Rien de plus ennuyeux qu'un coup de téléphone surprise d'un numéro inconnu. À notre époque de messagers et de communication, la correspondance avec un numéro de téléphone inconnu qui scintille de manière inquiétante sur l'écran d'un smartphone peut provoquer au moins un peu d'excitation. Il est doublement ennuyeux lorsqu'un appel arrive non seulement soudainement (tels qu'ils sont, ces appels), mais aussi à un moment inconfortable pour vous. Par exemple, lorsque vous n'avez pas encore vraiment réussi à vous réveiller, ou vice versa, vous êtes déjà en plein essor dans un lit aussi séduisant après une longue journée. Certaines affaires appellent le week-end, après neuf heures du soir ou la nuit - généralement au-delà du bien et du mal.

Au fait, à propos de moi. Je m'appelle Natasha, je travaille chez Skyeng en tant que Data Scientist et je suis impliquée dans le développement de différents produits de l'entreprise. Pourquoi je parle d'appels soudains? La communication vocale avec les clients qui souhaitent simplement commencer ou interrompre brusquement leur formation pour une raison quelconque fait partie du modèle de travail de l'entreprise. Les appels aident à impliquer et à renvoyer les gens au processus d'apprentissage d'une langue, ou directement à découvrir ce qui n'a pas fonctionné. L'une de mes dernières tâches est d'analyser le travail de notre centre d'appels. Je les ai aidés à choisir le meilleur moment pour entrer en contact avec des étudiants à travers la Russie et la CEI: parce que personne n'aime les appels à des moments aléatoires de la journée, et exaspérer mes propres utilisateurs est la dernière chose.
L'humeur des gens lors de ces appels est extrêmement importante pour nous, car elle affecte directement la conversion. Alors permettez-moi de vous en dire plus sur la façon dont Skyeng appelle les étudiants et sur le modèle de prévision que j'ai construit pour que nos clients soient à l'aise et à l'aise, et nous atteignons un taux de conversion de 60 à 70%.
Il est physiquement impossible de deviner le moment opportun pour une personne en particulier, sauf si vous êtes un médium. Louez les progrès, pour identifier de tels modèles, des statistiques sont apparues, dont le modèle plus ou moins conviendra à la grande majorité des utilisateurs.
Dans l'analyse de nos enregistrements CRM, qui enregistre l'activité du centre d'appels, l'hypothèse d'appels professionnels en dehors des heures de travail et la nécessité de suivre le bon sens uniquement ont été confirmées. Il s'est donc avéré préférable d'appeler les gens du lundi au jeudi, de 10 à 18 heures (tout d'un coup!). C'est pendant cette période que les gens sont les plus susceptibles de prendre contact et l'appel dure plus de 15 secondes, c'est-à-dire que nous sommes considérés comme réussis.
Pour commencer, nous avons décidé de déterminer l'influence du facteur humain sur la conversion, c'est-à-dire regarder le succès des opérateurs de centres d'appels:
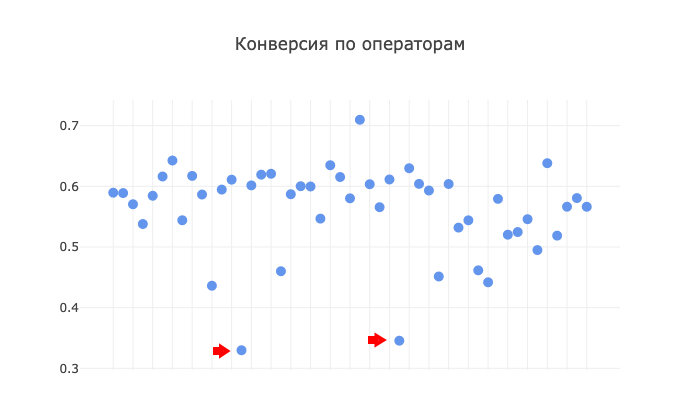
Vous n'avez pas besoin d'être un détective pour voir les deux «ancres» sur ce tableau. Ces deux anomalies sont des opérateurs avec une sorte d'efficacité extrêmement faible. Que faisons-nous des données anormales, dont la nature réside très probablement dans le facteur humain? Je crois que nous excluons complètement ces données du modèle pour atteindre la pureté et l'exactitude ultérieures du résultat. Ce que j'ai fait. Eh bien, en fait, ces deux opérateurs, ou plutôt leurs résultats, sont tellement absents du centre d'appels que je suis absolument sûr que la question n'est pas le processus de travail, mais les employés eux-mêmes. Ce sont peut-être de nouveaux arrivants, ce qui nous donne également une raison de les exclure.
