Le partitionnement ("partitionnement") dans SQL Server, avec une simplicité apparente ("ce qui est là - vous répartissez la table et les index par groupes de fichiers, vous gagnez en administration et en performances") est un sujet assez étendu. Ci-dessous, je vais essayer de décrire comment créer et appliquer un schéma de fonction et de partition et quels problèmes vous pouvez rencontrer. Je ne parlerai pas des avantages, sauf pour une chose - changer de section, lorsque vous supprimez instantanément un énorme ensemble de données d'une table, ou vice versa - charger instantanément un ensemble non moins énorme dans une table.
Comme l'indique
msdn : «Les données des tables et index partitionnés sont divisées en blocs qui peuvent être répartis sur plusieurs groupes de fichiers dans la base de données. Les données sont partitionnées horizontalement, les groupes de lignes sont donc mappés sur des sections individuelles. Toutes les sections d'un même index ou d'une même table doivent se trouver dans la même base de données. Une table ou un index est considéré comme une entité logique unique lors de l'exécution de requêtes ou de mises à jour sur les données. »
Les principaux avantages y sont également répertoriés:
- Transférez et accédez à des sous-ensembles de données rapidement et efficacement tout en maintenant l'intégrité de l'ensemble de données
- Les opérations de maintenance peuvent être effectuées plus rapidement avec une ou plusieurs sections;
- Vous pouvez augmenter la vitesse d'exécution des requêtes, selon les requêtes qui sont souvent exécutées dans votre configuration matérielle.
En d'autres termes, le partitionnement est utilisé pour la mise à l'échelle horizontale. La table / les index sont «répartis» par différents groupes de fichiers, qui peuvent être situés sur différents disques physiques, ce qui augmente considérablement la commodité de l'administration et, théoriquement, vous permet d'améliorer les performances des requêtes sur ces données - vous pouvez soit lire uniquement la section souhaitée (moins de données), ou tout lire en parallèle (les appareils sont différents, lisez vite). En pratique, tout est un peu plus compliqué et l'augmentation des performances des requêtes sur les tables partitionnées ne peut fonctionner que si vos requêtes utilisent la sélection par le champ que vous avez partitionné. Si vous n'avez pas encore d'expérience avec les tables partitionnées, gardez à l'esprit que les performances de vos requêtes peuvent ne pas changer, mais peuvent se détériorer après avoir partitionné votre table.
Parlons de l'avantage absolu que vous obtenez certainement avec le partitionnement (mais que vous devez également pouvoir utiliser) - il s'agit d'une augmentation garantie de la commodité de la gestion de votre base de données. Par exemple, vous avez un tableau avec un milliard d'enregistrements, dont 900 millions proviennent des anciennes périodes («fermées») et sont en lecture seule. À l'aide de la section, vous pouvez transférer ces anciennes données vers un groupe de fichiers en lecture seule distinct, les sauvegarder et ne plus les faire glisser dans toutes vos sauvegardes quotidiennes - la vitesse de création d'une copie de sauvegarde augmentera et la taille diminuera. Vous pouvez reconstruire l'index non pas sur toute la table, mais sur les sections sélectionnées. De plus, la disponibilité de votre base de données augmente - si l'un des périphériques contenant le groupe de fichiers avec la section tombe en panne, les autres seront toujours disponibles.
Pour obtenir les avantages restants (changer de section instantanément; augmenter la productivité) - vous devez concevoir spécifiquement la structure des données et écrire des requêtes.
Je suppose que j’ai déjà assez embarrassé le lecteur et maintenant je peux continuer à pratiquer.
Tout d'abord, créez une base de données avec 4 groupes de fichiers dans lesquels nous effectuerons des expériences:
create database [PartitionTest] on primary (name ='PTestPrimary', filename = 'E:\data\partitionTestPrimary.mdf', size = 8092KB, filegrowth = 1024KB) , filegroup [fg1] (name ='PTestFG1', filename = 'E:\data\partitionTestFG1.ndf', size = 8092KB, filegrowth = 1024KB) , filegroup [fg2] (name ='PTestFG2', filename = 'E:\data\partitionTestFG2.ndf', size = 8092KB, filegrowth = 1024KB) , filegroup [fg3] (name ='PTestFG3', filename = 'E:\data\partitionTestFG3.ndf', size = 8092KB, filegrowth = 1024KB) log on (name = 'PTest_Log', filename = 'E:\data\partitionTest_log.ldf', size = 2048KB, filegrowth = 1024KB); go alter database [PartitionTest] set recovery simple; go use partitionTest;
Créez une table que nous tourmenterons.
create table ptest (id int identity(1,1), dt datetime, dummy_int int, dummy_char char(6000));
Et remplissez-le de données pendant un an:
;with nums as ( select 0 n union all select 1 union all select 2 union all select 3 union all select 4 union all select 5 union all select 6 union all select 7 union all select 8 union all select 9 ) insert into ptest(dt, dummy_int, dummy_char) select dateadd(hh, rn-1, '20180101') dt, rn dummy_int, 'dummy char column #' + cast(rn as varchar) from ( select row_number() over(order by (select (null))) rn from nums n1, nums n2, nums n3, nums n4 )t where rn < 8761
Maintenant, la table pTest contient un enregistrement pour chaque heure de 2018.
Vous devez maintenant créer une fonction de partition qui décrit les conditions aux limites pour diviser les données en sections. SQL Server prend uniquement en charge le partitionnement de plage.
Nous allons partitionner notre table par la colonne dt (datetime) afin que chaque section contienne des données pendant 4 mois (ici j'ai foiré - en fait, la première section contiendra des données pour 3, la seconde pour 4, la troisième pour 5 mois, mais à des fins de démonstration - ce n'est pas un problème)
create partition function pfTest (datetime) as range for values ('20180401', '20180801')
Tout semble normal, mais ici j'ai délibérément fait une «erreur». Si vous regardez la syntaxe dans
msdn , vous verrez que lors de la création, vous pouvez spécifier à quelle section la bordure spécifiée appartiendra - à gauche ou à droite. Par défaut, pour une raison inconnue, la bordure spécifiée fait référence à la section "gauche", donc dans mon cas, il serait correct de créer une fonction de partition comme suit:
create partition function pfTest (datetime) as range right for values ('20180401', '20180801')
Alors que j'ai effectivement exécuté:
create partition function pfTest (datetime) as range left for values ('20180401', '20180801')
Mais nous y reviendrons plus tard et recréerons notre fonction de partition. En attendant, nous continuons avec ce qui s'est passé afin de comprendre ce qui s'est passé et pourquoi ce n'est pas très bon pour nous.
Après avoir créé la fonction de partition, vous devez créer un schéma de partition. Il lie clairement les sections aux groupes de fichiers:
create partition scheme psTest as partition pfTest to ([FG1], [FG2], [FG3])
Comme vous pouvez le voir, nos trois sections seront dans des groupes de fichiers différents. Il est maintenant temps de partitionner notre table. Pour ce faire, nous devons créer un index clusterisé et, au lieu de spécifier le groupe de fichiers dans lequel il doit être situé, spécifier le schéma de partitionnement:
create clustered index cix_pTest_id on pTest(id) on psTest(dt)
Et ici aussi, j'ai fait une «erreur» dans le schéma actuel - j'aurais très bien pu créer un index cluster unique sur cette colonne, cependant, lors de la création d'un index unique, la colonne utilisée pour partitionner devrait être incluse dans l'index. Et je veux montrer ce que vous pouvez rencontrer avec cette configuration.
Voyons maintenant ce que nous avons obtenu dans la configuration actuelle (la
demande est prise à partir d'ici ):
SELECT sc.name + N'.' + so.name as [Schema.Table], si.index_id as [Index ID], si.type_desc as [Structure], si.name as [Index], stat.row_count AS [Rows], stat.in_row_reserved_page_count * 8./1024./1024. as [In-Row GB], stat.lob_reserved_page_count * 8./1024./1024. as [LOB GB], p.partition_number AS [Partition

