
Dans cet article, je veux offrir une alternative au style de conception de test traditionnel en utilisant les concepts de programmation fonctionnelle de Scala. L'approche a été inspirée par les nombreux mois de douleur dus au soutien de dizaines et de centaines de tests de chute et par un désir ardent de les rendre plus faciles et plus compréhensibles.
Malgré le fait que le code soit écrit en Scala, les idées proposées seront pertinentes pour les développeurs et les testeurs dans tous les langages qui prennent en charge le paradigme de programmation fonctionnelle. Vous pouvez trouver un lien vers Github avec une solution complète et un exemple à la fin de l'article.
Le problème
Si vous avez déjà traité des tests (peu importe - tests unitaires, d'intégration ou fonctionnels), il est fort probable qu'ils aient été écrits sous la forme d'un ensemble d'instructions séquentielles. Par exemple:
C'est la méthode préférée pour la plupart, ne nécessitant pas de développement, pour décrire les tests. Notre projet comprend environ 1000 tests de différents niveaux (tests unitaires, tests d'intégration, de bout en bout) et tous, jusqu'à récemment, étaient écrits dans un style similaire. Au fur et à mesure que le projet progressait, nous avons commencé à ressentir des problèmes importants et un ralentissement avec le soutien de tels tests: mettre les tests en ordre n'a pas pris moins de temps que d'écrire du code pertinent pour l'entreprise.
Lors de l'écriture de nouveaux tests, il fallait toujours penser à zéro comment préparer les données. Souvent, copiez-collez les étapes des tests voisins. En conséquence, lorsque le modèle de données dans l'application a changé, le château de cartes s'est effondré et a dû être collecté d'une nouvelle manière à chaque test: au mieux, juste un changement dans les fonctions des assistants, au pire - une immersion profonde dans le test et la réécriture.
Lorsque le test s'est écrasé honnêtement - c'est-à-dire à cause d'un bogue dans la logique métier, et non à cause de problèmes dans le test lui-même - il était impossible de comprendre où quelque chose s'est mal passé sans débogage. Étant donné qu'il a fallu beaucoup de temps pour comprendre les tests, personne ne connaissait parfaitement les exigences - comment le système devrait se comporter dans certaines conditions.
Toute cette douleur est le symptôme de deux problèmes plus profonds de cette conception:
- Le contenu du test est autorisé sous une forme trop lâche. Chaque test est unique, comme un flocon de neige. La nécessité de lire les détails du test prend beaucoup de temps et se démotive. Les détails non importants détournent l'attention de l'essentiel - les exigences vérifiées par le test. Le copier-coller devient le principal moyen d'écrire de nouveaux cas de test.
- Les tests n'aident pas le développeur à localiser les bogues, mais signalent uniquement un problème. Pour comprendre l'état dans lequel le test est effectué, vous devez le restaurer dans votre tête ou vous connecter avec un débogueur.
Modélisation
Pouvons-nous faire mieux? (Spoiler: nous pouvons.) Voyons en quoi consiste ce test.
val db: Database = Database.forURL(TestConfig.generateNewUrl()) migrateDb(db) insertUser(db, id = 1, name = "test", role = "customer") insertPackage(db, id = 1, name = "test", userId = 1, status = "new") insertPackageItems(db, id = 1, packageId = 1, name = "test", price = 30) insertPackageItems(db, id = 2, packageId = 1, name = "test", price = 20) insertPackageItems(db, id = 3, packageId = 1, name = "test", price = 40)
Le code testé, en règle générale, attendra la saisie de certains paramètres explicites - identificateurs, tailles, volumes, filtres, etc. De plus, il aura souvent besoin de données du monde réel - nous voyons que l'application fait référence aux menus et aux modèles de menus base de données. Pour une exécution de test fiable, nous avons besoin d'un appareil - l'état dans lequel le système et / ou les fournisseurs de données doivent se trouver avant le début du test et les paramètres d'entrée, souvent liés à l'état.
