Les tests unitaires sont excellents, mais un n'est pas suffisant. Souvent, vous voulez également vous assurer que l'application en cours d'exécution fonctionnera. Les tests d'intégration viennent à la rescousse. Il est de plus en plus utilisé pour tester les services et Docker vous permet de gérer facilement votre environnement de test. Mais, comme toujours, les choses ne sont pas si simples quand il y a beaucoup plus de microservices et de dépendances.
Yuri Badalyants de RIT ++ a raconté comment dans 2GIS ils testent un tas d'un grand nombre de services et tout un zoo technologique. Sous la coupe, la version de ce rapport, complétée et mise à jour sous la supervision attentive de l'orateur: quelles options vous avez essayées, ce que vous avez trouvé, quels problèmes vous n'avez pas à résoudre maintenant. Il s'agira de Docker, de Testcontainers et également de Scala.
À propos du conférencier: Yuri Badalyants (@
LMnet ) a commencé sa carrière en 2011 en tant que développeur Web, a travaillé avec PHP, JavaScript et Java. Maintenant, il écrit sur Scala dans 2GIS.
Casino
2GIS fournit des cartes de ville et des répertoires d'entreprises depuis 20 ans et nous avons récemment une
nouvelle version avec une carte illimitée de la Russie. Je vais vous parler de l'expérience acquise pendant que je travaillais dans l'équipe Casino. Cette équipe intervient dans trois domaines principaux:
- Publicité - quels annonceurs afficher, lesquels masquer, lesquels augmenter et comment abaisser la note.
- BigData est lié à la publicité et à sa personnalisation, ainsi qu'à la construction d'analyses et de métriques.
- Crawler est un programme qui recherche des organisations sur Internet pour les ajouter automatiquement à la base de données.
Ces trois domaines sont les tâches principales qui, à leur tour, comportent un grand nombre de sous-tâches. Actuellement, il existe plus de 25 microservices écrits en Scala. Il s'agit exclusivement de notre code, mais nous utilisons également des systèmes tiers, par exemple, PostgreSQL, Cassandra et Kafka. Nous stockons les données dans Hadoop et les traitons dans Spark. De plus, nous utilisons les méthodes d'apprentissage automatique fournies par l'équipe Data Science.
En conséquence, nous avons un grand nombre de services et de microservices, un grand nombre de dépendances et, bien sûr, tout cela doit être testé d'une manière ou d'une autre.
Bien sûr, nous écrivons des tests unitaires. Cependant, même si tous les tests sont verts, cela ne signifie pas que tout fonctionne. Quelque chose peut mal tourner pendant la phase d'intégration des composants ou des microservices. Par conséquent, nous écrivons des tests d'intégration.
Tests d'intégration
Chaque microservice développé par l'équipe Casino résout son problème commercial et se trouve dans un référentiel séparé dans GitLab. Cet article se concentrera sur les tests d'intégration au sein d'un tel référentiel (microservice) avec des dépendances verrouillées, qui est la responsabilité des développeurs eux-mêmes. L'équipe QA teste l'interaction des microservices, et je n'aborderai pas ce sujet.
Lorsque j'ai rejoint l'équipe pour la première fois, fin 2016, il y avait approximativement le schéma de test d'intégration suivant:
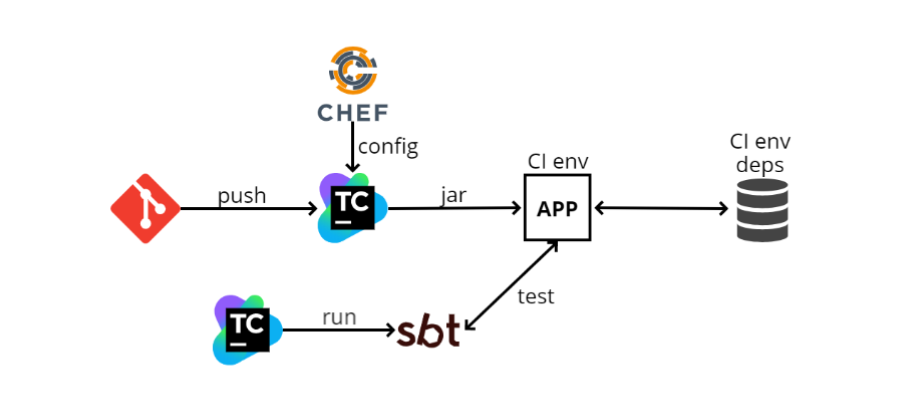
- Le développeur insère son code dans GIT, après quoi le code du microservice entre dans TeamCity. TeamCity commence à construire du code et à exécuter des tests.
