Les données de série chronologique ou les séries chronologiques sont des données qui changent au fil du temps. Les cotations de devises, la télémétrie des mouvements de transport, les statistiques d'accès au serveur ou la charge CPU sont des données de séries chronologiques. Les stocker nécessite des outils spécifiques - des bases de données temporelles. Il existe des dizaines d'outils, par exemple InfluxDB ou ClickHouse. Mais même les meilleures solutions de stockage de séries chronologiques présentent des inconvénients. Tous les stockages de séries chronologiques sont de bas niveau, adaptés uniquement aux données de séries chronologiques, et l'exécution et l'injection dans la pile actuelle sont coûteuses et douloureuses.

Mais, si vous avez une pile PostgreSQL, vous pouvez oublier InfluxDB et toutes les autres bases de données temporelles. Installez deux extensions, TimescaleDB et PipelineDB, et stockez, traitez et analysez les données de séries chronologiques directement dans l'écosystème PostgreSQL. Sans l'introduction de solutions tierces, sans les inconvénients des stockages temporels et sans les problèmes de leur exécution. Quelles sont ces extensions, quels sont leurs avantages et leurs capacités, dira
Ivan Muratov ( binakot ) - le chef du département de développement de la "First Monitoring Company".
Que sont les données de séries chronologiques ou les séries chronologiques?
Ce sont des données sur le processus qui sont collectées à différents moments de sa vie.
Par exemple, l'emplacement de la voiture: vitesse, coordonnées, direction ou utilisation des ressources sur le serveur avec des données sur la charge du processeur, la RAM utilisée et l'espace disque libre.
Les séries chronologiques ont plusieurs caractéristiques.
- Dans une sangle de fixation . Tout enregistrement de série chronologique possède un champ avec un horodatage auquel la valeur a été enregistrée.
- Les caractéristiques du processus, appelées niveaux de la série : vitesse, coordonnées, données de charge.
- Presque toujours avec de telles données, elles fonctionnent en mode ajout uniquement . Cela signifie que les nouvelles données ne remplacent pas les anciennes. Seules les données obsolètes sont supprimées.
- Les inscriptions ne sont pas considérées séparément les unes des autres . Les données ne sont utilisées que collectivement pour des fenêtres temporelles, des intervalles ou des périodes.
Solutions de stockage populaires
Le graphique que j'ai pris de
db-engines.com montre la popularité de divers modèles de stockage au cours des deux dernières années.
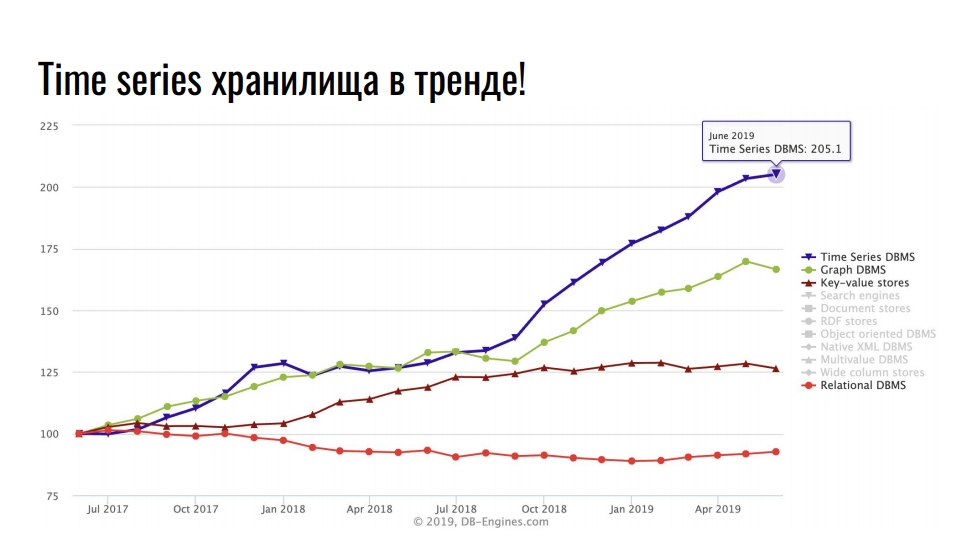
La première place est occupée par les stockages de séries chronologiques, en second lieu - les bases de données graphiques, puis - les bases de données de valeurs-clés et relationnelles. La popularité des référentiels spécialisés est associée à une croissance intensive de l'intégration des technologies de l'information: Big Data, réseaux sociaux, IoT, surveillance des infrastructures à forte charge. En plus des données commerciales utiles, même les journaux et les mesures prennent une énorme quantité de ressources.
Solutions de stockage populaires pour les données de séries chronologiques
Le graphique montre des solutions spécialisées pour stocker des données de séries chronologiques. L'échelle est logarithmique.
