Bonjour à tous. Avant le début du cours de Machine Learning, il reste un peu plus d'une semaine. En prévision du début des cours, nous avons préparé une traduction utile qui intéressera à la fois nos étudiants et tous les lecteurs de blog. Commençons.

Il est temps de se débarrasser des boîtes noires et de faire confiance à l'apprentissage automatique!Dans son livre
"Interprétable Machine Learning", Christoph Molnar met parfaitement en évidence l'essence de l'interprétabilité du Machine Learning avec l'exemple suivant: Imaginez que vous êtes un expert en science des données et pendant votre temps libre, essayez de prédire où vos amis iront en vacances d'été sur la base de leurs données de Facebook et twitter. Donc, si les prévisions sont correctes, vos amis vous considéreront comme un sorcier qui peut voir l'avenir. Si les prévisions sont fausses, cela ne nuira à rien d'autre qu'à votre réputation d'analyste. Imaginez maintenant que ce n'était pas seulement un projet amusant, mais que des investissements y étaient attirés. Disons que vous vouliez investir dans l'immobilier où vos amis sont susceptibles de se détendre. Que se passe-t-il si les prédictions du modèle échouent? Vous perdrez de l'argent. Tant que le modèle n'a pas d'impact significatif, son interprétabilité importe peu, mais lorsqu'il y a des conséquences financières ou sociales associées aux prédictions du modèle, son interprétabilité prend un sens complètement différent.
Apprentissage automatique expliqué
Interpréter, c'est expliquer ou montrer en termes compréhensibles. Dans le contexte d'un système ML, l'interprétabilité est la capacité d'expliquer son action ou de la montrer sous une
forme lisible par l'homme .
Beaucoup de gens ont surnommé les modèles d'apprentissage automatique des «boîtes noires». Cela signifie que malgré le fait que nous pouvons obtenir des prévisions précises de leur part, nous ne pouvons pas expliquer ou comprendre clairement la logique de leur compilation. Mais comment extraire des informations du modèle? Quelles sont les choses à garder à l'esprit et de quels outils avons-nous besoin pour le faire? Ce sont des questions importantes qui viennent à l’esprit en ce qui concerne l’interprétabilité des modèles.
Importance de l'interprétabilité
La question que se posent certaines personnes est la suivante:
pourquoi ne pas simplement être heureux que nous obtenions un résultat concret du travail du modèle, pourquoi est-il si important de savoir comment telle ou telle décision a été prise? La réponse réside dans le fait que le modèle peut avoir un certain impact sur les événements ultérieurs dans le monde réel. L'interprétabilité sera beaucoup moins importante pour les modèles conçus pour recommander des films que pour les modèles utilisés pour prédire les effets d'un médicament.
"Le problème est qu'une seule métrique, telle que la précision de la classification, est une description inadéquate de la plupart des tâches du monde réel." (
Doshi Veles et Kim 2017 )
Voici une vue d'ensemble de l'apprentissage automatique explicable. Dans un sens, nous capturons le monde (ou plutôt les informations qu'il contient), collectons des données brutes et les utilisons pour de nouvelles prévisions. En substance, l'interprétabilité n'est qu'une autre couche du modèle qui aide les gens à comprendre l'ensemble du processus.
