 TL; DR
TL; DR : Description de l'architecture client-serveur de notre système de gestion de configuration de réseau interne, QControl. Il est basé sur un protocole de transport à deux niveaux qui fonctionne avec des messages compressés avec gzip sans décompression entre les points de terminaison. Les routeurs et les points finaux distribués reçoivent des mises à jour de configuration, et le protocole lui-même permet l'installation de relais intermédiaires localisés. Le système est construit sur le principe de la
sauvegarde différentielle («récent-stable», expliqué ci-dessous) et utilise le langage de requête JMESpath avec le moteur de modèle Jinja pour rendre les fichiers de configuration.
Qrator Labs gère un réseau d'atténuation des attaques distribué à l'échelle mondiale. Notre réseau fonctionne sur le principe de anycast, et les sous-réseaux sont annoncés via BGP. En tant que réseau de diffusion BGP situé physiquement dans plusieurs régions de la Terre, nous pouvons traiter et filtrer le trafic illégitime plus près du cœur de l'Internet - les opérateurs de niveau 1.
D'un autre côté, être un réseau géographiquement distribué n'est pas facile. La communication entre les points de présence du réseau est essentielle pour un fournisseur de services de sécurité afin d'avoir une configuration cohérente de tous les nœuds du réseau, en les mettant à jour en temps opportun. Par conséquent, afin de fournir le plus haut niveau possible de services de base aux consommateurs, nous devions trouver un moyen de synchroniser de manière fiable les données de configuration entre les continents.
Au commencement était la Parole. Il est rapidement devenu un protocole de communication nécessitant une mise à jour.
La pierre angulaire de l'existence de QControl et en même temps la principale raison de consacrer beaucoup de temps et de ressources à la construction d'un tel protocole est la nécessité d'obtenir une source de configuration unique faisant autorité et, en fin de compte, de synchroniser nos points de présence avec lui. Le référentiel lui-même n'était qu'une des nombreuses exigences lors du développement de QControl. En plus de cela, nous avions également besoin d'une intégration avec les services existants et prévus aux points de présence (TP), des méthodes intelligentes (et personnalisables) de validation des données, ainsi que le contrôle d'accès. En plus de cela, nous voulions également gérer un tel système à l'aide de commandes, plutôt que d'apporter des modifications aux fichiers. Avant QControl, les données étaient envoyées aux points de présence en mode presque manuel. Si l'un des points de présence n'était pas disponible et que nous avons oublié de le mettre à jour plus tard, la configuration s'est révélée désynchronisée - vous avez dû passer du temps à le remettre en service.
En conséquence, nous sommes arrivés avec le schéma suivant:
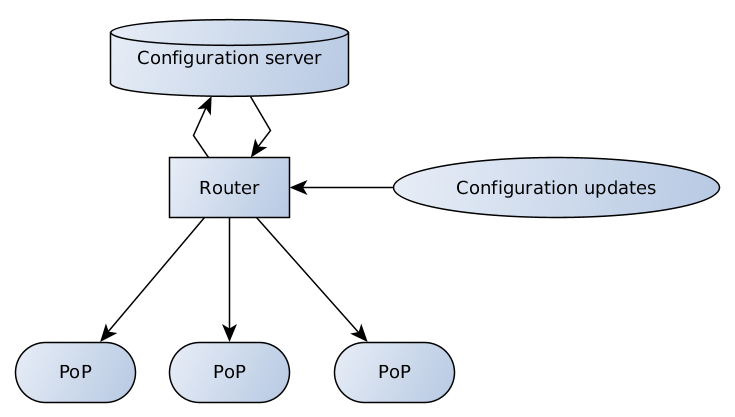
Le serveur de configuration est responsable de la validation et du stockage des données, le routeur dispose de plusieurs points d'extrémité qui reçoivent et diffusent les mises à jour de configuration des clients et des équipes d'assistance au serveur, et du serveur aux points de présence.
