En général, la reconnaissance faciale et l'identification des personnes en fonction de leurs résultats ressemblent à du sexe d'adolescent pour les aînés - tout le monde parle beaucoup de lui, mais peu de pratique. Il est clair que nous ne sommes plus surpris qu'après avoir téléchargé des photos de rassemblements amicaux, Facebook / VK suggère de marquer les personnes trouvées sur la photo, mais ici, nous savons intuitivement que les réseaux sociaux ont une bonne aide sous la forme d'un graphique de connexions d'une personne. Et s'il n'y a pas un tel graphique? Commençons cependant dans l'ordre.

Initialement, la reconnaissance faciale et l'identification de «l'ami / l'ennemi» avec nous est née de besoins exclusivement domestiques - les toxicomanes sont entrés dans la porte d'un collègue et surveillent constamment l'image de la caméra vidéo installée, et même démontent où le voisin et où l'étranger n'avait aucun désir non.
Par conséquent, en seulement une semaine, un prototype a été assemblé sur le genou, composé d'une caméra IP, d'un périphérique à carte unique, d'un capteur de mouvement et de la bibliothèque de reconnaissance Python face_recognition. Étant donné que la bibliothèque python était sur une seule plaque, un matériel plutôt puissant ... disons-le soigneusement, pas très rapidement, nous avons décidé de construire le processus de traitement comme suit:
- le capteur de mouvement détermine s'il y a mouvement dans la zone d'espace qui lui est confiée et signale sa présence;
- un service écrit basé sur gstreamer, qui reçoit constamment un flux d'une caméra IP, coupe 5 secondes avant et 10 secondes après la détection et le transmet à la bibliothèque de reconnaissance pour analyse;
- à son tour, elle regarde la vidéo, y trouve des visages, les compare à des échantillons connus et, si elle est inconnue, remet la vidéo au canal Telegram, plus tard, elle était censée être contrôlée au même endroit pour couper immédiatement les faux positifs - par exemple, lorsqu'un voisin tourné vers la caméra du mauvais côté sur les échantillons.
L'ensemble du processus a été collé ensemble par notre bien-aimé Erlang, et au cours des tests sur des collègues, il a prouvé sa capacité de travail minimale.
Cependant, le modèle assemblé n'a pas trouvé d'application dans la vraie vie - pas en raison de son imperfection technique, ce qui était sans aucun doute - comme le montre l'expérience, collecté sur le genou dans des conditions de bureau en serre a une très mauvaise tendance à se casser sur le terrain, et au moment de la démonstration au client , et à cause de celles organisationnelles, les résidents de l'entrée ont refusé la majorité de toute surveillance vidéo.
Le projet est allé sur l'étagère et a périodiquement poussé avec un bâton pour des démonstrations pendant les ventes et l'envie de se réincarner dans le ménage personnel.
Tout a changé depuis le moment où nous avions un projet plus spécifique et assez commercial sur le même sujet. Comme il ne serait pas possible de couper les coins en utilisant un capteur de mouvement directement à partir de l'énoncé du problème, j'ai dû approfondir les nuances de la recherche et de la reconnaissance des visages dans trois têtes (d'accord, deux et demi, si vous comptez la mienne) directement sur le flux. Et puis une révélation s'est produite.
Le problème est que la plupart des résultats sur cette question sont des croquis purement académiques sur le thème «J'ai dû écrire un article dans un magazine sur un sujet à la mode et obtenir une coche pour la publication». Je ne porte pas atteinte aux mérites des scientifiques - parmi les articles que j'ai trouvés il y avait beaucoup d'utiles et d'intéressants, mais, hélas, je dois admettre que la reproductibilité du travail de leur code affiché sur Github laisse beaucoup à désirer ou ressemble à une entreprise douteuse avec du temps perdu au final.
De nombreux cadres pour les réseaux de neurones et l'apprentissage automatique étaient souvent difficiles à lever - la reconnaissance faciale était une tâche étroite distincte pour eux, sans intérêt pour un large éventail de problèmes qu'ils ont résolus. En d'autres termes, pour prendre un exemple prêt à l'emploi et l'exécuter sur le matériel cible juste pour vérifier comment cela fonctionne et si cela fonctionne, n'a pas fonctionné. Ce n'était pas un exemple, alors la nécessité de l'obtenir a suggéré une quête aigre de l'assemblage de certaines bibliothèques de certaines versions pour un système d'exploitation strictement défini. C'est-à-dire de prendre et de voler en déplacement - des miettes littéralement comme le visage_recognition mentionné précédemment, que nous avons utilisé pour les métiers précédents.
