
Dans un
article précédent
, j'ai raconté un bref historique du développement des produits internes et externes de DublGIS. Aujourd'hui, nous plongeons dans les détails du développement d'un des produits, à savoir l'exportation de données. Je parlerai de l'architecture du projet et des solutions techniques individuelles qui nous ont permis de développer progressivement le projet et de l'adapter à l'évolution des exigences au fil du temps.
Un bref résumé du dernier article
Il existe plusieurs produits internes qui collectent de grandes quantités de données cartographiques, un répertoire d'organisations, de la publicité, des commentaires des utilisateurs, des critiques, des photos, diverses analyses. Ces produits communiquent entre eux via le bus de données ou via Rest Api. Et il existe un processus d'exportation distinct qui collecte toutes ces données dans un tas, les traite et les décompose au format souhaité, emballe et forme un «bundle» prêt à l'emploi pour la livraison à ses produits finaux. La livraison a lieu soit via le serveur de mise à jour pour les versions PC et mobile, soit dans le backend en ligne pour, en fait, la version en ligne de 2GIS.
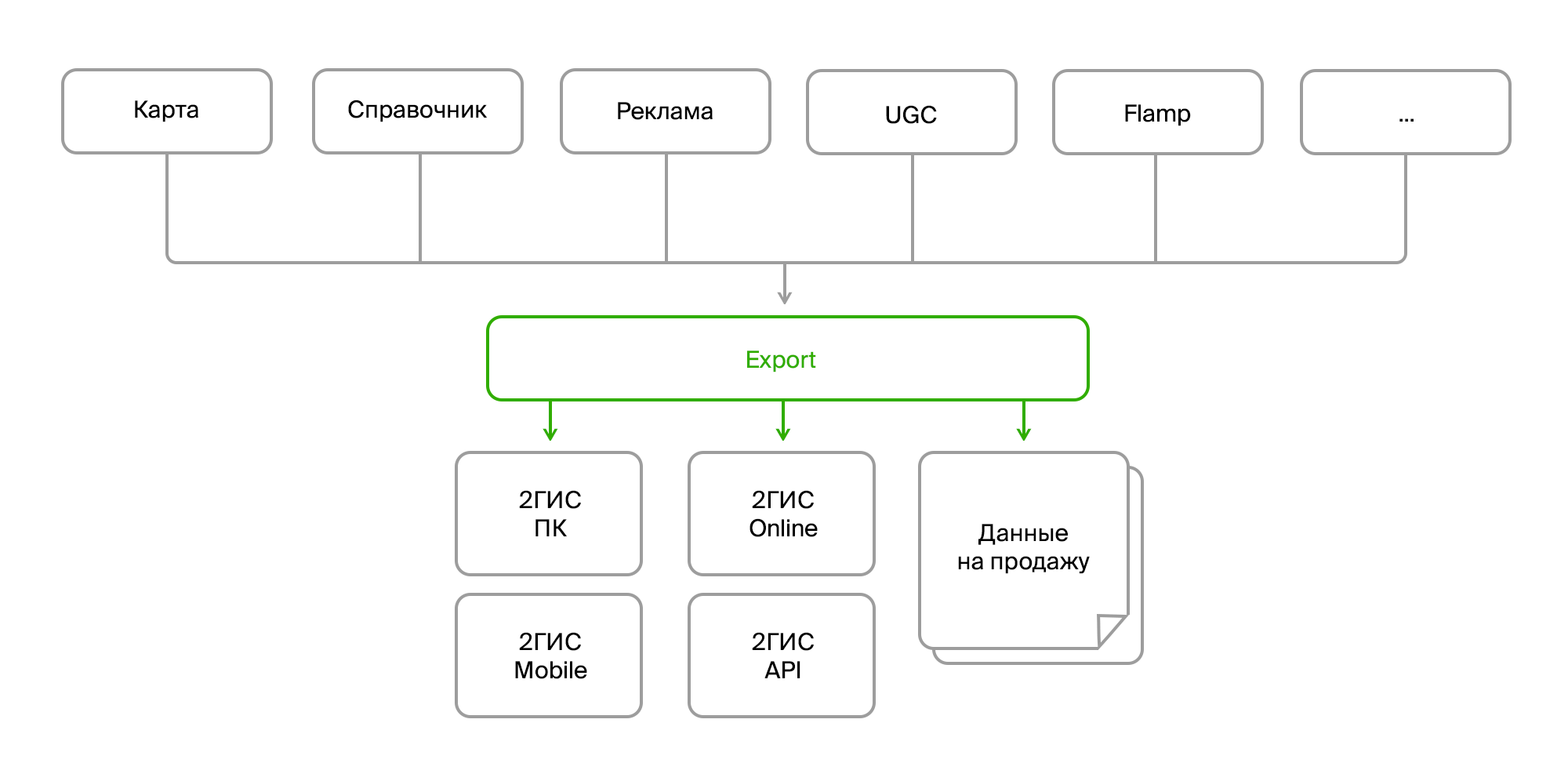
Données source
Donc, à l'entrée, nous avons:
- plusieurs sources des mêmes données;
- différentes méthodes de livraison (Firebird, bus, FTP, RestAPI);
- structure différente des mêmes objets;
- des changements constants dans la structure des données;
- différents formats (données brutes dans la base de données, XML, JSON).
