Bonjour à tous! Nous publions une traduction de l'article préparé pour les étudiants du nouveau groupe du cours Data Engineer . Si vous êtes intéressé à apprendre à construire un système de traitement de données efficace et évolutif à un coût minimal, consultez l' enregistrement de la master class par Egor Mateshuk!

Il y a quelques semaines, j'ai écrit un article sur Hadoop, qui couvrait divers
pièces et compris quel rôle il joue dans le domaine de l'ingénierie des données. Dans cet article, je
Je vais donner une brève description des différents formats de fichiers dans Hadoop. C'est simple et rapide
sujet. Si vous essayez de comprendre comment Hadoop fonctionne et quelle place il prend dans le travail
Ingénieur de données, consultez mon article sur Hadoop ici .
Les formats de fichiers Hadoop sont divisés en deux catégories: orientés lignes et colonnes
orienté.
Orienté vers les lignes:
Des rangées de données d'un type sont stockées ensemble, formant un
stockage: SequenceFile, MapFile, Avro Datafile. Ainsi, si nécessaire
accéder à une petite quantité de données à partir d'une ligne, de toute façon toute la ligne
sera lu en mémoire. Les retards de sérialisation peuvent dans une certaine mesure
atténuer le problème, mais complètement de la surcharge de lecture de la ligne de données entière avec
le lecteur ne pourra pas se débarrasser. Stockage orienté ligne
convient dans les cas où il est nécessaire de traiter la ligne entière en même temps
les données.
Orienté colonne:
Le fichier entier est divisé en plusieurs colonnes de données et toutes les colonnes de données
stockés ensemble: Parquet, RCFile, ORCFile. Format orienté colonne (colonne-
orienté), vous permet de sauter les colonnes inutiles lors de la lecture des données, ce qui convient
situations où une petite quantité de lignes est nécessaire. Mais ce format de lecture et d'écriture
nécessite plus d'espace mémoire car toute la ligne de cache doit être en mémoire
(pour obtenir une colonne de plusieurs lignes). En même temps, il ne convient pas
enregistrement en continu, car après un échec d'enregistrement, le fichier actuel ne peut pas être
les données restaurées et orientées linéairement peuvent être réutilisées
synchronisé à partir du dernier point de synchronisation en cas d'erreur d'écriture, par conséquent,
par exemple, Flume utilise un format de stockage orienté ligne.

Figure 1 (à gauche). Tableau logique illustré
Figure 2 (à droite). Emplacement orienté ligne (fichier de séquence)

Figure 3. Disposition orientée colonne
Si vous n'avez pas encore complètement compris l'orientation des colonnes ou des lignes,
ne t'inquiète pas. Vous pouvez suivre ce lien pour comprendre la différence entre les deux.
Voici quelques formats de fichiers largement utilisés dans le système Hadoop:
Fichier de séquence
Le format de stockage change selon que le stockage est compressé,
Utilise-t-il la compression d'écriture ou la compression de bloc:

Figure 4. La structure interne du fichier de séquence sans compression et avec compression des enregistrements.
Sans compression:
Stockage dans l'ordre correspondant à la longueur d'enregistrement, la longueur de clé, la valeur de degré,
Valeur de clé et valeur de valeur. La plage est le nombre d'octets. Sérialisation
effectuée en utilisant le spécifié.
Compression d'enregistrement:
Seule la valeur est compressée et le codec compressé est stocké dans l'en-tête.
Compression de bloc:
Plusieurs enregistrements sont compressés afin que vous puissiez utiliser
profitez des similitudes entre les deux entrées et économisez de l'espace. Drapeaux
des synchronisations sont ajoutées au début et à la fin du bloc. Valeur de bloc minimale
défini par l'attribut o.seqfile.compress.blocksizeset.

Figure 4. La structure interne du fichier de séquence avec compression de bloc.
Fichier de carte
Un fichier de mappage est un type de fichier de séquence. Après avoir ajouté l'index à
le fichier de séquence et son tri se traduisent par un fichier de carte. L'index est stocké en tant que
fichier, qui contient généralement les indices de chacune des 128 entrées. Les indices peuvent être
chargé en mémoire pour une récupération rapide, car les fichiers dans lesquels les données sont stockées,
organisé dans l'ordre spécifié par la clé.
Les entrées du fichier de carte doivent être en ordre. Sinon, nous
obtenir une IOException.
Types de fichiers de carte dérivés:
- SetFile: un fichier de carte spécial pour stocker une séquence de clés du type
Inscriptible Les clés sont écrites dans un ordre spécifique. - ArrayFile: la clé est un entier indiquant la position dans le tableau, valeur
type Inscriptible. - BloomMapFile: optimisé pour la méthode get () d'un fichier de carte en utilisant
filtres Bloom dynamiques. Le filtre est stocké en mémoire, et la méthode habituelle
get () est appelée en lecture uniquement si la valeur de clé
existe.
Les fichiers répertoriés ci-dessous sur le système Hadoop incluent RCFile, ORCFile et Parquet.
La version orientée colonne d'Avro est Trevni.
Fichier RC
Fichier de colonnes d'enregistrement de la ruche - ce type de fichier divise d'abord les données en groupes de lignes,
et dans un groupe de lignes, les données sont stockées dans des colonnes. Sa structure est la suivante
façon:

