Remarque perev. : Ce matériel poursuit une remarquable série d'articles de l'évangéliste technologique AWS Adrian Hornsby, dont le but était d'expliquer simplement et clairement l'importance des expériences conçues pour atténuer les conséquences des défaillances des systèmes informatiques.
"Si vous n'avez pas réussi à préparer le plan, alors vous prévoyez d'échouer." - Benjamin Franklin
Dans la
première partie de cette série d'articles, j'ai présenté le concept d'ingénierie du chaos et expliqué comment cela aide à trouver et à corriger les failles du système avant qu'elles n'entraînent des pannes de production. Il a également expliqué comment l'ingénierie du chaos contribue à un changement culturel positif au sein des organisations.
À la fin de la première partie, j'ai promis de parler des «outils et méthodes pour introduire des pannes dans les systèmes». Hélas, ma tête avait ses propres plans à cet égard, et dans cet article, j'essaierai de répondre à la question la plus populaire qui se pose aux personnes qui souhaitent s'engager dans l'ingénierie du chaos:
que casser en premier? Grande question! Cependant, il ne semble pas s'embêter avec ce panda ...
 Ne jouez pas avec le panda du chaos!Réponse courte
Ne jouez pas avec le panda du chaos!Réponse courte : visez des services essentiels sur le chemin de la demande.
Une réponse longue mais plus intelligible : pour comprendre par où commencer les expériences avec le chaos, faites attention à trois domaines:
- Regardez l' histoire des échecs et identifiez les modèles;
- Décidez des dépendances critiques ;
- Utilisez le soi-disant. effet de confiance excessive .
C'est drôle, mais cette partie avec le même succès pourrait s'appeler
"Voyage vers la connaissance de soi et l'illumination" . Dans ce document, nous allons commencer à "jouer" avec des outils sympas.
1. La réponse se trouve dans le passé
Si vous vous souvenez, dans la première partie, j'ai présenté le concept de correction des erreurs (COE) - la méthode par laquelle nous analysons nos manquements: manquements technologiques, de processus ou d'organisation - pour comprendre leurs causes et empêcher leur répétition future. . En général, cela devrait commencer.
"Pour comprendre le présent, vous devez connaître le passé." - Karl Sagan
Regardez l'historique des échecs, mettez des balises dans SOE ou postmortem'ah et classifiez-les. Identifiez les modèles courants qui entraînent souvent des problèmes et, pour chaque entreprise d'État, posez-vous la question suivante:
"Cela aurait-il pu être prévu, et donc évité par l'introduction d'un dysfonctionnement?"Je me souviens d'un échec au tout début de ma carrière. Cela aurait pu être facilement évité si nous avions eu quelques expériences de chaos simples:
Dans des conditions normales, les instances d'arrière-plan répondent aux contrôles d'intégrité d'un équilibreur de charge (ELB ). ELB utilise ces vérifications pour rediriger les demandes vers des instances saines. Lorsqu'il s'avère qu'une certaine instance est «malsaine», l'ELB cesse de lui envoyer des demandes. Une fois, après une campagne marketing réussie, le trafic a augmenté et les backends ont commencé à répondre aux contrôles de santé plus lentement que d'habitude. Il faut dire que ces bilans de santé étaient approfondis , c'est-à-dire que l'état des dépendances était vérifié.
Cependant, pendant un certain temps, tout était en ordre.
Puis, déjà dans des conditions plutôt stressantes, l'une des instances a commencé à effectuer une tâche cron régulière non critique de la catégorie ETL. La combinaison d'un trafic élevé et de cronjob a stimulé l'utilisation du processeur de près de 100%. La surcharge du processeur a ralenti encore plus les réponses aux contrôles d'intégrité - à tel point qu'ELB a décidé que l'instance rencontrait des problèmes. Comme prévu, l'équilibreur a cessé de lui distribuer du trafic, ce qui, à son tour, a entraîné une augmentation de la charge sur les autres instances du groupe.
Soudain, toutes les autres instances ont également échoué au contrôle de santé.
Le démarrage d'une nouvelle instance a nécessité le téléchargement et l'installation de packages et a pris beaucoup plus de temps que l'ELB nécessaire pour les déconnecter - un par un - dans le groupe de mise à l'échelle automatique. Il est clair que bientôt l'ensemble du processus a atteint un point critique et la demande est tombée.
