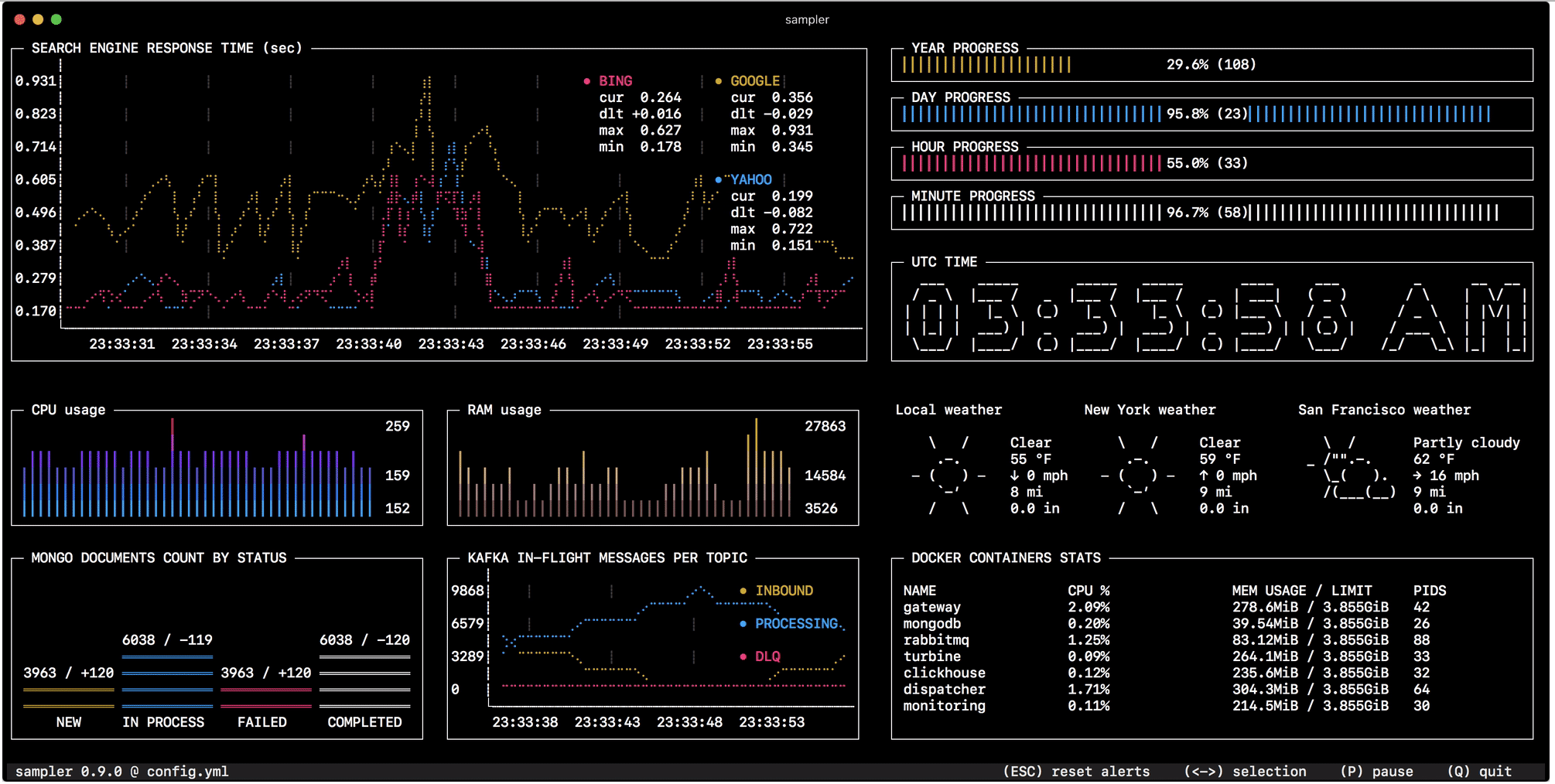
La surveillance du changement d'état dans la base de données, la surveillance de la taille des files d'attente, la télémétrie à partir de serveurs distants, l'exécution de déploiements de scripts et la réception de notifications à la fin sont configurées en une minute avec un simple fichier YAML.
Le code est disponible sur github . Instructions d' installation - pour Linux, macOS et Windows (expérimental).