Les grandes entreprises, comme toujours, nous ont sauvés. Intel et Nvidia ont depuis longtemps ressenti l'élan croissant et l'attractivité commerciale de cette classe de tâches, mais en tant que fournisseurs d'équipements, ils distribuent gratuitement leurs frameworks pour résoudre des problèmes d'application spécifiques.
Notre projet n'était probablement pas de recherche, mais de nature expérimentale, nous n'avons donc pas analysé et comparé les solutions de fournisseurs individuels, mais simplement pris la première dans le but de collecter un prototype prêt à l'emploi et de le tester au combat, tout en recevant la réponse la plus rapide possible. Par conséquent, le choix s'est très vite
porté sur
Intel OpenVINO - une bibliothèque pour l'application pratique de l'apprentissage automatique dans les tâches appliquées.
Pour commencer, nous avons monté un stand, qui est traditionnellement un ensemble de nettop avec un processeur Intel Core i3 et des caméras IP de fournisseurs chinois sur le marché. La caméra était directement connectée au nettop et lui fournissait un flux RTSP avec un FPS pas très grand, basé sur l'hypothèse que les gens ne courraient toujours pas devant lui comme dans les compétitions. La vitesse de traitement d'une image (recherche et reconnaissance de visages) a fluctué de l'ordre de dizaines à centaines de millisecondes, ce qui était bien suffisant pour intégrer le mécanisme de recherche des personnes utilisant des échantillons existants. De plus, nous avions également un plan de sauvegarde - Intel a un coprocesseur spécial pour accélérer les calculs des réseaux de
neurones Neural Compute Stick 2 , que nous pourrions utiliser si nous n'avions pas de processeur à usage général. Mais - jusqu'à présent, rien ne s'est passé.
Après avoir terminé l'assemblage et vérifié la fonctionnalité des exemples de base - une caractéristique distinctive du SDK Intel se trouvait dans un guide d'exemples pas à pas et très détaillé - nous avons commencé à créer le logiciel.
La tâche principale qui nous attendait était de rechercher une personne dans le champ de vision de la caméra, son identification et une notification en temps opportun de sa présence. En conséquence, en plus de reconnaître les visages et de les comparer avec des modèles (comment faire cela, à l'époque, ne posait pas moins de questions que tout le reste), nous devions fournir des éléments secondaires du plan d'interface. À savoir, nous devons recevoir des cadres avec les visages des personnes nécessaires de la même caméra pour leur identification ultérieure. Pourquoi, à partir du même appareil photo, je pense que c'est aussi assez évident - le point d'installation de l'appareil photo sur l'objet et l'optique de l'objectif introduisent certaines distorsions, ce qui, vraisemblablement, peut affecter la qualité de la reconnaissance, nous utilisons une source de données source différente d'un outil de suivi.
C'est-à-dire En plus du gestionnaire de flux lui-même, nous avons besoin d'au moins une archive vidéo et un analyseur de fichiers vidéo qui isolera tous les visages détectés de l'enregistrement et sauvegardera les plus appropriés comme références.
Comme toujours, nous avons pris le familier Erlang et PostgreSQL comme colle entre ffmpeg, les applications sur OpenVINO et l'API Telegram Bot pour les alertes. De plus, nous avions besoin d'une interface Web pour fournir l'ensemble minimal de procédures de gestion du complexe, que notre collègue frontender avait téléchargé sur VueJS.