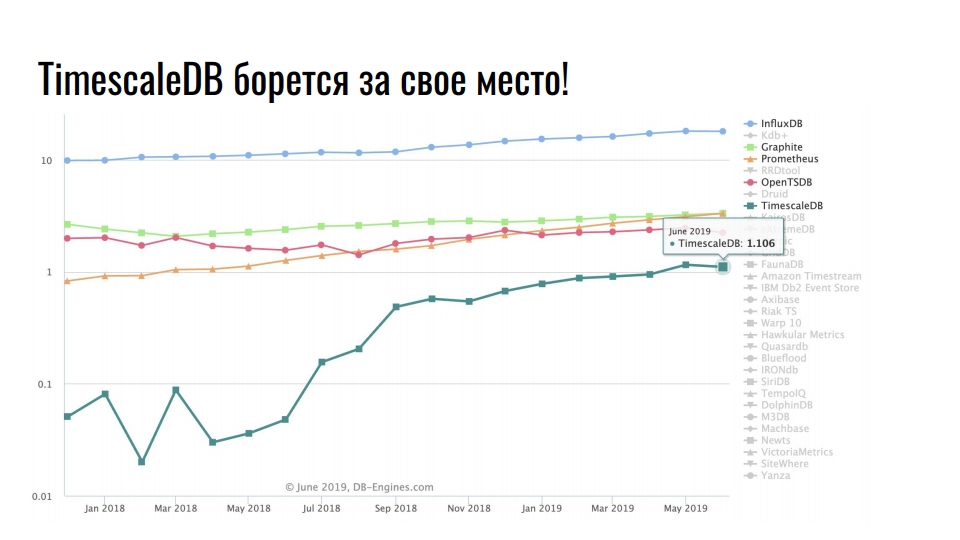
Leader stable InfluxDB. Tous ceux qui ont rencontré des données de séries chronologiques ont entendu parler de ce produit. Mais le graphique montre une multiplication par dix de TimescaleDB - une extension du SGBD relationnel se bat pour une place sous le soleil parmi les produits initialement développés dans le cadre de la série chronologique.
PostgreSQL n'est pas seulement une bonne base de données, mais aussi une plate-forme extensible pour développer des solutions spécialisées.
Postgres, Postgis et TimescaleDB
La First Monitoring Company surveille le mouvement des véhicules à l'aide de satellites. Nous suivons 20 000 véhicules et stockons les données de mouvement pendant deux ans. Au total, nous avons 10 To de données de télémétrie actuelles. En moyenne, chaque véhicule envoie 5 enregistrements de télémétrie par minute en conduisant. Les données sont envoyées via un équipement de navigation à nos serveurs télématiques. Ils reçoivent 500 paquets de navigation par seconde.
Il y a quelque temps, nous avons décidé de mettre à niveau globalement l'infrastructure et de passer d'un monolithe à des microservices. Nous avons appelé le nouveau système Waliot, et il est déjà en production - 90% de tous les véhicules y sont transférés.
Beaucoup de choses ont changé dans l'infrastructure, mais le lien central est resté inchangé - il s'agit de la base de données PostgreSQL. Nous travaillons maintenant sur la version 10 et nous nous préparons à passer à 11. En plus de PostgreSQL, en tant que stockage principal, dans la pile, nous utilisons PostGIS pour le calcul géospatial et TimescaleDB pour stocker un large éventail de données de séries chronologiques.
Pourquoi PostgreSQL?
Pourquoi essayons-nous d'utiliser une base de données relationnelle pour stocker des séries chronologiques, plutôt que des solutions spécialisées
ClickHouse pour ce type de données? Parce que dans le contexte de l'expertise accumulée et des impressions de travailler avec PostgreSQL, nous ne voulons pas utiliser une solution inconnue comme stockage principal.
Passer à une nouvelle solution est un risque.
Il existe de nombreuses solutions spécialisées pour le stockage et le traitement des données de séries chronologiques. La documentation n'est pas toujours suffisante et une large sélection de solutions n'est pas toujours bonne. Il semble que les développeurs de chaque nouveau produit souhaitent tout écrire à partir de zéro, car quelque chose n'était pas agréable dans la solution précédente. Pour comprendre ce qui n'aimait pas exactement, vous devez rechercher des informations, analyser et comparer. Une grande variété de
sommets , de
notes et de
comparaisons est plutôt effrayant que motivant pour essayer quelque chose. Vous devrez passer beaucoup de temps à essayer toutes les solutions par vous-même. Nous ne pouvons pas nous permettre d'adapter une seule solution pendant plusieurs mois. C'est une tâche difficile et le temps passé ne sera jamais payant. Par conséquent, nous avons choisi des extensions pour PostgreSQL.
Pendant la phase de développement de l'infrastructure Waliot, nous avons considéré InfluxDB comme le principal référentiel de télémétrie. Mais quand je suis tombé sur TimescaleDB et que j'ai effectué des tests, il n'y avait pas de questions sur le choix. PostgreSQL avec l'extension TimescaleDB vous permet d'utiliser d'autres extensions dans le même stockage PostGIS ou PipelineDB. Nous n'avons pas besoin d'extraire des données, de les transformer, d'effectuer des analyses et de les transférer sur le réseau. Tout se trouve sur un serveur ou dans un système en cluster - les données n'ont pas besoin d'être glissées. Tous les calculs sont effectués au même niveau.
Récemment,
Nikolay Samokhvalov , l'auteur du compte postgresmen, a
publié un lien vers un article intéressant sur l'utilisation de SQL pour le streaming de données. Cinq des six auteurs de l'article participent au développement de divers produits Apache et travaillent avec le traitement en continu. Par conséquent, l'article mentionne Apache Spark, Apache Flink, Apache Beam, Apache Calcite et KSQL de Confluent.