Du point de vue du consommateur:
- encore une fois, différents formats (leurs formats de données pour différentes versions du produit, des formats distincts pour la vente);
- changements de format constants;
- des données agrégées (vous devez combiner différents objets en un seul, collecter des données sur l'entreprise dans toutes les succursales, les compléter avec des liens vers des photos, des avis, des arrêts les plus proches, etc.);
- pré et post-traitement complexes (mise à jour de certaines données sur la base d'autres, conversion de données, génération de données manquantes, par exemple, organisation de mini-logos publicitaires sur des bâtiments, suppression ou correction de données erronées);
- exigences de cohérence et de validité des données;
- TOUTES les données sont nécessaires.
Ici, il convient de se concentrer sur le dernier paragraphe. Comme vous le savez, la principale caractéristique de 2GIS est le travail hors ligne. Autrement dit, la plupart des données que vous voyez dans nos versions PC et mobile se trouvent sur votre appareil. Mais il s'agit d'un vaste éventail: des centaines de milliers d'objets géo (mers, forêts, rivières, routes, bâtiments, entrées, porches, signatures, plans d'étage, modèles 3D), des dizaines et des centaines de milliers d'entreprises et leurs succursales avec contacts, heures de travail, attributs supplémentaires comme la facture moyenne et la disponibilité du Wi-Fi. Et, bien sûr, des textes publicitaires et des photos.
Et tout est en constante évolution, ajouté, supprimé.
Et pour ne pas se noyer dans ce flot incessant de changements, lors du développement de l'architecture d'exportation, nous avons dû nous concentrer sur plusieurs domaines principaux:
- sources de données;
- méthodes de livraison;
- algorithmes de traitement;
- formats de données des consommateurs.
Nous résumons à partir de différentes sources et formats de données
Différentes sources introduisent les difficultés suivantes:
- ils donnent les mêmes données dans différents formats;
- ont un ensemble différent d'entités ou d'attributs qui doivent être réduits à un seul objet de domaine.
Il s'agit d'un problème assez standard et il est résolu en standard. Nous avons juste besoin de créer une interface pour recevoir des données, et une implémentation spécifique va déjà là où elle est nécessaire et obtiendra les données sous la forme dont nous avons besoin.

Exemple d'interface:
public interface ISource : IDisposable { ISourceReader GetDeletedRows(); ISourceReader GetInsertedOrUpdatedRows(); byte[] GetDataVersion(); } public interface ISourceReader : IDisposable { bool Read(); object this[string columnName] { get; } }
Un exemple de mise en œuvre de l'obtention d'entreprises:
internal class FirmSetSource : ISource { public ISourceReader GetDeletedRows() { if(_lastDataVersion == null) return null; var query = DataContext.ExecuteObject<EsbFirmDeleted>(_lastDataVersion); return new DeletedIdsSourceReader<long>( query.Select(x => x.Id).GetEnumerator()); } public ISourceReader GetInsertedOrUpdatedRows() { return new EnumeratorSourceReader(typeof(FirmSet), GetNewOrChangedRows().GetEnumerator()); } public virtual byte[] GetDataVersion() { return DataContext.ExecuteObject<EsbFirm>().Max(x => x.RowVersion); } }
Cette abstraction nous permet en partie de résoudre le problème avec des différences dans le modèle de domaine, mais pas complètement. Une limitation importante est la nécessité de recevoir des données de manière incrémentielle, c'est-à-dire de ne recevoir que leurs mises à jour, et de ne pas aspirer le tout à chaque fois. Dans ce cas, il est plutôt gênant de suivre la relation entre les données afin de collecter certains agrégats. Et il est relativement difficile de tout faire sans erreurs. Par conséquent, nous avons décidé qu'à ce stade, nous allons extraire les données des sources une à une, et nous allons résoudre le problème avec le modèle de domaine à un niveau différent.