Pourquoi en ai-je besoin alors qu'il existe des systèmes de surveillance complets?
Je dois dire tout de suite que ce n'est en aucun cas une alternative aux tableaux de bord et à la surveillance à grande échelle. Comparer Sampler avec Prometheus + Grafana revient à comparer la tail et less avec Elastic Stack ou Splunk .
Mais si vous élevez et configurez la surveillance de la production pour votre tâche - comme un canon sur des moineaux, alors peut-être Sampler sera la réponse à la question. Il a été conçu comme un outil de prototypage, de démonstration ou simplement d'observation de métriques sur un environnement local et un serveur distant.
Il faut donc le mettre sur tous les serveurs?
Non, Sampler peut être exécuté localement, mais les mesures peuvent être prises à partir de nombreuses machines distantes. Chaque composant du tableau de bord a une section init où vous pouvez entrer via ssh (ou effectuer toute autre action pour entrer dans le interactive shell - établir une connexion à la base de données, se connecter via JMX, se connecter à l'API, etc.)
Vues des composants et exemples de configuration
Les exemples de configuration affichent des commandes pour macOS. Beaucoup fonctionneront sous Linux, mais certains doivent être adaptés.
Runchart

La configuration runcharts: - title: Search engine response time rate-ms: 500 # sampling rate, default = 1000 scale: 2 # number of digits after sample decimal point, default = 1 legend: enabled: true # enables item labels, default = true details: false # enables item statistics: cur/min/max/dlt, default = true items: - label: GOOGLE sample: curl -o /dev/null -s -w '%{time_total}' https://www.google.com - label: YAHOO sample: curl -o /dev/null -s -w '%{time_total}' https://search.yahoo.com - label: BING sample: curl -o /dev/null -s -w '%{time_total}' https://www.bing.com
Sparkline

La configuration sparklines: - title: CPU usage rate-ms: 200 scale: 0 sample: ps -A -o %cpu | awk '{s+=$1} END {print s}' - title: Free memory pages rate-ms: 200 scale: 0 sample: memory_pressure | grep 'Pages free' | awk '{print $3}'