Mais pas l'article lui-même n'est intéressant, mais le
sujet sur Hacker News , dans lequel il est discuté. L'auteur du sujet écrit que, sur la base de l'article, il a implémenté presque toutes les idées basées sur PostgreSQL 11. Il a utilisé des extensions CitusDB pour la mise à l'échelle horizontale et le partage, PipelineDB pour le calcul de flux et les vues matérialisées, TimescaleDB pour le stockage des données de séries chronologiques et la coupe. Il utilise également plusieurs wrappers de données étrangères.
Un mélange fou de PostgreSQL et de ses extensions confirme une fois de plus que PostgreSQL n'est pas seulement un SGBD - c'est une plate-forme.
Et quand le stockage enfichable sera livré ... Ugh!
Ironiquement, lors de la recherche des solutions, nous avons trouvé
Outflux , le développement de l'équipe
TimescaleDB , qu'ils ont publié le 1er avril. Que pensez-vous qu'elle fait? Ceci est un utilitaire pour migrer d'InfluxDB vers TimescaleDB en une seule commande ...
Battage publicitaire Postgres!
Ne sous-estimez pas le pouvoir du battage médiatique! Nous plaisantons souvent que «le développement est motivé par le battage médiatique», car il influe sur nos perceptions des composants de réglage et d'infrastructure. Chez
HighLoad ++, nous discutons beaucoup de PostgreSQL, ClickHouse, Tarantool - ce sont des développements hype. Ne dites simplement pas que cela n'affecte pas vos préférences et le choix des solutions pour l'infrastructure ... Bien sûr, ce n'est pas le facteur principal, mais y a-t-il un effet?
Je travaille avec PostgreSQL depuis 5 ans. J'aime cette solution. Il résout presque toutes mes tâches en un rien de temps. Chaque fois que quelque chose tournait mal avec cette base, mes mains tordues étaient à blâmer. Par conséquent, le choix était prédéterminé.
TimescaleDB VS PipelineDB
Passons aux extensions TimescaleDB et PipelineDB. Que disent leurs créateurs des extensions?
TimescaleDB est une base de données de séries chronologiques open source optimisée pour une insertion rapide et des requêtes complexes.
PipelineDB est une extension hautes performances conçue pour exécuter des requêtes SQL continues
pour les données de séries chronologiques .
En plus de travailler avec des données de séries chronologiques, ils ont une histoire similaire. Timescale a été fondée en 2015 et Pipeline en 2013. Les premières versions de travail sont apparues respectivement en 2017 et 2015. Il a fallu deux ans aux équipes pour libérer la fonctionnalité minimale. Les versions de production des deux extensions ont eu lieu en octobre dernier avec une différence d'une semaine. Apparemment, pressés les uns après les autres.
GitHub a un tas d'étoiles et de fourchettes, qui, comme d'habitude, ne sont pas un seul commit. C'est comme ça que l'Open Source fonctionne, il n'y a rien à faire. Mais il y a beaucoup d'étoiles,
TimescaleDB a plus que
PipelineDB , et même plus que PostgreSQL lui-même.
Les extensions semblent être similaires, mais elles se positionnent différemment.
TimescaleDB prétend avoir inséré des millions d'enregistrements par seconde et stocké des centaines de milliards de lignes et des dizaines de téraoctets de données. L'extension est plus rapide que InfluxDB, Cassandra, MongoDB ou vanilla PostgreSQL. Prise en charge des outils de réplication et de sauvegarde en streaming. TimescaleDB est une extension, pas un fork de PostgreSQL.
PipelineDB stocke uniquement le résultat des calculs de streaming, sans avoir besoin de stocker des données brutes pour leurs calculs. L'extension est capable d'agrégation continue sur des flux de données en temps réel, se combinant avec des tables conventionnelles pour des calculs dans le contexte d'un domaine. PipelineDB est une extension, pas une fourchette, mais au départ c'était une fourchette.
Timescaledb
Maintenant en détail sur les extensions. Commençons par TimescaleDB. Je travaille avec lui depuis près de 2 ans. Faites-le glisser en production avant la version finale. Examinons des exemples d'application.
Stockage des métriques d'infrastructure . Nous avons des mesures de consommation des ressources du conteneur Docker, du temps de validation des mesures, de l'identifiant du conteneur et des champs de consommation des ressources, par exemple, de la mémoire libre. Nous devons afficher des statistiques pour tous les conteneurs avec une quantité moyenne de fenêtres de mémoire libres pendant 10 secondes. La requête que vous voyez résout ce problème et TimescaleDB peut être utilisé comme référentiel pour les métriques d'infrastructure.
SELECT time_bucket('10 seconds', time) AS period, container_id, avg(free_mem) FROM metrics WHERE time < now() - interval '10 minutes' GROUP BY period, container_id ORDER BY period DESC, container_id;
period | container_id | avg -----------------------+--------------+--- 2019-06-24 12:01:00+00 | 16 | 72202 2019-06-24 12:01:00+00 | 73 | 837725 2019-06-24 12:01:00+00 | 96 | 412237 2019-06-24 12:00:50+00 | 16 | 1173393 2019-06-24 12:00:50+00 | 73 | 90104 2019-06-24 12:00:50+00 | 96 | 784596
Pour les calculs . Nous devons calculer le nombre de camions qui ont quitté Krasnodar et leur tonnage total par jour.
SELECT time_bucket('1 day', time) AS day, count(*) AS trucks_exiting, sum(weight) / 1000 AS tonnage FROM vehicles INNER JOIN cities ON cities.name = 'Krasnodar' WHERE ST_Within(last_location, ST_Polygon(cities.geom, 4326)) AND NOT ST_Within(current_location, ST_Polygon(cities.geom, 4326)) GROUP BY day ORDER BY day DESC LIMIT 3;
Il utilise également des fonctions de l'extension PostGIS pour calculer le transport qui a quitté la ville, plutôt que de simplement s'y déplacer.
