Cet article décrit le processus d'analyse de la phrase de la langue russe en utilisant la grammaire sans contexte et l'algorithme d'analyse LR.
Le traitement du langage naturel est la direction générale de l'intelligence artificielle et de la linguistique mathématique. Il étudie les problèmes d'analyse informatique et de synthèse des langages naturels.
En général, le processus d'analyse des phrases en langage naturel est le suivant: (1) la division des phrases en unités syntaxiques - mots et phrases; (2) détermination des paramètres grammaticaux de chaque unité; (3) la définition de la relation syntaxique entre les unités. La sortie est un arbre d'analyse abstrait.
1. Diviser les phrases en unités syntaxiques
Une phrase en langage naturel se compose de formes de mots et de phrases fortes. Un certain nombre de formes de mots d'un mot donné est appelé un paradigme.
Par exemple
"": [, , , , , ]
Les phrases - conjonctions composées, prédicats ou expressions stables - ne changent pas et ne peuvent pas être décomposées en unités plus petites sans perte de sens. De plus, par un mot, nous entendons toute unité syntaxique - une forme de mot ou une phrase.
Chaque mot d'une phrase est déterminé par un triple:
- forme des mots / chaîne de mots («écrit»)
- forme normale du mot ("écrire")
- un ensemble de paramètres grammaticaux (['VERBE', 'chanter', 'musc', 'tran', 'passé'])
Ainsi, la répartition de la phrase "
Clairement, il ne viendra pas à la réunion " sera la suivante:
[' ', '', '', '', '', ''] ' ' - ,
2. Définition des paramètres grammaticaux (grammaires)
Un gramme est un élément d'une catégorie grammaticale; différents grammes de la même catégorie s'excluent mutuellement et ne peuvent être exprimés ensemble. Pour chaque forme de mot, nous définissons un ensemble de sept grammes:
[ , , , , , , ]
Comme source, nous utiliserons le dictionnaire
OpenCorpora et son interface,
pymorphy2 . Pour rechercher une règle dans la grammaire pour un ensemble de grammes donné, nous les présenterons sous forme générale:
'' [NOUN,plur,neut,accs] -> [NOUN,?numb,?per,?gend,accs,None,None] '?' ,
3. Définition de la relation syntaxique entre les mots
Pour déterminer la relation syntaxique entre les mots, nous utiliserons la grammaire hors contexte et l'analyse LR.
Grammaire et analyse LR
La grammaire formelle est une façon de décrire une langue sous la forme de productions dites. Par exemple:
a -> ab | ac
signifie la règle 'a' engendre 'ab' OU 'ac'.
Les non-terminaux sont des objets qui dénotent n'importe quelle essence du langage (phrase, formule, etc.).
Terminaux - objets directement présents dans la langue correspondant à la grammaire et ayant une signification spécifique et immuable (lettres, mots, formules, etc.). Les grammaires sans contexte sont des grammaires dans lesquelles les côtés gauche de tous les produits sont des non-terminaux uniques.
Pour décrire la langue russe, nous utiliserons la théorie de la grammaire des composants (
grammaire de structure de phrases ), qui prétend que toute unité grammaticale complexe se compose de deux unités plus simples et sans intersection, appelées ses composantes immédiates. Les composants suivants sont distingués:
(1) Groupe nominal (NP) NP[case='nomn'] -> N[case='nomn'] | ADJ[case='nomn'] NP[case='nomn'] | …
C'est-à-dire qu'une expression nominale nominative est un substantif dans le cas nominatif OU un adjectif dans le cas nominatif + une expression nominale nominative OU une autre.
(2) Groupe verbal (VP) VP[tran] -> V[tran] NP[case='ablt'] | ADJ VP[tran] | …
En d'autres termes, un groupe de verbes transitifs est un verbe transitif + un groupe de noms ablatifs OU un adjectif court + un groupe de verbes transitifs OU un autre.
(3) Groupe prépositionnel (PP) PP -> PREP NP[case='datv'] | ...
Un groupe prépositionnel est une préposition + un groupe datif nominal OU un autre.
(4) Offre complète (S) S -> NP[case='nomn'] VP[tran]
Une phrase complète existe si et seulement si les groupes de noms et de verbes sont appariés en nombre, personne et sexe.
def agreement(self, node_left, node_right): ... if (numb1 and numb2): if (numb1 != numb2): return False; if (per1 and per2): if (per1 != per2): return False; if (gend1 and gend2): if (gend1 != gend2): return False; return True;
Une phrase incomplète est une phrase où la partie nominale est omise. En règle générale, dans de telles phrases, le groupe de verbes est exprimé par un verbe impersonnel. Par exemple, «
je veux marcher », «il fait
jour ». Une phrase elliptique est une phrase où la partie verbale est omise, elle est remplacée par un tiret. Par exemple, "
Derrière le dos est une forêt. À droite et à gauche se trouvent des marécages ."