Ainsi, nous avons obtenu trois sections peu réussies - la première stocke les données du début du temps jusqu'au 04/01/2018 00:00:00 inclus, la seconde - du 01/01/2018 00:00:01 au 08/01/2018 00:00:00 inclus, la troisième du 08/01/2018 00:00:01 jusqu'à la fin du monde (j'ai délibérément manqué la fraction de seconde, car je ne me souviens pas à quelle gradation SQL Server écrit ces fractions, mais la signification est correctement transmise).
Créez maintenant un index non clusterisé sur le champ dummy_int, «aligné» selon le même schéma de partitionnement.
Pourquoi avons-nous besoin d'un index aligné?nous avons besoin d'un index aligné pour pouvoir effectuer l'opération de commutation d'une section (switch) - et c'est l'une de ces opérations pour lesquelles, souvent, elles se soucient du partitionnement. S'il existe au moins un index non aligné dans la table, vous ne pouvez pas changer de section
create nonclustered index nix_pTest_dummyINT on pTest(dummy_int) on psTest(dt);
Et voyons pourquoi j'ai dit que vos requêtes pourraient ralentir après l'implémentation de la section. Exécutez la demande:
SET STATISTICS TIME, IO ON; select id from pTest where dummy_int = 54 SET STATISTICS TIME, IO OFF;
Et voyons les statistiques d'exécution:
Table 'ptest'. Scan count 3, logical reads 6, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Et le plan de mise en œuvre:

Puisque notre index est «aligné» par sections, conditionnellement, chaque section a son propre index, qui est «non connecté» avec les index des autres sections. Nous n'avons pas imposé de conditions au champ par lequel l'index est partitionné, donc SQL Server est obligé d'exécuter la recherche d'index dans chaque section, en fait, 3 Index Seek au lieu d'une.
Essayons d'exclure une section:
SET STATISTICS TIME, IO ON; select id from pTest where dummy_int = 54 and dt < '20180801' SET STATISTICS TIME, IO OFF;
Et voyons les statistiques d'exécution:
Table 'ptest'. Scan count 2, logical reads 4, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Oui, une section a été exclue et la recherche de la valeur souhaitée n'a été effectuée que dans deux sections.
C'est quelque chose dont il faut se souvenir lors du choix du partitionnement. Si vous avez des requêtes qui n'utilisent pas de restriction sur le champ par lequel la table est partitionnée, vous pouvez avoir un problème.
Nous n'avons plus besoin de l'index non clusterisé, donc je le supprime
drop index nix_pTest_dummyINT on pTest;
Et pourquoi un index non cluster était-il nécessaire?en général, je n'en avais pas besoin, je pouvais montrer la même chose avec l'index de cluster, je ne sais pas pourquoi je l'ai créé, mais depuis que je l'ai fait et fait des captures d'écran - ne disparaissent pas
Maintenant, considérons le scénario suivant: nous archivons les données de ce tableau tous les 4 mois - nous supprimons les anciennes données et ajoutons une section pour les quatre prochains mois (l'organisation de la «fenêtre coulissante» est décrite dans msdn et un tas de blogs).
Nous divisons la tâche en petites sous-tâches compréhensibles:
- Ajouter une section pour les données du 01/01/2019 au 04/01/2019
- Créer une table de scène vide
- Changer la section des données jusqu'au 04/01/2018 dans la table des étapes
- Débarrassez-vous de la section vide
C'est parti:
1. Nous annonçons que la nouvelle section sera créée dans le groupe de fichiers FG1, car elle sera bientôt libérée de nous:
alter partition scheme psTest next used [FG1];
Et changez la fonction de partition en ajoutant une nouvelle bordure:
SET STATISTICS TIME, IO ON; alter partition function pfTest() split range ('20190101'); SET STATISTICS TIME, IO OFF;
Nous regardons les statistiques:
Table 'ptest'. Scan count 1, logical reads 76171, physical reads 0, read-ahead reads 753, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 1, logical reads 7440, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Il y a 8809 pages dans le tableau (index de cluster), donc le nombre de lectures, bien sûr, est au-delà du bien et du mal. Voyons ce que nous avons maintenant dans les sections.

