Bonjour, Habr!
Je m'appelle Maxim Ponomarenko et je suis développeur chez Sportmaster. J'ai 10 ans d'expérience dans le domaine informatique. Il a commencé sa carrière dans les tests manuels, puis est passé au développement de bases de données. Au cours des 4 dernières années, accumulant les connaissances acquises dans les tests et le développement, je me suis engagé dans l'automatisation des tests au niveau du SGBD.
Je fais partie de l'équipe Sportmaster depuis un peu plus d'un an et je suis engagé dans le développement de tests automatisés sur l'un des grands projets. En avril, les gars de Sportmaster Lab et moi avons parlé lors d'une conférence à Krasnodar, mon rapport s'appelait «Tests unitaires dans le SGBD», et maintenant je veux le partager avec vous. Il y aura beaucoup de texte, j'ai donc décidé de diviser le rapport en deux messages. Dans le premier, nous parlerons des autotests et des tests en général, et dans le second, je m'attarderai sur notre système de tests unitaires et les résultats de son application.

Au début, une petite théorie ennuyeuse. Qu'est-ce qu'un test automatique? Il s'agit de tests effectués par des logiciels, et dans l'informatique moderne, ils sont de plus en plus utilisés dans le développement de logiciels. Cela est dû au fait que les entreprises se développent, leurs systèmes d'information se développent et, par conséquent, la quantité de fonctionnalités à tester augmente. La réalisation de tests manuels devient de plus en plus coûteuse.
J'ai travaillé pour une grande entreprise, dont les sorties sortent tous les deux mois. Dans le même temps, un mois entier a été consacré à une dizaine de testeurs pour vérifier la fonctionnalité avec leurs mains. Grâce à l'introduction de l'automatisation par une petite équipe de développeurs, nous avons pu réduire le temps de test à 2 semaines en un an et demi. Nous avons non seulement augmenté la vitesse des tests, mais également augmenté sa qualité. Les tests automatisés sont exécutés régulièrement et ils complètent toujours le cours complet des tests qui leur sont inhérents, c'est-à-dire que nous excluons le facteur humain.
L'informatique moderne se caractérise par le fait que le développeur peut être tenu non seulement d'écrire du code produit, mais également d'écrire des tests unitaires qui vérifient ce code.
Mais que se passe-t-il si votre système est basé principalement sur la logique du serveur? Il n'y a pas de solution unique et de meilleures pratiques sur le marché. En règle générale, les entreprises résolvent ce problème en créant leur propre système de test auto-écrit. Un tel système de test automatisé propriétaire auto-écrit a été créé sur notre projet, et j'en parlerai dans mon rapport.
Tester la fidélité