Mais les données de six autres opérateurs avec une conversion inférieure à 0,5 restent dans le modèle. Je pense qu'il ne peut y avoir de situation idéale, comme les gens, alors ces six équilibreront nos calculs ultérieurs avec le reste de l'échantillon d'une cinquantaine d'employés.
Fuseaux horaires, régions et jours de la semaine
Nous avons une situation difficile avec les fuseaux horaires. Nous recueillons maintenant suffisamment d'informations pour déterminer d'où vient l'élève et quand il est préférable pour lui d'appeler. Mais c'était loin d'être toujours. Ce sont ces couches d'informations anciennes, mais toujours fonctionnelles, qui ont créé un certain nombre d'inconvénients à la fois pour nos utilisateurs et pour les opérateurs de centres d'appels. Pour traiter ces anciennes données, j'ai écrit un calcul séparé de la zone de l'utilisateur sur la base d'autres données indirectes (par numéro de téléphone, région et informations sur l'utilisation de notre application).
Si vous commencez à approfondir les statistiques CRM, vous pouvez toujours obtenir toute une couche d'informations utiles pour créer un modèle efficace. Pour commencer, j'ai construit un calendrier de conversion pour les jours de la semaine afin de confirmer mon hypothèse initiale selon laquelle il vaut mieux appeler en semaine, sauf le vendredi. En fait, mes hypothèses étaient correctes:
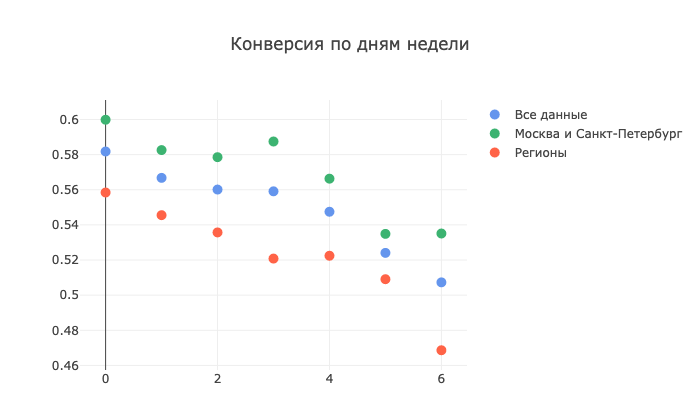
Une telle division entre Moscou, Saint-Pétersbourg et d'autres villes a été faite précisément en raison de doutes quant à la détermination du fuseau horaire. Pour le jour zéro, nous avons pris le lundi, respectivement, le sixième - dimanche. Le graphique ci-dessus montre clairement à quel point la conversion s'affaisse par région le week-end, ce qui confirme l'hypothèse d'un problème avec les fuseaux horaires sur lesquels les opérateurs de centre d'appels se sont concentrés.
Moscou et Peter vont un peu mieux. Peut-être parce que les habitants de ces villes sont habitués à un rythme de vie plus élevé. Mais même avec tout le stoïcisme des Moscovites et des habitants de la ville sur la Neva, les chiffres disent qu '"il n'y a rien à appeler du vendredi au dimanche".
