Dans le monde de la cryptographie, il existe de nombreuses façons simples de crypter un message. Chacun d'eux est bon à sa manière. L'un d'eux sera discuté.
Ylchu Schzzkgow
Ou traduit du "Chiffre de César" en russe - Chiffre de César .

- Quelle est son essence?
- Il encode le message, décalant chaque lettre de N points. Le chiffre classique de César fait avancer les lettres de trois pas. En termes simples - c'était «abv», c'est devenu «où».
"Mais qu'en est-il des lettres à la fin de l'alphabet?" Et les espaces?
Ils vont bien. Si vous déplacez la lettre, le chiffre dépasse la portée de l'alphabet - il recommence à compter. Autrement dit, les lettres "Eyuya" se transforment en "abv". Et les espaces restent des espaces.
- N doit-il nécessairement être égal à trois?
Pas du tout. N peut différer de trois. Tout N compris entre [1: M-1] est autorisé, où M est le nombre de lettres de l'alphabet.
Un tel chiffre est facile à déchiffrer si vous connaissez son existence. Mais ce n'est pas sa «fiabilité» qui m'a attiré, mais autre chose.
Cravate
Un jour d'été, je voulais savoir:
- Mais que se passe-t-il si je crypte un mot à l'aide de César et que j'obtiens un mot existant à la sortie?
- Combien de ces mots sont des «shifters»?
- Et y aura-t-il un modèle si N est changé?
J'ai commencé à chercher des réponses à ces questions dans les mêmes minutes.
Tâche: trouver tous les mots
Retraite. Des concerts de Mikhail Zadornov et de mon expérience personnelle, j'ai compris deux choses:
- Les Américains ne sont pas offensés par le discours des comédiens russes.
- La langue russe est forte et puissante. Et il y a beaucoup de mots dedans.
Par conséquent, j'ai décidé de prendre la langue anglaise comme base. De plus, il était une fois, il y avait INFA que les gars anglophones étaient capables de mettre en place un dictionnaire complet de mots anglais. Ce qui m'a incité à trouver un tel ensemble de données.
La première ligne de recherche de Google paresseuse m'a amené à ce référentiel . L'auteur a promis 479K mots anglais dans des formats pratiques. J'ai aimé le fichier json, dans lequel tous les mots étaient disposés sous une forme pratique pour le chargement dans le dictionnaire Python.
Après la première autopsie, il s'est avéré qu'il y avait moins de mots - 370 101 pièces. "Mais cela n'a pas d'importance, car pour un bon exemple, ce sera suffisant", ai-je pensé.
words = json.load(open('words_dictionary.json', 'r')) len(words.keys()) >> 370101
Vous devez d'abord créer un alphabet. J'ai décidé d'en faire une liste de la manière la plus pratique pour moi. Il fallait aussi se souvenir du nombre de lettres de l'alphabet:
abc = list('abcdefghijklmnopqrstuvwxyz') abc_len = len(abc)
Au début, il était intéressant de rendre la fonction de traduire un mot crypté. Voici ce qui s'est passé:
J'ai décidé de faire un grand cycle de tous les mots et de commencer à les traduire un par un. Mais j'ai rencontré un problème. Il s'est avéré que certains mots contenaient un signe «-», ce qui était à la fois surprenant et naturel.
Sans réfléchir à deux fois, j'ai compté le nombre de ces mots et il s'est avéré qu'il n'y en avait que deux. Après quoi, il a supprimé les deux, car cela n'affectera guère le résultat. Pour m'aider, cette fonction est née:
Le dictionnaire ressemblait à:
{'a': 1, 'aa': 1, 'aaa': 1, 'aah': 1, ... }
Par conséquent, j'ai décidé de ne pas être intelligent et de remplacer ceux par des mots codés. Pour ce faire, a écrit une fonction:
Et, bien sûr, nous avions besoin d'un grand cycle qui passera par tous les mots, trouvera les mots-shifters et sauvegardera le résultat. Le voici:
Vous avez peut-être remarqué que dans les paramètres de la fonction est «min_len = 0». Il sera nécessaire à l'avenir. Car la particularité de cet ensemble de données était un ensemble de mots "étrange". Tels que: "aa", "aah" et combinaisons similaires. Ce sont eux qui ont donné le premier résultat - 660 mots-shifters.
