
Il y a quelques années, chez Badoo, nous avons commencé à utiliser l'approche MVI pour le développement Android. Il était destiné à simplifier une base de code complexe et à éviter le problème des états incorrects: dans des scénarios simples, il est facile, mais plus le système est complexe, plus il est difficile de le maintenir sous la forme correcte et plus il est facile de manquer un bogue.
Dans Badoo, toutes les applications sont asynchrones - non seulement en raison des nombreuses fonctionnalités disponibles pour l'utilisateur via l'interface utilisateur, mais également en raison de la possibilité d'envoi de données à sens unique par le serveur. En utilisant l'ancienne approche de notre module de discussion, nous sommes tombés sur plusieurs bogues étranges difficiles à reproduire, que nous avons dû consacrer beaucoup de temps à éliminer.
Notre collègue Zsolt Kocsi (
Medium ,
Twitter ) du bureau de Londres a expliqué comment l'utilisation de MVI nous permet de créer des composants indépendants faciles à réutiliser, quels avantages nous obtenons et quels inconvénients nous avons rencontrés lors de l'utilisation de cette approche.
Il s'agit du troisième article d'une série d'articles sur l'architecture Badoo Android. Liens vers les deux premiers:
- Architecture MVI moderne basée sur Kotlin .
- Construire un système de composants réactifs avec Kotlin .
Ne vous attardez pas sur des composants mal connectés.
Une connectivité faible est considérée comme meilleure que forte. Si vous ne comptez que sur des interfaces et non sur des implémentations spécifiques, il vous sera plus facile de remplacer des composants, il est plus facile de passer à d'autres implémentations sans réécrire la majeure partie du code, ce qui simplifie notamment les tests unitaires.
Nous terminons généralement ici et disons que nous avons fait tout notre possible en termes de connectivité.
Cependant, cette approche n'est pas optimale. Supposons que vous ayez une classe A qui doit utiliser les capacités de trois autres classes: B, C et D. Même si vous vous y référez via des interfaces, la classe A devient plus difficile avec chacune de ces classes:
- il connaît toutes les méthodes de toutes les interfaces, leurs noms et types de retour, même s'il ne les utilise pas;
- lors du test de A, vous devez configurer davantage de simulations ( objet factice );
- il est plus difficile d'utiliser A à plusieurs reprises dans d'autres contextes où nous n'avons pas ou ne voulons pas avoir B, C et D.
Bien entendu, c'est précisément la classe A qui doit déterminer l'ensemble minimum d'interfaces nécessaire pour cela (principe de ségrégation des interfaces de
SOLID ). Cependant, dans la pratique, nous avons tous dû faire face à des situations où, pour des raisons de commodité, une approche différente a été adoptée: nous avons pris une classe existante qui implémente certaines fonctionnalités, extrait toutes ses méthodes publiques dans l'interface, puis utilisé cette interface là où la classe mentionnée était nécessaire. Autrement dit, l'interface n'a pas été utilisée sur la base de ce que ce composant est requis, mais sur la base de ce qu'un autre composant peut offrir.
Avec cette approche, la situation s'aggrave avec le temps. Chaque fois que nous ajoutons de nouvelles fonctionnalités, nos classes sont liées dans un réseau de nouvelles interfaces dont elles ont besoin de connaître. Les classes augmentent en taille et les tests deviennent de plus en plus difficiles.
Par conséquent, lorsque vous devez les utiliser dans un contexte différent, il sera presque impossible de les déplacer sans tout cet enchevêtrement avec lequel ils sont connectés, même via des interfaces. Vous pouvez faire une analogie: vous voulez utiliser une banane, et c'est entre les mains d'un singe qui pend sur un arbre, donc en conséquence, dans la charge sur la banane, vous obtiendrez un morceau entier de la jungle. En bref, le processus de transfert prend beaucoup de temps et vous vous demandez rapidement pourquoi, en pratique, il est si difficile de réutiliser le code.
Composants Black Box
Si nous voulons que le composant soit facilement et réutilisable, alors pour cela nous n'avons pas besoin de connaître deux choses:
- à quel autre endroit il est utilisé;
- sur d'autres composants qui ne sont pas liés à sa mise en œuvre interne.
La raison est claire: si vous ne connaissez pas le monde extérieur, vous ne serez pas connecté avec lui.
Ce que nous attendons vraiment du composant:
- définir ses propres données d'entrée (entrée) et de sortie (sortie);
- Ne pensez pas d'où viennent ces données ni où elles vont;
- il doit être autosuffisant pour que nous n'ayons pas besoin de connaître la structure interne du composant pour son utilisation.
Vous pouvez considérer le composant comme une boîte noire ou un circuit intégré. Elle a des contacts d'entrée et de sortie. Vous les soudez - et le microcircuit fait partie d'un système dont il ne sait rien.