Barchart

La configuration barcharts: - title: Local network activity rate-ms: 500 # sampling rate, default = 1000 scale: 0 # number of digits after sample decimal point, default = 1 items: - label: UDP bytes in sample: nettop -J bytes_in -l 1 -m udp | awk '{sum += $4} END {print sum}' - label: UDP bytes out sample: nettop -J bytes_out -l 1 -m udp | awk '{sum += $4} END {print sum}' - label: TCP bytes in sample: nettop -J bytes_in -l 1 -m tcp | awk '{sum += $4} END {print sum}' - label: TCP bytes out sample: nettop -J bytes_out -l 1 -m tcp | awk '{sum += $4} END {print sum}'
Jauge

La configuration gauges: - title: Minute progress rate-ms: 500 # sampling rate, default = 1000 scale: 2 # number of digits after sample decimal point, default = 1 percent-only: false # toggle display of the current value, default = false color: 178 # 8-bit color number, default one is chosen from a pre-defined palette cur: sample: date +%S # sample script for current value max: sample: echo 60 # sample script for max value min: sample: echo 0 # sample script for min value - title: Year progress cur: sample: date +%j max: sample: echo 365 min: sample: echo 0
Zone de texte

La configuration textboxes: - title: Local weather rate-ms: 10000 # sampling rate, default = 1000 sample: curl wttr.in?0ATQF border: false # border around the item, default = true color: 178 # 8-bit color number, default is white - title: Docker containers stats rate-ms: 500 sample: docker stats --no-stream --format "table {{.Name}}\t{{.CPUPerc}}\t{{.MemUsage}}\t{{.PIDs}}"
Asciibox

La configuration asciiboxes: - title: UTC time rate-ms: 500 # sampling rate, default = 1000 font: 3d # font type, default = 2d border: false # border around the item, default = true color: 43 # 8-bit color number, default is white sample: env TZ=UTC date +%r
Fonctionnalité supplémentaire
Déclencheurs