- TeamCity prend le fichier de configuration (config) de Chef (un système de gestion de configuration similaire à Ansible, uniquement écrit en Ruby). Chef sert également à automatiser le déploiement. Quand j'ai 100 machines, je ne veux pas aller sur chacune d'elles et installer ce dont j'ai besoin sur SSH, et Chef me permet d'automatiser cela.
- TeamCity collecte le fichier jar (puisque nous écrivons dans Scala, l'artefact que nous publions est le jar), puis le programme le charge dans l'environnement CI. Notre application y est déployée, il y a aussi quelques dépendances. Dans le diagramme, l'une des dépendances est représentée comme une base de données. Il peut y avoir autant de dépendances que possible, et grâce à Chef, notre application les connaît et commence à interagir avec elles.
- Ensuite, TeamCity lance SBT (c'est notre système de construction où la compilation et les tests sont exécutés) et exécute les tests eux-mêmes. Ils sont relativement similaires aux tests unitaires, mais ils fonctionnent principalement sur ce principe: aller via http à une adresse spécifique, vérifier une méthode et voir ce qu'elle renvoie; ou faites un peu de préparation, puis voyez si ce dont vous avez besoin est revenu.
Que dire d'un tel dispositif? Plus important encore, cela fonctionne. Lorsque tout est configuré, l'exécution des tests est facile, car ils ressemblent à des tests unitaires. Mais les avantages s'arrêtent là.
Et les inconvénients commencent.
L'environnement CI est toujours activé , ce qui représente un gaspillage supplémentaire de ressources. Puisque Chef est une configuration statique, vous devriez toujours avoir une sorte de machine où toutes les dépendances seront configurées, où les applications seront déployées indépendamment. Une telle machine consommera des ressources supplémentaires, car les tests sont exécutés de temps en temps, et la machine doit être prête tout le temps. De plus, l'environnement CI est inclus avec toutes les dépendances.
Il n'est pas possible d'exécuter des tests sur deux branches en même temps . Cela découle du paragraphe précédent: comme nous avons un seul environnement, nous ne pouvons tout simplement pas les exécuter en parallèle.
Il n'est pas possible de tester le démarrage, l'arrêt et le redémarrage . J'expliquerai pourquoi cela est nécessaire: toutes nos applications obéissent à la logique du soi-disant
arrêt gracieux , c'est-à-dire que lorsque nous obtenons SIGTERM, nous n'arrêtons pas le processus au milieu, mais interceptons ce signal et comprenons que nous devons désactiver le programme. À ce stade, une certaine logique est activée, par exemple, les requêtes HTTP qui sont «en cours» sont traitées, ou si nous travaillons avec Kafka, nous validons tous les offs - en d'autres termes, nous effectuons certaines actions afin de pouvoir terminer le travail en toute sécurité, et puis, quand tout est fait, éteignez.
Cette logique n'est pas toujours simple, et vous ne pouvez la tester avec un tel schéma que manuellement, car à partir des tests nous ne contrôlons pas le cycle de vie de l'application. Il s'avère que TeamCity a en quelque sorte déployé quelque chose via Chef, alors que les tests sont à un stade différent et ne savent pas comment l'application est déployée.
Le prochain
inconvénient est qu'il est très
difficile de configurer tout cela localement . Autrement dit, il existe de nombreuses dépendances, elles ont leurs propres configurations, elles doivent être générées sur la machine locale. L'application elle-même possède également son propre fichier de configuration, dans lequel il existe de nombreuses valeurs. Les tests eux-mêmes ont une configuration qui doit être mise en correspondance avec la configuration de l'application, et il peut également y avoir plus d'une valeur de configuration. Il semble que tout cela ne semble pas si effrayant, comme «aller réparer les configurations à trois endroits», mais en réalité, cela peut prendre des heures aux nouveaux employés pour le faire.
Docker GitLab CI +
Au fil du temps, ce schéma s'est transformé en un autre:
GitLab CI et
Docker . Cela ne s'est pas produit parce que le schéma précédent n'était pas idéal, mais parce que l'entreprise a légèrement changé de cap en termes d'organisation administrative.
Auparavant, chaque équipe, et nous en avons beaucoup, comme nous le voulions ou comme nous le pouvions, et déployait son travail. Par exemple, nous avions TeamCity, Chef et d'autres équipes pouvaient utiliser Jenkins ou Ansible.
Nous nous dirigeons maintenant vers le cloud local et Kubernetes, et il existe une équipe distincte qui gère tout cela, à la fois GitLab CI et Kubernetes. D'autres équipes l'utilisent simplement comme un service. C'est beaucoup plus pratique car vous n'avez pas besoin d'administrer tout cela manuellement.
