AntipovSN et MihhaCF
Deuxième partie, dans laquelle Athos a toutes les règles, mais le comte de la Fer manque quelque chose
UPD Part One est ici
UPD troisième partie ici
Introduction des auteurs:
Bon après-midi Aujourd'hui, nous continuons la série d'articles consacrés à la notation et à l'utilisation de la théorie des graphes. Vous pouvez vous familiariser avec le premier article ici .
Toutes les allégories comiques, les encarts, etc. sont conçus pour soulager légèrement le récit et ne pas le laisser tomber dans une conférence fastidieuse. Nous nous excusons auprès de tous ceux qui ne rentrent pas dans notre humour
Le but de cet article: en moins de 30 minutes, de décrire les principaux moyens de stockage des données graphiques et de décrire les règles et principes de construction de notre modèle de notation d'un emprunteur.
Termes et définitions:
- Une table de hachage est une structure de données qui implémente une interface de tableau associatif; elle vous permet de stocker des paires (clé, valeur) et d'effectuer trois opérations: l'opération d'ajout d'une nouvelle paire, l'opération de recherche et l'opération de suppression d'une paire par clé. La recherche par table de hachage, en moyenne, est effectuée pendant le temps O (1).
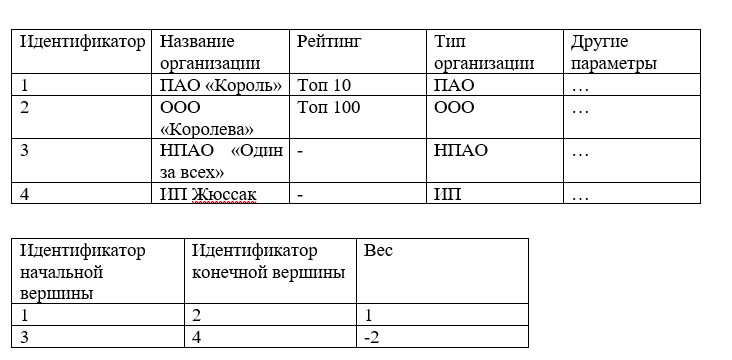
Les auditeurs embauchés par Korol PJSC pour évaluer la solvabilité de One for All NPO ont rencontré quelques problèmes. D'une part, il est très simple de décrire le schéma d'interaction de 10 à 15 entreprises et de procéder à une première évaluation de l'interaction entre les entreprises, il suffit d'avoir une feuille de papier et un stylo à portée de main. Mais que faire si vous avez des informations sur l'interaction de dizaines ou de centaines de milliers d'entreprises? Par exemple, si vous avez besoin de décrire les interactions d'Aramis avec toutes ses passions ou de D'artagnan avec tous ceux avec qui il s'est battu?
Comment stocker des données sur ces interactions?
Quelles structures de données et approches utiliser?
Les auditeurs devraient planter tout un corps d'écrivains monastiques pour ce travail.
Nous ne le ferons pas et donnerons à nos auditeurs les connaissances et les technologies du futur ( nous leur enverrons Prometheus sous la forme d'un T-800, qui leur donnera la lumière des connaissances ).
Eh bien, eh bien, commençons à répondre aux questions posées. Que la lumière soit!
Comme nous l'avons écrit et dessiné ici , un graphique est un rapport de 2 ensembles - un ensemble de nœuds et un ensemble d'arêtes. Quelle est la meilleure façon de stocker un graphique?
Avant de répondre à la question de savoir comment stocker le graphique, vous devez décider exactement ce que nous voulons stocker et sous quelle forme.
Selon la théorie des graphes, les nœuds de graphes peuvent être n'importe quel objet avec n'importe quel ensemble de paramètres (ce fait nous sera utile plus tard, pour les modèles avancés / adaptatifs pour calculer une boule de notation).
Alors, que devons-nous stocker?
Au minimum, l'identifiant du nœud et les identifiants de ses voisins (auxquels il est associé). La présence de ces données vous permet déjà de rechercher en largeur et en profondeur.
Dois-je stocker des données de bord de graphique? Oui, si nous avons affaire à un graphique pondéré. Dans notre cas, nous avons affaire à un graphique pondéré et dans le premier article, nous avons dessiné un tel graphique.
Ces informations sont-elles suffisantes? Non.
D'où venaient les côtes? Dans les manuels, ces informations sont simplement là, quelqu'un les a collectées et traitées avant nous. À notre fin du Moyen Âge (juste à l'époque où vivaient les mousquetaires), personne ne se souciait de calculer le poids des bords de notre comte. Nous devons le faire nous-mêmes. Dans cet article et dans le suivant, nous ne décrirons pas la méthodologie spécifique pour calculer le poids d'un bord; cela sera fait dans l'article 4. Maintenant, il est important pour nous de décider quelles informations sur notre graphique nous allons stocker.