Les déclencheurs vous permettent de déclencher une action supplémentaire si la valeur mesurée satisfait à la condition spécifiée. La condition et la réaction sont également des commandes shell dans lesquelles les variables $label , $cur et $prev sont fournies. Tout d'abord, les déclencheurs ont été conçus pour les alertes (les notifications sonores et visuelles sont intégrées), mais avec l'option de votre propre script pour répondre au déclenchement d'un déclencheur, vous pouvez personnaliser son action comme vous le souhaitez (par exemple, envoyer une notification à votre téléphone avec Pushover )
L'exemple ci-dessous illustre la configuration des déclencheurs. Si la latence de la réponse du moteur de recherche dépasse 0,3 s - l'échantillonneur clignote la cloche du terminal standard, perd le ton quindar de la NASA, affiche une notification visuelle sur le graphique et exécute un script qui, dans ce cas, énonce la valeur de latence mesurée en voix:
runcharts: - title: SEARCH ENGINE RESPONSE TIME (sec) rate-ms: 200 items: - label: GOOGLE sample: curl -o /dev/null -s -w '%{time_total}' https://www.google.com - label: YAHOO sample: curl -o /dev/null -s -w '%{time_total}' https://search.yahoo.com triggers: - title: Latency threshold exceeded condition: echo "$prev < 0.3 && $cur > 0.3" |bc -l # "1" TRUE actions: terminal-bell: true # default = false sound: true # NASA quindar tone, default = false visual: true # default = false script: 'say alert: ${label} latency exceeded ${cur} second'
Coque interactive
Si vous devez entrer le shell interactif avant de commencer l'échantillonnage (pour une connexion unique à la base de données, une connexion SSH, une connexion à JMX, etc.), vous pouvez spécifier un init script qui sera exécuté une fois au démarrage. Un exemple de connexion et d'interrogation de mongoDB:
textboxes: - title: MongoDB polling rate-ms: 500 init: mongo --quiet --host=localhost test # sample: Date.now(); # mongo shell transform: echo result = $sample #