En utilisant Kubernetes, nous avons déployé le schéma suivant:

- Au lieu de TeamCity, Gitlab CI est maintenant utilisé.
- GitLab CI crée une image Docker et la déploie sur Kubernetes. La configuration est désormais stockée directement dans le référentiel, et non séparément dans Chef, donc pour le déploiement, vous n'avez pas besoin de travailler avec un service de configuration tiers.
- Les dépendances sont soulevées à l'avance, également à Kubernetes.
- Ensuite, GitLab CI lance SBT et teste dans une étape distincte.
Tout est assez similaire au schéma précédent et ne diffère pas fondamentalement de celui-ci, c'est-à-dire que même les avantages et les inconvénients seront exactement les mêmes, mais Docker apparaît.
Avec docker, vous pouvez faire différentes choses plus amusantes et l'une d'entre elles est la composition de docker.
Docker-compose
Il s'agit d'une sorte de "superposition" sur Docker, qui vous permet d'exécuter plusieurs images de docker en une seule entité.
Un bon exemple où docker-compose aide vraiment est Kafka. Elle a besoin de ZooKeeper pour fonctionner. Si vous soulevez Kafka et ZooKeeper sans composition de docker, vous devez soulever séparément ZooKeeper dans le docker, séparément - Kafka, et garder ces deux conteneurs de docker cohérents. Ce n'est pas très pratique, et docker-compose vous permet de décrire les deux conteneurs dans un seul fichier docker-compose.yml et d'utiliser la simple commande
docker-compose run Kafka augmenter Kafka et ZooKeeper.
Vous pouvez créer des tests d'intégration sur docker-compose. Voyons à quoi cela ressemblera.

- Encore une fois, poussez tout dans GitLab.
- GitLab CI lance docker-compose.
- Dans docker-compose, l'application monte, toutes les dépendances et SBT montent, et le SBT conduit les tests pour cette application - tout se passe à l'intérieur de docker-compose.
Grâce à ce schéma, il n'est pas nécessaire de conserver un environnement et des dépendances séparés, car tout va directement au runner GitLab CI, où doivent simplement se trouver docker et docker-compose. Au démarrage, il va pomper les images nécessaires et les exécuter.
De plus, vous pouvez tester différentes branches en même temps car tout se passe sur le coureur.
Il
est désormais
plus facile de configurer l' environnement
localement , mais vous devez toujours coordonner plusieurs endroits. Le fait est que maintenant, lorsque nous faisons la configuration locale, nous n'avons pas besoin de tout mettre sur la machine locale, tout est écrit dans le fichier docker-compose.yml. Ainsi, vous devez configurer à deux endroits différents - c'est docker-compose.yml et la configuration de nos tests.
En ce qui concerne les inconvénients,
il est toujours impossible de tester le démarrage, l'arrêt et le redémarrage , car à partir du SBT, à partir des tests, nous ne contrôlons pas le cycle de vie de l'application. Il est exécuté par docker-compose, il exécute SBT et les tests sont exécutés à l'intérieur de SBT. Ainsi, il n'y a pas de gestion complète du cycle de vie de l'application. Il y a aussi des difficultés avec le lancement, dont je voudrais parler davantage.
docker-compose 2
À l'époque de docker-compose 2, docker-compose.yml, le fichier ressemblait à ceci:
version: '2.1' services: web: build: . depends_on: db: condition: service_healthy redis: condition: service_started redis: image: redis db: image: db healthcheck: test: "some test here"
Les services sont enregistrés ici, c'est-à-dire ce que nous allons lever dans le cadre de ce docker-compose. Dans ce cas, je viens de prendre un exemple de la documentation docker-compose. Il existe trois services: web, redis et db (base de données).
Le Web est notre application, et redis et db sont des dépendances.
Il y a un élément dans le bloc Web appelé
depends_on . Cela suggère que l'application Web dépend de certains autres conteneurs et est décrite ci-dessous sur laquelle: à partir de la base de données et de redis.
Il existe également une clause
condition . Pour redis, il s'agit de
service_started , ce qui signifie que jusqu'au démarrage de redis, le conteneur n'essaiera pas de démarrer l'application Web.
Quant à la base de données, son état est
service_healthy , et le bilan de santé est décrit ci-dessous. Autrement dit, nous devons non seulement lancer le conteneur Docker, mais également exécuter un certain contrôle de santé. Il peut s'agir de n'importe quelle logique personnalisée.
