Dans cet article, je décrirai notre expérience de la migration de Preply vers Kubernetes, comment et pourquoi nous l'avons fait, quelles difficultés nous avons rencontrées et quels avantages nous avons gagnés.

Kubernetes pour Kubernetes? Non, les exigences commerciales!
Autour de Kubernetes, il y a beaucoup de battage médiatique et pour une bonne raison. Beaucoup de gens disent que cela résoudra tous les problèmes, certains disent que vous n'avez probablement pas besoin de Kubernetes . La vérité est bien sûr quelque part entre les deux.

Cependant, toutes ces discussions sur où et quand Kubernetes est nécessaire méritent un article séparé. Je vais maintenant parler un peu de nos besoins commerciaux et du fonctionnement de Preply avant la migration vers Kubernetes:
- Lorsque nous avons utilisé le flux Skullcandy , nous avions beaucoup de branches, toutes fusionnées en une branche commune appelée
stage-rc , déployée sur scène. L'équipe QA a testé cet environnement, après avoir testé la branche était joyeuse dans le maître et le maître déployé sur le prod. L'ensemble de la procédure a pris environ 3-4 heures et nous avons pu déployer de 0 à 2 fois par jour - Lorsque nous avons déployé le code cassé sur la prod, nous avons dû annuler toutes les modifications incluses dans la dernière version. Il était également difficile de trouver quel changement a cassé notre produit
- Nous avons utilisé AWS Elastic Beanstalk pour héberger notre application. Chaque déploiement de Beanstalk dans notre cas a pris 45 minutes (l'ensemble du pipeline ainsi que les tests ont fonctionné en 90 minutes ). Le retour à la version précédente de l'application a pris 45 minutes
Pour améliorer nos produits et processus dans l'entreprise, nous voulions:
- Brisez un monolithe en microservices
- Déployez plus rapidement et plus souvent
- Revenez plus vite
- Changer notre processus de développement parce que nous pensions qu'il n'était plus efficace
Nos besoins
Nous changeons le processus de développement
Pour mettre en œuvre nos innovations avec Skullcandy flow, nous devions créer un environnement dynamique pour chaque branche. Dans notre approche avec la configuration d'application dans Elastic Beanstalk, c'était difficile et coûteux à faire. Nous voulions créer des environnements qui:
- Déployé rapidement et facilement (de préférence des conteneurs)
- Travaillé sur des instances ponctuelles
- Ils étaient aussi similaires à prod
Nous avons décidé de passer au développement basé sur le tronc. Avec son aide, chaque fonctionnalité a une branche distincte, qui, indépendamment des autres, peut fusionner en un maître. Une branche maître peut être déployée à tout moment.
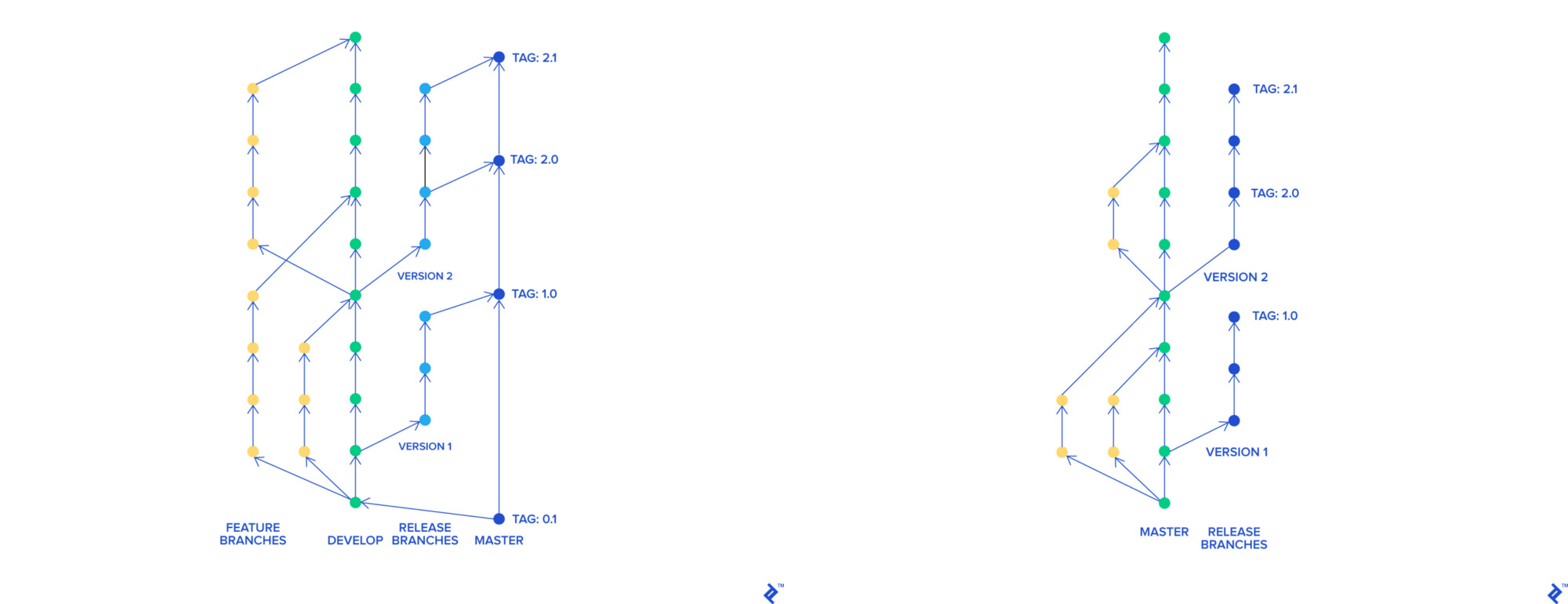
git-flow et développement basé sur le tronc
Déployez plus rapidement et plus souvent