Nous allons préparer les dépendances avec ce luminaire - remplir la base de données (file d'attente, service externe, etc.). Avec la dépendance préparée, nous initialisons la classe testée (services, modules, référentiels, etc.).
val svc = new SomeProductionLogic(db) val result = svc.calculatePrice(packageId = 1)
En exécutant le code de test sur certains paramètres d'entrée, nous obtenons un résultat ( sortie ) significatif pour l'entreprise - à la fois explicite (renvoyé par la méthode) et implicite - un changement dans l'état notoire: base de données, service externe, etc.
result shouldBe 90
Enfin, nous vérifions que les résultats sont exactement ce qu'ils attendaient, en résumant le test avec une ou plusieurs affirmations .
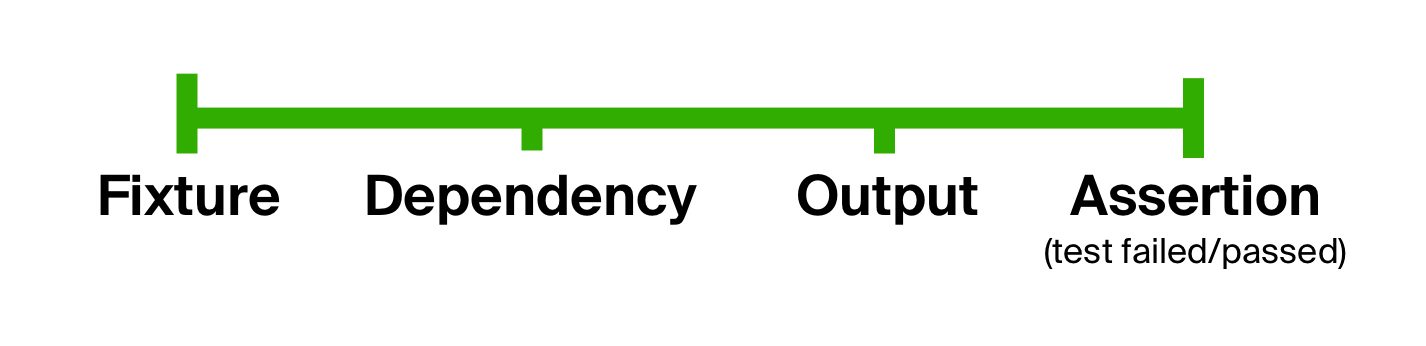
On peut conclure qu'en général, le test comprend les mêmes étapes: préparation des paramètres d'entrée, exécution du code de test sur eux et comparaison des résultats avec ceux attendus. Nous pouvons utiliser ce fait pour nous débarrasser du premier problème du test - forme trop lâche, divisant clairement le test en étapes. Cette idée n'est pas nouvelle et a longtemps été utilisée dans les tests de type BDD ( développement axé sur le comportement ).
Et l'extensibilité? Chacune des étapes du processus de test peut contenir autant d'étapes intermédiaires que vous le souhaitez. À l'avenir, nous pourrions former un appareil, en créant d'abord une sorte de structure lisible par l'homme, puis en la convertissant en objets qui remplissent la base de données. Le processus de test est extensible à l'infini, mais, en fin de compte, il se résume toujours aux étapes principales.

Exécution de tests
Essayons de réaliser l'idée de diviser le test en étapes, mais nous déterminons d'abord comment nous aimerions voir le résultat final.
En général, nous voulons faire de la rédaction et des tests de support un processus moins laborieux et plus agréable. Moins d'instructions non explicites (répétées ailleurs) sont moins explicites dans le corps du test, moins il faudra apporter de modifications aux tests après avoir changé de contrat ou de refactorisation et moins de temps il faudra pour lire le test. La conception du test devrait encourager la réutilisation des morceaux de code fréquemment utilisés et empêcher la copie irréfléchie. Ce serait bien si les tests avaient un aspect uniforme. La prévisibilité améliore la lisibilité et fait gagner du temps - imaginez combien de temps il faudrait aux étudiants en physique pour maîtriser chaque nouvelle formule si elle était décrite en mots libres plutôt qu'en langage mathématique.
Ainsi, notre objectif est de cacher tout ce qui est distrayant et superflu, ne laissant que les informations essentielles à la compréhension de l'application: ce qui est testé, ce qui est attendu en entrée et ce qui est attendu en sortie.