Par exemple, nous utilisons PostgreSQL, qui utilise l'extension PostGIS, et il a besoin d'un certain temps pour s'initialiser. Lorsque nous lançons le conteneur Docker, nous ne pouvons pas travailler immédiatement avec l'extension postgis - nous devons attendre que l'extension s'initialise. Par conséquent, nous
SELECT PostGIS_Version(); simplement
SELECT PostGIS_Version(); requêtes
SELECT PostGIS_Version(); à
SELECT PostGIS_Version(); . Jusqu'à ce que l'extension soit initialisée, la requête générera une erreur et lorsque l'extension sera initialisée, elle commencera à renvoyer la version. C'est très pratique et logique -
nous allons d'abord augmenter toutes les dépendances, puis l'application .
docker-compose 3
Lorsque docker-compose 3 est sorti, nous avons commencé à l'utiliser.
Mais dans la documentation, un élément est apparu lors de la modification de la logique depend_on. Les développeurs de dockers ont décidé qu'une description du graphique de dépendance était suffisante. Cela signifie que lorsque vous lancez la commande
docker-compose run web , l'application elle-même et la base de données dont elle dépend démarrent simultanément.

Le paragraphe suivant de la documentation indique que depend_on n'est plus une condition.
Ainsi, si vous souhaitez toujours obtenir la fonctionnalité utilisée dans la deuxième version, vous devrez tout prendre en main.
La page
Contrôle de la commande de démarrage propose plusieurs solutions. La première option consiste à utiliser
wait-for-it.sh .
Maintenant, docker-compose.yml est un peu différent:
version: '3' services: web: build: . depends_on: [ db, redis ] redis: image: redis command: [ "./wait-for-it.sh", ... ] db: image: redis command: [ "./wait-for-db.sh", ... ]
depends_on est juste un tableau, il n'y a aucune condition.
Dans nos dépendances, nous redéfinissons la commande, c'est-à-dire que dans docker-compose, vous pouvez attacher une commande avec laquelle le conteneur docker démarre.
Là, nous devrions écrire wait-for-it.sh, et autre chose. Au lieu des trois points dans l'exemple ci-dessus, nous devons écrire ce que nous devons attendre, ainsi que la commande d'origine qui lance le conteneur Docker.
Pour ce faire, vous devez trouver le fichier docker, copier la commande pour redis à partir de là et le coller, il en va de même pour la base de données. Un énorme inconvénient est que l'
abstraction tombe en panne - je ne veux pas savoir quelle commande lance le conteneur Docker. Ces commandes peuvent être non triviales, assez complexes, mais je ne veux pas déranger, je veux juste entrer dans la
docker run et c'est tout.
Personnellement, je n'aime pas vraiment cette solution, mais nous avions quelques services qui fonctionnent comme ça.
Script au-dessus de docker-compose
Puis j'ai décidé que le moment était venu pour la "
construction de vélos", et j'ai eu
docker-compose-run.sh :
version: '3' services: postgres: ... my_service: depends_on: [ postgres ] ... sbt: depends_on: [ my_service ] ...
Permettez-moi de vous donner un exemple semi-réaliste: il y a postgres dans docker-compose.yml, il y a mon_service application, qui dépend de postgres, et SBT, dans lequel les tests sont exécutés et qui dépend de mon service.
J'exécute le programme non pas via
docker run , mais via le script docker-compose-run.sh.
Premièrement, cela commence d'abord par la dépendance la plus profonde, dans mon cas c'est postgres. Le script démarre la dépendance en mode "démon", c'est-à-dire qu'il ne bloque pas le terminal:
docker-compose up -d postgres
J'attends ensuite que la condition soit satisfaite par la fonction wait_until. C'est presque la même chose que wait-for-it.sh, seulement, pour ainsi dire, dans un style impératif. Pendant l'initialisation de PostGIS, le terminal est bloqué, c'est-à-dire que le programme attend également, et s'il n'attend pas, une erreur est générée et les tests cessent de fonctionner.
wait_until 10 2 docker-compose exec -T postgres psql
Lorsque PostGIS est initialisé, passez à l'étape suivante et faites de même avec le service. Pour lui, le test est un peu plus simple: le port 80 doit être lié.
docker-compose up -d my_service wait_until 10 2 docker-compose exec -T \ my_service sh -c "netstat -ntlp | grep 80 || exit 1"
La dernière étape consiste à exécuter SBT via la commande run, dans laquelle les tests sont exécutés.
docker-compose run sbt down $?
Ainsi, tout est relevé dans le bon ordre, mais manuellement.
À la fin, la fonction
down est appelée, qui accepte le résultat de la commande précédente. Si c'est "0", alors les tests ont réussi et nous désactivons simplement docker-compose; sinon, nous «crachons» d'abord les journaux pour comprendre ce qui n'a pas fonctionné, puis nous désactivons la composition par docker.
function down { echo "Exiting with code $1" if [[ $1 -eq 0 ]]; then docker-compose down exit $1 else docker-compose logs -t postgres my_service docker-compose down exit $1 fi }
Un tel schéma fonctionne, mais ne s'adapte pas bien. Chaque service devra décrire son docker-compose-run.sh avec sa propre logique. De plus, la configuration de lancement s'étend entre docker-compose-run.sh et docker-compose.yml. Eh bien, en général, il semble que nous n'utilisions pas de composition de docker, mais que nous ayons des problèmes avec ses lacunes.