Afin de déterminer si cette phrase appartient au langage grammatical, nous utiliserons l'algorithme d'analyse LR. Cet algorithme implique la construction d'un arbre d'analyse de bas en haut (des feuilles à la racine). L'élément clé de l'algorithme est la méthode de "transfert-convolution" (anglais
shift-réduire ):
(1) nous lisons les caractères de la ligne d'entrée jusqu'à ce qu'il y ait une chaîne qui correspond au côté droit de certaines des règles, mettons la chaîne trouvée dans la pile (transfert);
(2) remplacer la chaîne trouvée par la règle de la grammaire (convolution).
Si toutes les chaînes de chaînes ont été encapsulées, cette phrase appartient au langage de grammaire et il existe au moins un arbre d'analyse.
ArbrePour représenter la connexion syntaxique, la phrase utilise un arbre binaire, où les feuilles sont des mots (terminaux) avec un ensemble de grammes, et les nœuds sont des règles (pré-terminaux). La racine est la phrase (non terminale).
Un nœud d'arbre est défini comme suit:
class Node: def __init__(self, word=None, tag=None, grammemes=None, leaf=False): self.word = word;
La construction d'un arbre commence par les feuilles, auxquelles on assigne une chaîne de mots ou de phrases, ainsi qu'un ensemble de ses grammes.
def build(self, sent): for word in sent: new_node = Node(word[0], word[1], word[2], leaf=True) self.nodes.append(new_node)
Ensuite, l'analyse LR est effectuée. Chaque convolution correspond à l'union de deux nœuds ou feuilles sous un ancêtre commun. Un nœud ancêtre se voit attribuer une balise pré-terminale qui correspond à la règle de grammaire, en outre, l'ancêtre accepte les grammaires du membre principal du groupe, par exemple, dans le groupe de verbes V [tran] PRCL (par exemple
"aimerait" ) les signes seront tirés du verbe transitif V [tran], et pas d'une particule de PRCL; et dans le groupe de noms NP [case = 'nomn'] NP [case = 'gent'] (par exemple
"père d'enfants" ), les signes seront tirés du nom dans le nominatif.
Il est important de noter que la convolution se produit dans l'ordre établi:
def reduce(self): self.reduce_ADJ() # self.reduce_NP() # self.reduce_PP() # self.reduce_VP() # self.reduce_S() #
Cet ordre est important car il exclut la possibilité de «rater» certains membres de la proposition. Tout d'abord, les adjectifs sont formés avec des modificateurs (par exemple
incroyablement beaux ), puis des groupes nominaux, prépositionnels et enfin verbaux. Après cela, il y a une recherche de phrases complètes / incomplètes, s'il n'y en a pas, alors l'arbre n'a pas de racine, et donc la phrase n'appartient pas au langage de grammaire.