Revenons au modèle de l'appareil de test. Techniquement, chaque point de ce graphique peut être représenté par un type de données et des transitions de l'une à l'autre - des fonctions. Vous pouvez passer du type de données initial au type final en appliquant la fonction suivante au résultat de la précédente une par une. En d'autres termes, utiliser une composition de fonctions : préparer les données (appelons-les prepare ), exécuter le code de test ( execute ) et vérifier le résultat attendu ( check ). Nous passerons le premier point du graphique, fixture, à l'entrée de cette composition. La fonction d' ordre supérieur qui en résulte est appelée fonction de cycle de vie de test.
Fonction cycle de vie def runTestCycle[FX, DEP, OUT, F[_]]( fixture: FX, prepare: FX => DEP, execute: DEP => OUT, check: OUT => F[Assertion] ): F[Assertion] =
La question est: d'où viennent les fonctions internes? Nous préparerons les données d'un nombre limité de façons - pour remplir la base de données, se mouiller, etc. - par conséquent, les options pour la fonction de préparation seront communes à tous les tests. En conséquence, il sera plus facile de créer des fonctions de cycle de vie spécialisées qui masquent la mise en œuvre spécifique de la préparation des données. Étant donné que les méthodes d'invocation du code en cours de vérification et de vérification sont relativement uniques pour chaque test, l' execute et la check seront fournies explicitement.
Fonction cycle de vie adaptée aux tests d'intégration sur la base de données En déléguant toutes les nuances administratives à la fonction de cycle de vie, nous avons la possibilité d'étendre le processus de test sans entrer dans un test déjà écrit. En raison de la composition, nous pouvons infiltrer n'importe où dans le processus, y extraire ou ajouter des données.
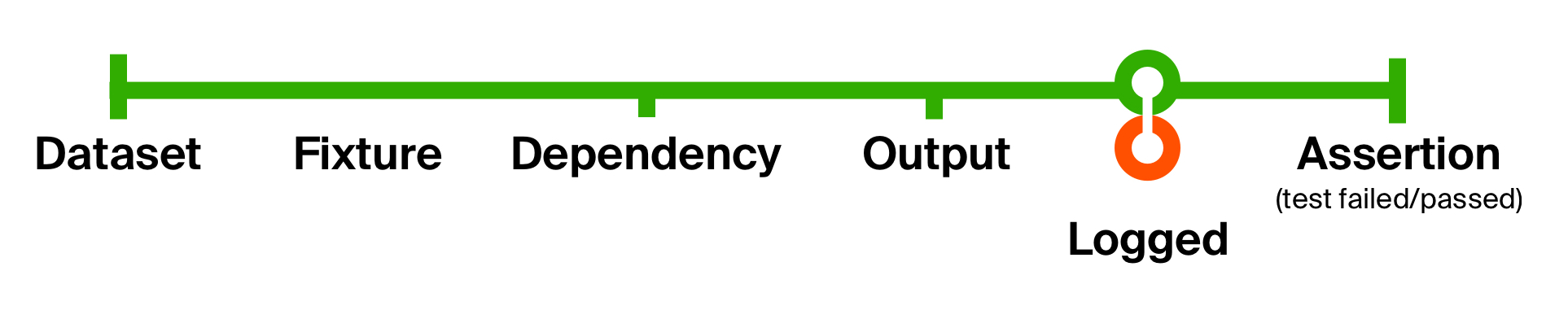
Pour mieux illustrer les possibilités de cette approche, nous allons résoudre le deuxième problème de notre test initial - le manque d'informations de support pour localiser les problèmes. Ajoutez la journalisation lors de la réception d'une réponse de la méthode testée. Notre journalisation ne changera pas le type de données, mais ne produira qu'un effet secondaire - l'affichage d'un message sur la console. Par conséquent, après l'effet secondaire, nous le rendrons tel quel.
Fonction de journalisation du cycle de vie def logged[T](implicit loggedT: Logged[T]): T => T = (that: T) => {
Avec un mouvement aussi simple, nous avons ajouté la journalisation du résultat renvoyé et l'état de la base de données dans chaque test . L'avantage de ces petites fonctions est qu'elles sont faciles à comprendre, faciles à composer pour une réutilisation et faciles à éliminer si elles ne sont plus nécessaires.

En conséquence, notre test ressemblera à ceci:
val fixture: SomeMagicalFixture = ???