De plus, le mode PTY et les scripts d' initiation à plusieurs étapes sont pris en charge .
Variables
Si la configuration contient des parties fréquemment utilisées que vous ne souhaitez pas répéter, vous pouvez les placer dans des variables et les utiliser n'importe où dans le fichier YML.
En pratique
En tant que programmeur backend, je dois souvent déboguer, prototyper et mesurer. D'où la nécessité régulière d'une visualisation et d'un suivi rapides. Écrire quelque chose de personnalisé à chaque fois est excessivement long, mais si le processus de personnalisation était rapide et (plus ou moins) pratique, une telle visualisation pourrait bien gagner du temps et résoudre des problèmes. Je n'ai rien trouvé de tel, il a donc été décidé d'écrire un tel outil moi-même et de le rendre aussi universellement configurable que possible.
Pour la toute première fois pour sa destination, j'ai commencé à l'utiliser pour déboguer le mécanisme de regroupement et d'accumulation de données, qui change rapidement le statut des "événements" en mémoire. La lecture de l'état du système à partir des journaux ou l'interrogation de compteurs individuels pour chacun des statuts ne vous aide pas à naviguer rapidement et à comprendre ce qui se passe, mais un coup d'œil à Sampler résout complètement ce problème -
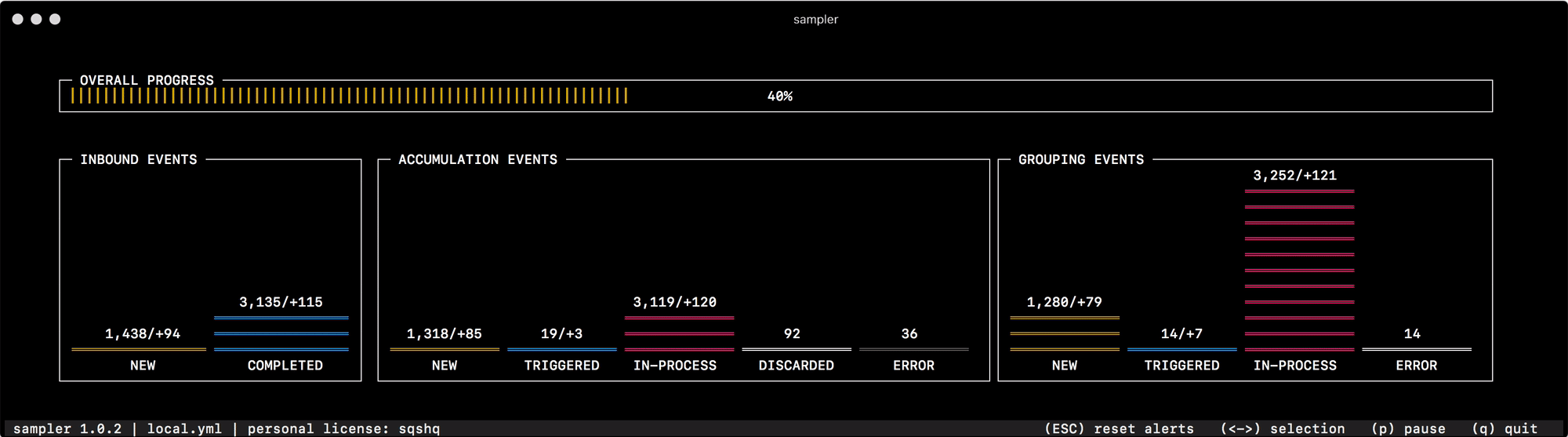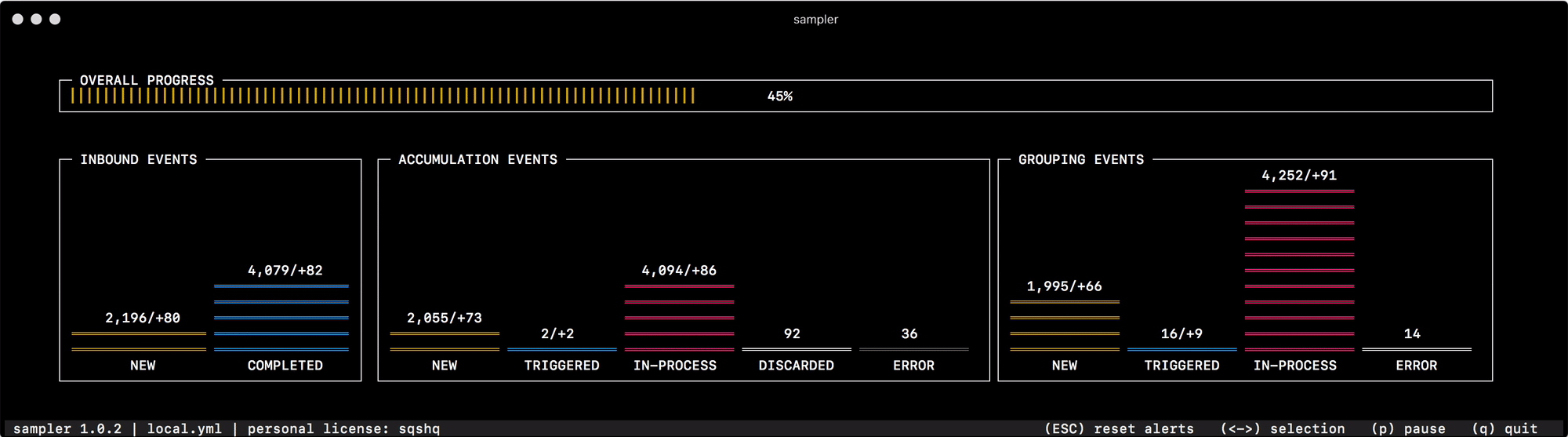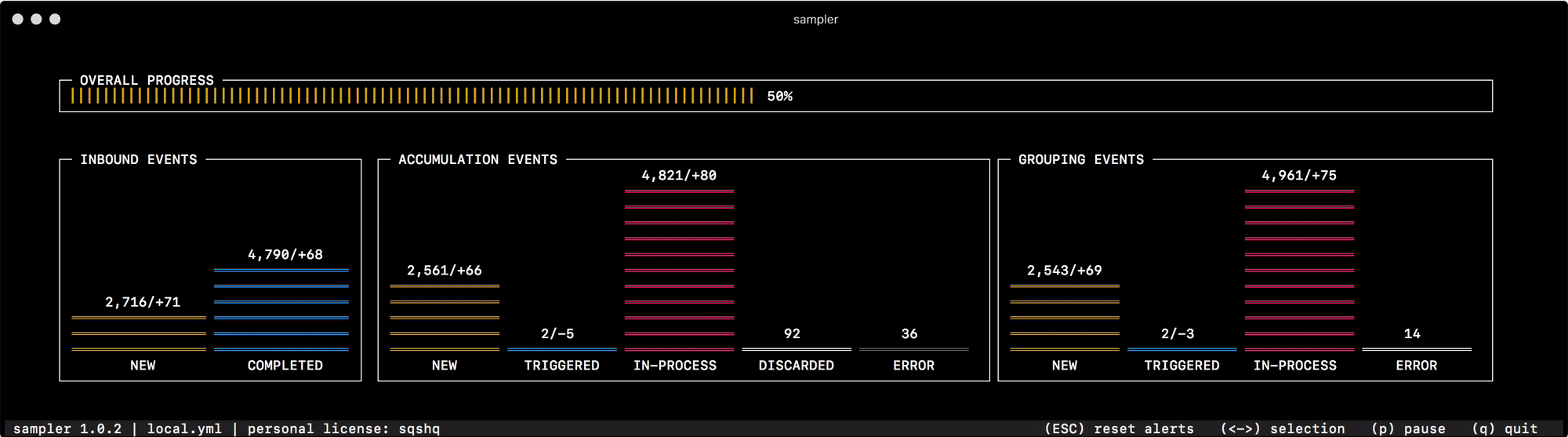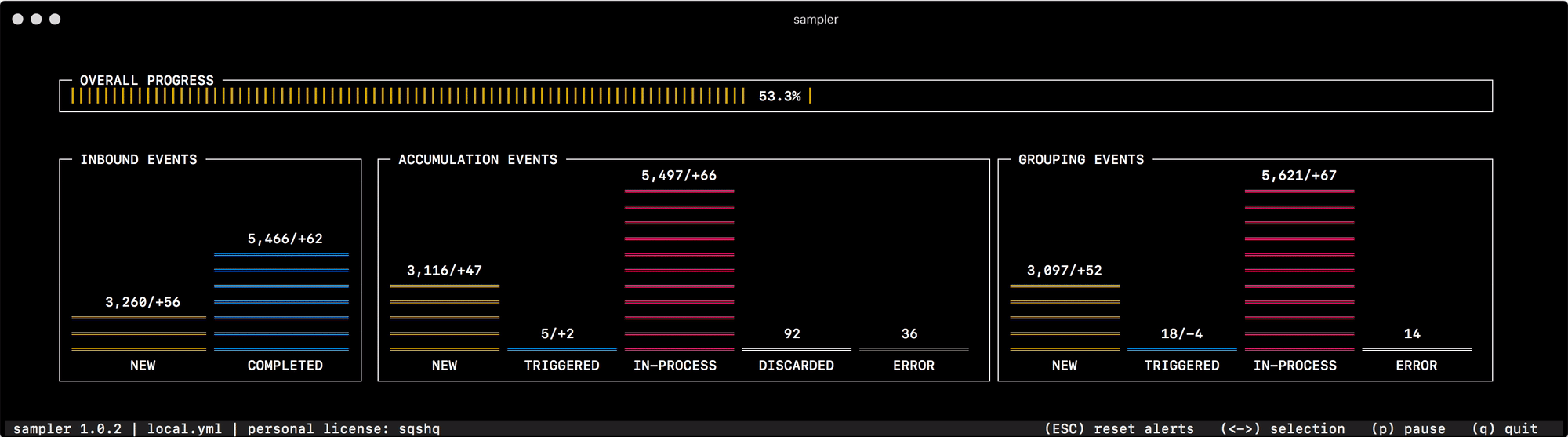
Pour tout ce que j'utilise moi-même, j'ai préparé une collection de "recettes" - configurations de mook que vous pouvez copier et commencer immédiatement à personnaliser pour vos tâches
- Connexions à la base de données: MySQL, PostgreSQL, MongoDB, Neo4J
- Kafka
- Docker
- Ssh
- Jmx
Cette liste sera complétée (et votre contribution est la bienvenue), et en attendant, dans les problèmes, les gens ont commencé à partager leurs configurations pour les tableaux de bord Kubernetes, Github, etc.
C'est tout, habr. Je serais heureux si quelqu'un serait utile.