Surveillance du taux de change . Le troisième exemple concerne les crypto-monnaies. La demande vous permet d'afficher l'évolution du prix d'Ethereum par rapport au Bitcoin et au dollar américain au cours des 2 dernières semaines par jour.
SELECT time_bucket('14 days', c.time) AS period, last(c.closing_price, c.time) AS closing_price_btc, last(c.closing_price, c.time) * last(b.closing_price, c.time) filter (WHERE b.currency_code = 'USD') AS closing_price_usd FROM crypto_prices c JOIN btc_prices b ON time_bucket('1 day', c.time) = time_bucket('1 day', b.time) WHERE c.currency_code = 'ETH' GROUP BY period ORDER BY period DESC;
C'est tout de même clair et pratique pour nous SQL.
Qu'est-ce qui est si cool avec TimescaleDB?
Pourquoi ne pas utiliser les outils de partitionnement de table intégrés? Et pourquoi s'embêter à casser des tables? La réponse évidente est la
vitesse d'insertion dans de telles bases de données . Le graphique montre les mesures réelles du taux d'insertion du nombre de lignes par seconde entre la table vanilla régulière PostgreSQL 10 sans sectionnement et l'hypertable TimescaleDB.
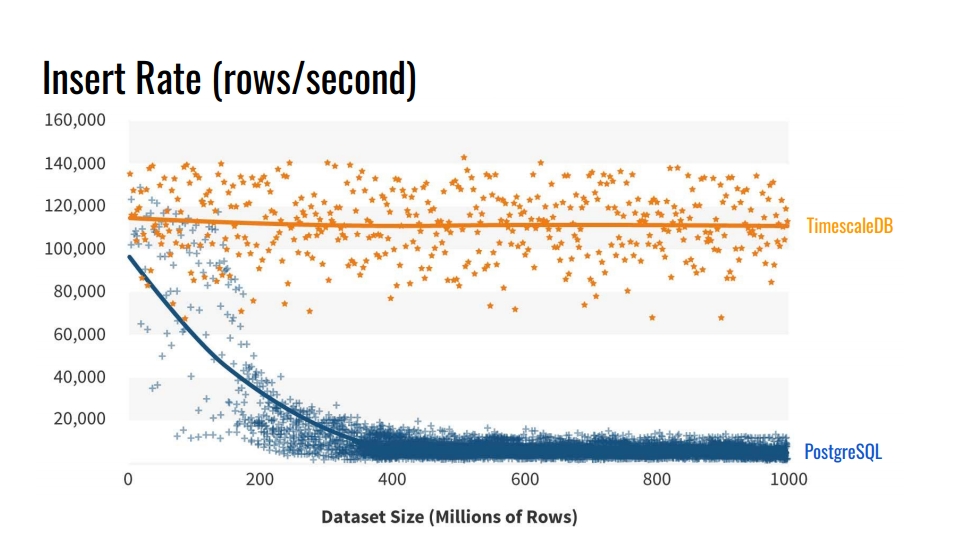
Cette référence écrit 1 milliard de lignes sur une machine, simulant un scénario de collecte de métriques de l'infrastructure. L'enregistrement contient le temps, l'identifiant du composant d'infrastructure et 10 mesures. La référence a été exécutée sur Azure VM avec 8 cœurs et 28 gigaoctets de RAM, ainsi que des disques SSD réseau. L'insertion a été effectuée par lots de 10 000 enregistrements.
D'où vient cette dégradation des performances de PostgreSQL? Parce que lorsque vous insérez, vous devez également mettre à jour les index de table. Quand ils ne rentrent pas dans le cache, nous commençons à charger des disques. Le partitionnement résout ce problème si les index de la section dans laquelle nous insérons les données sont placés dans la RAM.
Regardons le tableau suivant. Cela compare le système de partitionnement déclaratif intégré à PostgreSQL 10 et l'hyper table TimescaleDB. Sur l'axe horizontal, le nombre de sections.
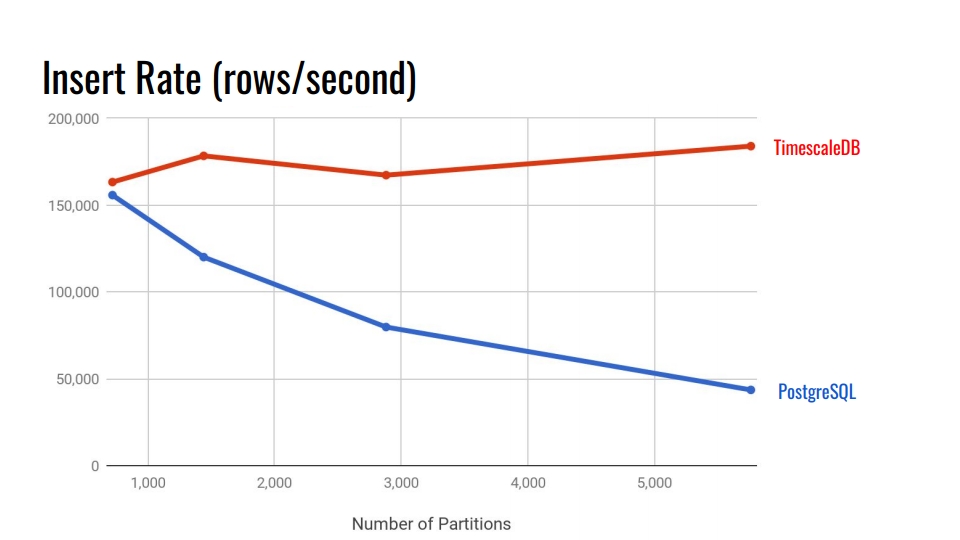
Dans TimescaleDB, la dégradation est négligeable avec l'augmentation des sections. Les développeurs d'extensions affirment qu'ils s'en sortent bien avec 10 000 sections dans une seule instance PostgreSQL.