La limite inférieure de notre objectif de 0,6 n'est atteinte qu'une seule fois - lundi, ce qui est surprenant, car il est généralement admis que cette journée est la plus difficile et les gens hésitent à résoudre les problèmes secondaires le lundi, car ils se concentrent sur le retour au rythme de travail après week-end. Non, non, et encore non - les chiffres ne mentent pas. Plus tard dans la semaine, nous allons plus ou moins en douceur, et la récession ne commence que jeudi.
Encore plus intéressante est l'image lors de la décomposition des appels par horloge:
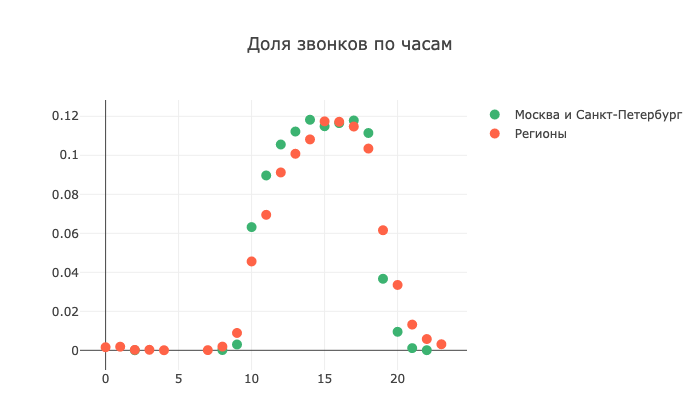 Notez la forte queue à gauche pour les régions. Très probablement, ces appels ont été passés à une heure inacceptable en raison d'un fuseau horaire mal défini
Notez la forte queue à gauche pour les régions. Très probablement, ces appels ont été passés à une heure inacceptable en raison d'un fuseau horaire mal définiVoyons maintenant la conversion de certains jours de la semaine:
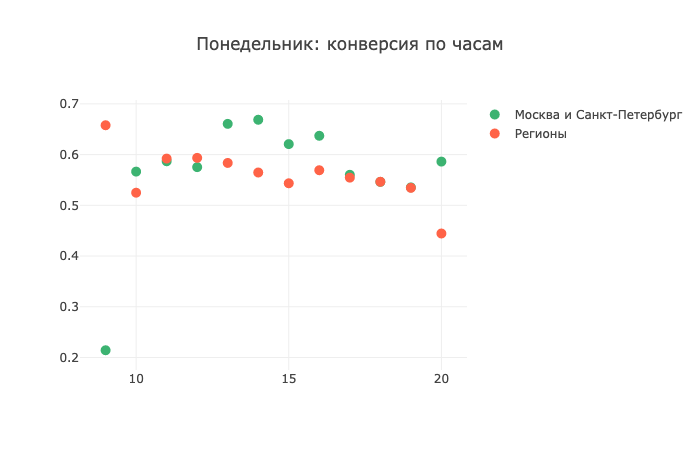
Voici les données de notre journée de champion du lundi. Au début du graphique, les «régions» sont poussées vers l'avant. Vers midi, la situation est nivelée. Soit dit en passant, faites attention au mouvement symétrique de notre carte vers 15 et 16 heures; que la capitale, que les régions montrent exactement le même mouvement en ce moment.