La logique du travail était la suivante:
- sous le contrôle d'un plan de contrôle (à Erlang) ffmpeg écrit un flux de la caméra vers la vidéo en sections de cinq minutes, un processus distinct garantit que les enregistrements sont stockés dans un volume strictement spécifié et nettoie le plus ancien lorsque ce seuil est atteint;
- grâce à l'interface Web, vous pouvez afficher n'importe quel enregistrement, ils sont classés par ordre chronologique, ce qui, bien que non sans difficulté, vous permet d'isoler le fragment souhaité et de l'envoyer pour traitement;
- le traitement consiste à analyser la vidéo et à extraire des images avec des visages détectés, il ne fait que le logiciel basé sur OpenVINO (je dois dire que nous avons réussi ici à réduire un peu l'angle - le logiciel pour analyser le flux et analyser les fichiers est presque identique, c'est pourquoi la plupart de celui-ci est allé à une bibliothèque partagée, et les utilitaires eux-mêmes ne diffèrent que dans la chaîne de traitement à la gstreamer modulaire). Le traitement a lieu sur vidéo, isolant les visages trouvés à l'aide d'un réseau neuronal spécialement formé. Les fragments résultants du cadre contenant les visages tombent dans un autre réseau de neurones, qui forme un vecteur à 256 éléments, qui est, en fait, les coordonnées des points de référence du visage d'une personne. Ce vecteur, le cadre détecté et les coordonnées du rectangle de la face trouvée sont stockés dans la base de données;
