Le thème Captcha n'est pas nouveau, y compris pour Habr. Cependant, les algorithmes captcha changent, tout comme les algorithmes pour les résoudre. Par conséquent, il est proposé de se souvenir de l'ancien et d'utiliser la version suivante de captcha:

En cours de route, apprenez le travail d'un simple réseau de neurones en pratique et améliorez également ses résultats.
Faites immédiatement une réserve que nous ne nous plongerons pas dans les réflexions sur le fonctionnement du neurone et que faire de tout cela, l'article ne prétend pas être scientifique, mais ne fournit qu'un petit tutoriel.
Pour danser du poêle. Au lieu de rejoindre
Peut-être que les mots de quelqu'un seront répétés, mais la plupart des livres sur le Deep Learning commencent vraiment par le fait que le lecteur se voit proposer des données pré-préparées avec lesquelles il commence à travailler. MNIST - 60 000 chiffres manuscrits, CIFAR-10, etc. Après avoir lu, une personne sort préparée ... pour ces ensembles de données. Il est complètement difficile de savoir comment utiliser vos données et, surtout, comment améliorer quelque chose lors de la construction de votre propre réseau de neurones.
C'est pourquoi l'article sur
pyimagesearch.com sur la façon de travailler avec vos propres données, ainsi que leur
traduction, s'est
avéré très pratique.
Mais comme on dit, le radis raifort n'est pas plus doux: même avec la traduction de l'article mâché sur les keras, il y a de nombreux angles morts. Encore une fois, un ensemble de données pré-préparé est offert, uniquement avec les chats, les chiens et les pandas. Vous devez combler les vides vous-même.
Cependant, cet article et ce code seront pris comme base.
Nous collectons des données sur captcha
Il n'y a rien de nouveau ici. Nous avons besoin d'échantillons de captcha, comme le réseau apprendra d'eux sous notre direction. Vous pouvez exploiter le captcha vous-même, ou vous pouvez en prendre un peu ici -
29 000 captchas . Vous devez maintenant couper les chiffres de chaque captcha. Il n'est pas nécessaire de couper tous les 29 000 captcha, d'autant plus que 1 captcha donne 5 chiffres. 500 captcha seront plus que suffisants.
Comment couper? C'est possible dans Photoshop, mais il vaut mieux avoir un meilleur couteau.
Voici donc le code du couteau python -
téléchargement . (pour Windows. Créez d'abord les dossiers C: \ 1 \ test et C: \ 1 \ test-out).
La sortie sera un vidage de nombres de 1 à 9 (il n'y a pas de zéros dans le captcha).
Ensuite, vous devez analyser ce blocage des numéros dans des dossiers de 1 à 9 et les placer dans chaque dossier par le numéro correspondant. Occupation moyenne. Mais en une journée, vous pouvez distinguer jusqu'à 1000 chiffres.
Si, lors du choix d'un numéro, vous ne savez pas lequel des numéros, il est préférable de supprimer cet échantillon. Et ça va si les chiffres sont bruyants ou entrent incomplètement dans le "cadre":


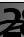
Vous devez collecter 200 échantillons de chaque chiffre dans chaque dossier. Vous pouvez déléguer ce travail à des services tiers, mais il est préférable de tout faire vous-même afin de ne pas chercher plus tard les numéros incorrectement appariés.
Réseau de neurones. Test
Tyat, tyat, nos filets ont traîné le mortAvant de commencer à travailler avec vos propres données, il est préférable de parcourir l'article ci-dessus et d'exécuter le code pour comprendre que tous les composants (keras, tensorflow, etc.) sont installés et fonctionnent correctement.
Nous utiliserons un réseau simple dont la syntaxe de lancement est issue de la ligne de commande (!):
python train_simple_nn.py --dataset animals --model output/simple_nn.model --label-bin output/simple_nn_lb.pickle --plot output/simple_nn_plot.png
* Tensorflow peut écrire lorsque vous travaillez sur des erreurs dans ses propres fichiers et méthodes obsolètes, vous pouvez les corriger à la main ou simplement les ignorer.