Le corps du test est devenu concis, les appareils et les contrôles peuvent être réutilisés dans d'autres tests, et nous ne préparons manuellement la base de données nulle part ailleurs. Un seul problème subsiste ...
Préparation du luminaire
Dans le code ci-dessus, nous avons utilisé l'hypothèse que le luminaire proviendra d'un endroit prêt à l'emploi et qu'il ne doit être transféré qu'à la fonction de cycle de vie. Étant donné que les données sont un ingrédient clé des tests simples et pris en charge, nous ne pouvons que nous pencher sur la façon de les former.
Supposons que notre magasin de tests possède une base de données moyenne de taille moyenne (pour simplifier, un exemple avec 4 tables, mais en réalité il peut y en avoir des centaines). Une partie contient des informations générales, une partie - directement commerciale, et toutes ensemble, elle peut être connectée à plusieurs entités logiques à part entière. Les tables sont interconnectées par des clés (clés étrangères ) - pour créer une entité Bonus , vous avez besoin de l'entité Package et, à son tour, de l' User . Et ainsi de suite.

Les circonstances des limitations de circuits et toutes sortes de hacks conduisent à des incohérences et, par conséquent, à tester l'instabilité et des heures de débogage passionnant. Pour cette raison, nous remplirons honnêtement la base de données.
Nous pourrions utiliser des méthodes militaires pour le remplissage, mais même avec un examen superficiel de cette idée, de nombreuses questions difficiles se posent. Qu'est-ce qui préparera les données des tests pour ces méthodes elles-mêmes? Dois-je réécrire les tests si le contrat change? Que se passe-t-il si les données sont fournies par une application non testée (par exemple, importées par quelqu'un d'autre)? Combien de requêtes différentes devront être effectuées afin de créer une entité dépendante de nombreuses autres?
Remplissage de la base lors du test initial insertUser(db, id = 1, name = "test", role = "customer") insertPackage(db, id = 1, name = "test", userId = 1, status = "new") insertPackageItems(db, id = 1, packageId = 1, name = "test", price = 30) insertPackageItems(db, id = 2, packageId = 1, name = "test", price = 20) insertPackageItems(db, id = 3, packageId = 1, name = "test", price = 40)
Les méthodes auxiliaires dispersées, comme dans l'exemple d'origine, sont le même problème, mais avec une sauce différente. Ils nous attribuent la responsabilité de la gestion des objets dépendants et de leurs relations, et nous aimerions éviter cela.
Idéalement, j'aimerais avoir ce type de données, un seul coup d'œil suffit pour comprendre en termes généraux dans quel état sera le système pendant le test. L'un des bons candidats pour la visualisation de l'état est une table (à la fois des ensembles de données en PHP et Python), où il n'y a rien de superflu à l'exception des champs critiques pour la logique métier. Si la logique métier change dans une fonction, toute la prise en charge des tests sera réduite à la mise à jour des cellules de l'ensemble de données. Par exemple:
val dataTable: Seq[DataRow] = Table( ("Package ID", "Customer's role", "Item prices", "Bonus value", "Expected final price") , (1, "customer", Vector(40, 20, 30) , Vector.empty , 90.0) , (2, "customer", Vector(250) , Vector.empty , 225.0) , (3, "customer", Vector(100, 120, 30) , Vector(40) , 210.0) , (4, "customer", Vector(100, 120, 30, 100) , Vector(20, 20) , 279.0) , (5, "vip" , Vector(100, 120, 30, 100, 50), Vector(10, 20, 10), 252.0) )
À partir de notre table, nous générerons des relations clés - entité par ID. Dans ce cas, si l'entité dépend d'une autre, une clé sera formée pour la dépendance. Il peut arriver que deux entités différentes génèrent une dépendance avec le même identifiant, ce qui peut entraîner une violation de la restriction sur la clé primaire de la base de données ( clé primaire ). Mais à ce stade, les données sont extrêmement bon marché à dédupliquer - puisque les clés ne contiennent que des identifiants, nous pouvons les placer dans une collection qui fournit la déduplication, par exemple, dans Set . Si cela s'avère insuffisant, nous pouvons toujours effectuer une déduplication plus intelligente sous la forme d'une fonction supplémentaire compilée en fonction de cycle de vie.