- en outre, une fois le traitement terminé, l'opérateur ouvre la variété de trames dessinées, est horrifié par leur nombre et procède à la recherche de personnes cibles. Les échantillons sélectionnés peuvent être ajoutés à une personne existante ou en créer un nouveau. Une fois le traitement de la tâche terminé, les résultats de l'analyse sont supprimés, à l'exception des vecteurs stockés mappés aux enregistrements d'observables;
- en conséquence, nous pouvons regarder à la fois les trames et les vecteurs de détection et éditer, en supprimant les échantillons non réussis;
- parallèlement au cycle de détection en arrière-plan, le service d'analyse de flux fonctionne toujours, ce qui fait la même chose, mais avec le flux de la caméra. Il sélectionne les visages dans le flux observé et les compare aux échantillons de la base de données, qui est basée sur l'hypothèse simple que les vecteurs d'une personne seront plus proches les uns des autres que de tous les autres vecteurs. Un calcul par paire de la distance entre les vecteurs se produit, lorsque le seuil est atteint, un enregistrement de détection et une trame sont mis dans la base de données. De plus, une personne est ajoutée à la liste d'arrêt dans un avenir proche, ce qui évite plusieurs notifications concernant la même personne;
- le plan de contrôle vérifie périodiquement le journal de détection et, en cas de nouvelles entrées, notifie avec un message avec la photo jointe et met en évidence le visage à travers le bot à ceux qui sont autorisés selon les paramètres.
Cela ressemble à ceci:
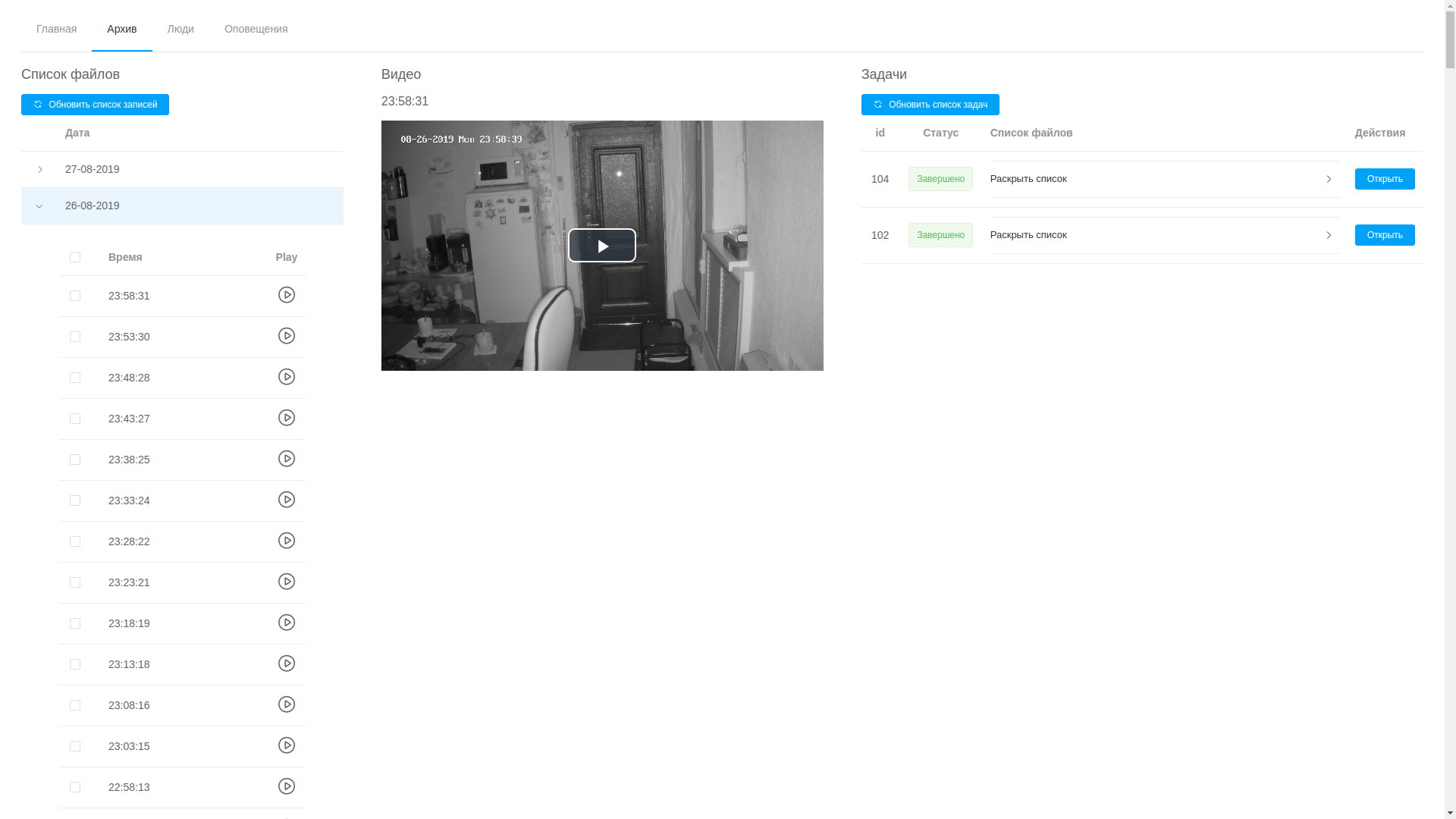 Voir l'archive