Le nouveau processus basé sur le tronc nous a permis de livrer les innovations à la branche principale plus rapidement l'une après l'autre. Cela nous a grandement aidés à trouver du code cassé dans le prod et à le restaurer. Cependant, le temps de déploiement était toujours de 90 minutes et le temps de restauration était de 45 minutes, de ce fait, nous ne pouvions pas déployer plus souvent 4 à 5 fois par jour.
Nous avons également rencontré des difficultés à utiliser l'architecture de service sur Elastic Beanstalk. La solution la plus évidente était d'utiliser des conteneurs et des instruments pour les orchestrer. De plus, nous avions déjà de l'expérience avec Docker et docker-compose pour le développement local.
Notre prochaine étape était de rechercher les orchestrateurs de conteneurs populaires:
- AWS ECS
- Swarm
- Apache mesos
- Nomade
- Kubernetes
Nous avons décidé de rester à Kubernetes, et c'est pourquoi. Parmi les orchestrateurs en question, tout le monde avait un défaut important: ECS est une solution dépendante du fournisseur, Swarm a déjà perdu les lauriers de Kubernetes, Apache Mesos ressemblait à un vaisseau spatial pour nous avec ses Zookeepers. Nomad semblait intéressant, mais il ne s'est révélé pleinement qu'en intégration avec d'autres produits Hashicorp, nous avons également été déçus que les espaces de noms de Nomad soient payés.
Malgré son seuil d'entrée élevé, Kubernetes est la norme de facto dans l'orchestration de conteneurs. Kubernetes as a Service est disponible chez la plupart des principaux fournisseurs de cloud. L'orchestre est en développement actif, a une grande communauté d'utilisateurs et de développeurs et une bonne documentation.
Nous nous attendions à migrer entièrement notre plateforme vers Kubernetes dans un an. Deux ingénieurs de plate-forme sans expérience de Kubernetes ont été impliqués dans la migration à démarrage partiel.
Utiliser Kubernetes
Nous avons commencé par la preuve de concept, créé un cluster de tests et documenté tout ce que nous avons fait en détail. Nous avons décidé d'utiliser kops , car dans notre région à cette époque, EKS n'était toujours pas disponible (en Irlande, il a été annoncé en septembre 2018 ).
En travaillant avec le cluster, nous avons testé l' autoscaler du cluster , le gestionnaire de cert , Prometheus, les intégrations avec Hashicorp Vault, Jenkins et bien plus encore. Nous avons «joué» avec des stratégies de mise à jour continue, fait face à plusieurs problèmes de réseau, en particulier avec DNS , et renforcé nos connaissances en clustering de cluster.
Ils ont utilisé des instances ponctuelles pour optimiser les coûts d'infrastructure. Pour recevoir des notifications sur les problèmes ponctuels , ils ont utilisé kube-spot-terminaison-notice-handler , Spot Instance Advisor peut vous aider à choisir le type d'instance ponctuelle.
Nous avons commencé la migration du flux Skullcandy vers le développement basé sur Trunk, où nous avons lancé une étape dynamique pour chaque demande d'extraction, ce qui nous a permis de réduire le délai de livraison des nouvelles fonctionnalités de 4 à 6 à 1 à 2 heures .