Exemple clé sealed trait Key case class PackageKey(id: Int, userId: Int) extends Key case class PackageItemKey(id: Int, packageId: Int) extends Key case class UserKey(id: Int) extends Key case class BonusKey(id: Int, packageId: Int) extends Key
Nous déléguons la génération de faux contenu à des champs (par exemple, des noms) à une classe distincte. Ensuite, en recourant à l'aide de cette classe et aux règles de conversion des clés, nous obtenons des objets chaîne destinés directement à l'insertion dans la base de données.
Exemple de ligne object SampleData { def name: String = "test name" def role: String = "customer" def price: Int = 1000 def bonusAmount: Int = 0 def status: String = "new" } sealed trait Row case class PackageRow(id: Int, name: String, userId: Int, status: String) extends Row case class PackageItemRow(id: Int, packageId: Int, name: String, price: Int) extends Row case class UserRow(id: Int, name: String, role: String) extends Row case class BonusRow(id: Int, packageId: Int, bonusAmount: Int) extends Row
Les fausses données par défaut, en règle générale, ne nous suffiront pas, nous devrons donc être en mesure de redéfinir des champs spécifiques. Nous pouvons utiliser des lentilles - parcourez toutes les lignes créées et modifiez les champs de celles qui sont nécessaires. Comme les lentilles sont finalement des fonctions ordinaires, elles peuvent être composites, et c'est leur utilité.
Exemple d'objectif def changeUserRole(userId: Int, newRole: String): Set[Row] => Set[Row] = (rows: Set[Row]) => rows.modifyAll(_.each.when[UserRow]) .using(r => if (r.id == userId) r.modify(_.role).setTo(newRole) else r)
Grâce à la composition, dans l'ensemble du processus, nous pouvons appliquer diverses optimisations et améliorations - par exemple, grouper des lignes dans des tableaux afin qu'elles puissent être insérées avec une seule insert , réduire le temps de test ou sécuriser l'état final de la base de données pour simplifier les problèmes de capture.
Fonction de mise en forme du luminaire def makeFixture[STATE, FX, ROW, F[_]]( state: STATE, applyOverrides: F[ROW] => F[ROW] = x => x ): FX = (extractKeys andThen deduplicateKeys andThen enrichWithSampleData andThen applyOverrides andThen logged andThen buildFixture) (state)
Tous ensemble nous donneront un appareil qui remplit la dépendance pour le test - la base de données. Dans le test lui-même, rien de superflu ne sera vu, à l'exception de l'ensemble de données d'origine - tous les détails seront cachés dans la composition des fonctions.

Notre suite de tests ressemblera maintenant à ceci:
val dataTable: Seq[DataRow] = Table( ("Package ID", "Customer's role", "Item prices", "Bonus value", "Expected final price") , (1, "customer", Vector(40, 20, 30) , Vector.empty , 90.0) , (2, "customer", Vector(250) , Vector.empty , 225.0) , (3, "customer", Vector(100, 120, 30) , Vector(40) , 210.0) , (4, "customer", Vector(100, 120, 30, 100) , Vector(20, 20) , 279.0) , (5, "vip" , Vector(100, 120, 30, 100, 50), Vector(10, 20, 10), 252.0) ) " -" - { "'customer'" - { " " - { "< 250 - " - { "(: )" in calculatePriceFor(dataTable, 1) "(: )" in calculatePriceFor(dataTable, 3) } ">= 250 " - { " - 10% " in calculatePriceFor(dataTable, 2) " - 10% " in calculatePriceFor(dataTable, 4) } } } "'vip' - 20% , " in calculatePriceFor(dataTable, 5) }
Un code d'aide:
L'ajout de nouveaux cas de test à la table devient une tâche triviale, qui vous permet de vous concentrer sur la couverture du nombre maximum de conditions aux limites , plutôt que sur un passe-partout.
Réutilisation du code de préparation des appareils sur d'autres projets
Eh bien, nous avons écrit beaucoup de code pour préparer des appareils dans un projet spécifique, en y consacrant beaucoup de temps. Et si nous avons plusieurs projets? Sommes-nous condamnés à réinventer la roue et à copier-coller à chaque fois?