Jusqu'à présent, on supposait que nous parlions de flux de données bidirectionnels: si la classe A a besoin de quelque chose, elle extrait une méthode via l'interface B et reçoit le résultat sous la forme de la valeur retournée par la fonction.

Mais alors A connaît B, et nous voulons éviter cela.
Bien sûr, un tel schéma est logique pour les fonctionnalités d'implémentation de bas niveau. Mais si nous avons besoin d'un composant réutilisable qui fonctionne comme une boîte noire autonome, nous devons nous assurer qu'il ne sait rien des interfaces externes, des noms de méthode ou des valeurs de retour.
On passe à l'unidirectionnalité
Mais sans noms et méthodes d'interface, nous ne pouvons rien appeler! Il ne reste plus qu'à utiliser un flux de données unidirectionnel, dans lequel nous obtenons simplement des entrées et générons des sorties:

Au début, cela peut ressembler à une limitation, mais une telle solution présente de nombreux avantages, qui seront discutés ci-dessous.
Dès le
premier article, nous savons que les fonctionnalités (Feature) définissent leurs propres données d'entrée (Wish) et leurs propres données de sortie (State). Par conséquent, peu importe pour eux d'où vient le souhait ou où va l'État.
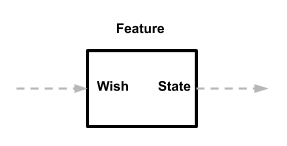
Voilà ce dont nous avons besoin! Les fonctionnalités peuvent être utilisées partout où vous pouvez leur donner une entrée, et avec la sortie, vous pouvez faire ce que vous voulez. Et comme les fonctionnalités ne communiquent pas directement avec d'autres composants, ce sont des modules autonomes et indépendants.
Maintenant, prenez la vue et concevez-la pour qu'elle soit également un module autonome.
Tout d'abord, la vue doit être aussi simple que possible afin qu'elle ne puisse gérer que ses tâches internes.
Quel genre de tâches? Il y en a deux:
- rendu ViewModel (entrée);
- déclenchement de ViewEvents en fonction des actions de l'utilisateur (sortie).
Pourquoi utiliser ViewModel? Pourquoi ne pas dessiner directement l'état de la fonction?
- (Non) afficher une fonctionnalité à l'écran ne fait pas partie de l'implémentation. La vue doit pouvoir s'afficher si les données proviennent de plusieurs sources.
- Pas besoin de refléter la complexité de l'état dans la vue. Le ViewModel ne doit contenir que les informations prêtes à être affichées qui sont nécessaires pour rester simple.
En outre, View ne devrait pas être intéressé par les éléments suivants:
- d'où viennent tous ces ViewModels;
- ce qui se passe lorsque ViewEvent est déclenché;
- toute logique métier;
- suivi analytique;
- journalisation
- d'autres tâches.
Toutes ces tâches sont externes et View ne doit pas y être connecté. Arrêtons-nous et résumons la simplicité de la vue:
interface FooView : Consumer<ViewModel>, ObservableSource<Event> { data class ViewModel( val title: String, val bgColor: Int ) sealed class Event { object ButtonClicked : Event() data class TextFocusChanged(val hasFocus: Boolean) : Event() } }
Une implémentation Android devrait:
- Trouvez les vues Android par leur ID.
- Implémentez la méthode accept de l'interface client en définissant la valeur à partir du ViewModel.
- Définissez les écouteurs (ClickListeners) pour interagir avec l'interface utilisateur pour générer des événements spécifiques.
Un exemple:
class FooViewImpl @JvmOverloads constructor( context: Context, attrs: AttributeSet? = null, defStyle: Int = 0, private val events: PublishRelay<Event> = PublishRelay.create<Event>() ) : LinearLayout(context, attrs, defStyle), FooView,
S'il ne se limite pas aux fonctionnalités et à la vue, voici à quoi ressemblera tout autre composant avec cette approche:
interface GenericBlackBoxComponent : Consumer<Input>, ObservableSource<Output> { sealed class Input sealed class Output }
Maintenant, tout est clair avec le motif!