Exécuter Docker à partir du code
Lorsque le schéma précédent a été créé, j'ai pensé: si j'ai déjà tout dans le docker, alors pourquoi ne pas l'exécuter à partir du code. J'ai commencé à chercher une solution et j'ai trouvé plusieurs options.
La première option consiste à simplement
utiliser le client docker . Il existe deux principaux clients dockers dans le monde JVM:
docker-java et
spotify docker-client .
Le client Docker vous permet d'exécuter des commandes Docker directement à partir du code à l'aide de l'API. Autrement dit, au lieu de concaténer des chaînes pour créer des commandes comme
`docker run ...` , vous pouvez simplement former une telle commande dans le code et l'exécuter. C'est beaucoup plus pratique.
Cette méthode fonctionne bien et, bien sûr, ils peuvent tout faire, cependant, c'est un niveau très bas. Je devrais créer mon propre analogique de composition de docker, ce qui est une très grosse tâche.
L'option suivante est la
bibliothèque docker-it-scala , qui encapsule ces deux clients et vous permet de choisir le backend à utiliser. Elle peut gérer les conteneurs dont vous avez besoin.
Mais l'inconvénient de cette bibliothèque est qu'elle n'a pas d'API très flexible et qu'il n'y a pas de contrôle du cycle de vie.
Je n'aimais pas non plus cette option, j'ai continué ma recherche et trouvé des
Testcontainers . Je voudrais vous en dire plus à ce sujet.
Conteneurs d'essai
Il s'agit d'une sorte de bibliothèque java pour lancer et tester des conteneurs Docker. Il y a une façade Scala, testcontainers-scala. Hors de la boîte, il existe un certain nombre de services populaires, par exemple, PostgreSQL, MySQL, Nginx, Kafka, Selenium. Vous pouvez exécuter n'importe quel autre conteneur. La bibliothèque possède une API assez simple et flexible, sur laquelle je m'attarderai plus en détail.
Conteneurs prédéfinis
Alors, comment travailler avec des conteneurs prédéfinis, qui sont dans la bibliothèque: en fait, tout est assez simple, car les conteneurs sont représentés comme des objets:
val pgContainer: PostgreSQLContainer = PostgreSQLContainer("postgres:9.6") pgContainer.start() val pgUrl: String = pgContainer.jdbcUrl val pgPort: Int = pgContainer.mappedPort(5432) pgContainer.stop()
Dans ce cas, nous créons
PostgreSQLContainer , nous pouvons le démarrer et commencer à travailler avec. Ensuite, nous obtenons
jbdcUrl , avec lequel vous pouvez vous connecter à PostgreSQL. Après cela, nous obtenons
mappedPort .
Cela signifie que PostgreSQL sort du port docker 5432, et Testcontainers voit ce port et l'attribue automatiquement à un port aléatoire. Autrement dit, d'après les tests que nous voyons, par exemple, 32422. L'affectation se produit automatiquement.
Conteneur personnalisé
La vue suivante, le soi-disant conteneur personnalisé, est également assez simple:
class GenericContainer( imageName: String, exposedPorts: Seq[Int] = Seq(), env: Map[String, String] = Map(), command: Seq[String] = Seq(), classpathResourceMapping: Seq[(String, String, BindMode)] = Seq(), waitStrategy: Option[WaitStrategy] = None ) ...
Il existe un
GenericContainer dont vous devez hériter et remplacer un certain nombre de champs. Assurez-vous de définir uniquement
imageName - c'est le nom du conteneur que nous voulons créer.
Vous pouvez définir les ports
exposedPorts : ces ports que le conteneur dépassera. Dans env, vous pouvez définir des variables d'environnement; vous pouvez également définir la
command à exécuter.
classpathResourceMapping vous permet de jeter des ressources du classpath dans le conteneur Docker. C'est très pratique, par exemple, si la configuration de l'application se trouve directement dans les ressources de test. Vous mappez simplement à l'intérieur et l'application à l'intérieur de docker a accès à cette configuration.
waitStrategy est une chose très pratique qui manquait dans docker-compose 3, en fait c'est HealthCheck. Il existe plusieurs
waitStrategy prédéfinies, par exemple, vous pouvez attendre jusqu'à ce qu'une liaison de port se produise, ou une méthode http spécifique renverra 200. Mais vous pouvez écrire n'importe lequel de vos HealthCheck.