Donc, dans notre cas, il y a trois paramètres clés que nous devons connaître afin de calculer correctement le score de notation:
- Une évaluation interne d'un nœud - consiste en des indicateurs caractérisant le nœud (chiffre d'affaires, dette, amendes, etc.). Dans notre exemple, ce seront:
- Évaluation - un bon ou un mauvais nœud par rapport à NPO "One for all";
- Rang du nœud - le roi a le rang le plus élevé, Bonacieux - le plus bas;
- Le volume des fonds, autrement dit la solvabilité.
- Côtes d'évaluation. Dans notre cas, l'estimation de connexion sera pour chaque nœud - cela signifie que la relation Bonacieux - Constance peut ne pas être égale à la connexion Constance - Bonacieux, car ils ont différentes possibilités de s'influencer mutuellement.
- Niveau du nœud - ne sera pas stocké, mais est un indicateur important.
Ne demandez pas d'où viennent tous ces chiffres dans le modèle, D'artanyan le voit. Dans la vraie vie, ces indicateurs ne seront pas non plus calculés par nous (échanges, dettes, amendes, etc., nous prenons des sources existantes, nous ne sommes pas au Moyen Âge, en quelque sorte).
De tout ce qui précède, il s'avère qu'en plus des identifiants des nœuds, nous devons stocker les paramètres de chaque nœud et les poids des arêtes que nous obtenons en fonction de l'agrégation des paramètres des nœuds.
Total, les informations suivantes sont sujettes au stockage:
- Nom du nœud;
- Paramètres de noeud
- Nœud de voisins;
- Poids des côtes pour chaque voisin.
Super! Nous avons compris ce que nous devons stocker. Maintenant - comment stocker.
Et encore une petite digression.
À quoi ressemblera notre processus de notation sous une forme simplifiée:
- Collecte de données d'objets;
- Formation d'un objet qui décrira le modèle graphique. C'est dans cette installation que nous effectuerons toutes nos opérations de notation.
Sur la base de ces deux étapes, nous avons trois options:
- Nous stockons des données sur l'objet de scoring sur le serveur SQL / NoSQL. Toutes les opérations liées aux calculs, algorithmes, etc. sont effectuées directement sur le serveur;
- Nous stockons des données sur l'objet de scoring sur le serveur SQL / NoSQL. Sur la base de ces données, nous créons un objet séparé (par exemple, une table de hachage) avec lequel nous effectuons tous les calculs de base;
- Les données sur l'objet de notation sont stockées dans la RAM. Sur la base de ces données, nous créons un objet séparé (par exemple, une table de hachage) avec lequel nous effectuons tous les calculs de base.
Exigences de base pour ce processus:
- Vitesse de travail;
- Fiabilité
- Vérifiabilité.
Parlons maintenant. Nous allons nous asseoir, comme nos mousquetaires autour d'une tasse de ce qu'ils y ont bu, du thé par exemple. L'essentiel est que nous ne gênions pas toutes sortes de bites avec les gardes.
Si un stockage à long terme est nécessaire, vous pouvez sélectionner une table avec les champs significatifs correspondants. En NoSQL ou en RAM, il est préférable de stocker des données sous forme de liste ou de répertoire (table de hachage) d'objets.
{ 'Id': 1, 'Title': ' ', 'Rang': 4, 'Type': '', 'Profit': 10000 }
Avec des pics plus ou moins clairs. Quelle est la meilleure façon de représenter les arcs / bords d'un graphe? Pour ce faire, vous devez comprendre le principe de base de toute opération analytique sur le graphique - l'accès à tout arc / bord doit se produire très rapidement, de préférence, le temps d'accès doit être O (1). Un tableau ou une matrice vient immédiatement à l'esprit - une structure dans laquelle n'importe quel élément est accessible rapidement par index.
[i, j] - l'élément de matrice désigne l'arc du graphe, où i est l'identifiant du sommet initial, j est l'identifiant du sommet final, l'accès et la sélection du sommet initial s'effectuent directement par l'identifiant du sommet initial. L'intersection de i et j stocke le poids du bord.
Cette vision présente plusieurs inconvénients:
- Souvent, la structure est redondante, surtout si le graphique est clairsemé (un petit nombre d'arêtes), il existe de nombreuses valeurs vides qui indiquent qu'il n'y a pas de connexion.