Unissez-vous, unissez-vous, unissez-vous!
Mais que se passe-t-il si nous avons différents composants et chacun d'eux a sa propre entrée et sortie? Nous allons les connecter!
Heureusement, cela peut facilement être fait à l'aide de Binder, ce qui aide également à créer la bonne portée, comme nous le savons dans le
deuxième article :
Le premier avantage: facile à étendre sans modifications
L'utilisation de composants non liés sous la forme de boîtes noires qui ne sont connectées que temporairement nous permet d'ajouter de nouvelles fonctionnalités sans modifier les composants existants.
Prenons un exemple simple:

Ici, les fonctionnalités (F) et View (V) sont simplement connectées les unes aux autres.
Les liaisons correspondantes seront:
bind(feature to view using stateToViewModelTransformer) bind(view to feature using uiEventToWishTransformer)
Supposons que nous voulons ajouter le suivi de certains événements d'interface utilisateur à ce système.
internal object AnalyticsTracker : Consumer<AnalyticsTracker.Event> { sealed class Event { object ProfileImageClicked: Event() object EditButtonClicked : Event() } override fun accept(event: AnalyticsTracker.Event) {
La bonne nouvelle est que nous pouvons le faire simplement en réutilisant le canal de vue de sortie existant:

En code, cela ressemble à ceci:
bind(feature to view using stateToViewModelTransformer) bind(view to feature using uiEventToWishTransformer)
De nouvelles fonctionnalités peuvent être ajoutées avec une seule ligne de reliure supplémentaire. Maintenant, non seulement nous ne pouvons pas changer une seule ligne de vue de code, mais il ne sait même pas que la sortie est utilisée pour résoudre un nouveau problème.
De toute évidence, il nous est désormais plus facile d’éviter des soucis supplémentaires et des composants inutilement compliqués. Ils restent simples. Vous pouvez ajouter des fonctionnalités au système en connectant simplement les composants aux composants existants.
Deuxième avantage: facilité d'utilisation répétée
En utilisant l'exemple de Feature and View, on peut clairement voir que nous pouvons ajouter une nouvelle source d'entrée ou un consommateur de données de sortie avec une seule ligne avec liaison. Cela facilite grandement la réutilisation des composants dans différentes parties de l'application.
Cependant, cette approche n'est pas limitée aux classes. Cette façon d'utiliser les interfaces nous permet de décrire des composants réactifs autonomes de toute taille.
En nous limitant à certaines données d'entrée et de sortie, nous nous débarrassons de la nécessité de savoir comment tout fonctionne sous le capot, et donc nous évitons facilement de lier accidentellement les composants internes des composants avec d'autres parties du système. Et sans liaison, vous pouvez facilement et simplement utiliser des composants à plusieurs reprises.
Nous y reviendrons dans l'un des articles suivants et examinerons des exemples d'utilisation de cette technique pour connecter des composants de niveau supérieur.
Première question: où mettre les fixations?
- Choisissez le niveau d'abstraction. Selon l'architecture, il peut s'agir d'une activité, d'un fragment ou d'un ViewController. J'espère que vous avez encore un certain niveau d'abstraction dans les parties où il n'y a pas d'interface utilisateur. Par exemple, dans certaines des étendues de l'arborescence de contexte DI.
- Créez une classe distincte pour la liaison au même niveau que cette partie de l'interface utilisateur. S'il s'agit de FooActivity, FooFragment ou FooViewController, vous pouvez placer FooBindings à côté.
- Assurez-vous d'intégrer FooBindings dans les mêmes instances de composant que vous utilisez dans l'activité, le fragment, etc.
- Pour former l'étendue des liaisons, utilisez le cycle de vie Activité ou fragment. Si cette boucle n'est pas liée à Android, vous pouvez créer des déclencheurs manuellement, par exemple, lors de la création ou de la destruction d'une étendue DI. D'autres exemples de portée sont décrits dans le deuxième article .
Deuxième question: les tests
Puisque notre composant ne sait rien des autres, nous n'avons généralement pas besoin de stubs à la place. Les tests sont simplifiés pour vérifier la bonne réponse du composant aux données d'entrée et produire les résultats attendus.
Dans le cas de Feature, cela signifie:
- la possibilité de tester si certaines données d'entrée génèrent l'état attendu (sortie).
Et dans le cas de View:
- nous pouvons tester si un ViewModel particulier (entrée) conduit à l'état attendu de l'interface utilisateur;
- nous pouvons tester si la simulation de l'interaction avec l'interface utilisateur conduit à l'initialisation dans le ViewEvent attendu (sortie).
Bien sûr, les interactions entre les composants ne disparaissent pas comme par magie. Nous venons d'extraire ces tâches des composants eux-mêmes. Ils doivent encore être testés. Mais où?
Dans notre cas, Binders est responsable de la connexion des composants:
Nos tests devraient confirmer ce qui suit:
1. Transformateurs (mappeurs).
Certaines connexions ont des mappeurs, et vous devez vous assurer qu'ils convertissent correctement les éléments. Dans la plupart des cas, un test unitaire très simple suffit pour cela, car les mappeurs sont généralement aussi très simples:
@Test fun testCase1() { val transformer = Transformer() val testInput = TODO() val actualOutput = transformer.invoke(testInput) val expectedOutput = TODO() assertEquals(expectedOutput, actualOutput) }
2. Communication.
Vous devez vous assurer que les connexions sont correctement configurées. Quel est l'intérêt du travail des composants individuels et des mappeurs, si pour une raison quelconque la connexion entre eux n'a pas été établie? Tout cela peut être testé en configurant l'environnement de liaison avec des talons, des sources d'initialisation et en vérifiant si les résultats attendus sont reçus côté client:
class BindingEnvironmentTest { lateinit var component1: ObservableSource<Component1.Output> lateinit var component2: Consumer<Component2.Input> lateinit var bindings: BindingEnvironment @Before fun setUp() { val component1 = PublishRelay.create() val component2 = mock() val bindings = BindingEnvironment(component1, component2) } @Test fun testBindings() { val simulatedOutputOnLeftSide = TODO() val expectedInputOnRightSide = TODO() component1.accept(simulatedOutputOnLeftSide) verify(component2).accept(expectedInputOnRightSide) } }
Et bien que pour les tests, vous devrez écrire sur la même quantité de code qu'avec d'autres approches, cependant, les composants autosuffisants facilitent le test des parties individuelles, car les tâches sont clairement séparées.
Matière à réflexion
Bien que la description de notre système sous la forme d'un graphique de cases noires soit bonne pour la compréhension générale, cela ne fonctionne que tant que la taille du système est relativement petite.
Cinq à huit lignes de reliure sont acceptables. Mais, ayant plus connecté, il sera assez difficile de comprendre ce qui se passe:
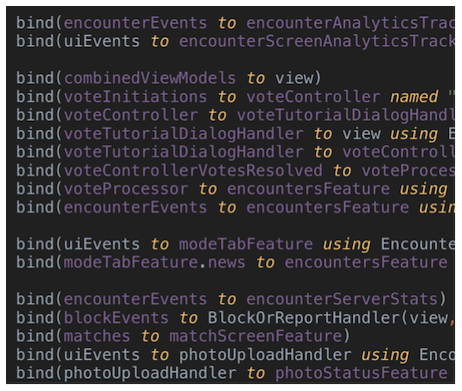

Nous étions confrontés au fait qu'avec une augmentation du nombre de liens (il y en avait encore plus que dans le fragment de code présenté) la situation devenait encore plus compliquée. La raison n'était pas seulement dans le nombre de lignes - certaines sortes de liaisons pouvaient être regroupées et extraites pour différentes méthodes - mais aussi parce qu'il devenait de plus en plus difficile de tout garder en vue. Et c'est toujours un mauvais signe. Si des dizaines de composants différents sont situés au même niveau, il est impossible d'imaginer toutes les interactions possibles.
La raison en est l'utilisation de composants - boîtes noires ou autre chose?
De toute évidence, si la portée que vous décrivez est initialement complexe, aucune approche ne vous sauvera du problème mentionné jusqu'à ce que vous divisiez le système en parties plus petites. Ce sera compliqué même sans une énorme liste de fixations, ce ne sera tout simplement pas si évident. De plus, il vaut mieux que la complexité soit exprimée explicitement et non cachée. Il est préférable de voir une liste croissante de jointures sur une seule ligne qui vous rappelle le nombre de composants individuels que vous ne connaissez pas sur ces liens cachés à l'intérieur des classes dans différents appels de méthode.
Étant donné que les composants eux-mêmes sont simples (ce sont des boîtes noires et que des processus supplémentaires n'y entrent pas), il est plus facile de les séparer, ce qui signifie que c'est un pas dans la bonne direction. Nous avons déplacé la difficulté à un seul endroit - à la liste des fixations, un coup d'œil qui vous permet d'évaluer la situation générale et de commencer à réfléchir à la façon de sortir de ce gâchis.
La recherche d'une solution nous a pris beaucoup de temps, et elle est toujours en cours. Nous prévoyons de discuter de la façon de faire face à ce problème dans les articles suivants. Restez en contact!