Parlons d'abord d'un projet où nous avons déployé un système de test automatisé. Notre projet est le système de fidélité de Sportmaster (au fait, nous en avons déjà parlé dans
cet article ).
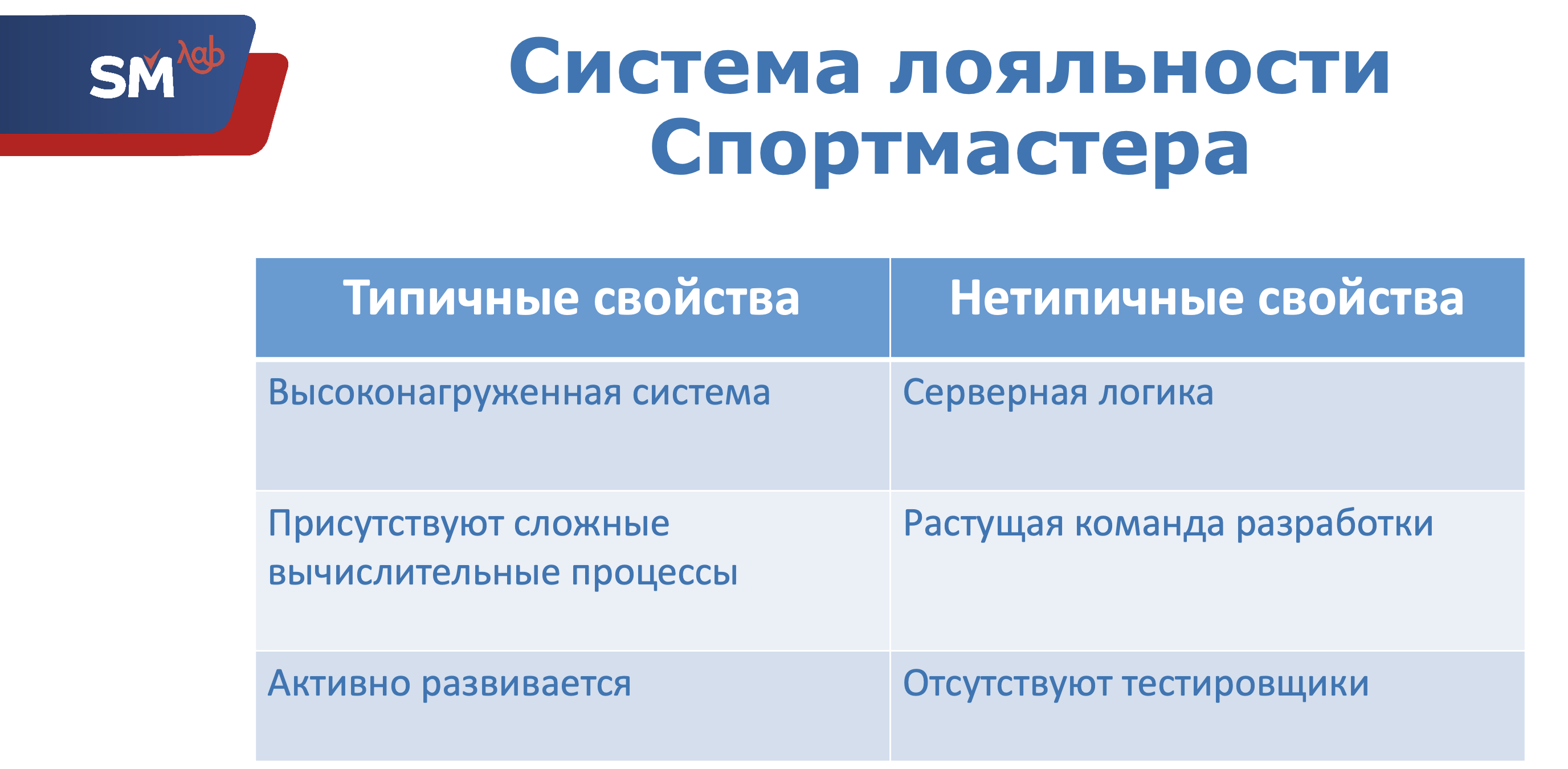
Si votre entreprise est suffisamment grande, votre système de fidélité aura trois propriétés standard:
- Votre système sera lourdement chargé.
- Votre système contiendra des processus informatiques complexes.
- Votre système sera activement développé.
Allons dans l'ordre. Sportmaster possède un grand nombre de magasins qui vendent activement. Naturellement, le système de fidélité est un système très chargé. Et puisque le projet est activement utilisé, nous devons fournir les normes de qualité les plus élevées, car toute erreur dans le logiciel représente beaucoup d'argent, de réputation et d'autres pertes.
Dans le même temps, plus d'une centaine de promotions différentes fonctionnent dans Sportmaster. Les parts sont très différentes: il y en a des matières premières, il y a des horaires au jour de la semaine, il y a des liens avec un magasin particulier, il y a des parts dans le montant du chèque, il y a le nombre de marchandises. En général, pas faible. Les clients ont des bonus, il existe des codes promotionnels qui sont utilisés lors des achats. Tout cela conduit au fait que le calcul de toute commande est une tâche très non triviale.
L'algorithme qui implémente le traitement des commandes est vraiment terrible et compliqué. Et toute modification de cet algorithme est une chose assez risquée. Il semble qu'il y ait eu les changements les plus extérieurs mineurs qui pourraient conduire à des effets plutôt imprévisibles. Mais ce sont précisément ces processus informatiques complexes, d'autant plus que la mise en œuvre de fonctionnalités critiques est le meilleur candidat pour l'automatisation. Vérifier des dizaines de cas du même type avec vos mains prend beaucoup de temps. Et puisque le point d'entrée du processus est inchangé, une fois décrit, vous pouvez rapidement tamponner les tests automatiques et être sûr de la fonctionnalité.
Étant donné que notre système est activement utilisé, l'entreprise voudra de vous quelque chose de nouveau, sera à jour et sera orientée vers le client. Dans notre système de fidélité, les versions sont publiées tous les deux mois. Ainsi, tous les deux mois, nous devons procéder à une régression complète de l'ensemble du système. Dans le même temps, bien sûr, comme dans toute informatique moderne, le développement ne vient pas immédiatement du développeur à la production. Il provient du circuit du développeur, puis passe séquentiellement le banc d'essai, libère, accepte, et alors seulement il est en production. Au moins sur les circuits de test et de libération, nous devons effectuer une régression complète de l'ensemble du système.