Puisque vous écrivez HealthCheck simplement dans votre code, vous pouvez utiliser, d'une part, une langue normale, pas bash, et, d'autre part, toutes les bibliothèques disponibles à partir de votre code: si vous voulez faire une HealthCheck personnalisée dans Cassandra - prenez le pilote et écrivez tout HealthCheck.
Exécution de tests
Et maintenant un peu sur la façon d'exécuter des tests:
class PostgresqlSpec extends FlatSpec with ForAllTestContainer { override val container = PostgreSQLContainer() "PostgreSQL container" should "be started" in { Class.forName(container.driverClassName) val connection = DriverManager .getConnection(container.jdbcUrl, container.username, container.password) // test some stuff } }
Je vais parler de
ScalaTest , la norme de facto pour les tests dans le monde Scala.
Par exemple, nous voulons écrire des tests pour Postgres. Créez un test
PostgresqlSpec et
ForAllTestContainer de
ForAllTestContainer . Il s'agit d'un trait fourni par la bibliothèque. Il démarrera les conteneurs nécessaires avant tous les tests et les arrêtera après tous les tests. Ou vous pouvez utiliser
ForeachTestContainer , puis les conteneurs commencent avant chaque test et s'arrêtent après chacun d'eux.
Ensuite, vous devez redéfinir le conteneur. Cela peut être fait en remplaçant la propriété du
container . Dans mon cas, j'utilise
PostgreSQLContainer .
Ensuite, nous écrivons des tests. Dans l'exemple, je crée une connexion, prends jdbcUrl, nom d'utilisateur, mot de passe, écris des tests spécifiques, envoie des requêtes.
En règle générale, les tests d'intégration nécessitent plusieurs conteneurs. Je peux les créer en utilisant
MultipleContainers :
val pgContainer = PostgreSQLContainer() val myContainer = MyContainer() override val container = MultipleContainers(pgContainer, myContainer)
Autrement dit, je crée des conteneurs, je les ajoute à
MultipleContainers et je les utilise comme
container .
Le schéma d'exécution des tests avec Testcontainers est le suivant:

- Poussez le code dans GitLa.
- Le coureur GitLab CI lance SBT.
- SBT exécute des tests. A l'intérieur des tests, notre application et ses dépendances sont lancées.
Les avantages de ce schéma:
- Pas besoin de garder un environnement et des dépendances séparés, tout se passe sur le runner.
- Vous pouvez tester différentes branches en même temps.
- Vous pouvez tester le démarrage, l'arrêt et le redémarrage, car nous pouvons contrôler le cycle de vie de l'application (tout commence directement dans le code de test).
- Il existe des bilans de santé flexibles qui faisaient cruellement défaut.
- Il n'y a pas de fichiers * .sh dans le référentiel, vous pouvez configurer les tests dans l'application aussi facilement que vous le souhaitez.
- Grâce au mappage classpathResource, vous pouvez utiliser la même configuration avec les tests et l'application.
- Vous pouvez configurer des tests à partir du code.
- Tout cela s'exécute aussi facilement à la fois dans CI et localement, car ce ne sont que des tests qui ressemblent et s'exécutent comme des tests unitaires, seul tout monte dans le conteneur Docker.
Il s'avère que tout est étrangement lisse et bon, mais ce n'est qu'à première vue, en fait, nous avons rencontré un certain nombre de problèmes.
Conteneurs dépendants
Le premier problème que nous avons rencontré concerne
les conteneurs dépendants . Disons qu'il existe une sorte de test:
class MySpec extends FlatSpec with ForAllTestContainer { val pgCont = PostgreSQLContainer() val appCont = AppContainer(pgCont.jdbcUrl, pgCont.username, pgCont.password) override val container = MultipleContainers(appCont, pgCont) // tests here }
Il exécute postgres et AppContainer. L'appContainer de postgres reçoit jdbcUrl, le nom d'utilisateur et le mot de passe pour la connexion. Ensuite, MultipleContainers est créé et le test lui-même est décrit.
J'exécute le programme et je vois une erreur:
Exception encountered when invoking run on a nested suite - Mapped port can only be obtained after the container is started
Le fait est que le port attribué ne peut pas être pris avant le démarrage du conteneur. Pourquoi cela se produit-il?
Le fait est que
ForAllTestContainer ou
ForEachTestContainer démarrent les conteneurs immédiatement avant les tests, et non au moment où je crée des instances de conteneur. Il s'avère qu'au moment où je crée l'AppContainer, je n'ai pas encore
PostgreSQLContainer activé, ce qui signifie que je ne peux pas obtenir le port attribué à partir de celui-ci, et il est nécessaire de former
jdbcUrl .
