Je m'appelle Oleg Ermakov, je travaille dans l'équipe de développement backend de l'application Yandex.Taxi. Il est habituel pour nous de mener des stand-ups quotidiens où chacun de nous parle des tâches effectuées pendant la journée. C'est comme ça que ça se passe ...
Les noms des employés peuvent changer, mais les tâches sont bien réelles!À 12 h 45, toute l'équipe se rassemble dans la salle de réunion. Le premier mot est pris par Ivan, un développeur stagiaire.
Ivan:
J'ai travaillé sur la tâche d'afficher toutes les options possibles pour les montants que le passager pourrait donner au conducteur à un coût connu du voyage. La tâche est bien connue - elle s'appelle "Changement de pièces". Compte tenu des spécificités, il a ajouté plusieurs optimisations à l'algorithme. J'ai donné la demande de la piscine pour l'examen avant-hier, mais depuis lors, je corrige les commentaires.
Par le sourire satisfait d'Anna, il devint clair dont Ivan corrige les remarques.
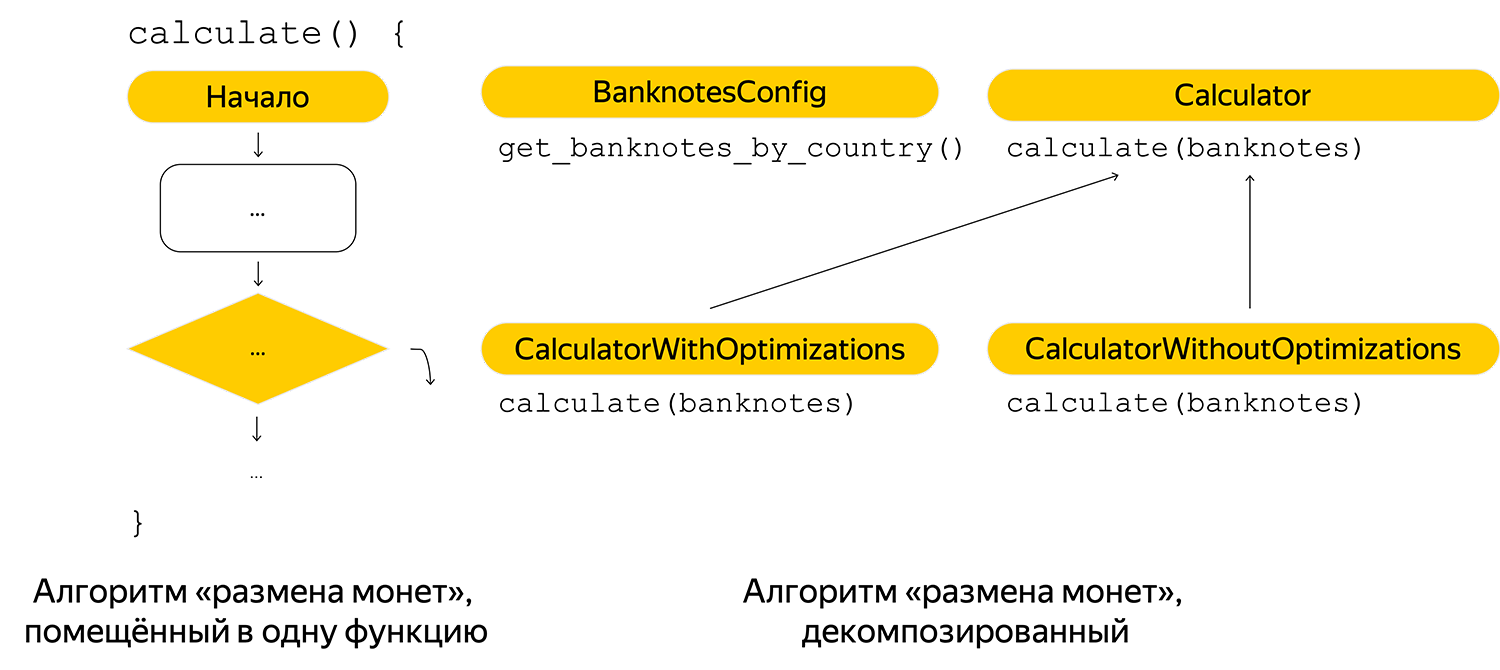
Tout d'abord, il a fait la décomposition minimale de l'algorithme, et il recevait intelligemment les billets de banque. Dans la première mise en œuvre, d'éventuels billets de banque ont été enregistrés dans le code, par conséquent, ils ont été sortis à la config par pays.
Ajout de commentaires pour l'avenir, afin que tout lecteur puisse rapidement comprendre l'algorithme:
for exception in self.exceptions[banknote]: exc_value = value + exception.delta if exc_value - cost >= banknote: continue if exc_value > cost >= exception.banknote: banknote_results.append(exc_value)
Bien sûr, j'ai passé le reste du temps à couvrir tout le code avec des tests.