Les propriétés décrites sont standard pour presque tous les systèmes de fidélité. Parlons des caractéristiques de notre projet.
Technologiquement, 90% de la logique de notre système de fidélité est basée sur serveur et implémentée sur Oracle. Il existe un client exposé sur Delphi, qui remplit la fonction d'un administrateur AWP. Il existe des services Web exposés pour des applications externes (comme un site Web). Par conséquent, il est très logique que si nous déployons un système de test automatisé, nous le ferons sur Oracle.
Le système de fidélité de Sportmaster existe depuis plus de 7 ans et a été créé par des développeurs uniques ... Le nombre moyen de développeurs sur notre projet au cours de ces 7 années était de 3-4 personnes. Mais au cours de la dernière année, notre équipe s'est considérablement développée et maintenant 10 personnes travaillent sur le projet. Autrement dit, des personnes qui ne sont pas familiarisées avec les tâches, les processus et l'architecture typiques viennent au projet. Et il y a un risque accru d'ignorer les erreurs.
Le projet se caractérise par l'absence de testeurs dédiés en tant qu'unités du personnel. Le test, bien sûr, l'est, mais les analystes sont engagés dans le test, en plus de leurs autres responsabilités principales: communiquer avec les clients commerciaux, les utilisateurs, définir les exigences du système, etc. etc ... Malgré le fait que les tests soient effectués de manière très efficace (cela est particulièrement approprié à mentionner, car l'un des analystes peut attirer l'attention de ce rapport), personne n'a annulé l'efficacité de la spécialisation et de la concentration sur une chose.
Compte tenu de tout ce qui précède, pour améliorer la qualité du produit publié et réduire le temps de développement, l'idée d'automatiser les tests sur le projet semble très logique. Et à différentes étapes de l'existence du système de fidélité, les développeurs individuels ont fait des efforts pour couvrir leur code avec des tests unitaires. C'était généralement un processus assez disparate où chacun utilisait son architecture et ses méthodes. Les tests unitaires étaient courants pour les résultats finaux: des tests ont été développés, utilisés pendant un certain temps, empilés dans un stockage de fichiers versionné, mais à un moment donné, ils ont cessé de démarrer et ont été oubliés. Cela était principalement dû au fait que les tests étaient plus liés à un artiste spécifique qu'à un projet.
UtPLSQL vient à la rescousse

Savez-vous quelque chose sur Stephen Feuerstein?
C'est un gars intelligent qui a consacré une longue partie de sa carrière à travailler avec Oracle et avec PL / SQL, a écrit un assez grand nombre d'ouvrages sur ce sujet. Un de ses livres les plus connus s'appelle: «Oracle PL / SQL. Pour les professionnels. ” C'est Steven qui est le propriétaire du développement de la solution utPLSQL, ou, comme cela signifie, du framework de tests unitaires pour Oracle PL / SQL. La solution utPLSQL a été créée en 2016, mais ils continuent à y travailler activement et à publier de nouvelles versions. Au moment du rapport, la dernière version est datée du 24 mars 2019.
Qu'est-ce que c'est. Il s'agit d'un projet open source distinct. Il pèse quelques mégaoctets, en tenant compte des exemples et de la documentation. Physiquement, il s'agit d'un schéma distinct dans la base de données ORACLE avec un ensemble de packages et de tables pour organiser les tests unitaires. L'installation prend quelques secondes. Une caractéristique distinctive d'utPLSQL est sa facilité d'utilisation.
Globalement, utPLSQL est un mécanisme permettant d'exécuter des tests unitaires, où un test unitaire fait référence à des procédures batch Oracle standard, dont l'organisation suit certaines règles. En plus du lancement, utPLSQL stocke un journal de tous vos tests, et il existe également un système de reporting interne.
Regardons un exemple de la façon dont le code de test unitaire mis en œuvre par cette technique ressemble.

Ainsi, l'écran affiche le code pour la spécification standard d'un package avec des tests unitaires. Quelles sont les exigences requises? Le package doit avoir le préfixe utp_. Toutes les procédures avec des tests doivent avoir exactement le même préfixe. Le package doit contenir deux procédures standard: "utp_setup" et "utp_teardown". La première procédure est appelée en redémarrant chaque test unitaire, la seconde - après le démarrage.