Le problème est que l'essence du conteneur est modifiable: il a plusieurs états. Par exemple, il peut être désactivé et réactivé.
Comment résoudre ce problème? La première méthode que j'appellerais «paresseuse».
class MyTest extends FreeSpec with BeforeAndAfterAll { lazy val pgCont = PostgreSQLContainer() lazy val appCont = AppContainer(pgCont.jdbcUrl, pgCont.username, pgCont.password) override def beforeAll(): Unit = { super.beforeAll() pgCont.start() appCont.start() } override def afterAll(): Unit = { super.afterAll() appCont.stop() pgCont.stop() } // tests here }
L'idée principale est de créer des conteneurs en utilisant
lazy lazy . Ensuite, ils ne seront pas initialisés immédiatement dans le constructeur de test, mais attendront le premier appel. Nous allons initialiser dans les
afterAll beforeAll et
afterAll , que le
BeforeAndAfterAll BeforeAndAfterAll de ScalaTest fournit. Dans
beforeAll conteneurs démarrent et dans
afterAll , ils s'éteignent. Comme les conteneurs sont déclarés paresseux, au moment où la méthode de démarrage est appelée dans beforeAll, ils seront créés, initialisés et démarrés.
Cependant, une erreur se produit quand même que je ne peux pas rejoindre localhost: 32787:
org.postgresql.util.PSQLException: Connection to localhost:32787 refused. Check that the hostname and port are correct and that the postmaster is accepting TCP/IP connections.
Il semblerait que nous ayons utilisé jdbcUrl, pourquoi localhost apparaît-il? Voyons comment fonctionne jdbcUrl:
@Override public String getJdbcUrl() { return "jdbc:postgresql://" + getContainerIpAddress() + ":" + getMappedPort(POSTGRESQL_PORT) + "/" + databaseName; }
Il s'agit simplement d'une concaténation de chaînes. Tout est clair avec des constantes, elles ne peuvent pas casser.
getMappedPort devrait également fonctionner, car nous l'avons déjà corrigé.
databaseName est une constante codée en dur. Mais avec
getContainerIpAddress plus intéressant. Par son nom, nous pouvons supposer qu'il doit renvoyer l'adresse IP du conteneur. Mais si vous exécutez ce code, il s'avère qu'il renvoie toujours localhost. Il s'est avéré que cette méthode n'est pas destinée à l'interaction entre conteneurs:
getContainerIpAddress fournit une interaction à partir de tests à l'intérieur du conteneur .
Recommandation du développeur Testcontainers:
créer un réseau personnalisé pour la communication entre conteneurs . Docker-compose fonctionne comme ceci: il crée un réseau et résout tout par lui-même.
Vous devez donc créer un réseau.
class MyTest extends FreeSpec with BeforeAndAfterAll { val network: Network = Network.newNetwork() val dbName = "some_db" val pgContainerAlias = "postgres" val jdbcUrl = s"jdbc:postgresql://$pgContainerAlias:5432/$dbName" lazy val pgCont = { val c = PostgreSQLContainer("postgres:9.6") c.container.withNetwork(network) c.container.withNetworkAliases(pgContainerAlias) c.container.withDatabaseName(dbName) c } lazy val appCont = { val c = AppContainer(jdbcUrl, pgCont.username, pgCont.password) c.container.withNetwork(network) c } override def beforeAll(): Unit = { super.beforeAll() pgCont.start() appCont.start() } override def afterAll(): Unit = { super.afterAll() appCont.stop() pgCont.stop() network.close() } // tests here }
Nous devons maintenant configurer manuellement notre jdbcUrl. Nous devons également activer nos conteneurs dans le réseau et définir l'alias du PostgreSQLContainer afin qu'il soit accessible au sein du réseau par un nom de domaine. En fin de compte, vous devez vous rappeler de «tuer» le réseau.
Enfin, un tel programme fonctionnera.
Dans les versions récentes de testcontainers-scala, l'initialisation des conteneurs paresseux est prise en charge immédiatement:
class MyTest extends FreeSpec with ForAllTestContainer with BeforeAndAfterAll { val network: Network = Network.newNetwork() val dbName = "some_db" val pgContainerAlias = "postgres" val jdbcUrl = s"jdbc:postgresql://$pgContainerAlias:5432/$dbName" lazy val pgCont = { val c = PostgreSQLContainer("postgres:9.6") c.container.withNetwork(network) c.container.withNetworkAliases(pgContainerAlias) c.container.withDatabaseName(dbName) c } lazy val appCont = { val c = AppContainer(jdbcUrl, pgCont.username, pgCont.password) c.container.withNetwork(network) c } override val container = MultipleContainers(pgCont, appCont) override def afterAll(): Unit = { super.afterAll() network.close() } // tests here }
Vous pouvez à nouveau utiliser
ForAllTestContainer et
MultipleContainers . Dans
beforeAll n'avez plus besoin de
beforeAll manuellement
beforeAll ordre de départ. Maintenant,
MultipleContainers peut travailler avec lazy lazy et les exécuter dans le bon ordre, et ne fait pas d'initialisation stricte immédiatement lors de la création. Dans le même temps, les manipulations avec le réseau personnalisé et jdbcUrl doivent également être effectuées manuellement.