Ensuite, nous avons toujours compris les points suivants:
- Pour installer un logiciel lors de la création d'une nouvelle instance depuis longtemps, il est préférable de privilégier l'approche immuable et Golden AMI .
- Dans les situations difficiles, les réponses aux contrôles de santé et aux ELB doivent avoir la priorité - et surtout vous voulez rendre la vie difficile aux autres instances.
- La mise en cache locale des contrôles de santé (même pendant quelques secondes) aide beaucoup.
- Dans une situation difficile, n'exécutez pas de tâches cron et d'autres processus non critiques - économisez des ressources pour les tâches les plus importantes.
- Lors de la mise à l'échelle automatique, utilisez des instances plus petites. Un groupe de 10 petites copies vaut mieux que 4 grandes; si une instance tombe, dans le premier cas, 10% du trafic sera réparti sur 9 points, dans le second - 25% du trafic sur trois points.
Alors,
cela pourrait-il être prévu et donc évité en introduisant le problème?Oui , et de plusieurs manières.
Tout d'abord, en simulant une utilisation élevée du processeur avec des outils tels que
stress-ng ou
cpuburn :
❯ stress-ng --matrix 1 -t 60s
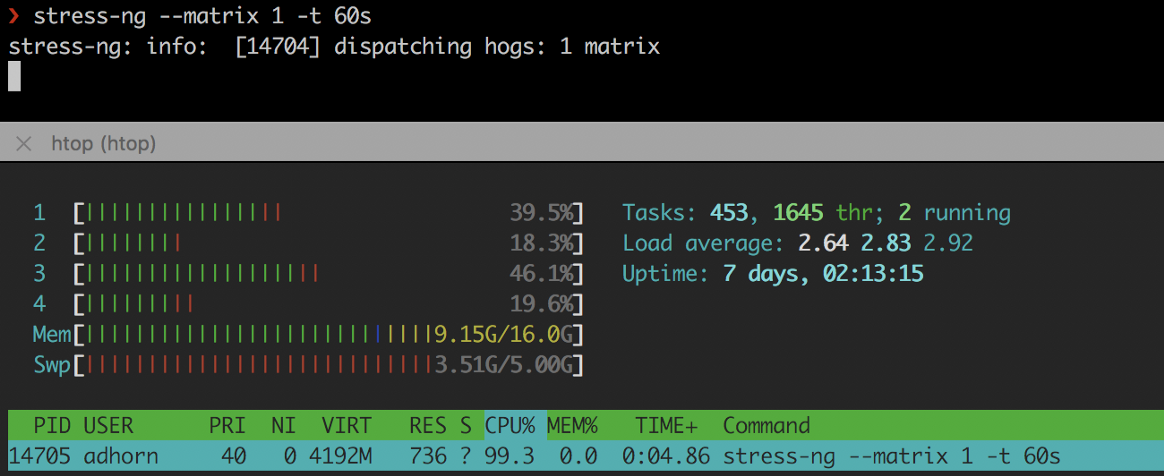 stress-ng
stress-ngDeuxièmement, surcharger l'instance à l'aide de
wrk et d'autres utilitaires similaires:
❯ wrk -t12 -c400 -d20s http://127.0.0.1/api/health
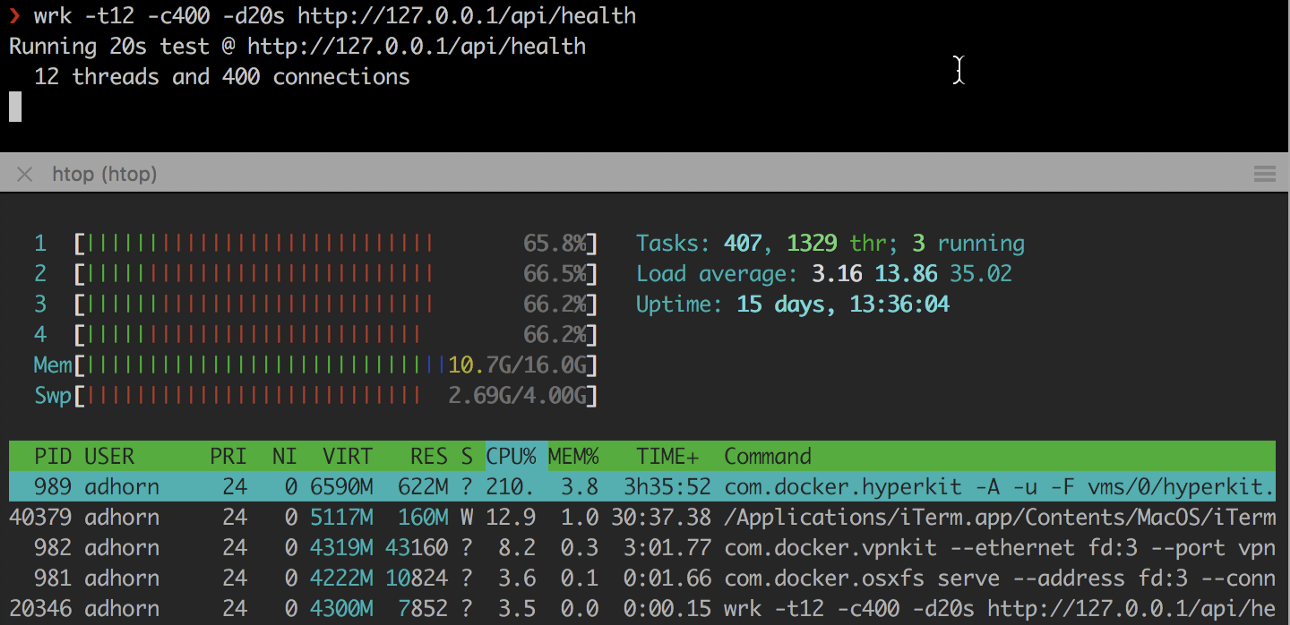
Les expériences sont relativement simples, mais elles peuvent donner matière à réflexion sans avoir à subir le stress d'un véritable échec.
Mais
ne vous arrêtez pas là . Essayez de reproduire l'échec dans un environnement de test et vérifiez votre réponse à la question "
Cela aurait-il pu être prévu et donc évité en introduisant un dysfonctionnement?" ". Il s'agit d'une mini expérience de chaos à l'intérieur d'une expérience de chaos pour tester des hypothèses, mais en commençant par un échec.
 Était-ce un rêve ou est-ce vraiment arrivé?