Nous pouvons faire abstraction de la préparation des luminaires à partir d'un modèle de domaine spécifique. Dans le monde de la FP, il y a le concept d'une classe de types . En bref, les classes de types ne sont pas des classes de POO, mais quelque chose comme des interfaces, elles définissent un comportement de groupe de types. La différence fondamentale est que ce groupe de types n'est pas déterminé par l'héritage de classe, mais par l'instanciation, comme les variables ordinaires. Comme pour l'héritage, la résolution d'instances de classes de types (via implicits ) se produit statiquement , au stade de la compilation. Pour simplifier, pour nos besoins, les classes de types peuvent être considérées comme des extensions de Kotlin et C # .
Pour mettre en gage un objet, nous n'avons pas besoin de savoir ce que cet objet a à l'intérieur, quels champs et méthodes il a. Il est seulement important pour nous que le comportement du log avec une certaine signature lui soit défini. Il serait Logged d'implémenter une certaine interface Logged dans chaque classe, et ce n'est pas toujours possible - par exemple, dans une bibliothèque ou des classes standard. Dans le cas des classes de caractères, tout est beaucoup plus simple. Nous pouvons créer une instance de la Logged , par exemple, pour les appareils, et l'afficher sous une forme lisible. Et pour tous les autres types, créez une instance pour le type Any et utilisez la méthode toString standard pour enregistrer gratuitement tous les objets dans leur représentation interne.
Un exemple de la classe Tagged et de ses instances trait Logged[A] { def log(a: A)(implicit logger: Logger): A }
En plus de la journalisation, nous pouvons étendre cette approche à l'ensemble du processus de préparation des luminaires. La solution de test proposera ses propres timeclasses et l'implémentation abstraite de fonctions basées sur celles-ci. La responsabilité du projet qui l'utilise est d'écrire sa propre instance de classes de types pour les types.
Lors de la conception du générateur de luminaires, je me suis concentré sur la mise en œuvre des principes de programmation et de conception SOLIDE comme indicateur de sa stabilité et de son adaptabilité à différents systèmes:
- Le principe de responsabilité unique : chaque classe de type décrit exactement un aspect du comportement de type.
- Le principe ouvert et fermé : nous ne modifions pas le type de combat existant pour les tests, nous l'étendons avec les instances des tyclasses.
- Le principe de substitution de Liskov n'a pas d'importance dans ce cas, car nous n'utilisons pas d'héritage.
- Le principe de ségrégation d'interface : nous utilisons de nombreuses classes de temps spécialisées au lieu d'une seule globale.
- Le principe d'inversion de dépendance : la mise en œuvre du générateur de fixture ne dépend pas de types de combat spécifiques, mais de calendriers abstraits.
Après s'être assuré que tous les principes sont respectés, on peut affirmer que notre solution semble suffisamment soutenue et évolutive pour être utilisée dans différents projets.
Après avoir écrit les fonctions du cycle de vie, la génération d'appareils et la conversion d'ensembles de données en appareils, ainsi que l'abstraction d'un modèle de domaine spécifique de l'application, nous sommes enfin prêts à adapter notre solution à tous les tests.
Résumé
Nous sommes passés du style traditionnel (étape par étape) de la conception de test à celui fonctionnel. Un style étape par étape est bon dans les premiers stades et les petits projets, car il ne nécessite pas de travail supplémentaire et ne limite pas le développeur, mais commence à perdre lorsqu'il y a beaucoup de tests sur le projet. Le style fonctionnel n'est pas conçu pour résoudre tous les problèmes de test, mais il peut grandement faciliter la mise à l'échelle et la prise en charge des tests dans les projets où leur nombre est de plusieurs centaines ou milliers. Les tests de style fonctionnel sont plus compacts et se concentrent sur ce qui est vraiment important (données, code de test et résultat attendu), et non sur des étapes intermédiaires.
De plus, nous avons examiné un exemple vivant de la puissance des concepts de composition et de typeclasses dans la programmation fonctionnelle. Avec leur aide, il est facile de concevoir des solutions, dont une partie intégrante sont l'extensibilité et la réutilisabilité.
, , , . , , , -. , . !
: Github