Par conséquent, j'ai dû mettre une limite de cinq au moins cinq caractères pour que les mots soient agréables à l'œil et similaires à ceux existants.
words_result = check_all(words_cesar, min_len=5) words_result >> {'abime': 'delph', 'biabo': 'elder', 'bifer': 'elihu', 'cobra': 'freud', 'colob': 'frore', 'oxime': 'ralph', 'pelta': 'showd', 'primero': 'sulphur', 'teloi': 'whorl', 'xerox': 'ahura'}
Oui, dix mots flip ont été trouvés grâce à l'algorithme. Ma combinaison préférée:
primero [Premier] → soufre [Soufre]. La plupart des autres paires que le traducteur Google ne reconnaît pas.
À ce stade, j'ai partiellement étanché la soif de connaissance. Mais devant nous, il y avait des questions comme: «Qu'en est-il de l'autre N?»
Et en utilisant cette fonction, j'ai trouvé la réponse:
Le cycle s'est terminé en 10-15 secondes. Il ne reste plus qu'à voir les résultats. Mais, comme je pense que c'est plus intéressant quand il y a un planning. Et voici la fonction finale, qui va nous montrer le résultat:
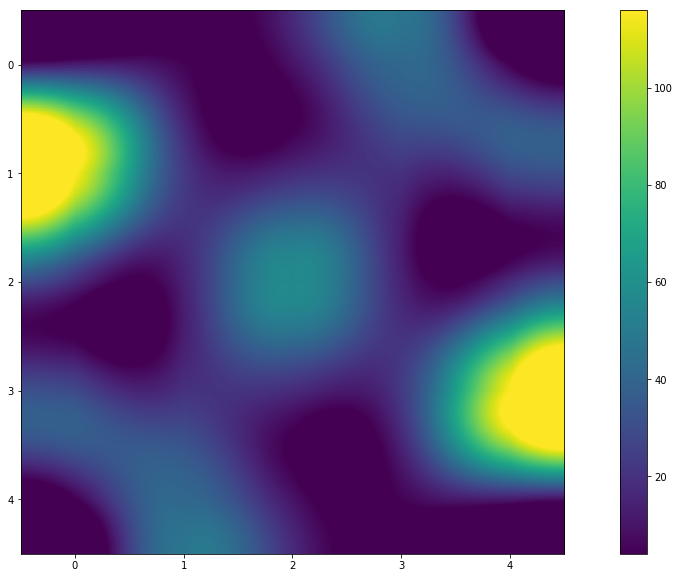
Résumé
Réponses aux questions au début
"Et si je crypte un mot en utilisant César et que j'obtiens un mot existant à la sortie?"
- C'est possible, même très. Certains N donnent beaucoup plus de mots que d'autres.
- Combien y a-t-il de mots «shifters»?
- Dépend de N, de la longueur minimale et, bien sûr, de l'ensemble de données. Dans mon cas, avec N = 3, la longueur minimale de mot de 0 et 5 est le nombre de mots: 660 et 10, respectivement.
- Et y aura-t-il un modèle si vous changez N?
- Apparemment, oui! À partir du graphique (ou de la carte thermique), vous pouvez voir que les couleurs sont symétriques. Et les valeurs dans la matrice des résultats l'indiquent. Et la réponse à la question "Pourquoi en est-il ainsi?" Je laisse le soin au lecteur.
Inconvénients de ce travail
- Jeu de données pas tout à fait correct. Beaucoup de mots ne sont pas évidents. Bien qu'il en soit ainsi. Ce sont « tous » les mots de la langue anglaise.
- Code
toujours peut être amélioré. - Le "code de César" est un cas particulier du "code athénien", où la formule:
Pour "César's Cipher" A = 1. Soit dit en passant, il a plus de nuances, ce qui signifie plus intéressant.
Mon fichier de travail avec le résultat et une liste de mots flip se trouve dans ce référentiel
Efzp zzhgl!