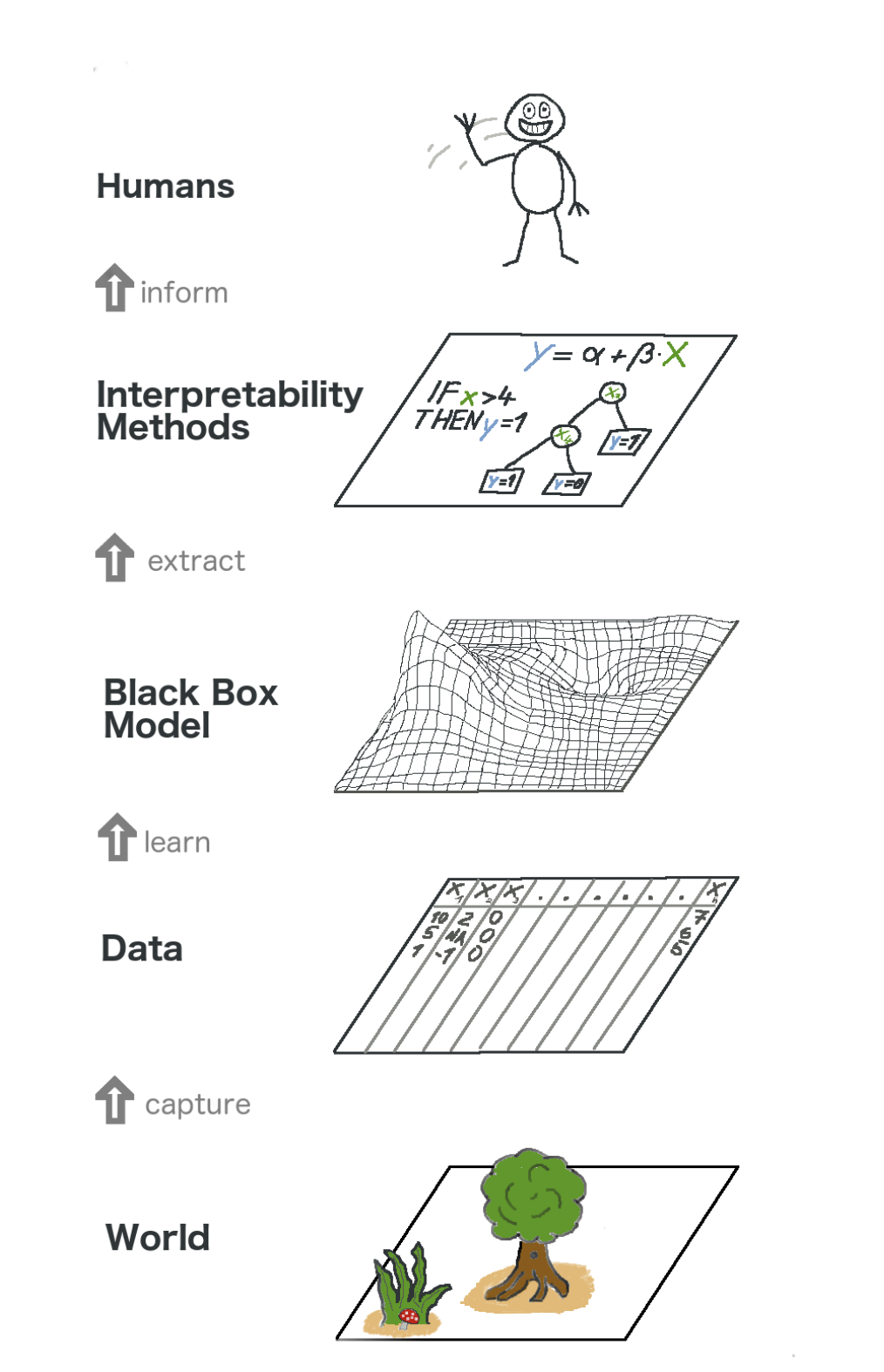 Le texte dans l'image de bas en haut: Monde -> Obtenir des informations -> Données -> Formation -> Modèle de boîte noire -> Extraire -> Méthodes d'interprétation -> Personnes
Le texte dans l'image de bas en haut: Monde -> Obtenir des informations -> Données -> Formation -> Modèle de boîte noire -> Extraire -> Méthodes d'interprétation -> PersonnesCertains des
avantages de l' interprétabilité sont les suivants:
- Fiabilité
- Commodité de débogage;
- Informations sur les fonctionnalités d'ingénierie;
- Gestion de la collecte de données pour les caractéristiques
- Information sur la prise de décision;
- Instaurer la confiance.
Méthodes d'interprétation des modèles
Une théorie n'a de sens que tant que nous pouvons la mettre en pratique. Au cas où vous voudriez vraiment traiter de ce sujet, vous pouvez essayer de suivre le cours Explication de l'apprentissage automatique de Kaggle. Vous y trouverez la corrélation correcte de la théorie et du code afin de comprendre les concepts et de pouvoir mettre en pratique les concepts d'interprétabilité (explicabilité) des modèles aux cas réels.
Cliquez sur la capture d'écran ci-dessous pour accéder directement à la page du cours. Si vous voulez d'abord avoir un aperçu du sujet, continuez à lire.
Informations pouvant être extraites des modèles
Pour comprendre le modèle, nous avons besoin des informations suivantes:
- Les caractéristiques les plus importantes du modèle;
- Pour toute prévision spécifique du modèle, l'effet de chaque attribut individuel sur une prévision spécifique.
- L'influence de chaque caractéristique sur un grand nombre de prévisions possibles.
Voyons quelques méthodes qui aident à extraire les informations ci-dessus du modèle:
Importance de la permutation
Quelles caractéristiques le modèle considère-t-il importantes? Quels symptômes ont le plus d'impact? Ce concept est appelé importance des fonctionnalités, et l'importance de la permutation est une méthode largement utilisée pour calculer l'importance des fonctionnalités. Il nous aide à voir à quel moment le modèle produit des résultats inattendus, il nous aide à montrer aux autres que notre modèle fonctionne exactement comme il se doit.
L'importance de la permutation fonctionne pour de nombreuses évaluations scikit-learn. L'idée est simple: réorganiser ou mélanger arbitrairement une colonne dans le jeu de données de validation, en laissant toutes les autres colonnes intactes. Un signe est considéré comme «important» si la précision du modèle diminue et que sa modification entraîne une augmentation des erreurs. En revanche, une fonction est considérée comme «sans importance» si le remaniement de ses valeurs n'affecte pas la précision du modèle.
Comment ça marche?
Prenons un modèle qui prédit si une équipe de football recevra ou non le prix «Homme du jeu», en fonction de certains paramètres. Ce prix est décerné au joueur qui démontre les meilleures compétences du jeu.
L'importance de la permutation est calculée après la formation du modèle. Alors,
RandomForestClassifier et préparons le modèle
RandomForestClassifier , appelé
my_model , sur les données d'entraînement.