Mais mardi, la situation commence à changer:
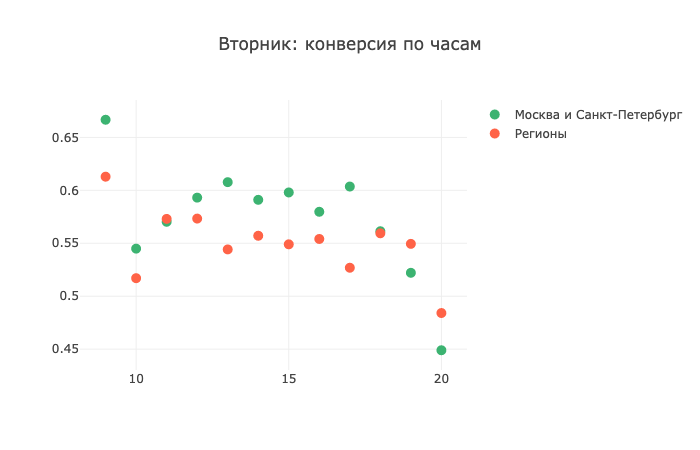
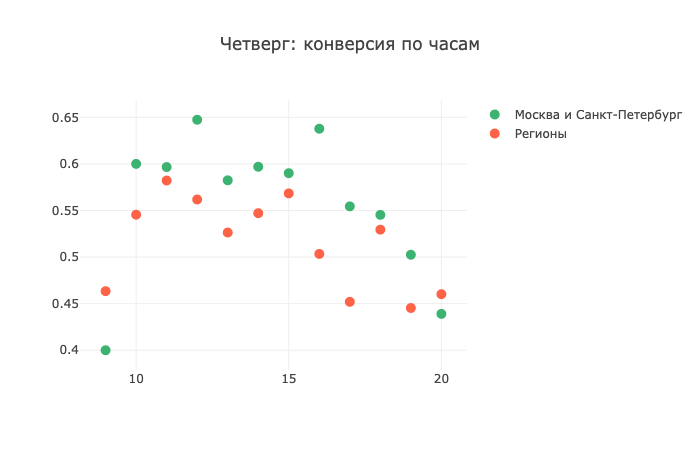
Et jeudi, les régions montrent leur réticence à répondre aux appels:
Rappelez-vous que j'ai dit que les appels du week-end sont mauvais? En général, le tableau statistique confirme mes propos, mais il y a un «mais». En bref, voyez par vous-même:
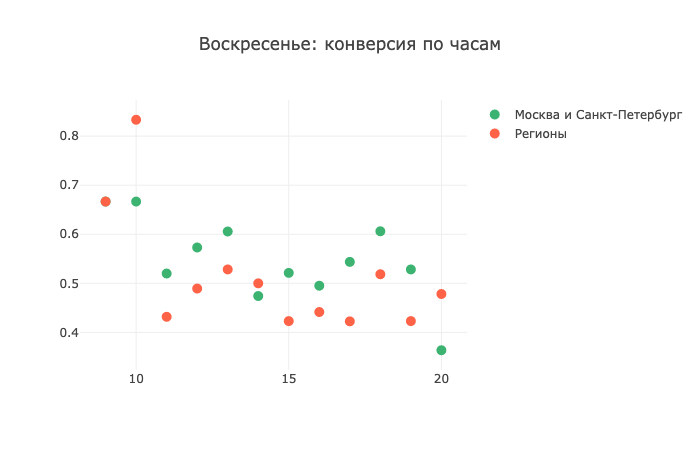
À 9-10 heures du matin, la conversion dans les régions se poursuit! Et déjà à 11 heures du matin - il se détache à peine de la barre des 0,4, c'est-à-dire qu'il s'affaisse deux fois. Je n'ai aucune idée de comment cela fonctionne et pourquoi cela se produit, donc je peux partager mes théories dans les commentaires, j'adorerais le lire.
Si nous résumons toutes les données, nous pouvons dériver les règles suivantes pour un appel «réussi»:
- Lundi: de 13 à 17;
- Mardi: de 12 à 18;
- Mercredi: de 11 à 12 et de 15 à 17;
- Jeudi: de 10 à 17;
- Vendredi: de 10 à 12;
- Samedi: de 16 à 18;
- Dimanche: du 13 au 14 et du 18 au 19.
En fait, tout s'inscrit dans le cadre du bon sens. En semaine du lundi au jeudi - pour appeler jusqu'à cinq à six heures du soir, et le vendredi après-midi pour résoudre les problèmes est presque impossible. Les statistiques sur les week-ends "flottent" un peu, en mettant l'accent sur l'après-midi, ainsi, le pic anormal mentionné à 10 heures le dimanche sort du tableau. Et donc tout est stable.