Se moquer
Cependant, il y a encore des problèmes. Par exemple moki. Parfois, il n'est pas très pratique de créer une sorte de dépendance dans un conteneur Docker. Nous utilisons Spark JobServer, qui crée des tâches Spark et contrôle leur cycle de vie dans Spark. Nous utilisons deux de ses méthodes: «créer» et «donner un statut».
Pour exécuter Spark JobServer dans Docker. Il faut soulever Spark, et jusqu'à récemment, il n'y avait pas du tout de docker et il fallait l'assembler soi-même. De plus, Spark JobServer utilise PostgreSQL pour stocker les états. Par conséquent, vous devez faire beaucoup de travail difficile lorsque vous n'avez vraiment besoin que de deux méthodes avec une API simple.
Mais vous pouvez jeter un œil à l'implémentation de Spark JobServer et créer une maquette qui se comporte de la même manière, mais qui ne nécessite pas les dépendances de Spark JobServer d'origine.
Cela ressemble à ceci (dans l'exemple, un pseudocode simplifié):
val hostIp = ??? AppContainer(sparkJobServerMockHost = hostIp) val sparkJobServerMock = new SparkJobServerMock() sparkJobServerMock.init(someData) val apiResult = appApi.callMethod() assert(apiResult == someData)
http- API Spark JobServer. - , . , , , mock.
- , . : «» config; , host.
SparkJobServerMock , host-, docker-, , , docker-.
? docker-, , gateway , docker-.
, Testcontainers API. , Testcontainers docker-java-, . «» docker-:
val client: com.github.dockerjava.api.DockerClient = DockerClientFactory .instance .client val networkInfo: com.github.dockerjava.api.model.Network = client .inspectNetworkCmd() .withNetworkId(network.getId) .exec() val hostIp: String = networkInfo .getIpam .getConfig .get(0) .getGateway
-,
DockerClient . Testcontainers
DockerClientFactory . c
inspectNetworkCmd . , info, gateway.
, , .
— . Docker : Windows, Mac, . Linux. , , Linux .
, Testcontainers . , docker-. :
Testcontainers.exposeHostPorts(sparkJobServerMockPort)
,
. docker-.
`host.testcontainers.internal` .
, :
val sparkJobServerMockHost = "host.testcontainers.internal" val sparkJobServerMockPort = 33333 Testcontainers.exposeHostPorts(sparkJobServerPort) AppContainer(sparkJobServerMockHost, sparkJobServerMockPort)
Testcontainers
, , Testcontainers , . Java-, Scala-. :
- . , testcontainers-java JUnit, testcontainers-scala ScalaTest, testcontainers-java . Scala- .
- Scala . . , . , predefined Java-. , .
- API . API, . , . , , .
Résumé
. Docker , , , , network gateway.
Testcontainers — , . API , .
Java-, . — . .
, docker-, .
— , , , . .?, .
— - ?Kubernetes, . end-to-end , , , , .
, , unit-, .
— Kubernetes ?-, , -, , , , Spark Kubernetes ; , .
, , unit-, , , break point , , .
, , , CI , .
, minicube — Mac, . , , , , .
— ? : master? , - , , 2.1, 2.2, ?ImageName, Postgres 9.6.
val pgContainer: PostgreSQLContainer = PostgreSQLContainer("postgres:9.6")
9.6, 10. [ ], .
Image tag — , — , . , latest .
— , ?, CI , GitLab CI , , Branch Name.
— , , , ? - , ? 20- , ?-, , . , , , , , .
- , , full-time , , , .
commit', , , , Android, iOS . . , , , , — .
, , -: - , - . , - .
Vous voulez plus de détails sur les microservices eux-mêmes et pas seulement sur Scala - notre programme ScalaConf a des réponses à diverses questions. Plus intéressés par l'architecture et les interconnexions de ses différentes parties - venez à HighLoad ++ les 7 et 8 novembre.
Tout est si savoureux, et on ne sait pas quoi choisir, alors abonnez-vous à la newsletter dans laquelle nous parlons de rapports et collectons des documents utiles sur le sujet.