"Utp_setup", en règle générale, prépare notre système à exécuter un test unitaire, par exemple, crée des données de test. "Utp_teardown" - au contraire, tout revient à ses paramètres d'origine et réinitialise les résultats du lancement.
Voici un exemple du test unitaire le plus simple, qui vérifie la normalisation du numéro de téléphone du client saisi à l'aspect standard de notre système de fidélité. Il n'y a pas de normes obligatoires pour la rédaction de procédures avec des tests unitaires. En règle générale, une méthode du système testé est appelée et le résultat renvoyé par cette méthode est comparé à celui de référence. Il est important que la comparaison du résultat de référence et du résultat se fasse via des méthodes utPLSQL standard.
Un test unitaire peut avoir n'importe quel nombre de contrôles. Comme vous pouvez le voir dans l'exemple, nous effectuons quatre appels consécutifs de la méthode testée pour normaliser le numéro de téléphone et après chaque appel, nous évaluons le résultat. Lors du développement d'un test unitaire, il faut tenir compte du fait qu'il existe des contrôles qui n'affectent en aucune façon le système, et après certains, il est nécessaire de revenir à l'état initial du système.
Par exemple, dans le test unitaire présenté, nous formaterons simplement le numéro de téléphone saisi, ce qui n'affecte pas le système de fidélité.
Et si nous écrivons des tests unitaires en utilisant la méthode de création d'un nouveau client, après chaque vérification, un nouveau client sera créé dans le système, ce qui peut affecter le lancement ultérieur du test.

C'est ainsi que s'exécutent les tests unitaires. Il existe deux options de lancement possibles: démarrer tous les tests unitaires à partir d'un package spécifique ou démarrer un test unitaire spécifique dans un package spécifique.

Voici un exemple de système de reporting interne. D'après les résultats du test unitaire, utPLSQL crée un petit rapport. On y voit le résultat de chaque test spécifique et le résultat global du test unitaire.
6 règles d'autotests
Avant de commencer à créer un nouveau système pour les tests automatisés d'un système de fidélité, avec la direction, nous avons déterminé les principes que nos futurs tests automatiques devraient respecter.

- Les tests automatiques doivent être efficaces et bénéfiques. Nous avons de merveilleux développeurs, dont je dois dire, car l'un d'entre eux verra probablement ce rapport, et ils écrivent du code merveilleux. Mais même leur merveilleux code n'est pas parfait et contenu, contient et contiendra des erreurs. Des autotests sont nécessaires pour trouver ces erreurs. Si ce n'est pas le cas, alors soit nous écrivons de mauvais auto-tests, soit nous arrivons à une zone morte, qui, en principe, n'est pas finalisée. Dans les deux cas, nous faisons quelque chose de mal et notre approche n'a tout simplement aucun sens.
- Des tests automatiques doivent être utilisés. Cela n'a aucun sens de passer beaucoup de temps et d'efforts à écrire un logiciel, à ajouter son référentiel et à l'oublier. Les tests doivent être exécutés et exécutés aussi régulièrement que possible.
- Les autotests devraient fonctionner de manière stable. Quelle que soit l'heure de la journée, le stand de lancement ou d'autres paramètres système, l'exécution des tests devrait conduire au même résultat. En règle générale, cela est assuré par le fait que les autotests fonctionnent avec des données de test spéciales avec des paramètres système fixes.
- Les tests automatiques devraient fonctionner à une vitesse acceptable pour votre projet. Ce temps est déterminé individuellement pour chaque système. Quelqu'un peut se permettre de travailler toute la journée et quelqu'un s'intègre de manière critique dans les secondes. Quelles normes de vitesse nous avons atteintes dans notre projet, je le dirai un peu plus tard.
- Le développement des autotests doit être flexible. Il n'est pas souhaitable de refuser de tester une fonctionnalité simplement parce que nous ne l'avons pas encore fait ou pour d'autres condamnations. utPLSQL n'impose aucune restriction de développement et Oracle, en principe, vous permet d'implémenter une variété de choses. La plupart des tâches ont une solution, la seule question est le temps et les efforts.
- Déployabilité. Nous avons plusieurs stands où vous devez effectuer des tests. Sur chacun des stands, un vidage des données peut être mis à jour à tout moment. Il est nécessaire de conduire un projet avec des autotests de manière à pouvoir effectuer sans effort son installation complète ou partielle.
Et dans le deuxième article dans quelques jours, je vous dirai ce que nous avons fait et quels résultats ont été obtenus.