Figure 5. Emplacement des données du fichier RC dans un bloc HDFS.
Comparez avec purement orienté ligne et colonne:
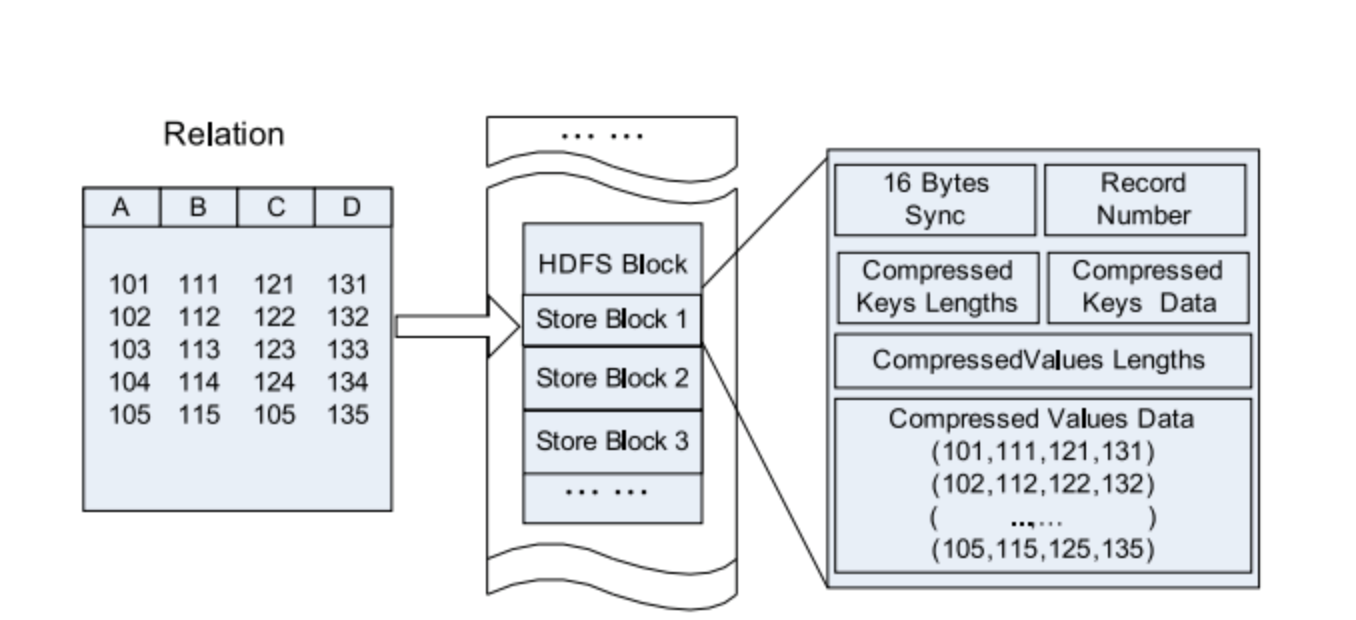
Figure 6. Stockage ligne par ligne dans le bloc HDFS.

Figure 7. Regroupement par colonnes dans un bloc HDFS.
Fichier ORC
ORCFile (Optimized Record Columnar File) - est un format plus efficace
fichier que rcfile. Il divise les données en interne en bandes de 250 millions chacune.
Chaque voie a un index, des données et un pied de page. L'index stocke le minimum et
la valeur maximale de chaque colonne, ainsi que la position de chaque ligne dans la colonne.