Dans PostgreSQL, l'implémentation native se dégrade considérablement après 3000. En général, le partitionnement déclaratif dans PostgreSQL est un grand pas en avant, mais il ne fonctionne bien que pour les tables avec moins de charge. Par exemple, pour les biens, les acheteurs et d'autres entités de domaine qui n'entrent pas dans le système de manière aussi intensive que les métriques.
Dans les versions 11 et 12 de PostgreSQL, la prise en charge du partitionnement natif apparaîtra et vous pouvez essayer d'exécuter des tests comparatifs pour les données de séries chronologiques avec de nouvelles versions. Mais il me semble que TimescaleDB est encore mieux. Tous les benchmarks de TimescaleDB peuvent être trouvés sur leur
github et essayer.
Caractéristiques clés
J'espère que vous avez déjà un intérêt pour l'extension. Passons en revue les principales fonctionnalités de TimescaleDB pour consolider ce sentiment.
Partitionnement à travers des hypertables . TimescaleDB utilise le terme «hypertable» pour les tables auxquelles la fonction create_hypertable () a été appliquée. Après cela, la table deviendra le parent de toutes les sections héritées - morceaux. La table parent elle-même ne contiendra aucune donnée, mais sera un point d'entrée pour toutes les requêtes et un modèle lors de la création automatique de nouvelles sections. Toutes les sections ne sont pas stockées dans le schéma principal de vos données, mais dans un schéma spécial. Ceci est pratique car nous ne voyons pas des milliers de ces sections dans le schéma de données.
L'extension est intégrée dans le planificateur et l'exécuteur de requêtes . Grâce à des crochets spéciaux dans PostgreSQL, TimescaleDB comprend quand il accède à un hypertable. TimescaleDB analyse la requête et redirige les requêtes uniquement vers les sections nécessaires en fonction des conditions spécifiées dans l'appel SQL lui-même. Cela vous permet de paralléliser le travail avec des sections lors de l'extraction d'une quantité importante de données.
L'extension n'impose pas de restrictions sur SQL . Vous pouvez utiliser librement les unions, les agrégats, les fonctions de fenêtre, les CTE et les index supplémentaires. Si vous avez vu la liste des restrictions pour le système de partitionnement intégré, cela devrait vous plaire.
Fonctions supplémentaires utiles spécifiques aux données de séries chronologiques:
- «Time_bucket» - «date_trun» d'une personne en bonne santé;
- histogrammes - remplir les intervalles manqués en utilisant l'interpolation ou la dernière valeur connue;
- travailleur en arrière-plan - services qui vous permettent d'effectuer des opérations en arrière-plan: nettoyage d'anciennes sections, réorganisation.
TimescaleDB vous permet de rester dans le puissant écosystème PostgreSQL . Cette extension ne casse pas PostgreSQL, donc toutes les solutions de haute disponibilité, les systèmes de sauvegarde, les outils de surveillance continueront de fonctionner. TimescaleDB est ami avec Grafana, Périscope, Prométhée, Telegraf, Zabbix, Kubernetes, Kafka, Seeq, JackDB.
Grafana prend déjà en charge nativement
TimescaleDB comme source de données. Grafana comprend dès le départ que PostscreSQL a TimescaleDB. Le générateur de requêtes de Grafana sur les tableaux de bord comprend des fonctions TimescaleDB supplémentaires, telles que «time_bucket», «first», «last». Vous pouvez créer des graphiques directement à partir de la base de données relationnelle avec ces fonctions de série temporelle sans requêtes gigantesques.
Prometheus dispose d' un adaptateur qui vous permet d'en fusionner les données et d'utiliser TimescaleDB comme un entrepôt de données fiable. Utilisez un adaptateur pour ne pas stocker de données dans Prometheus pendant des années.
Il existe également un
plugin Telegraf . La solution vous permet de supprimer complètement Prometheus. Les données d'infrastructure sont immédiatement transférées à TimescaleDB et lues via Telegraf.
Licences et actualités
Il n'y a pas si longtemps, la société est passée à un nouveau modèle de licence. La plupart du code est sous licence Apache 2.0. Une petite partie est gratuite, mais sous licence TSL.
Il existe une version Enterprise avec une licence commerciale. Ne vous inquiétez pas, pas tous les goodies de la version Enterprise. Fondamentalement, il existe une automatisation telle que la suppression automatique des morceaux obsolètes, qui peut être effectuée via un simple "cron" et des choses similaires.
Maintenant, l'entreprise travaille activement sur une solution de cluster. Peut-être tombera-t-il dans la version Enterprise. Il existe également une version cloud pour les startups qui souhaitent réussir à pénétrer le marché avant que les investisseurs ne manquent d'argent.
