 TL; DR
TL; DR : architecture client-serveur de notre outil de gestion de configuration interne, QControl.
Au sous-sol, il existe un protocole de transport à deux couches fonctionnant avec des messages compressés par gzip sans décompression entre les points de terminaison. Les routeurs et les points finaux distribués reçoivent les mises à jour de configuration, et le protocole lui-même permet d'installer des relais localisés intermédiaires. Il est basé sur une conception de
sauvegarde différentielle («récente-stable», expliquée plus loin) et utilise le langage de requête JMESpath et le modèle Jinja pour le rendu de la configuration.
Qrator Labs opère et maintient un réseau d'atténuation distribué à l'échelle mondiale. Notre réseau est anycast, basé sur l'annonce de nos sous-réseaux via BGP. Être un réseau de diffusion BGP situé physiquement dans plusieurs régions du monde nous permet de traiter et de filtrer le trafic illégitime plus près de la dorsale Internet - les opérateurs de niveau 1.
D'un autre côté, être un réseau géographiquement réparti supporte ses difficultés. La communication entre les points de présence du réseau (PoP) est essentielle pour qu'un fournisseur de sécurité ait une configuration cohérente pour tous les nœuds du réseau et la mette à jour en temps opportun et de manière cohérente. Donc, pour fournir le meilleur service possible aux clients, nous avons dû trouver un moyen de synchroniser les données de configuration entre les différents continents de manière fiable.
Au début, il y avait la Parole ... qui est rapidement devenue un protocole de communication nécessitant une mise à niveau.
Le point clé de l'existence de QControl et la principale raison de consacrer beaucoup de temps et d'efforts à la construction d'un tel protocole est le besoin d'obtenir une source faisant autorité de la configuration et éventuellement de synchroniser nos PoP avec elle. Le stockage n'était qu'une des nombreuses fonctionnalités requises du développement de QControl. En plus de cela, nous avions également besoin d'une intégration avec la périphérie existante et future, de validations de données intelligentes (et personnalisables) et d'une différenciation d'accès. De plus, nous voulions que ce système gère les choses par le biais de commandes, et non par des modifications manuelles de fichiers. Avant QControl, les données étaient envoyées aux points de présence plus ou moins manuellement. Si un PoP n'était pas disponible pour le moment et que nous avons oublié de le mettre à jour plus tard, la configuration a été désynchronisée et un dépannage fastidieux a été nécessaire pour le ramener à la synchronisation.
Voici le système que nous avons conçu:
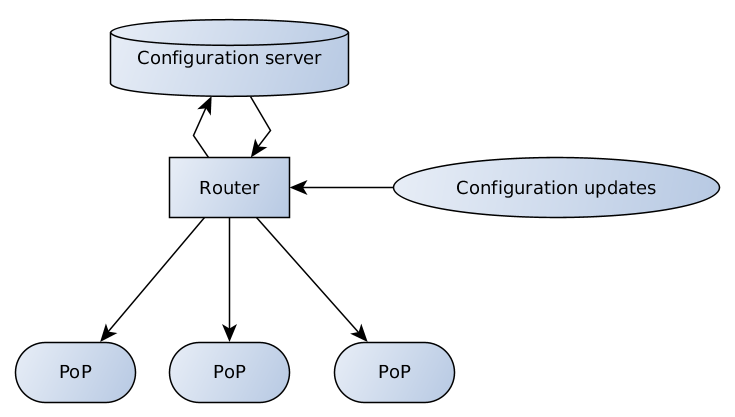
Le serveur de configuration est responsable de la validation et du stockage des données; le routeur a différents points d'extrémité pour recevoir et relayer les mises à jour de configuration des clients et de l'équipe de support vers le serveur et du serveur vers les PoP.
La qualité de la connexion Internet est encore assez diversifiée dans le monde entier - pour illustrer cela, imaginons un traceroute simple de Prague, de la République tchèque à Singapour et à Hong Kong.