La qualité de la connexion Internet est encore sensiblement différente dans différentes parties du monde - pour illustrer cette thèse, regardons un simple MTR de Prague, de la République tchèque à Singapour et à Hong Kong.

MTR de Prague à Singapour

Même chose à Hong Kong
Des retards élevés signifient moins de vitesse. De plus, il y a perte de paquets. La largeur des canaux ne compense pas ce problème, qui doit toujours être pris en compte lors de la construction de systèmes décentralisés.
Une configuration complète de point de présence est une quantité importante de données qui doivent être envoyées à de nombreux destinataires via des connexions non fiables. Heureusement, bien que la configuration change constamment, cela se produit par petites portions.
Conception récente et stable
On peut dire que la construction d'un réseau distribué sur le principe des mises à jour incrémentales est une solution assez évidente. Mais il y a beaucoup de problèmes avec les différences. Nous devons conserver tous les différences entre les points de contrôle, ainsi que pouvoir les envoyer au cas où quelqu'un manquerait certaines des données. Chaque destination doit les appliquer dans une séquence strictement définie. En règle générale, dans le cas de plusieurs destinations, une telle opération peut prendre beaucoup de temps. Le destinataire doit également pouvoir demander les pièces manquantes et, bien entendu, la partie centrale doit répondre correctement à une telle demande, en n'envoyant que les données manquantes.
En conséquence, nous sommes arrivés à une solution plutôt intéressante - nous n'avons qu'une seule couche de support, fixe, appelons-la stable, et une seule différence car elle est récente. Chaque récent est basé sur la dernière stable formée et est suffisant pour reconstruire les données de configuration. Dès qu'un nouveau récent arrive à destination, l'ancien n'est plus nécessaire.
Il ne reste que de temps en temps d'envoyer une nouvelle configuration stable, par exemple, du fait que la récente est devenue trop volumineuse. Il est également important ici que nous envoyions toutes ces mises à jour en mode diffusion / multidiffusion, sans se soucier des destinataires individuels et de leur capacité à collecter des données ensemble. Dès que nous sommes convaincus que tout le monde a la bonne écurie, nous n'envoyons que des nouveaux récents. Vaut-il la peine de préciser que cela fonctionne? Ça marche. Stable est mis en cache sur le serveur de configuration et les destinataires, récent est créé au besoin.
Architecture de transport à deux niveaux
Pourquoi avons-nous construit notre transport sur deux niveaux? La réponse est assez simple - nous voulions séparer le routage de la logique de haut niveau, en nous inspirant du modèle OSI avec sa couche transport et sa couche application. Pour le rôle du protocole de transport, nous avons pris Thrift, et pour le format de message de contrôle de haut niveau, le format de sérialisation msgpack. C'est pourquoi le routeur (exécutant la multidiffusion / diffusion / relais) ne regarde pas à l'intérieur de msgpack, ne décompresse pas et ne recompresse pas le contenu, et effectue uniquement le transfert de données.
Thrift (de l'anglais - "thrift", prononcé [θrift]) est un langage de description d'interface qui est utilisé pour définir et créer des services pour différents langages de programmation. Il s'agit d'un cadre pour l'appel de procédure distante (RPC). Il combine un pipeline logiciel avec un moteur de génération de code pour développer des services qui, à un degré ou à un autre, fonctionnent efficacement et facilement entre les langues.Nous avons adopté le framework Thrift en raison de RPC et de la prise en charge de nombreuses langues. Comme d'habitude, le client et le serveur sont les parties faciles. Cependant, le routeur s'est avéré être un écrou dur, en partie à cause du manque de solution prête à l'emploi lors de notre développement.

Il existe d'autres options, telles que protobuf / gRPC, cependant, lorsque nous avons commencé notre projet, gRPC était assez jeune et nous n'avons pas osé le prendre en compte.