Des nouvelles:
- un million de téléchargements au cours de la dernière année et demie;
- Investissement de 31 millions de dollars;
- Collaboration active avec MS Azure concernant les solutions IoT.
Pour résumer
TimescaleDB est conçu pour stocker des données de séries chronologiques. Il s'agit d'un système de partitionnement puissant avec des restrictions minimales par rapport aux natifs de PostgreSQL.
Malheureusement, l'extension n'a pas encore de version multinode. Si vous voulez un multimaître ou un fragment, vous devez jouer, par exemple, avec CitusDB. Si vous voulez une réplication logique, cela fera mal. Mais ça fait toujours mal avec elle.
Pipelinedb
Parlons maintenant de la deuxième extension. Malheureusement, nous n'avons pas pu le tester correctement au combat. Maintenant, il passe par l'étape d'adaptation dans notre système. Certes, il y a un problème dont je parlerai plus près de la fin.
Comme dans le cas précédent, nous commençons par de vrais exemples. Il est plus facile de comprendre les avantages de l'extension et la motivation à l'utiliser.
Collecte de statistiques . Imaginez que nous collections des statistiques sur les visites de notre site Web. Nous avons besoin d'analyses des pages les plus populaires, du nombre d'utilisateurs uniques et d'une idée des retards de ressources. Tout cela doit être mis à jour en temps réel. Mais nous ne voulons pas toucher à chaque fois la table de données et créer une requête, ni mettre à jour la vue en haut de la table.
CREATE CONTINUOUS VIEW v AS SELECT url::text, count(*) AS total_count, count(DISTINCT cookie::text) AS uniques, percentile_cont(0.99) WITHIN GROUP (ORDER BY latency::integer) AS p99_latency FROM page_views GROUP BY url;
url | total_count | uniques | p99_latency -----------+-------------+---------+------------ some/url/0 | 633 | 51 | 178 some/url/1 | 688 | 37 | 139 some/url/2 | 508 | 88 | 121 some/url/3 | 848 | 36 | 59 some/url/4 | 126 | 64 | 159
Le traitement en streaming et l'extension PipelineDB viennent à la rescousse. L'extension ajoute l'abstraction CONTINUES VIEW. Dans la version russe, cela peut ressembler à une «présentation continue». Cette vue est automatiquement mise à jour lorsqu'elle est insérée dans le tableau avec les enregistrements de visites, alors que sur la base de nouvelles données, sans lecture déjà enregistrée à l'avance.
Flux de données . PipelineDB ne se limite pas au nouveau type de vue. Supposons que nous effectuions des tests A / B et collections des analyses en temps réel sur l'efficacité d'une nouvelle solution d'entreprise. Mais nous ne voulons pas stocker les données sur les actions des utilisateurs eux-mêmes. Nous ne sommes intéressés que par le résultat - quel groupe a le plus de conversion.
Pour éviter le stockage direct de données brutes pour le streaming informatique, nous avons besoin d'une telle abstraction que les
flux - flux de données . PipelineDB présente cette fonctionnalité. Vous pouvez créer des flux comme des tables régulières. Sous le capot, ce sera «FOREIGN TABLE» basé sur la file d'attente ZeroMQ, que l'extension utilise imperceptiblement de notre part. Les données entrent dans la file d'attente interne ZeroMQ et déclenchent une mise à jour de la vue continue.
CREATE STREAM ab_event_stream ( name text, ab_group text, event_type varchar(1), cookie varchar(32) ); CREATE CONTINUOUS VIEW ab_test_monitor AS SELECT name, ab_group, sum(CASE WHENevent_type = 'v' THEN 1 ELSE 0 END) AS view_count, sum(CASE WHENevent_type = 'c' THEN 1 ELSE 0 END) AS conversion_count, count(DISTINCT cookie) AS uniques FROM ab_event_stream GROUP BY name, ab_group;
Ensuite, nous créons «VUE CONTINUE» à partir des données d'un flux créé précédemment. Lorsque les données arrivent dans le flux, la vue est mise à jour en fonction de ces données. Après cela, les données seront simplement supprimées, ne seront enregistrées nulle part et n'occuperont pas d'espace disque. Cela vous permet de créer des analyses sur une quantité presque illimitée de données, de les charger dans le flux de données PipelineDB et de lire le résultat du calcul à partir d'une vue continue.
Stream computing Après avoir créé le flux de données et la vue continue, nous pouvons travailler avec le streaming informatique. Cela ressemble à ceci.
INSERT INTO ab_event_stream (name, ab_group, event_type, cookie) SELECT round(random() * 2) AS name, round(random() * 4) AS ab_group, (CASE WHENrandom() > 0.4 THEN 'v' ELSE 'c' END) AS event_type, md5(random()::text) AS cookie FROM generate_series(0, 100000); SELECT ab_group, uniques FROM ab_test_monitor; SELECT ab_group, view_count * 100 / (conversion_count + view_count) AS conversion_rate FROM ab_test_monitor;
Le premier "SELECT" donne le groupe "ab" et le nombre de visiteurs uniques. Le second - donne le rapport entre les groupes - conversion. C'est tout le test A / B sur cinq appels SQL dans une base de données relationnelle.
La vue est mise à jour dynamiquement. Vous ne pouvez pas attendre le traitement de l'ensemble du tableau de données, mais lire les résultats intermédiaires qui ont déjà été traités. Les vues sont lues de la même manière que PostgreSQL standard. Vous pouvez également combiner une vue avec des tableaux ou même d'autres vues. Il n'y a aucune restriction.