L'importance de la permutation est calculée à l'aide de la bibliothèque
ELI5 . ELI5 est une bibliothèque en Python qui vous permet de visualiser et de déboguer divers modèles d'apprentissage automatique à l'aide d'une API unifiée. Il prend en charge plusieurs cadres ML et fournit des moyens d'interpréter le modèle de boîte noire.
Calcul et visualisation de l'importance à l'aide de la bibliothèque ELI5:
(Ici
val_X ,
val_y désignent des ensembles de validation, respectivement)
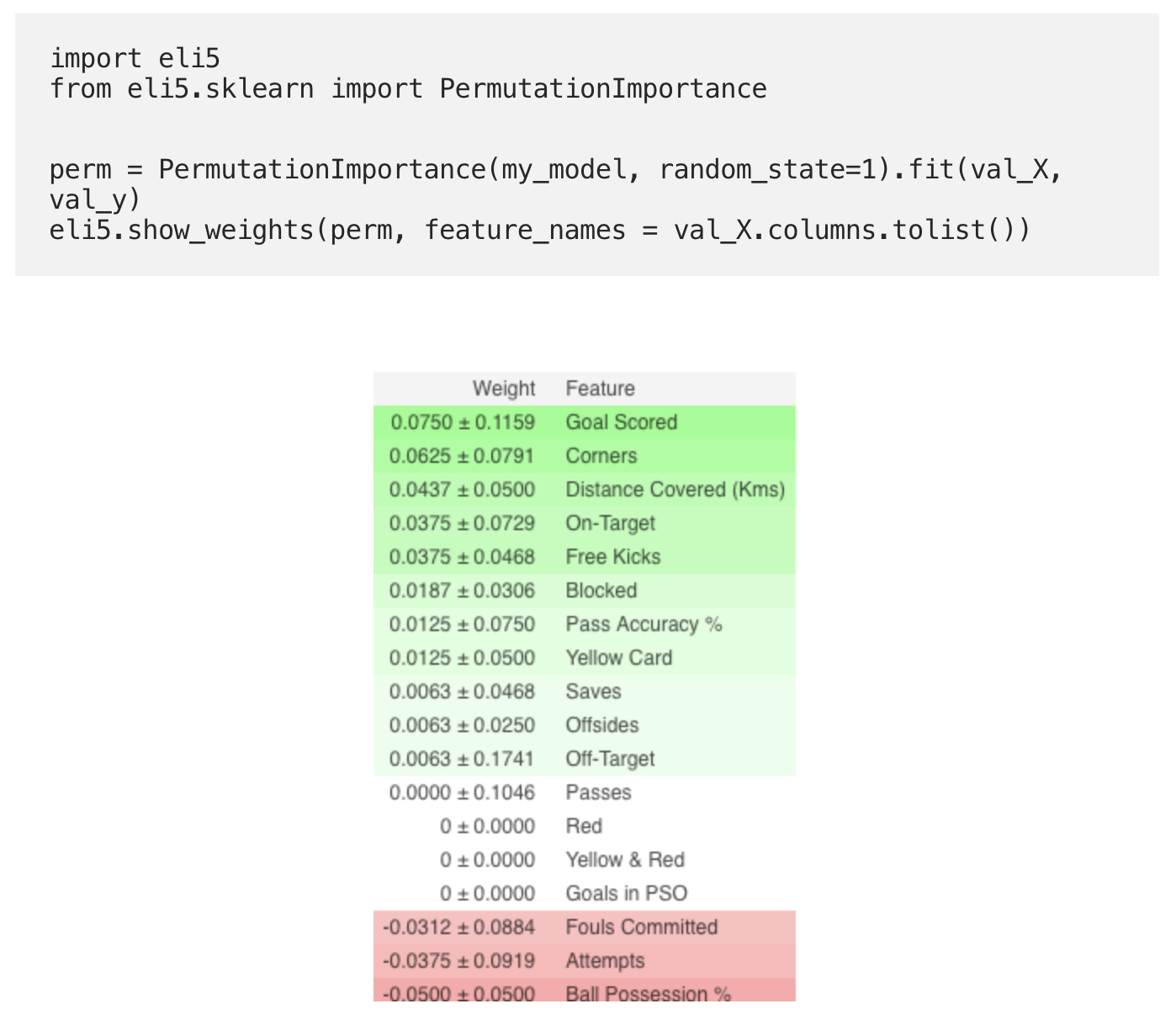
Interprétation
- Les signes ci-dessus sont les plus importants, les moins ci-dessous. Pour cet exemple, le signe le plus important était les buts marqués.
- Le nombre après ± reflète l'évolution de la productivité d'une permutation à l'autre.
- Certains poids sont négatifs. Cela est dû au fait que dans ces cas, les prévisions pour les données mélangées se sont avérées plus précises que les données réelles.
Pratique
Et maintenant, pour regarder l'exemple complet et vérifier si vous avez tout compris correctement, allez sur la page Kaggle en utilisant le
lien .
La première partie de la traduction a donc pris fin. Écrivez vos commentaires et rendez-vous sur le parcours!
Lisez la deuxième partie .