Figure 8. Emplacement des données dans le fichier ORC
Hive utilise les commandes suivantes pour utiliser le fichier .orc:
Parquet
Format de stockage générique orienté colonne basé sur Google Dremel.
Particulièrement bon pour le traitement de données avec un haut degré d'imbrication.
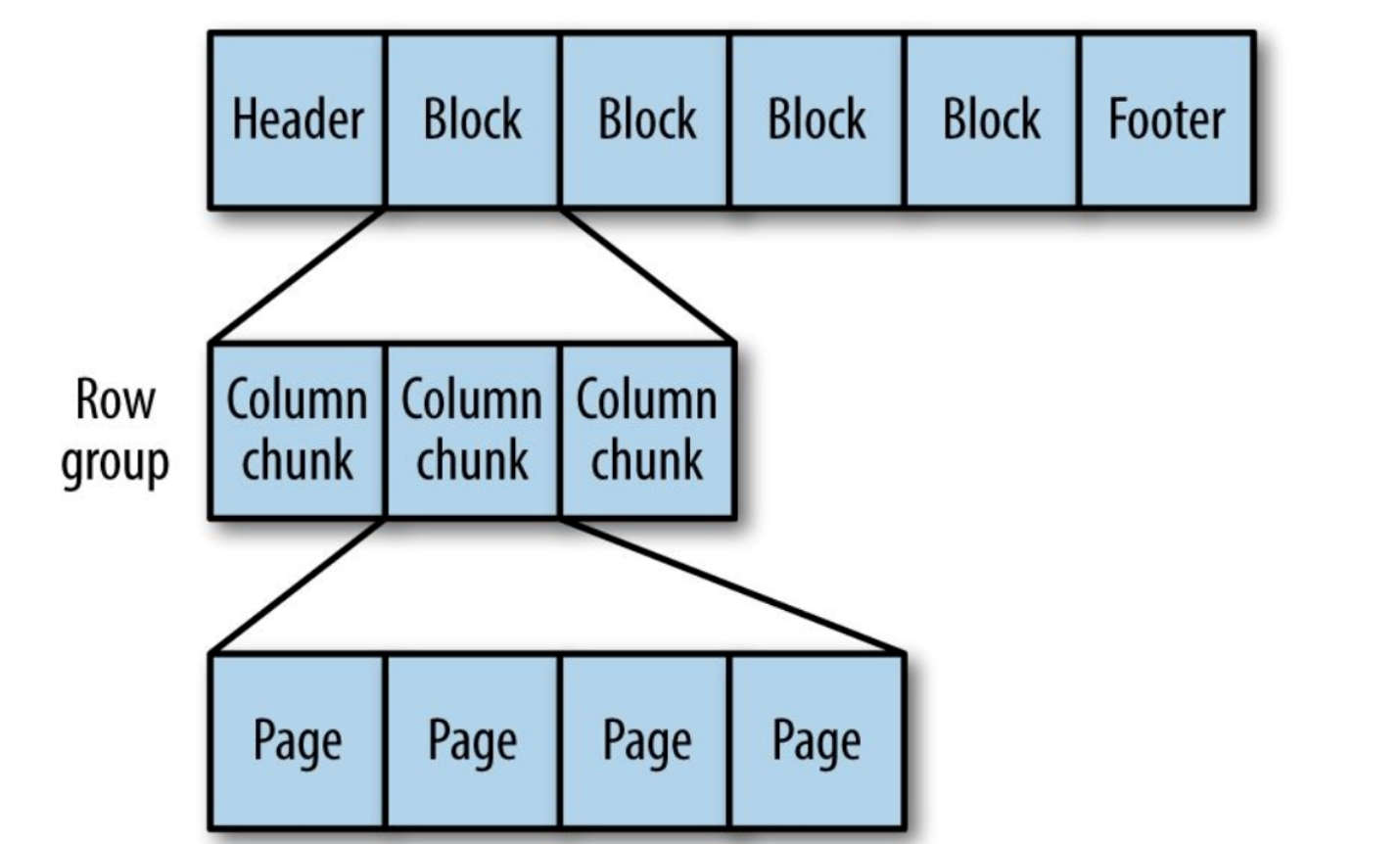
Figure 9. La structure interne du fichier Parquet.
Le parquet transforme les structures imbriquées en stockage à colonnes plates,
qui est représenté par le niveau de répétition et le niveau de définition (R et D) et utilise
métadonnées pour restaurer les enregistrements tout en lisant les données pour récupérer tous
fichier. Ensuite, vous verrez un exemple de R et D:
AddressBook { contacts: { phoneNumber: “555 987 6543” } contacts: { } } AddressBook { }

C’est tout. Vous connaissez maintenant les différences de formats de fichiers dans Hadoop. Si
trouver des erreurs ou des inexactitudes, n'hésitez pas à contacter
pour moi. Vous pouvez me contacter sur LinkedIn .