Modèle de domaine
Afin de ne pas dépendre des modifications de l'ensemble de données et de leur structure dans les sources de données, la base de données d'exportation a été réalisée avec une liste de tableaux relativement stable, qui est finalement tombée sur notre domaine. Si la source 1 manquait d'attributs pour l'entité A (objet de données dans l'image suivante), alors ils ont reçu une valeur par défaut ou étaient facultatifs. Et si l'entité B était une sorte d'agrégat de données sources ou même de sources différentes, alors chaque partie pourrait être obtenue séparément et ensuite assemblée dans son ensemble à l'étape suivante.

Nous abstenons de la méthode de livraison des données
En fait, avoir votre propre base de données dans l'exportation et l'apparence de l'interface
ISourceReader résolvent déjà ce problème. Mais il y a un point non résolu: des modèles d'acquisition de données légèrement différents. Dans un cas, nous tirons et obtenons un instantané au moment actuel, dans l'autre - deltas de changements sur le bus, dans le troisième - également le statut actuel au moment de la demande, mais avec des informations sur les objets supprimés au moment de la demande précédente.
Pour uniformiser ce zoo, nous ajouterons une base de données supplémentaire à laquelle nous fusionnerons toutes les données de toutes les sources.
Vous obtenez une telle image.
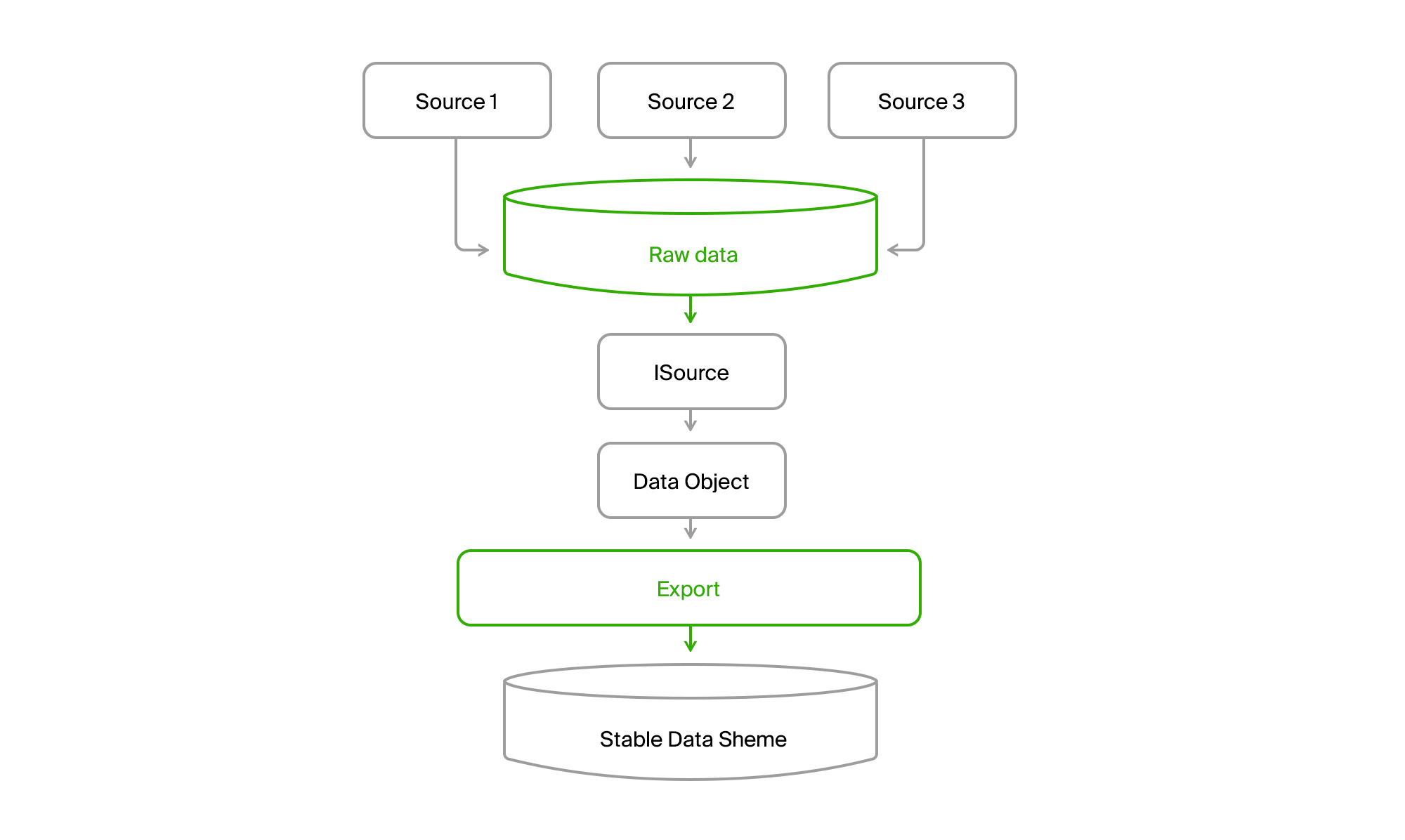
En conséquence, nous lisons toutes les données de n'importe quel canal dans toutes les villes vers la base de données centrale. La livraison est presque toujours incrémentielle, c'est-à-dire que seuls des changements surviennent. L'ancien DGPP, de son vivant, est resté une source alternative. Il était possible de pomper des données d'un SGBD vers un autre.
En outre, l'exportation via ISource a extrait les données de la ville de DGPP ou EMDB dans sa base de données de synchronisation stable et les a converties en son modèle de domaine.
Il ne reste plus alors qu'à les traiter et à les télécharger dans des formats grand public.
Résumé des algorithmes de préparation des données