Bien sûr, nous avons pu (et en fait, ça valait le coup) créer notre propre vélo. Il serait plus facile de créer un protocole pour ce dont nous avons besoin, car l'architecture client-serveur est relativement simple à mettre en œuvre par rapport à la construction d'un routeur sur Thrift. D'une manière ou d'une autre, il existe une attitude traditionnelle de préjugés à l'égard des protocoles auto-écrits et des implémentations des bibliothèques populaires (pas en vain), de plus, la discussion soulève toujours la question: «Comment allons-nous le porter dans d'autres langues?» Par conséquent, nous avons immédiatement jeté des idées sur le vélo.
Msgpack est un analogue de JSON, mais plus rapide et moins. Il s'agit d'un format de sérialisation de données binaires qui permet l'échange de données entre plusieurs langues.Au premier niveau, nous avons Thrift avec le minimum d'informations nécessaires au routeur pour transmettre le message. Au deuxième niveau sont des structures msgpack packagées.
Nous avons choisi msgpack car il est plus rapide et plus compact que JSON. Mais plus important encore, il prend en charge les types de données personnalisés, ce qui nous permet d'utiliser des fonctionnalités intéressantes telles que le transfert de fichiers binaires bruts ou d'objets spéciaux indiquant le manque de données, ce qui était important pour notre schéma récemment stable.
JmespathJMESPath est un langage de requête JSON.C'est exactement à quoi ressemble la description, que nous obtenons de la documentation officielle JMESPath, mais en fait, cela en donne beaucoup plus. JMESPath vous permet de rechercher et de filtrer des sous-arbres dans une arborescence arbitraire, ainsi que d'appliquer des modifications aux données à la volée. Il vous permet également d'ajouter des filtres spéciaux et des procédures de conversion de données. Bien sûr, cela nécessite une tension cérébrale pour comprendre.
JinjaPour certains consommateurs, nous devons transformer la configuration en fichier - nous utilisons donc le moteur de modèle et Jinja est le choix évident. Avec son aide, nous générons un fichier de configuration à partir du modèle et des données reçues à destination.
Pour générer le fichier de configuration, nous avons besoin d'une demande JMESPath, d'un modèle pour l'emplacement du fichier dans le FS, d'un modèle pour la configuration elle-même. À ce stade également, il est agréable de clarifier les autorisations de fichier. Tout cela s'est avéré être combiné avec succès dans un seul fichier - avant le début du modèle de configuration, nous avons mis l'en-tête au format YAML, qui décrit le reste.
Par exemple:
---
selector: "[@][?@.fft._meta.version == `42`] | items([0].fft_config || `{}`)"
destination_filename: "fft/{{ match[0] }}.json"
file_mode: 0644
reload_daemons: [fft]
...
{{ dict(match[1]) | json(indent=2, sort_keys=True) }}
Afin de créer un fichier de configuration pour un nouveau service, nous ajoutons uniquement un nouveau fichier modèle. Aucune modification du code source ou du logiciel aux points de présence n'est requise.
Qu'est-ce qui a changé depuis l'introduction de QControl dans les opérations? Le premier et le plus important est la livraison cohérente et fiable des mises à jour de configuration sur tous les nœuds du réseau. La seconde consiste à obtenir un puissant outil de vérification de la configuration et à y apporter des modifications par notre équipe d'assistance, ainsi que par les consommateurs du service.
Nous avons réussi à faire tout cela en utilisant le schéma de mise à jour stable récent pour simplifier la communication entre le serveur de configuration et les destinataires de la configuration. Utilisation d'un protocole à deux couches pour prendre en charge une méthode de routage de données indépendante du contenu. Ayant intégré avec succès le moteur de génération de configuration basé sur Jinja dans un réseau de filtrage distribué. Ce système prend en charge un large éventail de méthodes de configuration pour nos périphériques distribués et variés.
Merci d'avoir écrit du matériel grâce à
VolanDamrod ,
serenheit ,
NoN .
Version anglaise de l' article.