L'essentiel est qu'après l'élaboration du programme, deux fichiers apparaissent dans le dossier de projet du projet: simple_nn_lb.pickle et simple_nn.model, et l'image de l'animal avec un pourcentage d'inscription et de reconnaissance s'affiche, par exemple:

Réseau de neurones - propres données
Maintenant que le test d'intégrité du réseau a été vérifié, vous pouvez connecter vos propres données et commencer à entraîner le réseau.
Mettez dans les dossiers du dossier dat avec des numéros contenant des échantillons sélectionnés pour chaque chiffre.
Pour plus de commodité, nous placerons le dossier dat dans le dossier du projet (par exemple, à côté du dossier animaux).
Maintenant, la syntaxe pour démarrer l'apprentissage en réseau sera:
python train_simple_nn.py --dataset dat --model output/simple_nn.model --label-bin output/simple_nn_lb.pickle --plot output/simple_nn_plot.png
Cependant, il est trop tôt pour commencer l'entraînement.
Vous devez corriger le fichier train_simple_nn.py.
1. À la toute fin du dossier:
Cela ajoutera des informations.
2.
image = cv2.resize(image, (32, 32)).flatten()
changer pour
image = cv2.resize(image, (16, 37)).flatten()
Ici, nous redimensionnons l'image d'entrée. Pourquoi exactement cette taille? Parce que la plupart des chiffres hachés sont de cette taille ou sont réduits à elle. Si vous redimensionnez à 32x32 pixels, l'image sera déformée. Oui et pourquoi?
De plus, nous poussons ce changement à essayer:
try: image = cv2.resize(image, (16, 37)).flatten() except: continue
Parce que le programme ne peut pas digérer certaines images et problèmes Aucun, ils sont donc ignorés.
3. Maintenant, la chose la plus importante. Où il y a un commentaire dans le code
définir l'architecture 3072-1024-512-3 avec Keras
L'architecture de réseau dans l'article est définie comme 3072-1024-512-3. Cela signifie que le réseau reçoit 3072 (32 pixels * 32 pixels * 3) à l'entrée, puis la couche 1024, la couche 512 et à la sortie 3 options - un chat, un chien ou un panda.
Dans notre cas, l'entrée est 1776 (16 pixels * 37 pixels * 3), puis la couche 1024, la couche 512, à la sortie de 9 variantes de nombres.
Par conséquent, notre code:
model.add(Dense(1024, input_shape=(1776,), activation="sigmoid"))model.add(Dense(512, activation="sigmoid"))
* 9 sorties n'ont pas besoin d'être indiquées en plus, car le programme lui-même détermine le nombre de sorties par le nombre de dossiers dans l'ensemble de données.
Nous lançons
python train_simple_nn.py --dataset dat --model output/simple_nn.model --label-bin output/simple_nn_lb.pickle --plot output/simple_nn_plot.png
Étant donné que les images avec des nombres sont petites, le réseau apprend très rapidement (5-10 minutes) même sur un matériel faible, en utilisant uniquement le CPU.
Après avoir exécuté le programme dans la ligne de commande, voyez les résultats:
Cela signifie que sur l'ensemble d'entraînement, la fidélité a été atteinte - 82,19%, sur le contrôle - 75,6% et sur le test - 75,59%.
Nous devons nous concentrer sur ce dernier indicateur pour la plupart. Pourquoi les autres sont également importants sera expliqué plus loin.
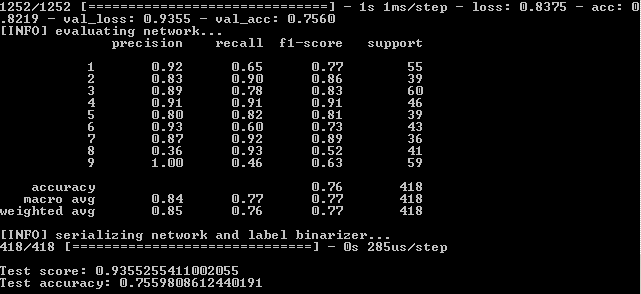
Voyons également la partie graphique du travail du réseau neuronal. Il se trouve dans le dossier de sortie du projet simple_nn_plot.png:
Plus rapide, plus haut, plus fort. Amélioration des résultats
Un peu sur la mise en place d'un réseau de neurones, voir
ici .