RUB = [1, 2, 5, 10, 50, 100, 200, 500, 1000, 2000, 5000] CUSTOM_BANKNOTES = [1, 3, 7, 11] @pytest.mark.parametrize( 'cost, banknotes, expected_changes', [
En plus des tests habituels qui s'exécutent sur chaque build du projet, il a écrit un test qui utilise un algorithme sans optimisations (considérez-le comme un buste complet). Le résultat de cet algorithme pour chaque facture des 10 000 premiers cas mis dans un fichier et exécuté séparément sur l'algorithme avec des optimisations pour être sûr qu'il fonctionne vraiment correctement.
Prenons un moment pour nous distraire du stand-up et résumer les résultats locaux de tout ce que dit Ivan. Lors de l'écriture de code, l'objectif principal est d'assurer ses performances. Pour atteindre cet objectif, vous devez effectuer les tâches suivantes:
- Décomposer la logique métier en fragments atomiques. La lisibilité est compliquée lors de l'affichage d'un canevas de code écrit dans une fonction.
- Ajoutez des commentaires aux parties "particulièrement complexes" du code. Notre équipe a l'approche suivante: si on vous pose une question sur l'implémentation sur la revue de code (ils demandent d'expliquer l'algorithme), alors vous devez ajouter un commentaire. Mieux encore, pensez-y à l'avance et ajoutez-le vous-même.
- Rédiger des tests couvrant les principales branches de l'exécution de l'algorithme. Les tests ne sont pas seulement une méthode de vérification de l'intégrité du code. Ils servent toujours d'exemple d'utilisation de votre module.
Hélas, même les spécialistes ayant de nombreuses années d'expérience n'utilisent pas toujours ces approches dans leur travail. À
l'école de développement backend que nous faisons actuellement, les étudiants acquerront des compétences pratiques pour écrire du code de haute qualité architecturale. Notre autre objectif est de diffuser les pratiques de couverture des tests pour le projet.
Mais revenons au stand-up. Après Ivan, Anna parle.
Anna:
Je suis en train de développer un microservice pour retourner les images de promotion. Comme vous vous en souvenez, le service a initialement distribué des talons de données statiques. Ensuite, les testeurs ont demandé de les personnaliser, et je les ai mis dans la configuration, et maintenant je fais une implémentation «honnête» avec le retour des données de la base de données (PostgreSQL 10.9). La décomposition, initialement prévue, m'a beaucoup aidée, dans le cadre de laquelle l'interface de réception des données en logique métier ne change pas, et chaque nouvelle source (qu'il s'agisse d'une config, d'une base de données ou d'un microservice externe) ne met en œuvre que sa propre logique.

J'ai vérifié le système écrit sous charge, les tests ont montré que la poignée commence à freiner fortement lorsque nous allons dans la base de données. Selon expliquer, j'ai vu que l'indice n'est pas utilisé. Jusqu'à ce que je trouve comment le réparer.
Vadim:
Et quel genre de demande?
Anya:
Deux conditions sous OU:
SELECT * FROM table_1 JOIN table_2 ON table_1.some_id = table_2.some_id WHERE (table_2.attr1 = 'val' OR table_1.attr2 IN ('val1', 'val2')) AND table_1.deleted_at IS NULL AND table_2.deleted_at IS NULL ORDER BY table_2.created_at
La requête explique a montré qu'elle n'utilise pas l'un des indices pour les attributs attr1 de table_2 et attr2 de table_1.
Vadim:
Face à un comportement similaire dans MySQL, le problème est précisément dans la condition pour OR, à cause de laquelle un seul index est utilisé, par exemple attr2. Et la deuxième condition utilise le scan seq - un passage complet à travers la table. La demande peut être divisée en deux demandes indépendantes. En option, divisez et gelez le résultat de la requête côté backend. Mais alors vous devez penser à encapsuler ces deux demandes dans une transaction, ou à les combiner en utilisant UNION - en fait, du côté de la base:
SELECT * FROM table_1 JOIN table_2 ON table_1.some_id = table_2.some_id WHERE (table_2.attr1 = 'val') AND table_1.deleted_at IS NULL AND table_2.deleted_at IS NULL ORDER BY table_2.created_at SELECT * FROM table_1 JOIN table_2 ON table_1.some_id = table_2.some_id WHERE (table_1.attr2 IN ('val1' , 'val2')) AND table_1.deleted_at IS NULL AND table_2.deleted_at IS NULL ORDER BY table_2.created_at
Anya:
Merci, je vais essayer ^ _ ^
Pour résumer à nouveau:
- Presque toutes les tâches de développement de produits sont liées à l'obtention d'enregistrements de sources externes (services ou bases de données). Vous devez aborder soigneusement le problème de la décomposition des classes qui déchargent les données. Des classes correctement conçues vous permettront d'écrire des tests et de modifier les sources de données sans problème.
- Pour travailler efficacement avec la base de données, vous devez connaître les fonctionnalités de l'exécution des requêtes, par exemple comprendre expliquer.
Travailler avec les informations et organiser les flux de données fait partie intégrante des tâches de tout développeur backend. L'école présentera l'architecture de l'interaction des services (et des sources de données). Les étudiants apprendront à travailler avec des bases de données architecturales et en termes de fonctionnement - migration de données et tests.
Le dernier à parler est Vadim.