Était-ce un rêve ou est-ce vraiment arrivé?Étudiez donc l'historique des pannes, analysez les
COE , étiquetez-les et classez-les en fonction du «rayon de dégâts» - ou, plus précisément, en fonction du nombre de clients concernés - puis recherchez des schémas. Demandez-vous si cela aurait pu être prévu et évité en introduisant le problème. Vérifiez votre réponse.
Passez ensuite aux modèles les plus courants avec la plus grande plage.
2. Créez une carte des dépendances
Prenez un moment pour réfléchir à votre candidature. Existe-t-il une carte claire de ses dépendances? Savez-vous quel impact ils auront en cas de panne?
Si vous n'êtes pas très familier avec le code de votre application ou s'il est devenu trop volumineux, il peut être difficile de comprendre ce que fait le code et quelles sont ses dépendances. Comprendre ces dépendances et leur impact possible sur l'application et les utilisateurs est essentiel pour comprendre par où commencer l'ingénierie du chaos: le composant avec le plus grand rayon de destruction sera le point de départ.
L'identification et la documentation des dépendances sont appelées «
mappage des dépendances ». Il est généralement réalisé pour des applications avec une base de code étendue utilisant des outils de profilage de code
(profilage de code) et d'instrumentation
(instrumentation) . Vous pouvez également créer des cartes en surveillant le trafic réseau.
Cependant, toutes les dépendances ne sont pas identiques (ce qui complique encore le processus). Certains sont
critiques , d'autres
secondaires (du moins théoriquement, car les plantages résultent souvent de problèmes de dépendance jugés non critiques) .
Sans dépendances critiques, un service ne peut pas fonctionner. Les dépendances non critiques «
ne devraient pas » avoir un effet sur le service en cas de chute. Pour gérer les dépendances, vous devez avoir une compréhension claire des API utilisées par l'application. Cela peut être beaucoup plus compliqué qu'il n'y paraît - du moins pour les grandes applications.