Ce que j'ai fait avec tout ça et quel modèle j'ai construit
Avant de procéder à la construction d'un modèle de centre d'appels, il a fallu tirer plusieurs conclusions. Tout d'abord, tout dépend du moment de l'appel. Mais ici, nous avons des problèmes.
La seule chose que nous pouvons suivre est la région d'enregistrement du numéro de téléphone, et déjà à partir de ces informations, nous partons de la construction du centre d'appels. Mais très souvent, des situations surviennent dans lesquelles nous ne pouvons pas déterminer exactement à partir de quelle région le nombre indiqué.
C'est cela, et non une certaine paresse fictive des régions, qui conduit au fait que les indicateurs généraux de conversion des utilisateurs en dehors du périphérique de Moscou et du périphérique diminuent par rapport aux capitales. Que pouvons-nous faire dans cette situation?
- Respectez les zones sensibles identifiées pour les appels vers les régions si nous ne disposons pas de suffisamment de données.
- Nous devons rechercher des outils pour déterminer plus précisément l'emplacement de l'utilisateur, afin de ne pas le déranger avec des appels vides.
Le deuxième point est particulièrement important. Ce sont ces écarts qui réduisent le taux de conversion global et continuent de faire enrager les clients.
Mais passons à la construction du modèle. Voici une liste générale des symptômes que j'ai identifiés comme pertinents:
- heure - l'heure de l'appel (signe catégorique de 0 à 23).
- jour de semaine - jour de la semaine (signe catégorique de 0 à 6).
- âge - l'âge de l'élève.
- durée de vie - la durée de vie de l'élève (en cours) au moment de l'appel.
- app_hour_ {k} - saisonnalité quotidienne de l'utilisation de l'application. Pour chaque heure, k est déterminé comme la fraction d'actions dans l'application à cette heure (k = 0, ..., 23) du nombre total d'actions dans l'application.
- app_weekday_ {k} - saisonnalité hebdomadaire d'utilisation de l'application. Pour chaque jour de la semaine, k est déterminé comme la proportion d'actions dans l'application ce jour de la semaine (k = 0, ..., 6) du nombre total d'actions dans l'application.
- class_hour_ {k} - saisonnalité quotidienne des cours. Pour chaque heure, k est déterminé comme la fraction des leçons à cette heure (k = 0, ..., 23) du nombre total de leçons.
- class_weekday_ {k} - saisonnalité hebdomadaire de l'utilisation de l'application. Pour chaque jour de la semaine, k est déterminé comme le pourcentage de leçons de ce jour de la semaine (k = 0, ..., 6) du nombre total de leçons.
- is_ru - 1 si le pays de l'étudiant est la Russie et 0 sinon.
- last_payment_amount - le montant du dernier paiement.
- days_last_lesson - le nombre de jours depuis la dernière leçon (en l'absence de la dernière leçon, remplacez par le nombre -100).
- days_last_payment - le nombre de jours à partir du dernier paiement (en l'absence du dernier paiement, nous remplaçons par le nombre -100).
Initialement, il y avait une centaine de signes, mais les calculs et les tests ont montré qu'ils n'affectaient pas le résultat final, ils ont donc été exclus comme non informatifs (par exemple, l'intensité des cours, le sexe de l'élève, son niveau, etc.). Comme modèle de classification binaire, une bibliothèque de renforcement de gradient sur les arbres de décision CatBoost a été utilisée.
Et voici la qualité de mon modèle (dans l'échantillon témoin):
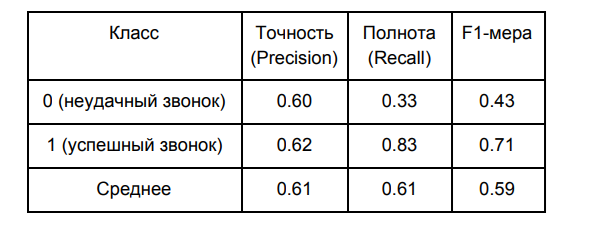
Ces résultats ont été obtenus pour la limite de séparation des classes de 0,5, qui est la valeur par défaut. Nous déterminons la limite de séparation de classe optimale sur la base des courbes ROC (caractéristique de fonctionnement du récepteur).