Topologie
Kafka reçoit la télémétrie, le sujet dans Kafka envoie ces données à PostgreSQL, et nous les agrégons davantage. Par exemple, nous combinons avec une table ordinaire et redirige les données vers le flux. De plus, il provoque la mise à jour de la présentation continue correspondante, à partir de laquelle les clients de la base de données peuvent déjà lire les données finies.
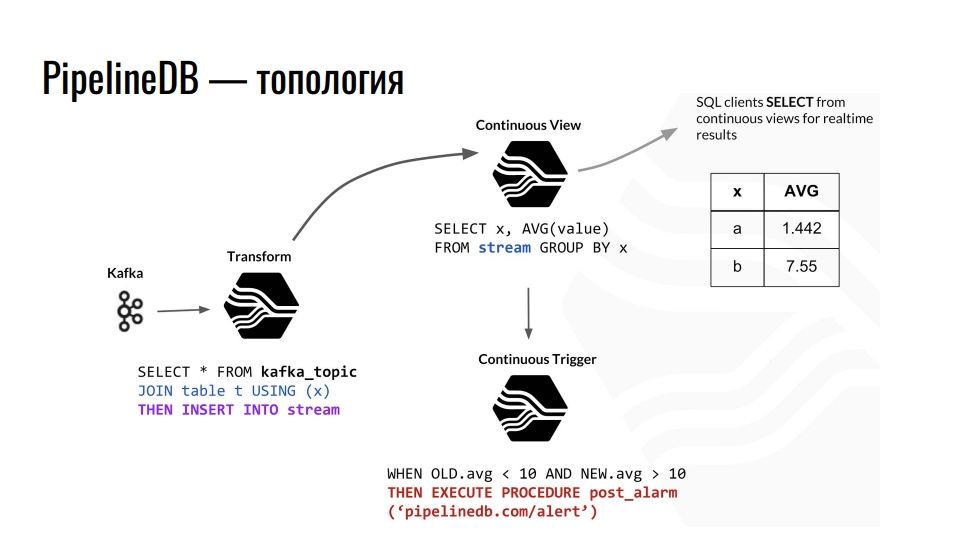 Un exemple de la topologie des composants PipelineDB à l'intérieur de PostgreSQL. Le circuit est emprunté à une présentation de Derek Nelson.
Un exemple de la topologie des composants PipelineDB à l'intérieur de PostgreSQL. Le circuit est emprunté à une présentation de Derek Nelson.En plus des flux et des vues, l'extension fournit également une abstraction de «transform» - convertisseurs ou mutateurs. Cette vue, mais visait à convertir le flux de données entrant en une sortie modifiée. À l'aide de ces mutateurs, vous pouvez modifier la présentation des données ou les filtrer. Du mutateur, tout tombe dans la vue CONTINUOUS VIEW. Nous y faisons déjà des demandes pour les entreprises. Quiconque connaît la programmation fonctionnelle doit comprendre l'idée.
Dans PipelineDB, nous pouvons suspendre un déclencheur sur nos vues et effectuer des actions, par exemple, «alerte». Avec tous ces calculs, nous ne stockons jamais les données brutes nous-mêmes, sur la base desquelles nous les calculons tous. Ceux-ci peuvent être des téraoctets, que nous téléchargeons séquentiellement sur un serveur avec un disque de cent gigaoctets. Après tout, nous ne sommes intéressés que par le résultat des calculs.
Caractéristiques clés
L'extension PipelineDB est plus difficile à apprendre que TimescaleDB. Dans TimescaleDB, nous créons une table, lui disons qu'elle est hypertable et profitons de la vie en utilisant plusieurs fonctions supplémentaires offertes par l'extension.
PipelineDB résout le problème du streaming informatique dans les bases de données relationnelles . La tâche de traitement en continu des données est plus compliquée que le partitionnement en termes d'intégration et d'utilisation. Cependant, tout le monde n'a pas d'énormes données et des milliards de lignes. Pourquoi compliquer l'infrastructure s'il y a PipelineDB? L'extension fournit ses propres implémentations de représentations, de flux, de convertisseurs et d'agrégats pour le traitement de flux. Il est également
intégré dans le planificateur de requêtes et l'exécuteur de requêtes permet d'implémenter le concept de stream computing dans une base de données relationnelle.
Comme TimescaleDB, l'extension PipelineDB
n'impose pas de restrictions SQL dans PostgreSQL . Il existe plusieurs fonctionnalités, par exemple, vous ne pouvez pas combiner deux flux, mais ce n'est pas nécessaire.
Prise en charge des structures de données probabilistes et des algorithmes . L'extension utilise le filtre Bloom pour SELECT DISTINCT, HyperLogLog pour COUNT (DISTINCT) et T-Digest pour percentile_count () directement dans SQL. Cela améliore la productivité.
Écosystème L'extension vous permet de travailler avec les solutions de haute disponibilité habituelles, les outils de surveillance et tout ce qui est familier dans PostgreSQL.
Compte tenu des spécificités de l'informatique en streaming, PipelineDB a des
intégrations avec Apache Kafka et avec Amazon Kinesis, un service d'analyse en temps réel. Puisque PipelineDB n'est plus une fourchette, mais une extension, l'intégration avec le reste du zoo devrait également être prête à l'emploi. Un must, mais nous ne vivons pas dans un monde idéal, et tout mérite d'être vérifié.