Commencez par trier toutes les API. Mettez en surbrillance les plus
importants et les plus
critiques . Prenez les
dépendances du référentiel de code, examinez les
journaux de connexion , puis consultez la
documentation (bien sûr, si elle existe - sinon vous avez encore plus de problèmes). Utilisez les outils de
profilage et de traçage , filtrez les appels externes.
Vous pouvez utiliser des programmes comme
netstat , un utilitaire de ligne de commande qui affiche une liste de toutes les connexions réseau (sockets actives) sur le système. Par exemple, pour afficher toutes les connexions actuelles, tapez:
❯ netstat -a | more

Dans AWS, vous pouvez utiliser les journaux de flux VPC - une méthode qui vous permet de collecter des informations sur le trafic IP qui va vers ou depuis les interfaces réseau sur les VPC. Ces journaux peuvent aider à d'autres tâches, par exemple, trouver une réponse à la question de savoir pourquoi un certain trafic n'atteint pas l'instance.
Vous pouvez également utiliser
AWS X-Ray . X-Ray vous permet d'obtenir un aperçu détaillé et de bout en bout
(de bout en bout) des demandes au fur et à mesure de leur progression dans l'application, et crée également une carte des composants de base de l'application. C'est très pratique si vous devez identifier les dépendances.
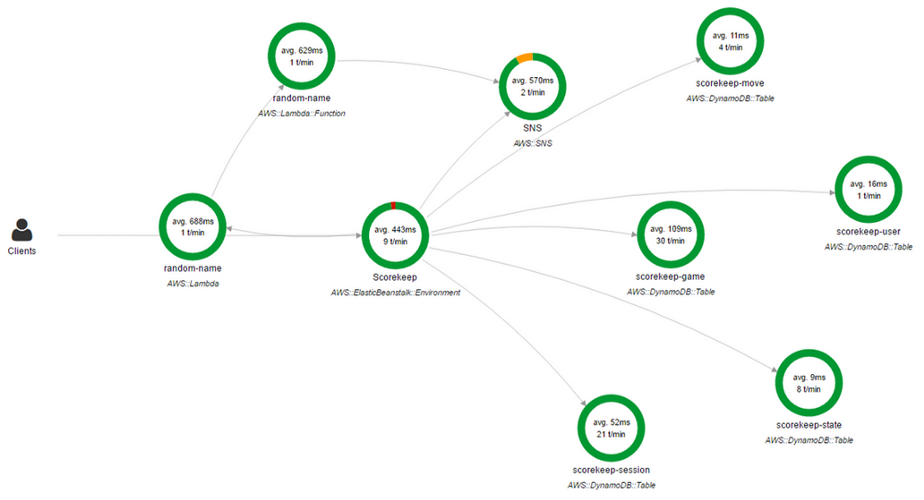 Console AWS X-Ray
Console AWS X-RayUne carte de dépendance réseau n'est qu'une solution partielle. Oui, il montre quelle application est associée à laquelle, mais il existe d'autres dépendances.
De nombreuses applications utilisent DNS pour se connecter aux dépendances, tandis que d'autres peuvent utiliser le mécanisme de découverte de service ou même des adresses IP codées en dur dans les fichiers de configuration (par exemple, dans
/etc/hosts ).