Vadim:
J'étais de service pendant une semaine, j'ai réglé la séquence des incidents. Une erreur ridicule dans le code a pris très longtemps: il n'y avait pas de journaux à la demande dans la prod, bien que leur création ait été écrite dans le code.
Par le silence lugubre de toutes les personnes présentes, il est clair - tout le monde était déjà en quelque sorte confronté au problème .
Pour obtenir tous les journaux dans le cadre de la demande, request_id est utilisé, qui est jeté dans tous les enregistrements sous la forme suivante:
log_extra est un dictionnaire avec des méta-informations de la demande, dont les clés et les valeurs seront écrites dans le journal. Sans passer log_extra à la fonction de journalisation, l'enregistrement ne sera pas associé à tous les autres journaux, car il n'aura pas request_id.
J'ai dû corriger l'erreur dans le service, la relancer et ensuite gérer l'incident. Ce n'est pas la première fois que cela se produit. Pour éviter que cela ne se reproduise, j'ai essayé de résoudre le problème globalement et de me débarrasser de log_extra.
J'ai d'abord écrit un wrapper sur l'exécution standard de la demande:
async def handle(self, request, handler): log_extra = request['log_extra'] log_extra_manager.set_log_extra(log_extra) return await handler(request)
Il était nécessaire de décider comment stocker log_extra dans une seule demande. Il y avait deux options. La première consiste à changer task_factory pour eventloop de asyncio:
class LogExtraManager: __init__(self, context: Any, settings: typing.Optional[Dict[str, dict]], activations_parameters: list) -> None: loop = asyncio.get_event_loop() task_factory = loop.get_task_factory() if task_factory is None: task_factory = _default_task_factory @functools.wraps(task_factory) def log_extrad_factory(ev_loop, coro): child_task = task_factory(ev_loop, coro) parent_task = asyncio.Task.current_task(loop=ev_loop) log_extra = getattr(parent_task, LOG_EXTRA_CONTEXT_KEY, None) setattr(child_task, LOG_EXTRA_CONTEXT_KEY, log_extra) return child_task
La deuxième option consiste à «pousser» la transition vers Python 3.7 via la commande d'infrastructure pour utiliser les variables de contexte :
log_extra_var = contextvars.ContextVar(LOG_EXTRA_CONTEXT_KEY) class LogExtraManager: def set_log_extra(log_extra: dict): log_extra_var.set(log_extra)
Eh bien et plus loin, il était nécessaire de transmettre stocké dans le contexte de log_extra dans l'enregistreur.
class LogExtraFactory(logging.LogRecord):
Résumé:
- Dans Yandex.Taxi (et partout dans Yandex) asyncio est activement utilisé. Il est important non seulement de pouvoir l'utiliser, mais aussi de comprendre sa structure interne.
- Développez l'habitude de lire les changelogs de toutes les nouvelles versions de la langue, réfléchissez à la façon dont vous pouvez vous faciliter la vie et celle de vos collègues à l'aide d'innovations.
- Lorsque vous travaillez avec des bibliothèques standard, n'ayez pas peur d'explorer leur code source et de comprendre leur appareil. Il s'agit d'une compétence très utile qui vous permettra de mieux comprendre le fonctionnement du module et d'ouvrir de nouvelles possibilités dans la mise en œuvre des fonctionnalités.
Les enseignants de l'école d'arrière-plan ont mangé plus d'une
livre de sel et rempli beaucoup de cônes dans le fonctionnement asynchrone des services. Ils expliqueront aux étudiants les caractéristiques du fonctionnement asynchrone de Python - à la fois au niveau pratique et dans l'analyse des internes des packages.
Livres et liens
L'apprentissage de Python peut vous aider:
- Trois livres: Python Cookbook , Diving Into Python 3 et Python Tricks .
- Conférences vidéo par des piliers de l'industrie informatique tels que Raymond Hettinger et David Beasley. À partir des conférences vidéo de la première, le rapport «Au-delà de PEP 8 - Meilleures pratiques pour un beau code intelligible» peut être distingué. Beasley vous conseille de regarder une performance sur asyncio.
Pour acquérir une meilleure compréhension de l'architecture, lisez les livres:
- "Applications très chargées . " Ici, les problèmes d'interaction avec les données sont décrits en détail (encodage des données, travail avec les données distribuées, réplication, partitionnement, transactions, etc.).
- «Microservices. Modèles de développement et de refactorisation . » Le livre présente les approches de base de l'architecture des microservices, décrit les lacunes et les problèmes auxquels on doit faire face lors du passage d'un monolithe aux microservices. Il n'y a presque rien dans le post à leur sujet, mais je vous conseille quand même de lire ce livre. Vous commencerez à comprendre les tendances des architectures de construction et à apprendre les pratiques de base de la décomposition de code.
Une autre des compétences les plus importantes que vous pouvez développer sans cesse en vous-même est la lecture du code de quelqu'un d'autre. Si vous réalisez soudain que vous lisez rarement le code de quelqu'un d'autre, je vous conseille de prendre l'habitude de regarder régulièrement de nouveaux
référentiels populaires.
Le stand-up a pris fin, tout le monde est allé travailler.