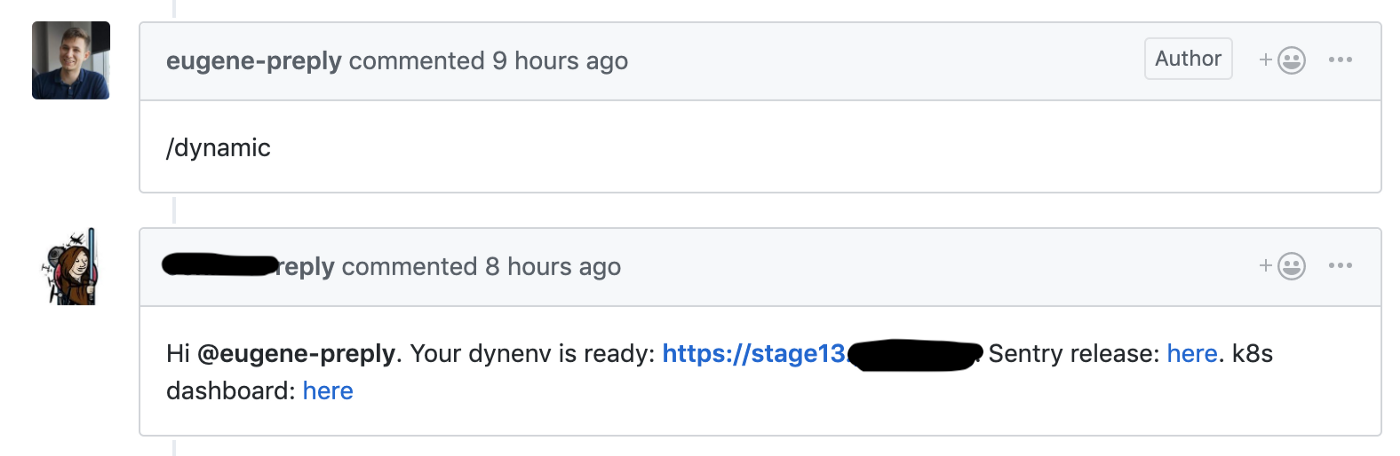
Github hook lance la création d'un environnement dynamique pour la demande de pull
Nous avons utilisé un cluster de test pour ces environnements dynamiques, chaque environnement était dans un espace de noms distinct. Les développeurs avaient accès au tableau de bord Kubernetes pour déboguer leur code.
Nous sommes heureux d'avoir commencé à bénéficier de Kubernetes après seulement 1-2 mois à compter du début de son utilisation.
Clusters de scène et de vente
Nos paramètres pour les groupes d'étapes et de produits:
- kops et Kubernetes 1.11 (la dernière version au moment de la création du cluster)
- Trois nœuds maîtres dans différentes zones d'accès
- Topologie de réseau privé avec bastion dédié, Calico CNI
- Prometheus pour la collecte des métriques est déployé dans le même cluster avec PVC (il convient de noter que nous ne stockons pas les métriques pendant une longue période)
- Agent Datadog pour APM
- Authentificateur Dex + dex-k8s pour fournir un accès au cluster aux développeurs
- Nœuds pour le travail de cluster d'étape sur des instances ponctuelles
En travaillant avec des clusters, nous avons rencontré plusieurs problèmes. Par exemple, les versions de l'agent Nginx Ingress et Datadog différaient sur les clusters, en relation avec cela, certaines choses fonctionnaient sur le cluster de la scène, mais ne fonctionnaient pas sur le prod. Par conséquent, nous avons décidé de faire la pleine conformité des versions du logiciel sur les clusters pour éviter de tels cas.
Migration de Prod vers Kubernetes
Les groupes de scène et de nourriture sont prêts, et nous sommes prêts à commencer la migration. Nous utilisons monorepa avec la structure suivante:
. ├── microservice1 │ ├── Dockerfile │ ├── Jenkinsfile │ └── ... ├── microservice2 │ ├── Dockerfile │ ├── Jenkinsfile │ └── ... ├── microserviceN │ ├── Dockerfile │ ├── Jenkinsfile │ └── ... ├── helm │ ├── microservice1 │ │ ├── Chart.yaml │ │ ├── ... │ │ ├── values.prod.yaml │ │ └── values.stage.yaml │ ├── microservice2 │ │ ├── Chart.yaml │ │ ├── ... │ │ ├── values.prod.yaml │ │ └── values.stage.yaml │ ├── microserviceN │ │ ├── Chart.yaml │ │ ├── ... │ │ ├── values.prod.yaml │ │ └── values.stage.yaml └── Jenkinsfile
Le Jenkinsfile racine contient une table de correspondance entre le nom du microservice et le répertoire dans lequel se trouve son code. Lorsque le développeur détient la demande d'extraction au maître, une balise est créée dans GitHub, cette balise est déployée sur le prod à l'aide de Jenkins conformément au fichier Jenkins.