MTR de Prague à Singapour

Même deuxième capture d'écran avec traceroute vers Hong Kong
Des nombres de latence élevés signifient une vitesse médiocre. En outre, il y a une forte perte de paquets. Les numéros de bande passante ne compensent pas ce problème, qui doit toujours être pris en considération lors de la construction de réseaux décentralisés.
La configuration PoP complète est un bloc de données assez important et doit être transférée à de nombreux récepteurs différents via des connexions non fiables. Heureusement, bien que la configuration change fréquemment, elle change par petits incréments.
Conception récente et stable
C'est une décision assez simple de construire un réseau distribué basé sur des mises à jour incrémentielles. Bien qu'il y ait beaucoup de problèmes avec les diff, ils sont difficiles à construire correctement: nous devons enregistrer tous les diff entre les points de référence quelque part, pour pouvoir les renvoyer si quelqu'un a perdu quelque chose. Chaque destination doit les appliquer de manière cohérente. Dans le cas où il y a plusieurs destinations, cela pourrait prendre beaucoup de temps sur tout le réseau. Le destinataire doit également être en mesure de demander des pièces manquantes et, bien entendu, la partie centrale doit répondre précisément à cette demande, en n'envoyant que les données manquantes.
Ce que nous avons construit à la fin est tout à fait une chose - nous n'avons qu'une seule couche de référence, la fixe "stable" et une seule diff, "récente" pour elle. Chaque récent est basé sur la dernière version stable et est suffisant pour reconstruire les données de configuration. Lorsqu'un nouveau récent arrive à destination, l'ancien est jetable.
Cela nous laisse parfois le besoin d'envoyer une nouvelle configuration stable car les récents deviennent trop gros. En outre, une note importante ici est que nous pouvons faire tout cela en diffusant / en diffusant des mises à jour, sans se soucier de la capacité des destinations de réception à assembler les pièces. Une fois que nous vérifions que tout le monde a la bonne écurie, ils sont tous nourris avec juste le récent frais. Faut-il dire que ça marche? Oui. Les écuries sont mises en cache sur le serveur de configuration et les récepteurs, les dernières étant recréées en cas de besoin.
Architecture de transport à deux couches
Pourquoi avons-nous exactement construit notre transport en deux couches? La réponse est assez simple: nous voulions séparer le routage de l'application, en nous inspirant du modèle OSI avec ses couches de transport et d'application. Nous avons donc séparé le protocole de transport (Thrift) du format de sérialisation de commande de haut niveau (msgpack). C'est pourquoi un routeur (qui fait de la multidiffusion / diffusion / relais) ne regarde ni à l'intérieur du msgpack, ni n'extrait ou ne compresse la charge utile et ne fait que la transmission.
Wiki d' épargne:
Apache Thrift vous permet de définir des types de données et des interfaces de service dans un fichier de définition simple. En prenant ce fichier en entrée, le compilateur génère du code à utiliser pour créer facilement des clients et des serveurs RPC qui communiquent de manière transparente entre les langages de programmation. Au lieu d'écrire une charge de code standard pour sérialiser et transporter vos objets et invoquer des méthodes distantes.Nous avons adopté le framework Thrift en raison de son RPC et de la prise en charge de plusieurs langues à la fois. Comme toujours, les parties faciles sont faciles à construire: le client et le serveur. Cependant, le routeur était assez difficile à casser, en partie en raison de l'absence de solution prête à l'emploi à l'époque.

Il existe d'autres options, comme le protobuf / gRPC, bien que lorsque nous avons commencé notre projet, le gRPC était immature et nous avons hésité à l'utiliser.