Par exemple, vous pouvez créer un
DNS trou noir à l' aide d'
iptables et voir ce qui se casse. Pour ce faire, entrez la commande suivante:
❯ iptables -I OUTPUT -p udp --dport 53 -j REJECT -m comment --comment "Reject DNS"
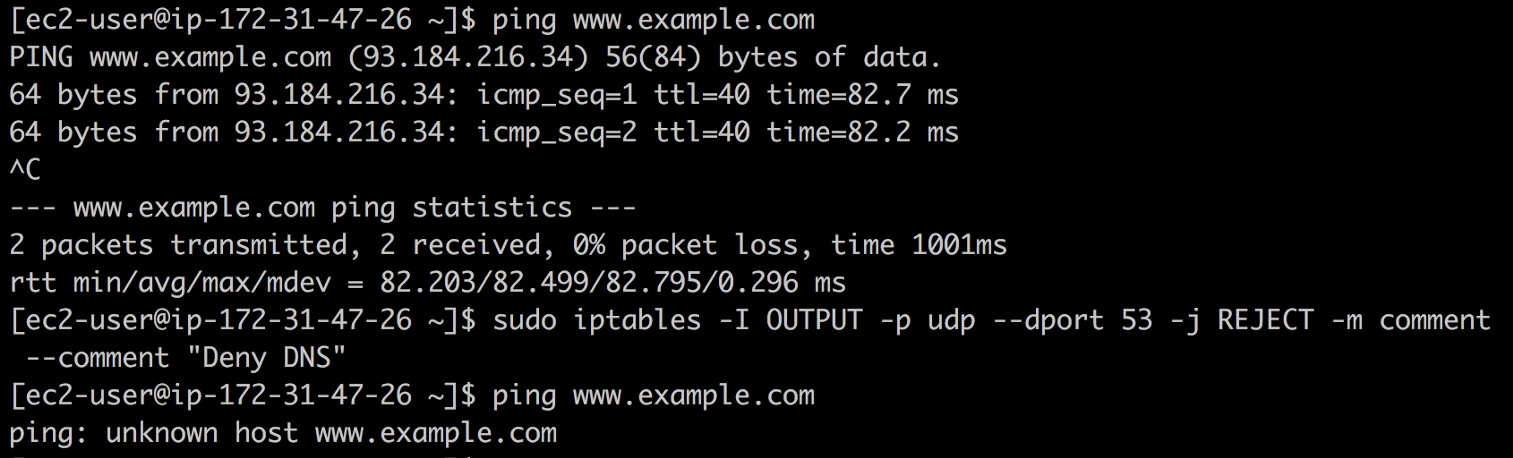 DNS du trou noir
DNS du trou noirSi vous trouvez des adresses IP dans
/etc/hosts ou d'autres fichiers de configuration dont vous ne savez rien (oui, malheureusement, cela se produit),
iptables peut à nouveau venir à la rescousse. Supposons que vous trouviez
8.8.8.8 et que vous ne savez pas qu'il s'agit de l'adresse du serveur DNS public de Google. À l'aide d'
iptables vous pouvez fermer le trafic entrant et sortant à cette adresse à l'aide des commandes suivantes:
❯ iptables -A INPUT -s 8.8.8.8 -j DROP -m comment --comment "Reject from 8.8.8.8" ❯ iptables -A OUTPUT -d 8.8.8.8 -j DROP -m comment --comment "Reject to 8.8.8.8"
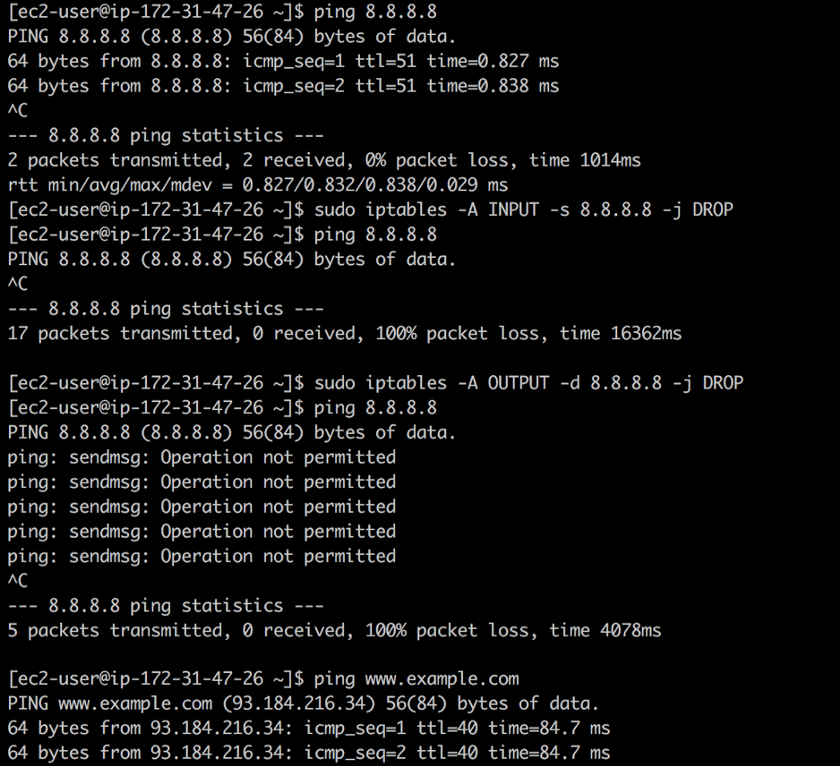 Fermer l'accès
Fermer l'accèsLa première règle supprime tous les paquets du DNS public de Google: le
ping fonctionne, mais les paquets ne sont pas retournés. La deuxième règle rejette tous les paquets provenant de votre système en direction du DNS public de Google. En réponse au
ping nous obtenons que l'
opération n'est pas autorisée .