En général, tout était comme prévu - une nouvelle section avec une limite supérieure est apparue (rappelez-vous que les conditions aux limites pour nous appartiennent à la section de gauche) 01/01/2019 et une section vide dans laquelle il y aura d'autres données avec une date plus longue.
Tout semble aller bien, mais pourquoi y a-t-il tant de lectures? Nous regardons attentivement la figure ci-dessus et voyons que les données de la troisième section qui se trouvaient dans FG3 se sont retrouvées dans FG1, mais la section suivante, vide, dans FG3.
2. Créez une table de scène.
Pour basculer (basculer) une section vers une table et vice versa, nous avons besoin d'une table vide dans laquelle toutes les mêmes restrictions et index sont créés comme sur notre table partitionnée. Le tableau doit être dans le même groupe de fichiers que la section que nous voulons «basculer» là-bas. La première section (archivée) se trouve dans FG1, nous créons donc une table et un index de cluster au même endroit:
create table stageTest (id int identity(1,1), dt datetime, dummy_int int, dummy_char char(6000)) ; create clustered index cix_stageTest_id on stageTest(id) on [FG1];
Vous n'avez pas besoin de partitionner cette table.
3. Nous sommes maintenant prêts à passer:
SET STATISTICS TIME, IO ON; alter table pTest switch partition 1 to stageTest SET STATISTICS TIME, IO OFF;
Et voici ce que nous obtenons:
4947, 16, 1, 59 ALTER TABLE SWITCH statement failed. There is no identical index in source table 'PartitionTest.dbo.pTest' for the index 'cix_stageTest_id' in target table 'PartitionTest.dbo.stageTest' .
Drôle, voyons ce que nous avons dans les indices:
select o.name tblName, i.name indexName, c.name columnName, ic.is_included_column from sys.indexes i join sys.objects o on i.object_id = o.object_id join sys.index_columns ic on ic.object_id = i.object_id and ic.index_id = i.index_id join sys.columns c on ic.column_id = c.column_id and o.object_id = c.object_id where o.name in ('pTest', 'stageTest')
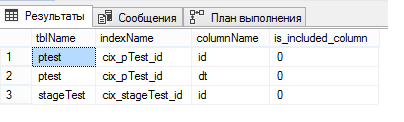
Rappelez-vous, j'ai écrit qu'il était nécessaire de créer un index cluster unique sur une table partitionnée? C'est précisément pourquoi c'était nécessaire. Lors de la création d'un index cluster unique, SQL Server nécessiterait explicitement d'inclure la colonne par laquelle nous partitionnons la table dans l'index, et il l'a donc ajouté lui-même et a oublié de le dire. Et je ne comprends vraiment pas pourquoi.
Mais, en général, le problème est compréhensible, nous recréons l'index de cluster sur la table des étapes.
create clustered index cix_stageTest_id on stageTest(id, dt) with (drop_existing = on) on [FG1];
Et maintenant, encore une fois, nous essayons de changer de section:
SET STATISTICS TIME, IO ON; alter table pTest switch partition 1 to stageTest SET STATISTICS TIME, IO OFF;
Ta Dam! La section est changée, voyez ce que cela nous a coûté:
SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 3 ms.
Mais rien. Passer d'une section à une table vide et vice versa (une table complète à une section vide) est une opération uniquement sur les métadonnées et c'est exactement pourquoi le partitionnement est une chose très, très cool.
Voyons ce qu'il y a avec nos sections:

Et tout va bien avec eux. Dans la première section, il ne reste aucun enregistrement, ils sont partis en toute sécurité pour la table stageTest. On peut avancer
4. Il ne nous reste plus qu'à supprimer notre première section vide. Faisons-le et voyons ce qui se passe:
SET STATISTICS TIME, IO ON; alter partition function pfTest() merge range ('20180401'); SET STATISTICS TIME, IO OFF;
Et c'est aussi une opération uniquement sur les métadonnées, dans notre cas. Nous regardons les sections:

Nous avons, comme c'était le cas, seulement 3 sections, chacune dans son propre groupe de fichiers. Mission accomplie. Qu'est-ce qui pourrait être amélioré ici? Eh bien, tout d'abord, je voudrais que les valeurs limites se réfèrent aux sections «à droite», afin que les sections contiennent toutes les données pendant 4 mois. Et j'aimerais que la création d'une nouvelle section coûte moins cher. Lisez les données dix fois plus que le tableau lui-même - buste.
Nous ne pouvons rien faire avec le premier maintenant, mais avec le second, nous allons essayer. Créons une nouvelle section qui contiendra les données du 01/01/2019 au 04/01/2019, et pas avant la fin des temps:
alter partition scheme psTest next used [FG2]; SET STATISTICS TIME, IO ON; alter partition function pfTest() split range ('20190401'); SET STATISTICS TIME, IO OFF;
Et nous voyons:
SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms.
Ha! Alors maintenant, cette opération est uniquement sur les métadonnées? Oui, si vous "divisez" une section vide - il s'agit d'une opération uniquement sur les métadonnées, donc ce sera la bonne décision de conserver les sections vides garanties à gauche et à droite et, si nécessaire, en sélectionner une nouvelle - "les couper" à partir de là.
Voyons maintenant ce qui se passe si je veux retourner les données de la table de scène à la table partitionnée. Pour ce faire, il me faudra:
- Créer une nouvelle section à gauche pour les données
- Basculez le tableau dans cette section
Nous essayons (et rappelons-nous que stageTest dans FG1):
alter partition scheme psTest next used [FG1]; SET STATISTICS TIME, IO ON; alter partition function pfTest() split range ('20180401'); SET STATISTICS TIME, IO OFF;
On voit:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'ptest'. Scan count 1, logical reads 2939, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Eh bien, pas mal, c'est-à-dire ne lisez que la partie gauche (que nous divisons) et c'est tout. Ok Pour basculer une table non vide non partitionnée dans une section de table partitionnée, la table source doit avoir des restrictions afin que SQL Server sache que tout ira bien et la commutation peut être effectuée en tant qu'opération sur les métadonnées (plutôt que de tout lire sur une ligne et de vérifier si la section correspond ou non aux conditions) ):
alter table stageTest add constraint check_dt check (dt <= '20180401')
Essayer de changer:
SET STATISTICS TIME, IO ON; alter table stageTest switch to pTest partition 1 SET STATISTICS TIME, IO OFF;
Statistiques:
SQL Server Execution Times: CPU time = 15 ms, elapsed time = 39 ms.
Encore une fois, l'opération ne concerne que les métadonnées. Nous regardons ce qui est avec nos sections:

Ok Cela semble réglé. Et maintenant, nous allons essayer de recréer la fonction et le schéma de partitionnement (j'ai supprimé le schéma et la fonction de partitionnement, recréé et rempli la table et recréé l'index de cluster à l'aide du nouveau schéma de partitionnement):
create partition function pfTest (datetime) as range right for values ('20180401', '20180801')
Voyons quelles sections nous avons maintenant:

Eh bien, nous avons maintenant trois sections «logiques» - du début du temps jusqu'au 04/01/2018 00:00:00 (non inclus), du 04/01/2018 00:00:00 (inclus) au 08/01/2018 00:00:00 ( non inclus) et le troisième, tout ce qui est supérieur ou égal au 01/01/2018 00:00:00.
Essayons maintenant d'effectuer la même tâche d'archivage des données que celle effectuée avec la fonction de partition précédente.
1. Ajoutez une nouvelle section:
alter partition scheme psTest next used [FG1]; SET STATISTICS TIME, IO ON; alter partition function pfTest() split range ('20190101'); SET STATISTICS TIME, IO OFF;
Nous regardons les statistiques:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'ptest'. Scan count 1, logical reads 3685, physical reads 0, read-ahead reads 4, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 1, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Pas mal, du moins raisonnablement - ne lisez que la dernière section. Nous regardons ce que nous avons dans les sections:

Notez que maintenant, la troisième section terminée est restée en place dans FG3, et une nouvelle section vide a été créée dans FG1.
2. Nous créons une table de scène et l'index de cluster CORRECT sur elle
create table stageTest (id int identity(1,1), dt datetime, dummy_int int, dummy_char char(6000)) ; create clustered index cix_stageTest_id on stageTest(id, dt) on [FG1];
3. Section de commutation
SET STATISTICS TIME, IO ON; alter table pTest switch partition 1 to stageTest SET STATISTICS TIME, IO OFF;
Les statistiques indiquent que l'opération de métadonnées est:
SQL Server Execution Times: CPU time = 0 ms, elapsed time = 5 ms.
Maintenant, sans surprise.
4. Supprimer la section inutile
SET STATISTICS TIME, IO ON; alter partition function pfTest() merge range ('20180401'); SET STATISTICS TIME, IO OFF;
Et là, nous avons une surprise:
Table 'ptest'. Scan count 1, logical reads 27057, physical reads 0, read-ahead reads 251, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Nous regardons ce que nous avons avec les sections:

Et ici, cela devient clair: notre section # 2 est passée du groupe de fichiers fg2 au groupe de fichiers fg1. Classe. Pouvons-nous faire quelque chose à ce sujet?
Peut-être que nous devons simplement avoir toujours une section vide et «détruire» la frontière entre la section gauche «toujours vide» et la section que nous avons «basculée» vers une autre table.
En conclusion:- Utilisez la syntaxe complète pour créer une fonction de partition, ne vous fiez pas aux valeurs par défaut - vous n'obtiendrez peut-être pas ce que vous vouliez.
- Gardez à gauche et à droite sur la section vide - ils vous seront très utiles lors de l'organisation d'une "fenêtre coulissante".
- Fractionner et fusionner des sections non vides - cela fait toujours mal, évitez cela si possible.
- Vérifiez vos requêtes - si elles n'utilisent pas le filtre par la colonne dans laquelle vous prévoyez de partitionner la table et que vous avez besoin de pouvoir changer de section - leurs performances peuvent considérablement diminuer.
- Si vous voulez faire quelque chose, testez d'abord pas en production.
J'espère que le matériel a été utile. Peut-être que cela s'est avéré être froissé, si vous pensez que quelque chose du déclaré n'est pas divulgué, écrivez, je vais essayer de le terminer. Merci de votre attention.