Licences et actualités
Tout le code est sous licence Apache 2.0. Il existe un abonnement payant au support de différentes galeries de tournage, ainsi qu'une version cluster avec une licence commerciale. Basée sur PipelineDB, la société fournit un service d'analyse Stride.
Avant de commencer à parler de l'extension, j'ai dit qu'il y avait un «mais». Il est temps de parler de lui. Le 1er mai 2019, l'équipe PipelineDB a annoncé qu'elle faisait désormais partie de Confluent. C'est l'entreprise qui développe KSQL - un moteur de streaming de données dans Kafka avec la syntaxe SQL. Maintenant, Victor Gamov, co-fondateur du podcast Debriefing, y travaille.
Qu'est-ce qui en découle? PipelineDB a gelé sur la version 1.0.0. En plus de corriger les bogues critiques, rien n'est prévu. En raison de la prise de contrôle, nous nous attendons à l'intégration d'Uber de Kafka avec PostgreSQL. C'est peut-être Confluent basé sur un stockage enfichable qui fera quelque chose de cool.
Que faire Accédez à TimescaleDB. Dans la dernière version, ils ont fait leur «VUE CONTINUE» avec le blackjack. Bien sûr, la fonctionnalité n'est plus aussi cool que dans PipelineDB, mais c'est une question de temps.
Pour résumer
PipelineDB est conçu pour un traitement de données en continu haute performance. Il vous permet d'effectuer des calculs sur de grands ensembles de données sans avoir à enregistrer les données elles-mêmes.
Avec PipelineDB, lorsque nous envoyons un flux de données à PostgreSQL dans un flux, nous les considérons comme virtuels. Nous ne sauvegardons pas les données, mais agrégons, calculons et éliminons. Vous pouvez créer un serveur de 200 gigaoctets et éliminer des téraoctets de données via des flux. Nous obtiendrons le résultat, mais les données elles-mêmes seront supprimées.
Si pour une raison quelconque, la "VUE CONTINUE" de TimescaleDB ne vous suffit pas, essayez PipelineDB. Il s'agit d'un projet open source sous licence Apache. Il n'ira nulle part, bien qu'il ne soit plus activement développé. Mais les choses peuvent changer, Confluent n'a pas encore écrit sur les plans d'expansion.
Utilisation de TimescaleDB et PipelineDB
Avec PostgreSQL et deux extensions,
nous pouvons stocker et traiter de grands tableaux de données de séries chronologiques . Vous pouvez penser à de nombreuses applications. Regardons un exemple de mon domaine - la surveillance des véhicules.

L'équipement de navigation envoie en continu des enregistrements de télémétrie à nos serveurs. Ils analysent divers textes et protocoles binaires dans un format commun et envoient des données à Kafka dans un sujet spécial. À partir de là, ils passent par l'intégration avec PipelineDB dans le flux de données de télémétrie à l'intérieur de PostgreSQL. Ce flux met à jour la vue de l'état actuel des véhicules et l'analyse globale de la flotte, et sur la base du déclencheur provoque l'enregistrement des enregistrements de télémétrie dans l'hypertable TimescaleDB.
Avec les extensions, nous avons trois avantages.
- Analyses en temps réel.
- Stockage des données de séries chronologiques.
- Diminution du volume de télémétrie stockée. À l'aide du mutateur PipelineDB, nous agrégons des données, par exemple, d'une minute, en calculant des valeurs moyennes.
Grafana prend en charge les fonctionnalités de TimescaleDB. Par conséquent, il est possible de créer des graphiques en fonction des mesures commerciales directement à partir de la boîte, jusqu'aux pistes sur la carte par coordonnées. Le département analytique sera ravi.
Pour "toucher" tout vous-même, regardez
la démo sur GitHub et exécutez l'
image Docker - à l'intérieur de l'assembly des derniers PostgreSQL, TimescaleDB et PipelineDB.
Total
PostgreSQL vous permet de combiner différentes extensions, ainsi que d'ajouter vos propres types de données et fonctions pour résoudre des problèmes spécifiques. Dans notre cas, l'utilisation des extensions TimescaleDB et PostGIS couvre presque entièrement les besoins de stockage de données de séries chronologiques et de calculs géospatiaux. Avec l'extension PipelineDB, nous pouvons effectuer des calculs continus pour diverses analyses et statistiques, et l'utilisation de colonnes JSONB nous permet de stocker des données faiblement structurées dans une base de données relationnelle. Les solutions Open Source suffisent à la tête - nous n'utilisons pas de solutions commerciales.
Ces extensions n'imposent pratiquement pas de restrictions à l'écosystème autour de PostgreSQL, telles que les solutions de haute disponibilité, les systèmes de sauvegarde, les outils de surveillance et d'analyse des journaux. Nous n'avons pas besoin de MongoDB s'il y a des colonnes JSONB, et nous n'avons pas besoin d'InfluxDB s'il y a TimescaleDB.
Vous aimez l'histoire d'Ivan et souhaitez partager quelque chose de similaire? Postulez avant le 7 septembre chez HighLoad ++ à Moscou. Le programme se remplit progressivement.En plus des cas de base de données, il y aura des rapports sur l'architecture, l'optimisation et, bien sûr, les charges élevées. Soumettez un rapport avant la date limite, nous vous attendons parmi les intervenants!