L'option authentique est la suivante.
Ajoutez des époques.
Dans le code on change
EPOCHS = 75
sur
EPOCHS = 200
Augmentez le "nombre de fois" que le réseau subira une formation.
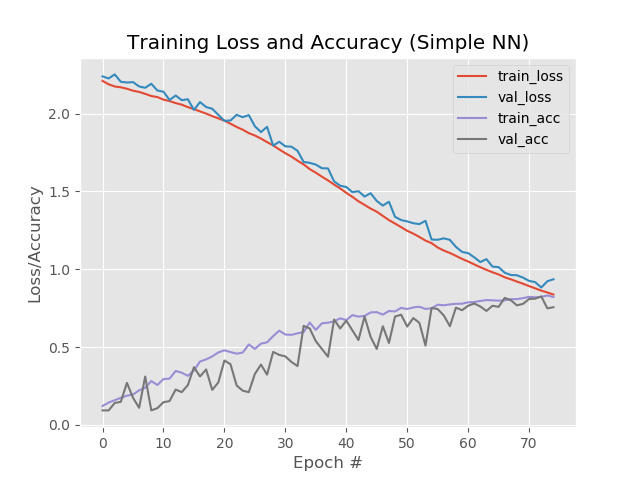
Résultat:
Ainsi, 93,5%, 92,6%, 92,6%.
En images:
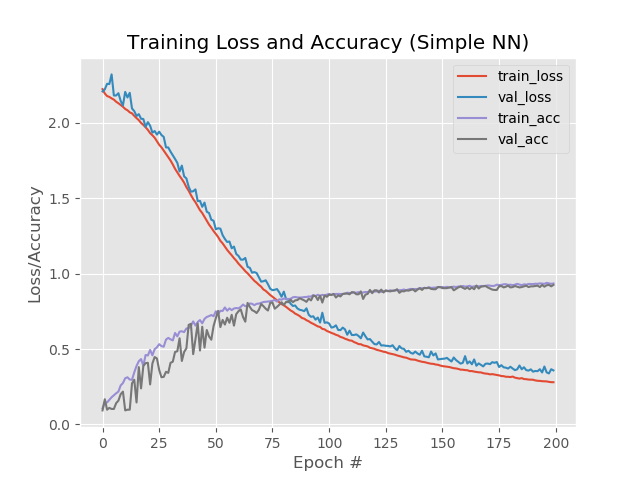
Ici, il est à noter que les lignes bleues et rouges après la 130e ère commencent à se disperser les unes des autres et cela indique qu'une nouvelle augmentation du nombre d'époques ne fonctionnera pas. Regardez ça.
Dans le code on change
EPOCHS = 200
sur
EPOCHS = 500
et s'enfuir à nouveau.
Résultat:
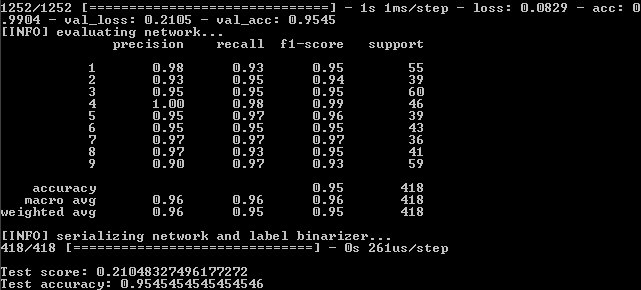
Nous avons donc:
99%, 95,5%, 95,5%.
Et sur le graphique:
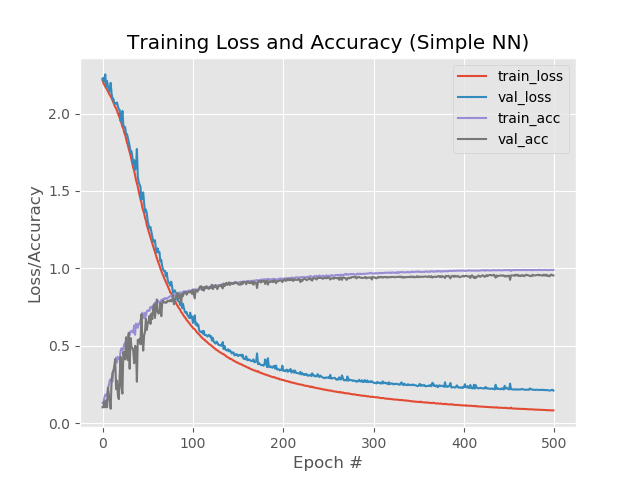
Eh bien, l'augmentation du nombre d'époques est clairement allée au filet. Cependant, ce résultat est trompeur.
Vérifions le fonctionnement du réseau à l'aide d'un exemple réel.
À ces fins, le script Predict.py se trouve dans le dossier du projet. Avant de commencer, préparez-vous.
Dans le dossier d'images du projet, nous avons mis les fichiers avec les images de nombres du captcha, que le réseau n'avait pas rencontrés auparavant dans le processus d'apprentissage. C'est-à-dire il est nécessaire de prendre des chiffres qui ne proviennent pas du dat dataset dat.
Dans le fichier lui-même, nous corrigeons deux lignes pour la taille d'image par défaut:
ap.add_argument("-w", "--width", type=int, default=16, help="target spatial dimension width") ap.add_argument("-e", "--height", type=int, default=37, help="target spatial dimension height")
Exécutez à partir de la ligne de commande:
python predict.py --image images/1.jpg --model output/simple_nn.model --label-bin output/simple_nn_lb.pickle --flatten 1
Et nous voyons le résultat:
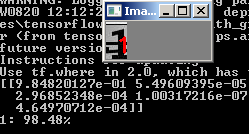
Une autre image:
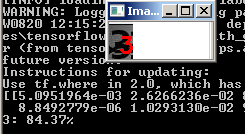
Cependant, cela ne fonctionne pas avec tous les nombres bruyants:
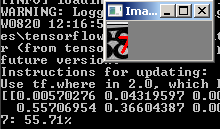
Que peut-on faire ici?
- Augmentez le nombre de copies de numéros dans les dossiers de formation.
- Essayez d'autres méthodes.
Essayons d'autres méthodes
Comme vous pouvez le voir sur le dernier graphique, les lignes bleues et rouges divergent autour de la 130e ère. Cela signifie que l'apprentissage après la 130e ère est inefficace. Nous fixons le résultat sur la 130e époque: 89,3%, 88%, 88% et voyons si d'autres méthodes pour améliorer le fonctionnement du réseau.
Réduisez la vitesse d'apprentissage. INIT_LR = 0.01
sur
INIT_LR = 0.001
Résultat:
41%, 39%, 39%
Eh bien, par.
Ajoutez un calque caché supplémentaire. model.add(Dense(512, activation="sigmoid"))
sur
model.add(Dense(512, activation="sigmoid")) model.add(Dense(258, activation="sigmoid"))
Résultat:
56%, 62%, 62%
Mieux, mais non.
Cependant, si vous augmentez le nombre d'époques à 250:
84%, 83%, 83%
Dans le même temps, les lignes rouges et bleues ne se détachent pas l'une de l'autre après la 130e ère:
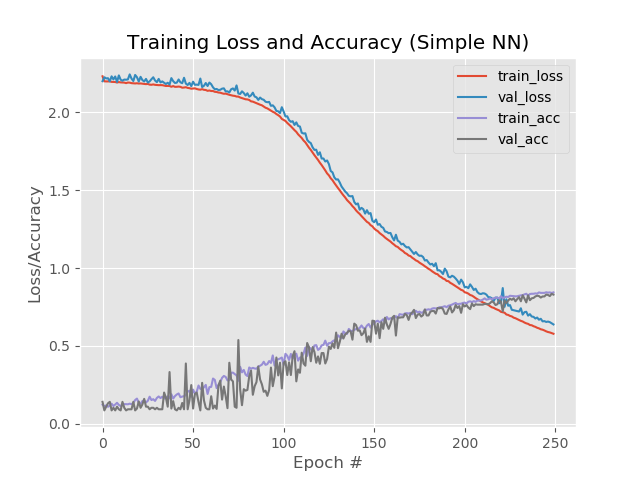 Économisez 250 époques et appliquez un éclaircissage
Économisez 250 époques et appliquez un éclaircissage :
from keras.layers.core import Dropout
Insérez l'amincissement entre les couches:
model.add(Dense(1024, input_shape=(1776,), activation="sigmoid")) model.add(Dropout(0.3)) model.add(Dense(512, activation="sigmoid")) model.add(Dropout(0.3)) model.add(Dense(258, activation="sigmoid")) model.add(Dropout(0.3))
Résultat:
53%, 65%, 65%
La première valeur est inférieure au reste, cela indique que le réseau n'apprend pas. Pour ce faire, il est recommandé d'augmenter le nombre d'époques.
model.add(Dense(1024, input_shape=(1776,), activation="sigmoid")) model.add(Dropout(0.3)) model.add(Dense(512, activation="sigmoid")) model.add(Dropout(0.3))
Résultat:
88%, 92%, 92%
Avec 1 couche supplémentaire, éclaircie et 500 époques:
model.add(Dense(1024, input_shape=(1776,), activation="sigmoid")) model.add(Dropout(0.3)) model.add(Dense(512, activation="sigmoid")) model.add(Dropout(0.3)) model.add(Dense(258, activation="sigmoid"))
Résultat:
92,4%, 92,6%, 92,58%
Malgré un pourcentage inférieur par rapport à une simple augmentation des époques à 500, le graphique semble plus uniforme:
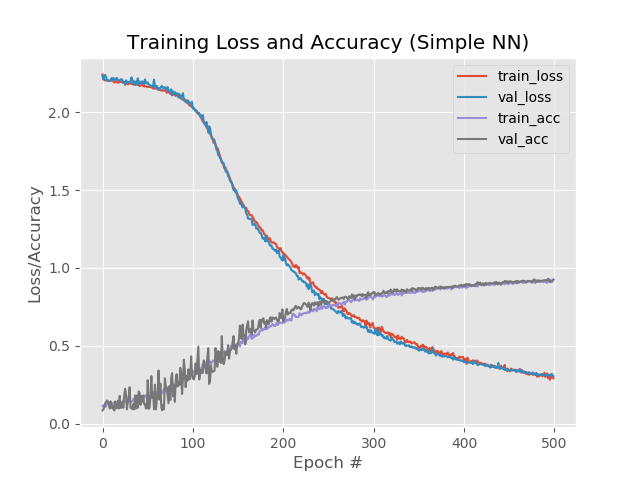
Et le réseau traite des images qui étaient tombées auparavant:
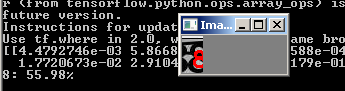
Maintenant, nous allons tout rassembler dans un fichier, qui découpera l'image avec le captcha à l'entrée en 5 chiffres, exécutera chaque chiffre à travers le réseau neuronal et produira le résultat vers l'interpréteur python.
C'est plus simple ici. Dans le fichier qui nous coupe les chiffres du captcha, ajoutez le fichier qui traite des prédictions.
Maintenant, le programme non seulement coupe le captcha en 5 parties, mais affiche également tous les numéros reconnus dans l'interpréteur:

Encore une fois, il faut garder à l'esprit que le programme ne donne pas 100% du résultat et souvent l'un des 5 chiffres est incorrect. Mais c'est un bon résultat, étant donné que dans l'ensemble de formation, il n'y a que 170-200 exemplaires pour chaque numéro.
La reconnaissance du captcha dure 3 à 5 secondes sur un ordinateur de puissance moyenne.
Sinon, comment pouvez-vous essayer d'améliorer le réseau? Vous pouvez lire dans le livre "Keras Library - un outil d'apprentissage en profondeur" A. Dzhulli, S. Pala.
Le script final qui coupe le captcha et le reconnaît est
ici .
Il démarre sans paramètres.
Scripts recyclés pour la
formation et le
test du réseau.
Captcha pour le test, y compris avec les faux positifs -
ici .
Le modèle de travail est
ici .
Les numéros dans les dossiers sont
ici .