- Pour trouver tous les voisins du sommet, il est nécessaire de trier le tableau de tous les éléments de la ième ligne de la matrice de relations.
- Une matrice avec plusieurs colonnes ne peut pas être stockée dans la base de données.
L'option suivante pour stocker des arcs / bords est un tableau, c'est-à-dire un ensemble de colonnes et de lignes.
Par exemple:

Une telle structure peut être facilement stockée dans une base de données relationnelle et, lors de l'exécution de requêtes SQL, vous pouvez sélectionner les valeurs nécessaires, mais en ce qui concerne la RAM, la complexité de trouver tous les bords du sommet augmente et dans le cas général prend O (n) où n est le nombre de tous les bords du graphique.
Il existe une autre très bonne méthode de stockage de graphe à utiliser dans presque tous les systèmes, sans les inconvénients décrits ci-dessus - il s'agit d'une référence de valeur-clé ou d'une table de hachage. L'obtention de tous les bords du sommet souhaité se produit à la vitesse O (1).
Un inconvénient majeur est que tous les langages de programmation ne prennent pas en charge cette conception.
Comment imaginer une structure similaire dans différents systèmes?
Dans la base de données relationnelle, vous pouvez implémenter la relation des tables d'objets et d'arêtes (paragraphe précédent)
NoSQL
{ 'Id': 1, 'Title': ' ', 'Rang': 4, 'Type': '', 'Profit': 10000, 'Relations': [{3,2}, {4,5}, … {n, -5}] }
Lorsque vous accédez à un objet par sa clé, nous obtenons immédiatement un ensemble de ses connexions. Si nous avons un graphe non pondéré, au lieu d'un tableau d'objets, vous pouvez passer un tableau d'identifiants de relations voisins: [3,4, ... n]. Sous la forme d'une référence, la clé est la valeur, cette option est similaire à la précédente. Dans le répertoire, la valeur-clé, vous pouvez stocker le même objet que dans l'exemple précédent, la clé, bien sûr, sera l'identifiant du sommet (il peut y avoir un nombre, il peut y avoir une chaîne, etc., ce qui permet un système de développement particulier). De plus, dans le répertoire, vous ne pouvez stocker que des tableaux de liens et des informations sur les sommets dans un autre répertoire.
Graf[1] = { 'Id': 1, 'Title': ' ', 'Rang': 4, 'Type': '', 'Profit': 10000, 'Relations': [{3,2}, {4,5}, … {n, -5}] }
ou
graf['one_for_all'] = 'Relations': [{3,2}, {4,5}, … {n, -5}]
Pour notre exemple, nous avons choisi l'option de stockage des données dans la RAM avec la création d'une table de hachage pour la notation des données. Les résultats intermédiaires seront écrits dans un fichier sur le serveur.
Nous avons des structures de stockage mal et mal définies, il est maintenant temps de savoir par où commencer à construire notre modèle analytique. Commençons par un simple - nous définissons l'interaction avec les voisins les plus proches et avec les voisins des voisins (amis d'amis).
Ainsi, il est possible de déterminer l'interaction avec tous les sommets interconnectés. Selon nos observations, l'interaction avec des voisins plus profonds que le niveau 2 n'a d'intérêt que dans des cas particuliers et est calculée par d'autres méthodes. La complexité de ce calcul est assez grande 0 (2 ^ n).
Pour calculer la balle, nous utiliserons un algorithme de recherche en profondeur légèrement modifié.
Le raffinement sera le suivant:
- Nous devons trouver non pas un sommet spécifique, mais trier tous les sommets à une profondeur de n, pour notre tâche n = 2.
- Nous ne devons pas stocker d'informations inutiles et supposer que le calcul peut être effectué pour n'importe quel nœud du graphique, de sorte que le niveau du nœud ne sera pas stocké dans le graphique.
- Si 2 chemins ou plus mènent au sommet, tous les chemins sont évalués, car nous avons affaire à des communications bidirectionnelles et il est nécessaire d'évaluer pleinement l'interaction des nœuds.
- Vous devez être en mesure de déterminer le niveau d'imbrication de n'importe quel sommet pour un calcul spécifique.
Eh bien, eh bien, les calculs théoriques de base ont été faits, même s'ils semblent à quelqu'un quelque chose de simple et de banal. Mais pour nous Gascons, tout cela est important et intéressant, presque comme entrer dans les Mousquetaires royaux.
Nous passons à la mise en œuvre pratique. Un pour tous et tous pour un!
Je te retrouve! Nous nous rencontrerons certainement! Peut-être dans 10 ou 20 ans! Mais rencontrez!
Le prochain article est proche!