Pour ce faire, nous construisons la dépendance de caractéristiques telles que l'exhaustivité et la spécificité en fonction de différentes valeurs de la frontière séparant les classes:
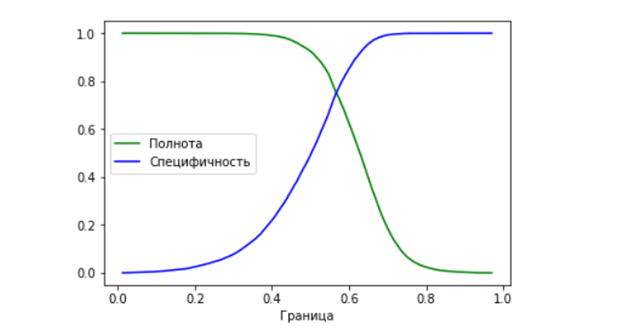
La valeur optimale de la frontière sera celle où l'on obtient en même temps les valeurs les plus élevées possibles de complétude et de spécificité (c'est-à-dire, dans ce cas, où les graphiques se croisent). Pour le modèle résultant, la bordure optimale était de 0,56717.
La qualité du modèle avec la bordure optimale est la suivante:
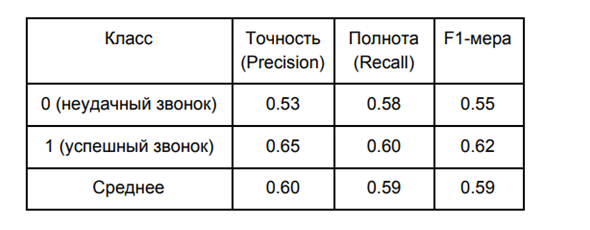
Dans notre situation, la précision du modèle était plus importante pour nous que son exhaustivité. C'est la précision accrue qui nous permet de réduire le nombre de prévisions faussement positives, c'est-à-dire qu'elle nous permet de réduire le nombre de situations où nous attendions un appel réussi, mais cela s'est avéré infructueux.
Pour résumer le mécanisme du modèle:
- pour chaque heure du jour et du jour de la semaine pour chaque élève, la probabilité de numérotation est calculée en tenant compte de ses caractéristiques et de son heure locale;
- pour un stockage supplémentaire, une heure est sélectionnée de 9 à 20 heures pour chaque jour de la semaine (l'heure est sélectionnée en fonction du fuseau horaire de l'élève);
- Avant d'enregistrer, l'heure est décalée sur l'heure de Moscou, car la numérotation sera effectuée dans le fuseau horaire de Moscou;
- Les résultats sont enregistrés dans la base de données.
Ainsi, les opérateurs de centres d'appels ont désormais prévu des données sur la probabilité de numérotation pour chaque utilisateur et pour chaque heure et chaque jour de la semaine. Si l'appel n'est pas urgent, l'opérateur peut choisir le créneau le plus optimal de la semaine et, dans les cas extrêmes - si l'appel ne peut plus être reporté - le moment le plus réussi de la journée de travail en cours.
Bien sûr, après l'introduction de mon modèle, il faudra faire une pause, puis refaire tout ce travail, mais avec de nouvelles données. Je peux faire des calculs abstraits à l'infini, calculer des probabilités et ajouter de nouvelles variables au modèle, mais jusqu'à ce que les statistiques vivantes confirment mon point, il est trop tôt pour fermer cette question.
Si cela vous a plu, je reviendrai après un certain temps avec les nouvelles données obtenues après l'introduction de mon modèle de prévision.