
La détection d'objets est l'une des tâches les plus importantes de l'apprentissage automatique. Récemment, une série d'algorithmes d'apprentissage automatique basés sur le Deep Learning pour la détection d'objets ont été publiés. Ces algorithmes occupent une place centrale dans les applications pratiques de vision par ordinateur, en particulier les voitures autonomes actuellement très populaires. Mais toutes ces méthodes sont des méthodes d'enseignement avec un enseignant, c'est-à-dire ils ont besoin d'un énorme ensemble de données (énorme ensemble de données). Naturellement, on souhaite disposer d'un modèle capable d'apprendre à partir de données «brutes» (non allouées). J'ai essayé d'analyser les méthodes existantes et d'indiquer également les voies possibles de leur développement. Je demande à tous ceux qui souhaitent miséricorde sous kat, ce sera intéressant.
Statut actuel de la question
Naturellement, la formulation de ce problème existe depuis longtemps (presque depuis les premiers jours de l'existence du machine learning) et il existe un nombre suffisant d'ouvrages sur ce sujet. Par exemple, l'un de mes préférés
Détection d'objets non supervisés invariants spatialement avec des réseaux de neurones convolutionnels . En bref, les auteurs forment VAE (Variation Auto Encoder), mais cette approche soulève un certain nombre de questions pour moi.
Un peu de philosophie
Alors qu'est-ce qu'un objet dans une image? Pour répondre à cette question, nous devons répondre à la question - pourquoi divisons-nous même le monde en objets? Après une petite réflexion sur cette question, je n'ai eu qu'une seule réponse à cette question (je ne dis pas qu'il n'y en a pas d'autres, je ne les ai tout simplement pas trouvées) - nous essayons de trouver une représentation du monde qui nous soit facile à comprendre et à contrôler la quantité d'informations nécessaires pour décrire le monde dans le cadre de la tâche en cours. Par exemple, pour la tâche de classification des images (qui est généralement mal formulée - il y a très rarement des images avec un seul objet. C'est-à-dire que nous résolvons le problème non pas ce qui est montré dans l'image, mais quel objet est "principal"), nous devons juste dire que l'image est "voiture" , à son tour, pour la tâche de détecter des objets, nous voulons savoir quels objets «intéressants» (nous ne sommes pas intéressés par toutes les feuilles des arbres dans l'image) sont là, et où ils sont, pour la tâche de décrire la scène, nous voulons obtenir le nom du processus «intéressant» cela se passe là-bas, par exemple, «coucher de soleil», etc.
Il s'avère que les objets sont une représentation pratique des données. Quelles propriétés cette représentation devrait-elle avoir? La vue doit contenir autant que possible des informations complètes sur l'image. C'est-à-dire ayant une description d'objet, nous voulons être en mesure de restaurer l'image d'origine avec le degré de précision nécessaire.
Comment cela peut-il être exprimé mathématiquement? Imaginez que l'image soit une réalisation d'une variable aléatoire X, et la représentation sera une réalisation d'une variable aléatoire Y. Compte tenu de ce qui précède, nous voulons que Y contienne autant d'informations que possible sur X. Naturellement, pour ce faire, utilisez le concept d'information mutuelle.
Modèles d'apprentissage automatique pour un maximum d'informations
La détection d'objets peut être considérée comme un modèle génératif, qui reçoit une image en entrée
et la sortie est une représentation objet de l'image
.

Rappelons maintenant la formule de calcul des informations mutuelles:
où
la distribution de la densité des joints ainsi
marginalisés.
Ici, je n'entrerai pas dans les détails de la raison pour laquelle cette formule ressemble à ceci, mais nous croirons qu'en interne c'est très logique. Soit dit en passant, sur la base des considérations décrites, il n'est pas nécessaire de choisir exactement des informations mutuelles, il peut s'agir de toute autre «information», mais nous y reviendrons plus près de la fin.
Particulièrement attentifs (ou ceux qui lisent des livres sur la théorie de l'information) ont déjà remarqué que l'information mutuelle n'est rien de plus que la divergence de Kullback-Lebler entre la distribution conjointe et le travail des marginaux. Ici, une légère complication survient - quiconque a lu au moins quelques livres sur l'apprentissage automatique sait que si nous n'avons que des échantillons de deux distributions (c'est-à-dire que nous ne connaissons pas les fonctions de distribution), cela n'optimise même pas, mais évalue même la divergence de Kullback, La tâche de Leibler est très simple. De plus, nos bien-aimés GAN sont nés précisément pour cette raison.
Heureusement, la merveilleuse idée d'utiliser la limite variationnelle inférieure décrite dans
Sur les limites variationnelles de l'information mutuelle vient à notre aide. Les informations mutuelles peuvent être représentées comme:
Ou
où
- la distribution de la représentation pour une image donnée, paramétrée par notre grille neuronale et à partir de cette distribution, nous pouvons échantillonner, mais nous n'avons pas besoin d'être en mesure d'estimer la densité ou la probabilité d'un échantillon particulier (ce qui est généralement typique de nombreux modèles génératifs).
Si une certaine fonction de densité est paramétrée par le deuxième réseau de neurones (dans le cas le plus général, nous avons besoin de 2 réseaux de neurones, bien que dans certains cas ils puissent être représentés par le premier), ici nous devons être capables de calculer les probabilités des échantillons résultants.
Valeur
appelé la limite variationnelle inférieure.
Nous pouvons maintenant résoudre l'approche de notre problème, à savoir augmenter non pas l'information mutuelle elle-même, mais sa limite variationnelle inférieure. Si la distribution
choisi correctement, puis au point maximum de la frontière variationnelle et les informations mutuelles coïncideront, mais dans le cas pratique (lorsque la distribution
ne peut pas imaginer exactement
, mais se compose d'une famille de fonctions assez importante) sera très proche, ce qui nous convient également.
Si quelqu'un ne sait pas comment cela fonctionne, je vous conseille de considérer attentivement l'algorithme EM. Voici un cas complètement similaire.
Que se passe-t-il ici? En fait, nous avons obtenu la fonctionnalité de formation de l'encodeur automatique. Si Y est le résultat à la sortie d'un réseau neuronal avec une image à l'entrée, cela signifie que
où
fonction de transformation du réseau neuronal. Et approximer la distribution inverse par gaussienne, c'est-à-dire
nous obtenons:
Et c'est une fonctionnalité classique pour l'encodeur automatique.
L'encodeur automatique ne suffit pas
Je pense que beaucoup veulent déjà former l'auto-encodeur et j'espère que dans sa couche cachée, il y aura des neurones qui répondront à des objets spécifiques. En général, il y a confirmation de quelque chose de similaire et il s'avère que la
création de fonctionnalités de haut niveau à l'aide d'un apprentissage non supervisé à grande échelle . Mais cela n'est toujours pas pratique. Et les personnes les plus attentives ont déjà remarqué que les auteurs de cet article ont utilisé la régularisation - ils ont ajouté un terme qui fournit une clarté dans la couche cachée, et ils ont écrit en noir et blanc qu'il ne se passe rien de ce genre sans ce terme.
Le principe de maximiser l'information mutuelle est-il suffisant pour apprendre une idée «pratique»? Evidemment non, car on peut choisir Y égal à X (c'est-à-dire utiliser l'image elle-même comme représentation) ou toute transformation bijective, l'information mutuelle va à l'infini dans ce cas. Il ne peut y avoir plus de cette valeur, mais comme nous le savons, c'est une très mauvaise idée.
Nous avons besoin d'un critère supplémentaire pour la «commodité» de la présentation. Les auteurs de l'article ci-dessus ont considéré la rareté comme une «commodité». C'est une sorte de réalisation de l'hypothèse selon laquelle il devrait y avoir quelques «objets importants» dans l'image. Mais nous irons plus loin - nous voulons non seulement apprendre le fait qu'un tel objet est dans l'image, mais aussi savoir où il se trouve, combien il se chevauche, etc. La question se pose, comment faire interpréter au réseau neuronal la sortie d'un neurone comme, par exemple, la coordonnée d'un objet? La réponse est évidente - la sortie de ce neurone doit être utilisée précisément pour cela. Autrement dit, connaissant l'idée, nous devons être en mesure de générer des images «similaires» à l'original.
L'idée générale a été empruntée aux gars de Facebook.
L'encodeur ressemblera à ceci:

où
- un vecteur décrivant l'objet,
- coordonnées de l'objet,
- l'échelle de l'objet,
- la position de l'objet en profondeur,
- la probabilité que l'objet soit présent.
Autrement dit, le réseau neuronal d'entrée reçoit une image d'une taille prédéterminée sur laquelle nous voulons trouver des objets et émet un tableau de descriptions. Si nous voulons un réseau à un seul passage, alors malheureusement, ce tableau devra être de taille fixe. Si nous voulons trouver tous les objets, nous devrons utiliser des réseaux de recrutement.
Le décodeur sera comme ceci:
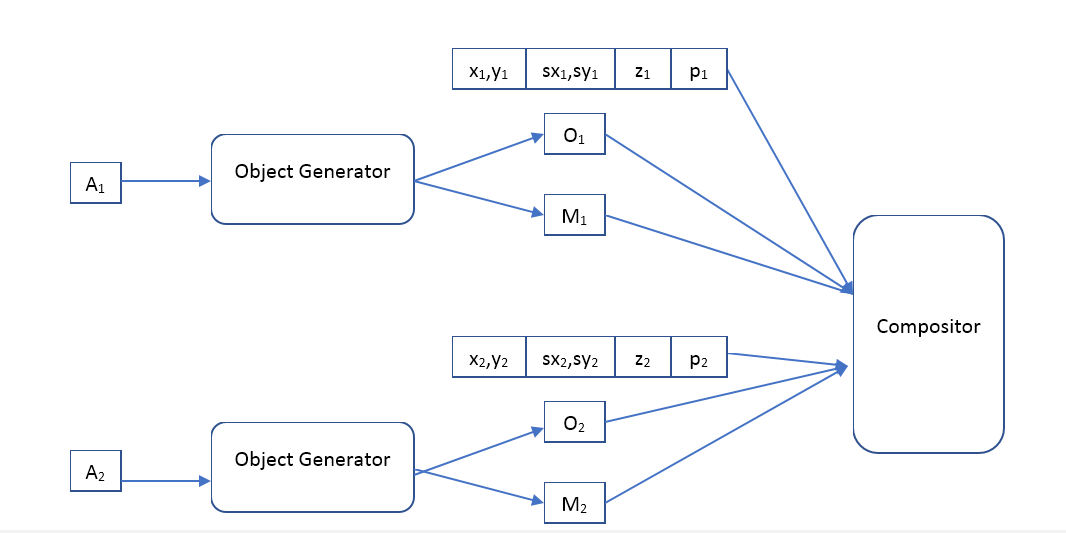
Où Object Generator est un réseau qui reçoit un vecteur de description d'objet à l'entrée et donne
- l'image (d'une certaine taille standard) de l'objet et le masque de pixels opaques (masque d'opacité).
Compositeur - reçoit l'image d'entrée de tous les objets, masque, position, échelle, profondeur et forme l'image de sortie, qui devrait être similaire à l'original.
Quelle est la différence entre notre approche et la VAE?
Il semble que nous voulions utiliser un encodeur automatique avec la même architecture que les auteurs de l'article
Détection d'objets non supervisés spatialement invariants avec des réseaux de neurones convolutifs , la question est donc de savoir quelle est la différence. A la fois là et là autoencoder, seulement dans la deuxième version c'est variationnel.
D'un point de vue théorique, la différence est très grande. VAE est un modèle génératif et sa tâche est de rendre 2 distributions (images initiales et générées) aussi similaires que possible. De manière générale, VAE ne garantit pas que l'image générée à partir de la «description» d'un objet généré à partir de l'image originale sera au moins légèrement similaire à l'original. Soit dit en passant, les auteurs de VAE
Auto-Encoding Variational Bayes eux-mêmes en parlent. Alors pourquoi ça marche toujours? Je pense que l'architecture choisie des réseaux de neurones et la «description» contribuent à augmenter l'information mutuelle de l'image et de la «description», mais je n'ai trouvé aucune preuve mathématique de cette hypothèse. Une question pour les lecteurs, quelqu'un peut-il être en mesure d'expliquer les résultats des auteurs - leur image restaurée est très similaire à l'original, pourquoi?
De plus, l'utilisation de la VAE oblige les auteurs à spécifier la distribution des «descriptions», et la méthode de maximisation de l'information mutuelle ne fait aucune hypothèse à ce sujet. Ce qui nous donne une liberté supplémentaire, par exemple, nous pouvons essayer de regrouper des vecteurs sur un modèle déjà formé
descriptions, et regardez - peut-être qu'un tel système apprendra les classes d'objets? Il convient de noter qu'un tel regroupement à l'aide de VAE n'a aucun sens, par exemple, les auteurs de l'article utilisent une distribution gaussienne pour ces vecteurs.
Les expériences
Malheureusement, le travail prend maintenant énormément de temps et il n'est pas possible de le terminer dans un délai acceptable. Si quelqu'un veut écrire plusieurs milliers de lignes de code, former des centaines de modèles d'apprentissage automatique et mener de nombreuses expériences intéressantes, simplement parce que cela lui fait plaisir - je serai heureux d'unir mes forces. Écrivez de façon personnelle.
Le champ d'expérimentation est ici très large. J'ai l'intention de commencer par enseigner l'auto-encodeur classique (cartographie déterministe des images aux descriptions et une distribution gaussienne inverse) et voir ce qu'il apprend. Dans les premières expériences, il suffira d'utiliser le compositeur décrit par les gars de Facebook, mais à l'avenir je pense que ce sera très intéressant de jouer avec différents compositeurs, et il est possible de les rendre également apprenants. Comparez différents régularisateurs: sans lui, clairsemés, etc. Comparez l'utilisation de modèles à action directe et récursifs. Utilisez ensuite des modèles de distribution plus avancés pour la distribution inverse, par exemple, une telle
estimation de densité en utilisant Real NVP . Découvrez à quel point cela s'améliore ou se détériore avec des modèles plus flexibles. Voyez ce qui se passera si l'affichage des images sur les descriptions est rendu non déterministe (généré à partir d'une distribution conditionnelle). Et enfin, essayez d'appliquer diverses méthodes de clustering aux vecteurs de description
et comprendre si un tel système peut apprendre des classes d'objets.
Mais surtout, je veux vraiment comparer la qualité du modèle basé sur la maximisation de l'information mutuelle et le modèle avec VAE.