Voir l'archive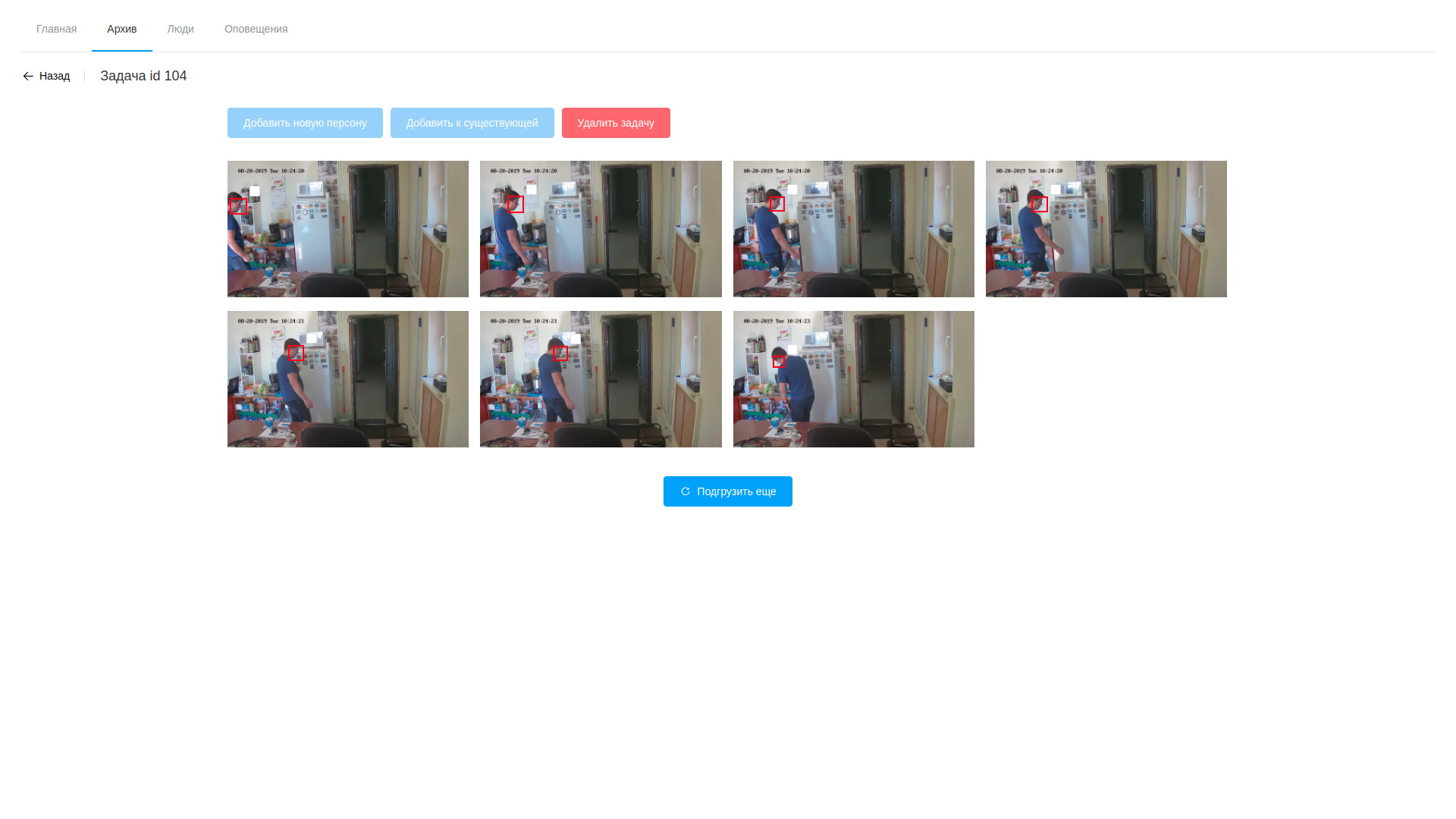 Résultats de l'analyse vidéo
Résultats de l'analyse vidéo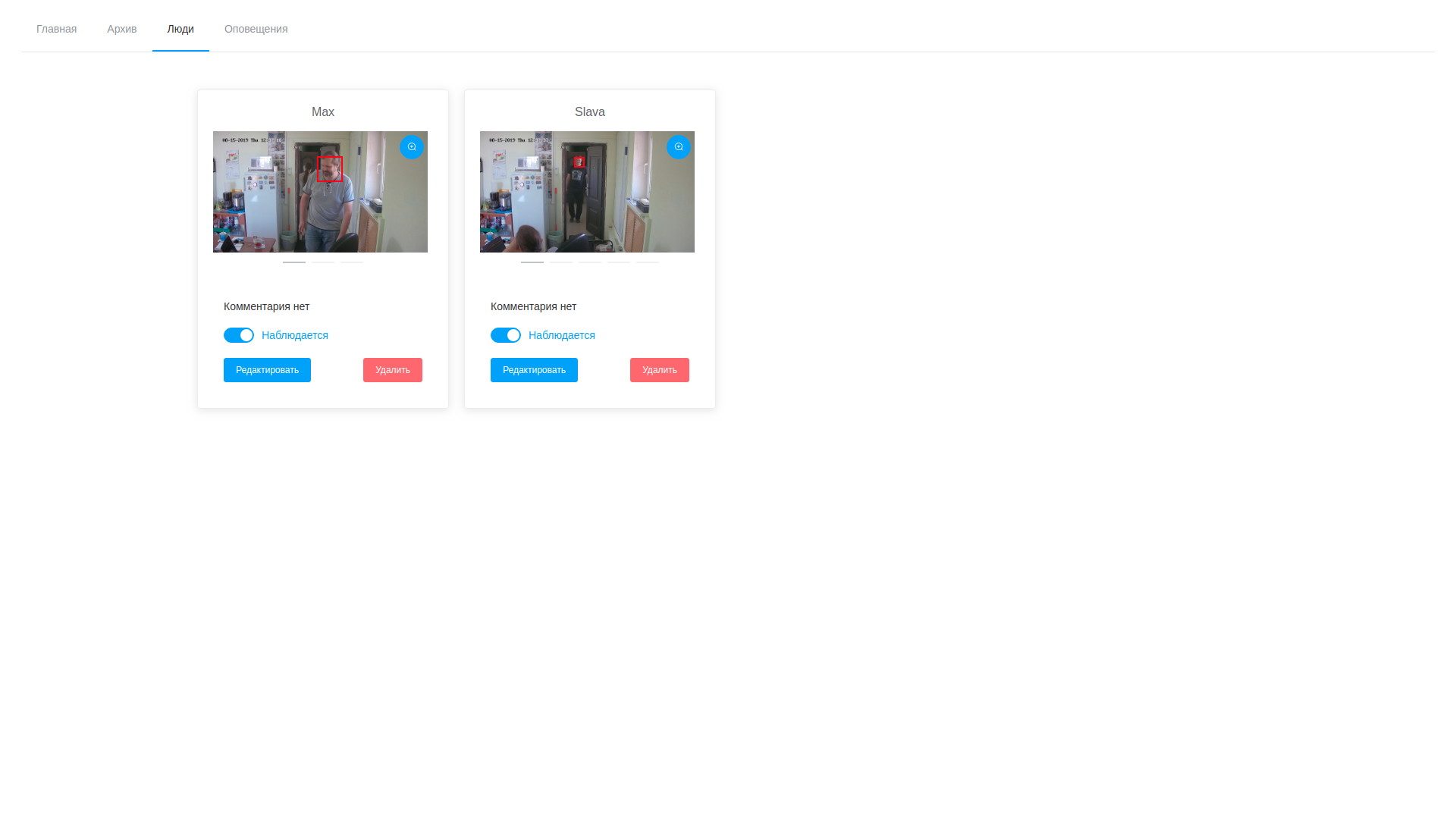 Liste des personnalités observées
Liste des personnalités observéesLa solution résultante est à bien des égards controversée et parfois même pas optimale à la fois en termes de productivité et en termes de réduction du temps de réaction. Mais, je le répète, nous n'avions pas pour objectif d'obtenir un système efficace tout de suite, mais simplement de suivre cette voie et de remplir le nombre maximum de cônes, d'identifier les chemins étroits et les problèmes potentiels non évidents.
Le système assemblé a été testé dans des conditions de bureau à effet de serre pendant une semaine. Pendant ce temps, les observations suivantes ont été notées:
- la qualité de la reconnaissance dépend clairement de la qualité des échantillons originaux. Si la personne observée passe trop rapidement dans la zone d'observation, alors avec un degré élevé de probabilité, elle ne laissera pas de données pour l'échantillonnage et ne sera pas reconnue. Cependant, je pense que c'est une question de réglage fin du système, y compris les paramètres d'éclairage et de flux vidéo;
- étant donné que le système fonctionne avec la reconnaissance des éléments du visage (yeux, nez, bouche, sourcils, etc.), il est facile de se tromper en plaçant un obstacle visuel entre le visage et la caméra (cheveux, lunettes noires, portant une cagoule, etc.) - le visage, très probablement, il sera trouvé, mais la comparaison avec les échantillons ne fonctionnera pas en raison de la forte différence entre les vecteurs de détection et les échantillons;