Bien sûr, nous pourrions (et devrions!) Créer notre propre roue. Il serait plus facile de créer un protocole personnalisé pour ce dont nous avons besoin, avec le routeur, car le client-serveur est plus simple à programmer que de créer un routeur fonctionnel avec Thrift. Cependant, il existe une négativité traditionnelle vis-à-vis des protocoles personnalisés et des implémentations de bibliothèques populaires, et il y a toujours le "comment le porter ensuite dans d'autres langues". Nous avons donc décidé de laisser tomber les idées wheely.
Description de Msgpack:
MessagePack est un format de sérialisation binaire efficace. Il vous permet d'échanger des données entre plusieurs langues comme JSON. Mais c'est plus rapide et plus petit. Les petits entiers sont codés en un seul octet, et les chaînes courtes typiques ne nécessitent qu'un seul octet supplémentaire en plus des chaînes elles-mêmes.À la première couche, nous avons un Thrift avec les informations minimales nécessaires pour que le routeur envoie un message. Sur la deuxième couche, nous avons des structures msgpack compressées.
Nous avons voté pour le msgpack car il est plus rapide et plus compact que JSON. Cependant, ce qui est encore plus important, c'est qu'il prend en charge les types de données personnalisés, permettant certaines fonctionnalités intéressantes comme les «blancs» et le transfert de données binaires brutes.
JmespathJMESPath est un langage de requête pour JSON.C'est la seule description que nous obtenons de la documentation officielle de JMESPath, mais en réalité, c'est bien plus que cela. JMESPath permet de rechercher et de filtrer des structures arborescentes arbitraires et même d'appliquer des transformations de données à la volée. Nous utilisons ce langage de requête pour obtenir des informations pertinentes à partir du gros objet de configuration.
Alors que la configuration entière a une structure arborescente, nous extrayons les sous-arbres pertinents pour différentes cibles de configuration.
Il est également suffisamment flexible pour changer la sous-arborescence, indépendamment d'un modèle de configuration ou d'autres plugins de configuration. Pour le rendre encore meilleur, JMES Path est facilement extensible et permet d'écrire des filtres personnalisés et des routines de transformation de données. Cependant, il a besoin d'un peu de cerveau pour comprendre.
JinjaPour certaines cibles, nous devons rendre la configuration dans des fichiers, nous avions donc besoin d'un moteur de modèle, où Jinja est un choix évident. Jinja génère un fichier de configuration à partir du modèle et des données reçues au point de destination.
Pour rendre le fichier de configuration, nous avons besoin d'une demande jmespath, d'un modèle pour le chemin et du fichier de destination, d'un modèle pour la configuration elle-même. De plus, à ce stade, il est bon de spécifier les droits d'accès aux fichiers. Tout cela a heureusement été combiné dans un seul fichier - avant le modèle de configuration, nous avons mis un en-tête YAML, décrivant le reste. Par exemple:
---
selector: "[@][?@.fft._meta.version == `42`] | items([0].fft_config || `{}`)"
destination_filename: "fft/{{ match[0] }}.json"
file_mode: 0644
reload_daemons: [fft]
...
{{ dict(match[1]) | json(indent=2, sort_keys=True) }}
Pour faire la configuration d'une nouvelle périphérie, nous ajoutons un nouveau fichier de modèle, aucune modification du code source et les mises à jour du logiciel PoP ne sont nécessaires.
Qu'est-ce qui a changé après l'implémentation de l'outil de gestion de configuration QControl?
Tout d'abord, nous avons obtenu des mises à jour de configuration cohérentes et fiables sur tout notre réseau.
Deuxièmement, nous mettons un outil puissant pour la validation de la configuration et le changement entre les mains de notre équipe d'assistance et de nos clients.
Nous avons accompli cela en employant une conception récente et stable pour simplifier la communication entre le serveur de configuration et les destinataires de configuration, en utilisant un protocole de communication à deux couches pour prendre en charge les routeurs indépendants de la charge utile et en implémentant le moteur de rendu de configuration basé sur Jinja pour prendre en charge une grande variété de fichiers de configuration pour notre périphérie diversifiée.