Et ici, une difficulté supplémentaire se pose. Premièrement, différents consommateurs veulent des données dans leurs formats. De plus, ils veulent des ensembles de données différents. Et dans l'appendice, les données hors ligne doivent être aussi compactes et structurées que possible afin de pouvoir être lues rapidement. En conséquence, nous obtenons des formats binaires qui sont développés par les équipes de produits finaux. Et ce sont des gars qui travaillent sur une pile technologique complètement différente. Nous avons le familier et le bien-aimé pour développer le backend .NET et parfois Java, ils ont principalement C ++ et python.
En général, un zoo de technologie.
À l'aube d'un développement rapide, alors que nous n'avions que DGPP (voir l'
article précédent) et la version PC de 2GIS, le format des données finales était un binaire, qui a été préparé par une bibliothèque spéciale écrite en C ++ et enveloppé dans un objet COM. Il semblerait que non l'intégration de code hétérogène. Nous connectons la référence, l'interface .NET est générée - et la pilotons. Et la première fois que nous l'avons fait.
Mais, comme d'habitude, quelques problèmes sont apparus.
- Nos données ont commencé à croître rapidement. De nouveaux types de données sont apparus, de nouvelles grandes villes comme Moscou.
- Les systèmes d'exploitation X64 bits ont commencé à se diffuser activement.
- Les problèmes dans COM devaient être débogués d'une manière ou d'une autre.
Passons en revue les points.
La croissance des données dont nos produits ont absolument besoin a conduit au fait que leur traitement a commencé à consommer une grande quantité de RAM. Et après avoir connecté la bibliothèque COM à notre processus .NET x86, nous avons automatiquement reçu le processus x86, c'est-à-dire un maximum d'agents 3Gb avec un espace d'adressage accru. Les équipes ne prenaient pas en charge la bibliothèque pour les ressources x64, mais la bibliothèque elle-même avait la possibilité d'utiliser le disque au lieu de la mémoire, ce qui a quelque peu atténué le problème.
Mais le débogage était toujours très difficile. Il fallait commencer l'exportation, attendre qu'elle prépare les données, commencer à ajouter ces données à la bibliothèque. Et après l'apparition de l'erreur, vous devez comprendre dans les journaux ce qui s'est mal passé et recommencer le processus. Pas bon, très mauvais.
La solution est comme d'habitude en surface. Il suffit de prendre tout le code étranger dans un processus séparé et d'établir une communication via des fichiers intermédiaires dans un format binaire ou texte simple.
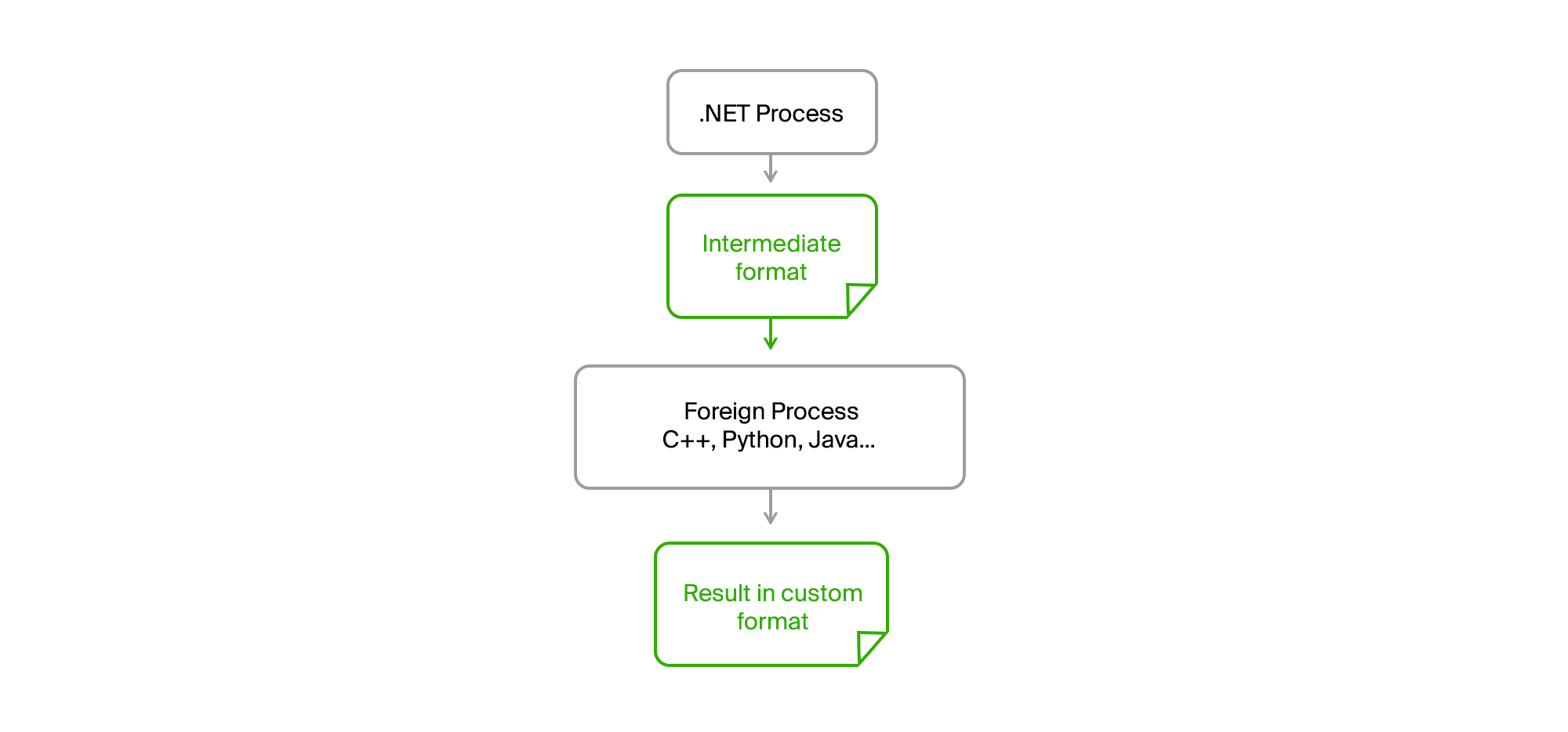
En conséquence, notre processus .NET d'origine est devenu complètement n'importe quel processeur. Aucune fuite de mémoire ou erreur critique dans le code tiers ne l'a plus affecté. L'exportation a préparé les données, les a téléchargées dans un fichier intermédiaire, les a transmises à l'utilitaire et en a également reçu le résultat sous forme de fichier. Les gars des équipes tierces ont écrit leurs algorithmes dans leurs langages (C ++ ou Python) et pouvaient les déboguer sur des données réelles en cas d'erreurs sur leur machine sans avoir besoin de commencer à exporter.
Nous n'avions qu'à conclure des accords sur l'interface utilitaire, qui étaient fournis avec le runtime, avaient une liste convenue de paramètres requis, et affichaient des messages d'information et des erreurs dans stdout dans le format requis.
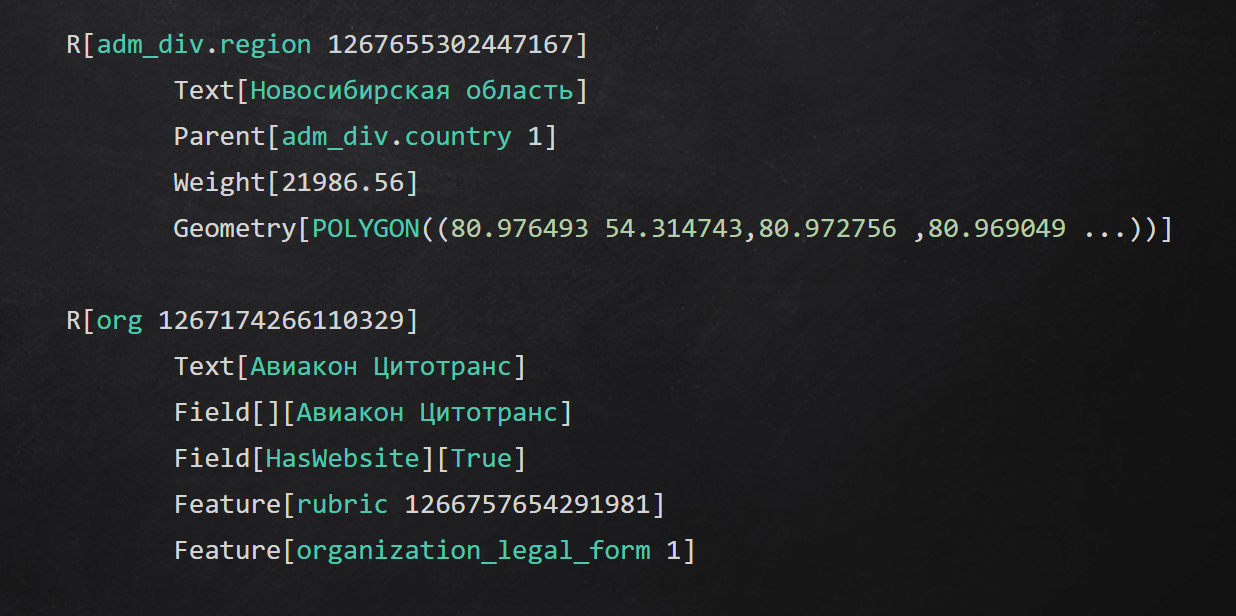 Exemple de format de texte intermédiaire
Exemple de format de texte intermédiaireRésumé
Dans l'article, j'ai parlé de certaines approches que nous avons utilisées à différents niveaux de l'application pour isoler le processus de préparation des données:
- caché les détails de l'accès aux sources de données derrière les interfaces;
- extrait des canaux de transmission de données en utilisant un stockage intermédiaire;
- créez votre domaine stable et convertissez-y les données d'origine;
- effectué des étapes individuelles de traitement des données dans des processus et utilisé le code dans d'autres langues.
Merci d'être arrivé au bout. Je répondrai à toutes les questions dans les commentaires, n'oubliez pas de poser.