Prenons un exemple conditionnel de construction d'un arbre:
sent = " " def build(self, sent): for word in sent: new_node = Node(word[0], word[1], word[2], leaf=True) self.nodes.append(new_node)

NP[case='nomn'] -> NPRO[case='nomn'] NP[case='accs'] -> N[case='accs'] NP[case='datv'] -> ADJ[case='datv'] NP[case='datv']

VP[tran] -> V[tran] NP[case='accs']

VP[tran] -> VP[tran] NP[case='datv']

S -> NP[case='nomn'] VP[tran]
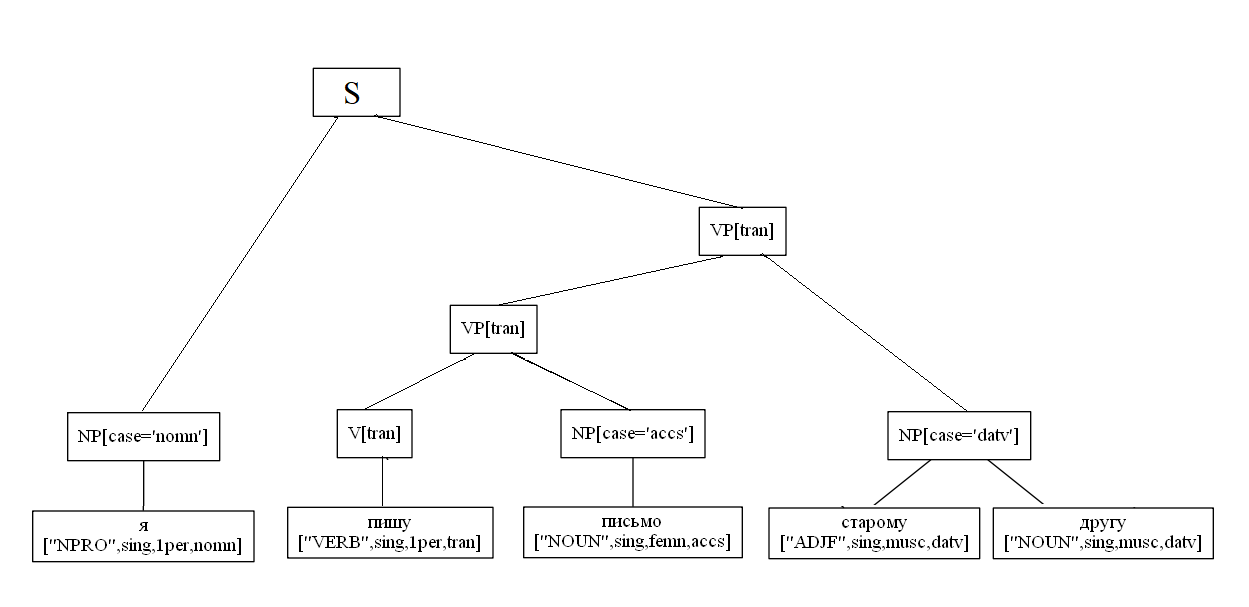
Un exemple spécifique d'analyse d'une phrase en deux parties:
import analyzer parser = analyzer.Parser() sent = " , ." t = parser.parse(sent) t[0].display() S NP[case='nomn'] ['NOUN', 'sing', 'femn', 'nomn'] VP[tran] VP[tran] ['VERB', 'sing', '3per', 'tran', 'pres'] NP[case='datv'] ['NOUN', 'sing', 'datv'] S NP[case='nomn'] ['NOUN', 'sing', 'femn', 'nomn'] VP[tran] PP PREP ['PREP'] NP[case='ablt'] ['NOUN', 'sing', 'femn', 'ablt'] VP[tran] ['VERB', 'sing', '3per', 'tran', 'pres']
Les problèmes
Le langage naturel est ambigu, sa compréhension dépend d'un certain nombre de facteurs - des caractéristiques de la structure grammaticale de la langue, de la culture nationale, du locuteur, etc. Nous listons les principaux problèmes du traitement en langage machine.
- Divulgation de l'anaphore. Une personne vivante comprend une anaphore basée sur le bon sens et le contexte, mais pour un ordinateur, ce n'est évidemment pas toujours facile.
- L'homonymie est une coïncidence dans le son et l'orthographe des unités linguistiques dont les significations ne sont pas liées les unes aux autres. Une solution est les méthodes probabilistes. Dans la phrase « Je le sais bien », la probabilité que « ceci » soit un pronom et non une particule sera plus grande. De telles méthodes nécessitent une enceinte suffisamment grande.
- L'ordre libre des mots conduit au fait que l'interprétation de la phrase peut être ambiguë. Par exemple, «L' être détermine la conscience » - qu'est-ce qui détermine quoi? En russe, l'ordre des mots libres est compensé par une morphologie développée, des mots de service et des signes de ponctuation, mais dans la plupart des cas pour l'ordinateur, cela pose un problème supplémentaire.
- Tout le monde n'écrit pas correctement. Sur le net, les gens ont tendance à utiliser des abréviations, des néologismes, des ellipses et d'autres choses qui peuvent contredire la norme littéraire. Pour cette raison, l'utilisation de grammaires et de dictionnaires sans contexte n'est pas toujours possible.
Conclusion
Le projet
est disponible pour utilisation et modification. Il contient l'analyseur lui-même, l'arbre d'analyse, ainsi que la grammaire russe et la grammaire de la langue russe et un petit dictionnaire des unions composées et des prédicats qui ne sont pas dans le dictionnaire OpenCorpora. À l'heure actuelle, pour les phrases longues et complexes, l'analyseur peut trouver 3 arbres ou plus, pour résoudre ce problème, des modifications sont apportées à la grammaire, et il est également prévu d'utiliser des méthodes probabilistes.