- les lunettes ordinaires n'affectent pas trop - nous avons eu des exemples de réponses positives chez les personnes portant des lunettes et de réponses faussement négatives chez les personnes qui mettent des lunettes pour le test;
- si la barbe se trouvait sur les échantillons originaux, puis qu'elle avait disparu, le nombre d'opérations est réduit (l'auteur de ces lignes a coupé sa barbe à 2 mm et le nombre d'opérations sur elle a été divisé par deux);
- des faux positifs ont également eu lieu, c'est une occasion pour une immersion supplémentaire dans les mathématiques de la question et, éventuellement, une solution à la question de la correspondance partielle des vecteurs et de la méthode optimale pour calculer la distance entre eux. Cependant, les tests sur le terrain devraient révéler encore plus de problèmes à cet égard.
Qu'est-ce qui vient? Vérifier le système au combat, optimiser le cycle de traitement de la détection, simplifier la procédure de recherche d'événements dans les archives vidéo, ajouter plus de données à l'analyse (âge, sexe, émotions) et encore 100500 petites et petites tâches qui doivent encore être effectuées. Mais le premier pas sur le chemin des mille pas que nous avons déjà fait. Si quelqu'un partage son expérience dans la résolution de tels problèmes ou donne des liens intéressants sur cette question - je serai très reconnaissant.