Le répertoire helm/ contient des graphiques HELM avec deux fichiers de valeurs séparés pour la scène et la vente. Nous utilisons Skaffold pour déployer de nombreuses cartes HELM sur la scène. Nous avons essayé d'utiliser le tableau générique, mais face au fait qu'il est difficile à mettre à l'échelle.
Conformément à l'application à douze facteurs, chaque nouveau microservice dans le prod écrit des journaux sur stdout, lit les secrets de Vault et dispose d'un ensemble d'alertes de base (vérification du nombre de foyers en fonctionnement, de cinq cents erreurs et de latences à l'entrée).
Que nous importions ou non de nouvelles fonctionnalités dans des microservices, dans notre cas, toutes les fonctionnalités principales se trouvent dans le monolithe Django et ce monolithe fonctionne toujours sur Elastic Beanstalk.

Briser le monolithe en microservices // Le parc Vigeland à Oslo
Nous avons utilisé AWS Cloudfront comme CDN et avec lui, nous avons utilisé un déploiement canari tout au long de notre migration. Nous avons commencé à migrer le monolithe vers Kubernetes et à le tester sur certaines versions linguistiques et sur les pages internes du site (comme le panneau d'administration). Un processus de migration similaire nous a permis d'attraper des bugs sur la prod et de peaufiner nos déploiements en quelques itérations. Au cours de quelques semaines, nous avons surveillé l'état de la plate-forme, la charge et la surveillance, et au final, 100% du trafic de vente a été transféré vers Kubernetes.
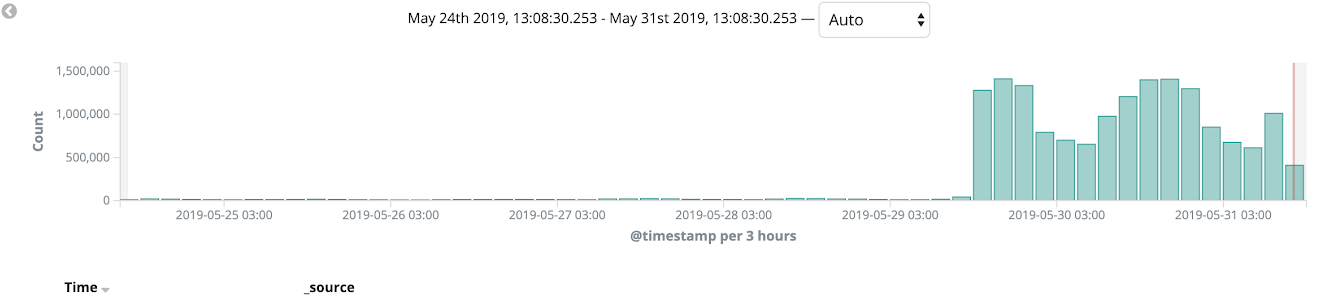
Après cela, nous avons complètement pu abandonner l'utilisation d'Elastic Beanstalk.
Résumé
La migration complète nous a pris 11 mois, comme je l'ai mentionné ci-dessus, nous avions prévu de respecter le délai d'un an.
En fait, les résultats sont évidents:
- Le temps de déploiement est passé de 90 min à 40 min
- Le nombre de déploiements est passé de 0-2 à 10-15 par jour (et continue de croître!)
- Le temps de restauration est passé de 45 à 1-2 minutes
- Nous pouvons facilement fournir de nouveaux microservices à la prod
- Nous avons rangé notre surveillance, notre journalisation, notre gestion des secrets, les avons centralisés et les avons décrits comme du code
Ce fut une expérience de migration très cool et nous travaillons toujours sur de nombreuses améliorations de plate-forme. Assurez-vous de lire l' article cool sur l'expérience avec Kubernetes du Jura, il était l'un de ces ingénieurs YAML qui ont été impliqués dans la mise en œuvre de Kubernetes dans Preply.