Remarque: dans ce cas particulier, il serait préférable d'utiliser whois 8.8.8.8 , mais ce n'est qu'un exemple.Vous pouvez aller encore plus loin dans le terrier du lapin, car tout ce qui utilise TCP et UDP dépend en fait de l'IP. Dans la plupart des cas, IP est liée à ARP. N'oubliez pas les pare-feu ...
 Si vous choisissez une pilule rouge, vous resterez au pays des merveilles et je montrerai à quelle profondeur le trou du lapin va ”
Si vous choisissez une pilule rouge, vous resterez au pays des merveilles et je montrerai à quelle profondeur le trou du lapin va ”Une approche plus radicale consiste à
éteindre les voitures une par une et à voir ce qui est cassé ... devenir un "singe du chaos". Bien sûr, de nombreux systèmes de production ne sont pas conçus pour une telle attaque grossière, mais au moins, ils peuvent être essayés dans un environnement de test.
Construire une carte des dépendances est souvent un exercice très long. J'ai récemment parlé avec un client que j'ai passé près de 2 ans à développer un outil qui, en mode semi-automatique, génère des cartes de dépendances pour des centaines de microservices et d'équipes.
Le résultat, cependant, est extrêmement intéressant et utile. Vous en apprendrez beaucoup sur votre système, ses dépendances et ses opérations. Encore une fois, soyez patient: le voyage lui-même est de la plus haute importance.
3. Méfiez-vous de l'arrogance
"Quiconque rêve de quoi, y croit." - Démosthènes
Avez-vous déjà entendu parler de l'
effet de l'excès de confiance ?
Selon Wikipedia, l'effet de la confiance excessive est "une distorsion cognitive dans laquelle la confiance d'une personne dans ses actions et décisions est beaucoup plus élevée que la précision objective de ces jugements, surtout lorsque le niveau de confiance est relativement élevé".
 Basé sur l'instinct et l'expérience ...
Basé sur l'instinct et l'expérience ...D'après ma propre expérience, je peux dire que cette distorsion est un excellent indice pour commencer l'ingénierie du chaos.
Méfiez-vous de l'opérateur confiant:
Charlie: "Cette chose n'est pas tombée depuis environ cinq ans, tout va bien!"
Échec: "Attendez ... je serai bientôt!"
Le biais résultant de la confiance en soi est une chose insidieuse et même dangereuse en raison de divers facteurs qui l'affectent. Cela est particulièrement vrai lorsque les membres de l'équipe mettent leur âme dans une certaine technologie ou consacrent beaucoup de temps à des «corrections».
Pour résumer
La recherche d'un point de départ pour l'ingénierie du chaos donne toujours plus de résultats que prévu, et les équipes qui commencent à se casser trop rapidement perdent de vue l'essence plus globale et intéressante de l'
ingénierie (du chaos) - l'application créative de
méthodes scientifiques et de
preuves empiriques pour la conception, le développement , exploitation, maintenance et amélioration des systèmes (logiciels).
Sur ce point, la deuxième partie prend fin. Veuillez rédiger des avis, partager des opinions ou simplement taper des mains sur
Medium .
Dans la partie suivante, je vais vraiment regarder les outils et techniques pour introduire des pannes système. Jusqu'à - au revoir! MISE À JOUR (19 décembre): La
traduction de la troisième partie est devenue disponible.
PS du traducteur
Lisez aussi dans notre blog: