
Dans l'environnement des ingénieurs SRE / DevOps, vous ne serez pas surpris qu'un jour un client (ou un système de surveillance) apparaisse et dise que «tout est perdu»: le site ne fonctionne pas, les paiements ne passent pas, la vie est en décomposition ... Peu importe comment je voudrais aider dans cette situation Il peut être très difficile de le faire sans un outil simple et compréhensible. Souvent, le problème est caché dans le code de l'application elle-même - il vous suffit de le localiser.
Et dans le chagrin et dans la joie ...
Il se trouve que nous aimons depuis longtemps New Relic. Il a été et reste un excellent outil pour surveiller les performances des applications, et vous permet également d'instrumenter l'architecture de microservices (en utilisant votre agent) et bien plus encore. Et tout pourrait être merveilleux, si ce n'est les changements dans la politique de prix du service: son
coût a augmenté de plus de 3 fois depuis 2013 . De plus, depuis l'année dernière, l'obtention d'un compte d'essai nécessite une communication avec un responsable personnel, ce qui rend difficile la présentation du produit à un client potentiel.
La situation habituelle: New Relic n'est pas nécessaire «sur une base continue», elle n'est mémorisée qu'au moment où les problèmes ont commencé. Mais vous devez toujours payer régulièrement (140 USD par serveur et par mois), et dans l'infrastructure cloud automatiquement évolutive, les montants sont plutôt élevés. Bien qu'il existe la possibilité de «Pay-As-You-Go», mais pour activer New Relic, vous devrez redémarrer l'application, ce qui peut entraîner la perte de la situation problématique pour laquelle tout a été démarré. Il n'y a pas si longtemps, New Relic a introduit un nouveau plan tarifaire -
Essentials , qui à première vue semble être une alternative raisonnable à Professional ... mais après un examen plus approfondi, il s'est avéré que certaines des fonctions importantes manquaient (en particulier, il n'a pas de
transactions clés , de
traçage inter-applications, de traçage distribué ) .
En conséquence, nous avons pensé trouver une alternative moins chère, et notre choix s'est porté sur les deux services Datadog et Atatus. Pourquoi exactement sur eux?
À propos des concurrents
Je dois dire tout de suite qu'il existe d'autres solutions sur le marché. Nous avons même envisagé des options Open Source, mais tous les clients n'ont pas la capacité gratuite d'héberger des solutions auto-hébergées ... - en outre, ils nécessiteront une maintenance supplémentaire. Le couple que nous avons sélectionné s'est avéré le plus proche de
nos besoins :
- prise en charge intégrée et développée pour les applications PHP (la pile de nos clients est très diversifiée, mais c'est un leader clair dans le contexte de la recherche d'une alternative à New Relic);
- coût abordable (moins de 100 USD par mois par hôte);
- instrumentation automatique;
- Intégration Kubernetes
- la similitude avec l'interface New Relic est un plus notable (car nos ingénieurs y sont habitués).
Par conséquent, au stade de la sélection initiale, nous avons éliminé plusieurs autres solutions populaires, et en particulier:
- Tideways, AppDynamics et Dynatrace - pour le prix;
- Stackify - est bloqué dans la Fédération de Russie et affiche trop peu de données.
L'article suivant est structuré de telle manière que les solutions envisagées seront brièvement présentées, après quoi je parlerai de notre interaction typique avec New Relic et de l'expérience / des impressions d'effectuer des opérations similaires dans d'autres services.
Présentation des concurrents sélectionnés

Tout le monde a probablement entendu parler de
New Relic ? Ce service a commencé son développement il y a plus de 10 ans, en 2008. Nous l'utilisons activement depuis 2012 et n'avons pas rencontré de problèmes d'intégration avec un très grand nombre d'applications en PHP, Ruby et Python, et nous avions également une expérience d'intégration avec C # et Go. Les auteurs du service ont des solutions pour surveiller l'application, l'infrastructure, le traçage des infrastructures de microservices, des applications pratiques pour les appareils des utilisateurs ont été créées, et bien plus encore.
Cependant, l'agent New Relic fonctionne sur des protocoles propriétaires, il ne prend pas en charge OpenTracing. L'instrumentation avancée nécessite des modifications spécifiques à New Relic. Enfin, le support de Kubernetes a jusqu'à présent un statut expérimental.
 Datadog
Datadog ,
qui a commencé son développement en 2010, semble nettement plus intéressant que New Relic en termes d'utilisation dans les environnements Kubernetes. En particulier, il prend en charge l'intégration avec NGINX Ingress, la collecte des journaux, les protocoles statsd et OpenTracing, ce qui vous permet de suivre une demande utilisateur à partir du moment où elle est connectée à la fin du travail, ainsi que de trouver des journaux pour cette demande (à la fois côté serveur Web et côté consommateur).
Lors de l'utilisation de Datadog, nous étions confrontés au fait qu'il construisait parfois de manière incorrecte une carte de microservice et à quelques failles techniques. Par exemple, il a incorrectement déterminé le type de service (il a pris Django pour un service de mise en cache) et a provoqué les 500e erreurs dans une application PHP utilisant la bibliothèque Predis populaire.
 Atatus
Atatus est le plus jeune instrument; service lancé en 2014. Son budget marketing est nettement inférieur aux concurrents listés, les mentions sont beaucoup moins fréquentes. Néanmoins, l'outil lui-même est très similaire à New Relic, et non seulement dans ses fonctionnalités (APM, surveillance du navigateur, etc.), mais aussi en apparence.
Un inconvénient important est uniquement la prise en charge de Node.js et PHP. En revanche, il est beaucoup mieux implémenté que Datadog. Contrairement à ce dernier, Atatus n'exige pas que les applications modifient ou définissent des balises supplémentaires dans le code.
Comment nous travaillons avec New Relic
Voyons maintenant comment nous utilisons généralement New Relic. Supposons que nous ayons un problème qui doit être résolu:
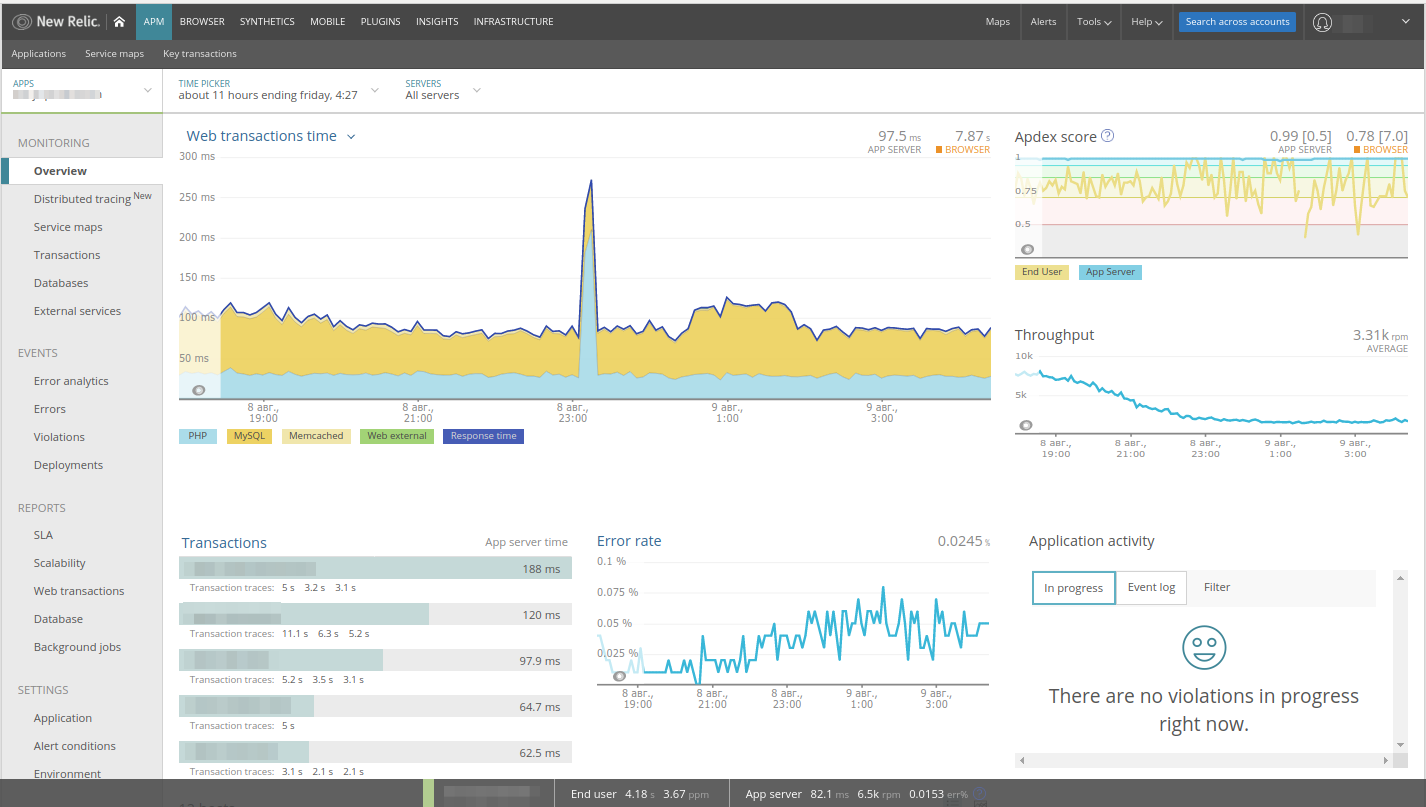
Il est facile de remarquer une
poussée sur le graphique - nous l'analysons. Dans New Relic, les transactions Web sont immédiatement sélectionnées pour l'application Web, tous les composants sont indiqués dans le graphique des performances, il existe des panneaux de taux d'erreur, de taux de demande ... Plus important encore, directement à partir de ces panneaux, vous pouvez vous déplacer entre les différentes parties de l'application (par exemple, en cliquant sur MySQL, à la section base de données).
Étant donné que dans cet exemple, nous voyons une augmentation de l'activité
PHP , cliquez sur ce graphique et accédez automatiquement à
Transactions :
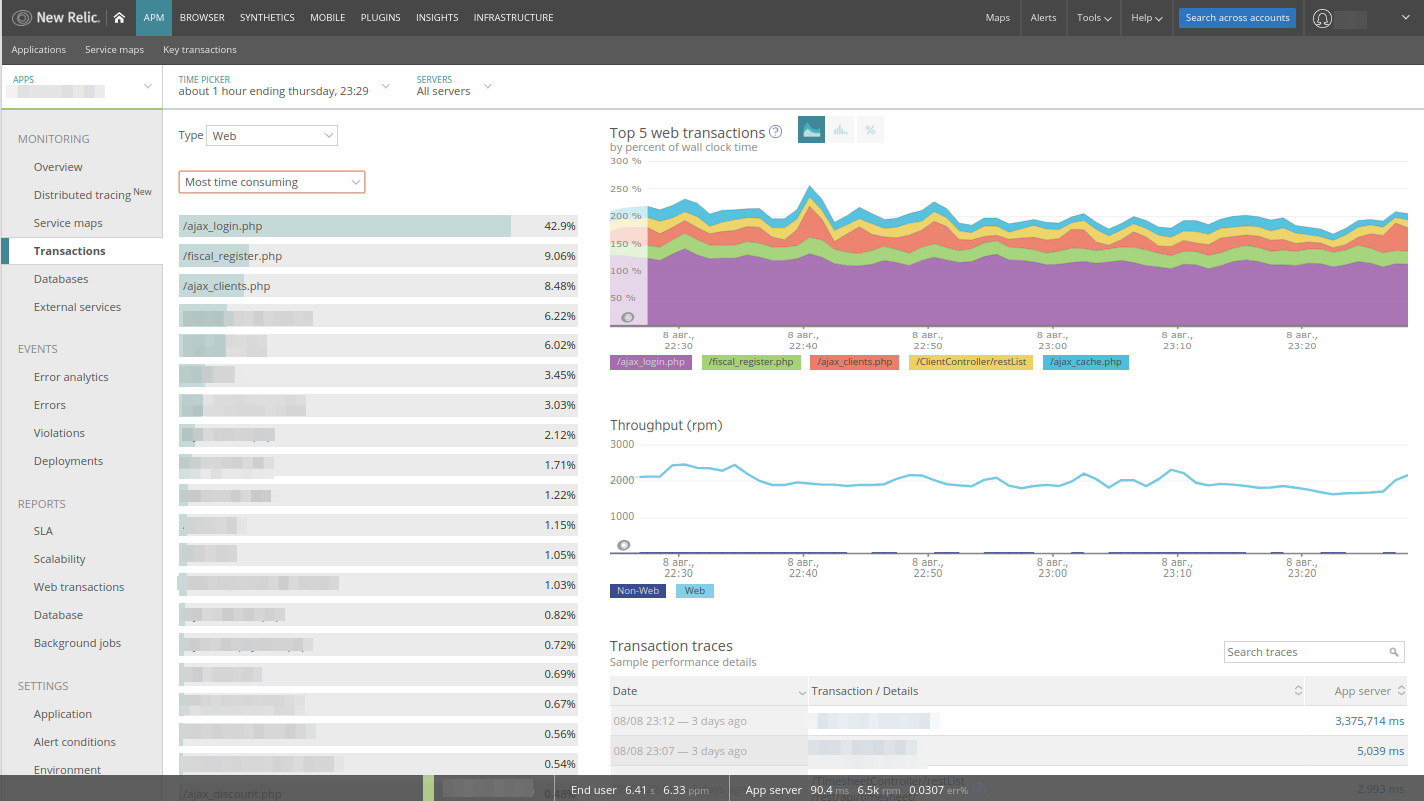
La liste des transactions, qui sont essentiellement des contrôleurs du modèle MVC, est déjà triée par
Plus longue , ce qui est très pratique: on voit immédiatement ce que fait l'application. Voici des exemples de longues requêtes collectées automatiquement par New Relic. Changer de tri est facile à trouver:
- le contrôleur d'application le plus chargé;
- Le contrôleur le plus fréquemment demandé
- le plus lent des contrôleurs.
De plus, vous pouvez développer chaque transaction et voir ce que l'application faisait au moment de l'exécution du code:
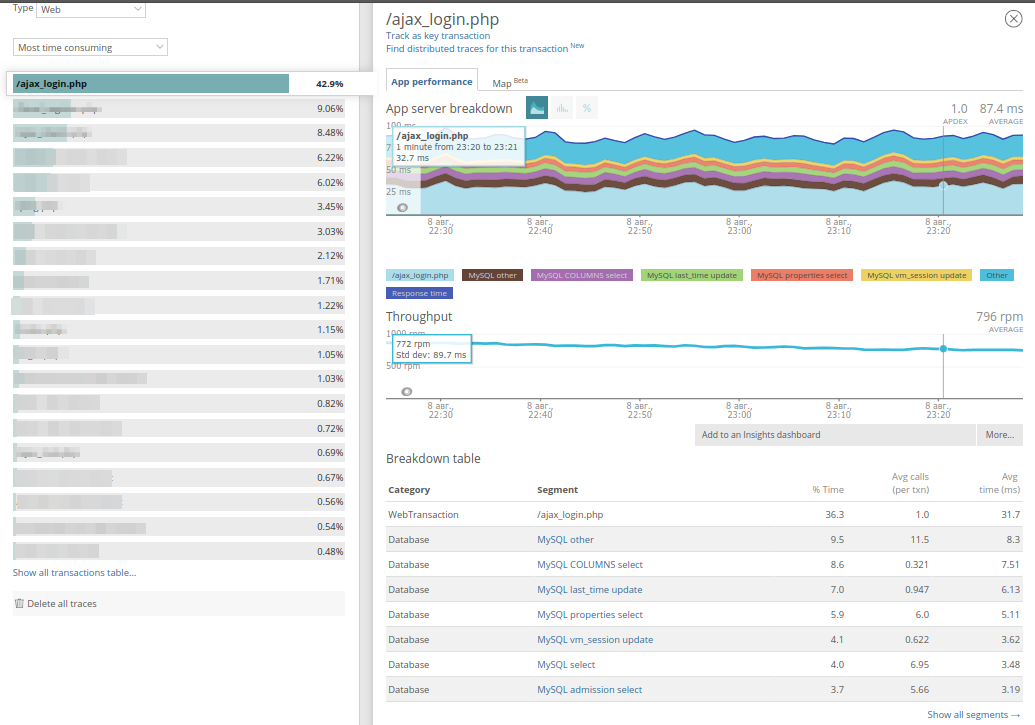
Enfin, des exemples de longues traces de requête (qui fonctionnent pendant plus de 2 secondes) sont enregistrés dans l'application. Voici le panneau pour une longue transaction:

On peut voir que deux méthodes prennent beaucoup de temps, et avec lui le moment où la demande a été exécutée, son URI et son domaine sont également affichés. Très souvent, cela aide à trouver la requête dans les journaux. En allant aux
détails de la
trace , vous pouvez voir d'où ces méthodes sont appelées:
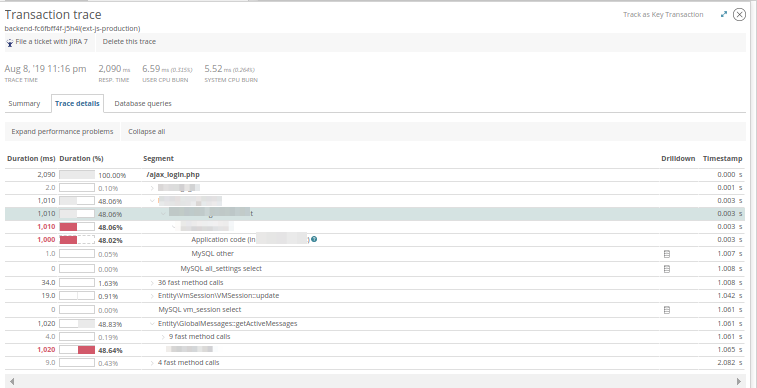
Et dans les
requêtes de base de données - évaluez les requêtes de base de données qui ont été exécutées au moment de l'application:

Fort de ces connaissances, nous pouvons évaluer la cause du ralentissement de l'application et, en collaboration avec le développeur, développer une stratégie pour résoudre le problème. En réalité, New Relic ne donne pas toujours une image claire, mais cela aide à choisir le vecteur d'investigation:
- le long
PDO::Construct nous a conduit au fonctionnement étrange de pgpoll; - instabilité dans le temps
Memcache::Get une configuration incorrecte suggérée de la machine virtuelle; - le temps étrangement augmenté pour le traitement du modèle a conduit à une boucle imbriquée avec un contrôle de la présence de 500 avatars dans le stockage d'objets;
- et ainsi de suite ...
Il arrive également qu'au lieu d'exécuter du code sur l'écran principal, quelque chose lié au stockage de données externe se développe - et peu importe ce que ce sera: Redis ou PostgreSQL - tous sont masqués dans l'onglet
Bases de données .

Vous pouvez sélectionner une base spécifique pour la recherche et trier les requêtes, de la même manière que pour les transactions. Et en allant dans l'onglet de demande, vous pouvez voir combien cette demande se trouve dans chacun des contrôleurs d'application, ainsi qu'évaluer la fréquence à laquelle elle est appelée. C'est très pratique:
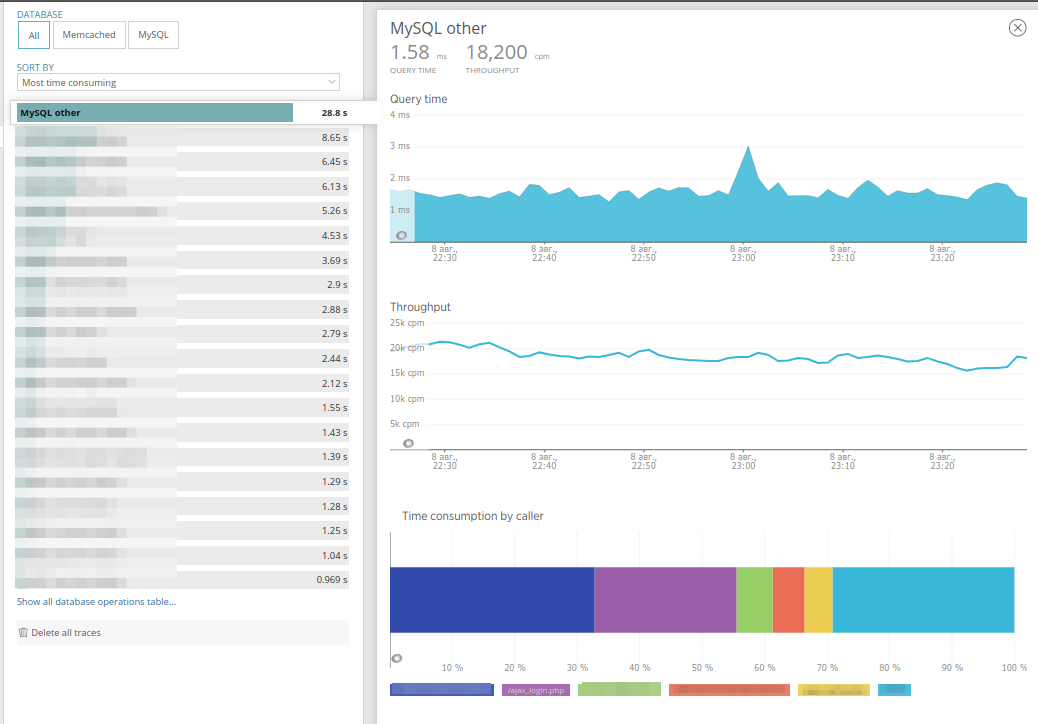
L'onglet
Services externes contient des données similaires, qui masquent les demandes de services HTTP externes, telles que l'accès au magasin d'objets, l'envoi d'événements à la sentinelle, etc. Par son contenu, l'onglet est complètement similaire aux bases de données:

Concurrents: opportunités et impressions
Maintenant, la chose la plus intéressante est de comparer les capacités de New Relic avec celles des concurrents. Malheureusement, nous n'avons pas pu tester les trois outils sur la même version d'une application en cours de production. Néanmoins, nous avons essayé de comparer les situations / configurations les plus identiques.
1. Datadog
Datadog nous accueille avec un panneau avec un mur de services:
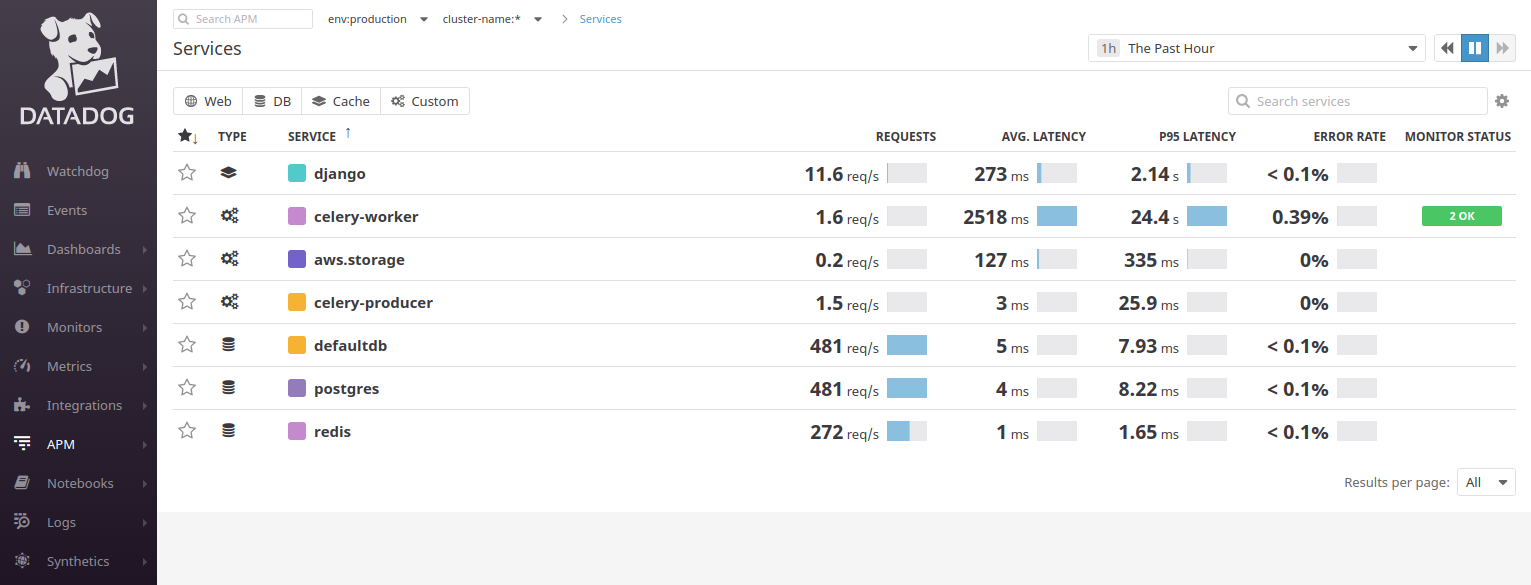
Il essaie de diviser les applications en composants / microservices, donc dans l'exemple d'application Django, nous voyons 2 connexions à PostgreSQL (
defaultdb et
postgres ), ainsi qu'à Celery, Redis. Pour travailler avec Datadog, vous devez avoir une connaissance minimale des principes de MVC: vous devez comprendre d'où viennent les demandes des utilisateurs. Habituellement,
une carte de service aide à cela:

Au fait, il y a quelque chose de similaire dans New Relic:
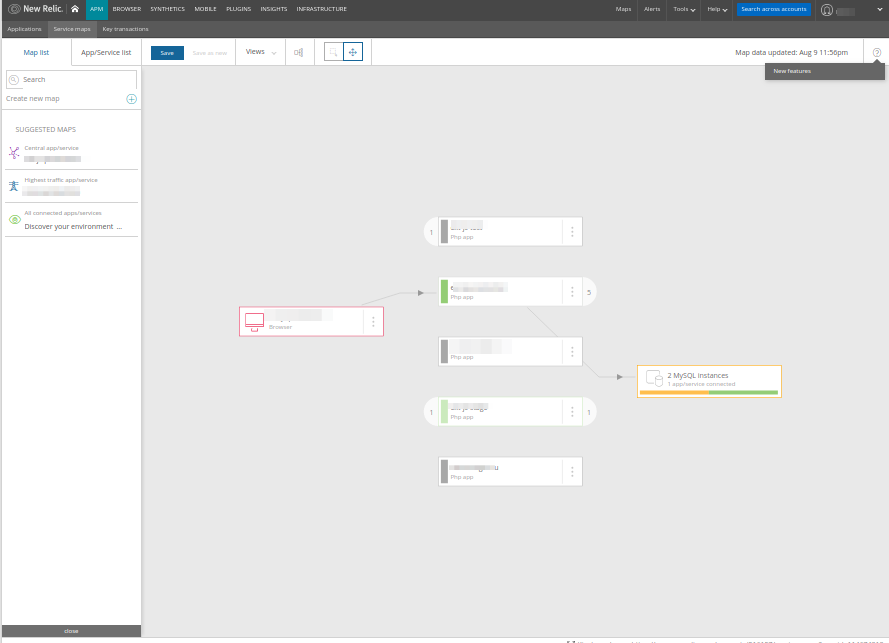
... et leur carte, à mon avis, est rendue plus simple et plus compréhensible: elle n'affiche pas les composants d'une application (ce qui la rendrait inutilement détaillée, comme dans le cas de Datadog), mais seulement des services ou microservices spécifiques.
Retour à Datadog: il ressort clairement de la carte de service que les demandes des utilisateurs parviennent à Django. Allons au service Django et voyons enfin ce que nous attendions:
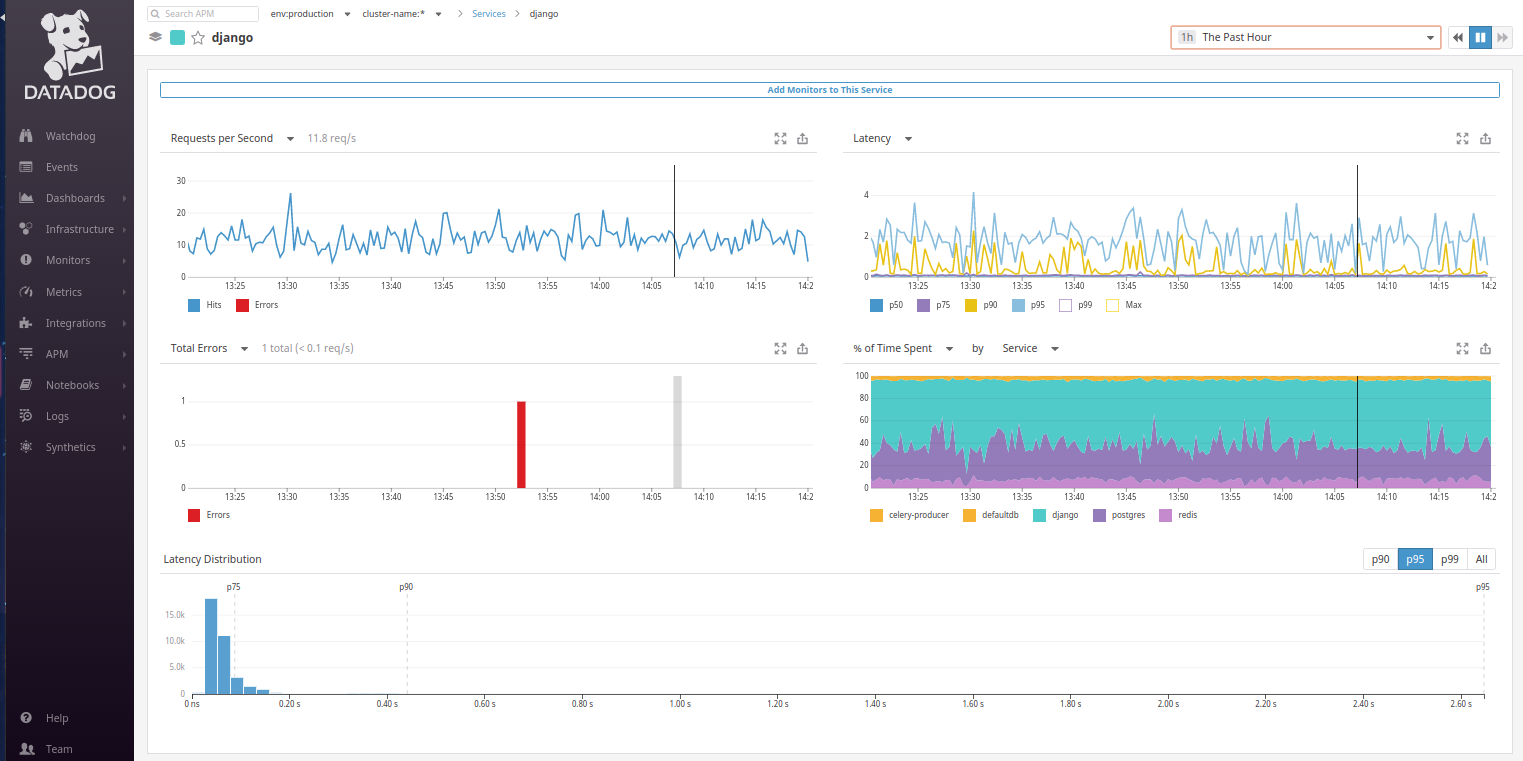
Malheureusement, par défaut, il n'y a pas de graphique de
temps de transaction Web similaire à celui que nous voyons sur le panneau principal de New Relic. Cependant, il peut être configuré à la place du graphique
% du temps passé . Il suffit de le passer en
temps moyen par demande par type ... et maintenant le tableau familier nous regarde!
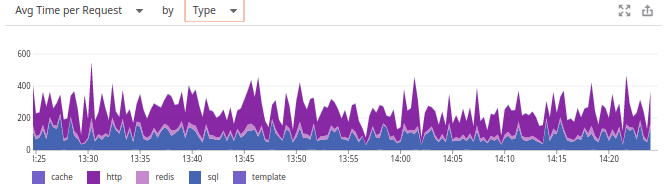
Pourquoi Datadog a opté pour un horaire différent est un mystère pour nous. Il était également frustrant que le système ne se souvienne pas du choix de l'utilisateur (contrairement aux deux concurrents), et donc que la création de panneaux personnalisés enregistre.
Mais j'ai été heureux de l'opportunité dans Datadog de passer de ces graphiques aux métriques des serveurs associés, de lire les journaux et d'évaluer la charge des gestionnaires de serveurs Web (Gunicorn). Tout est presque le même que dans New Relic ... et même quelques autres (journaux)!
Sous les graphiques se trouvent des transactions qui sont complètement similaires à New Relic:
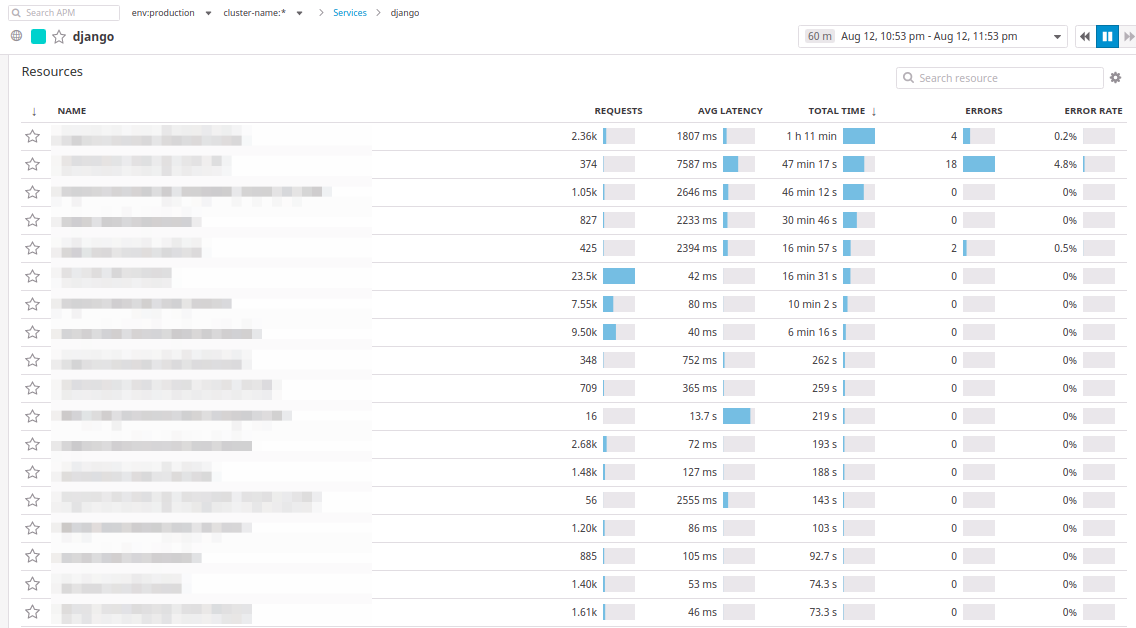
Dans Datadog, les transactions sont appelées
ressources . Vous pouvez trier les contrôleurs par le nombre de demandes, par le temps de réponse moyen, par le temps écoulé maximum pour une période de temps sélectionnée.
Vous pouvez étendre la ressource et voir tout ce que nous avons déjà observé dans New Relic:
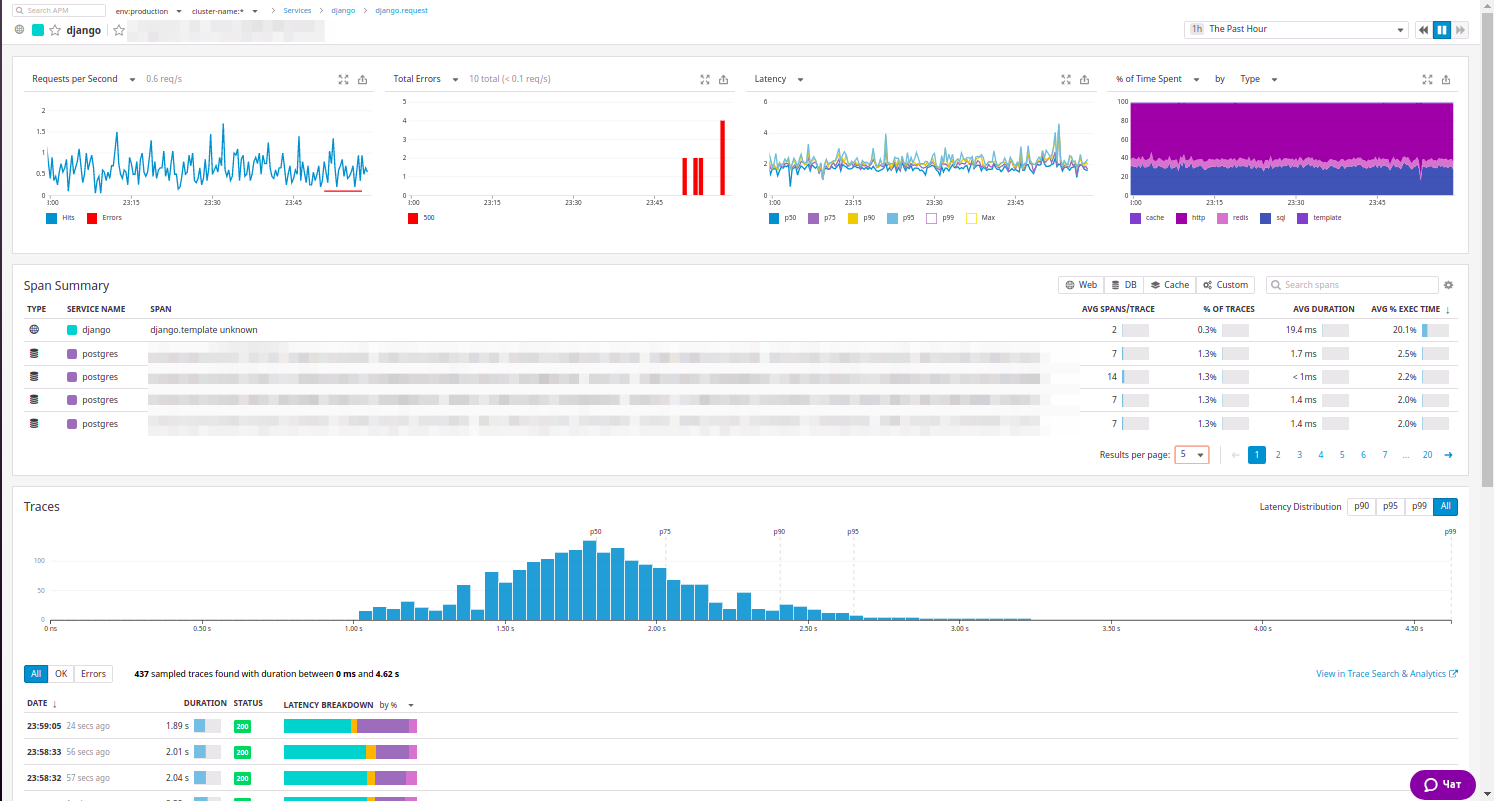
Il y a des statistiques sur la ressource, et une liste généralisée d'appels internes, et des exemples de demandes qui peuvent être triées par le code de réponse ... Au fait, nos ingénieurs ont vraiment aimé ce tri.
Tout exemple de ressource dans Datadog peut être développé et exploré:

Les paramètres de requête, un diagramme récapitulatif du temps écoulé pour chacun des composants et un diagramme en cascade, dans lequel la séquence d'appels est visible, sont présentés. De plus, le passage à l'arborescence du diagramme en cascade est également disponible:

Et la chose la plus intéressante est de visualiser la charge de l'hôte sur lequel la demande a été exécutée et de consulter les journaux des demandes.
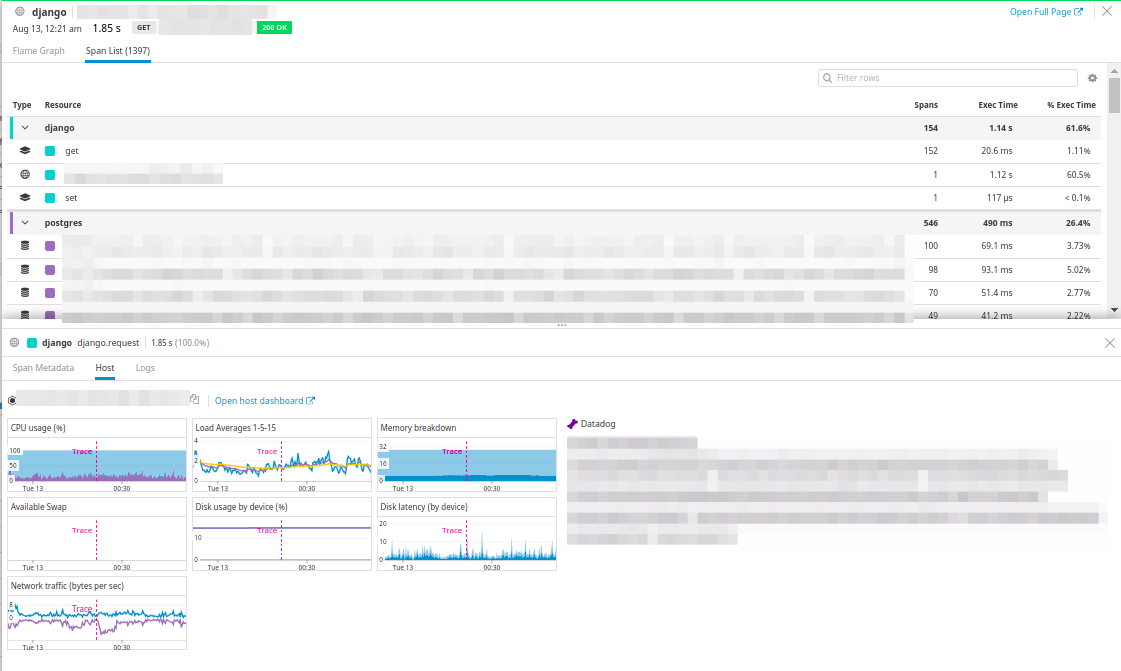
Grande intégration!
Vous vous demandez peut-être où se trouvent les onglets
Bases de données et
Services externes , comme dans New Relic. Ils ne sont pas là: puisque Datadog analyse l'application en composants, PostgreSQL sera considéré comme un
service distinct , et au lieu de Services externes, il vaut la peine de rechercher
aws.storage (il en sera de même pour tout autre service externe auquel l'application peut accéder).

Et voici un exemple avec
postgres :
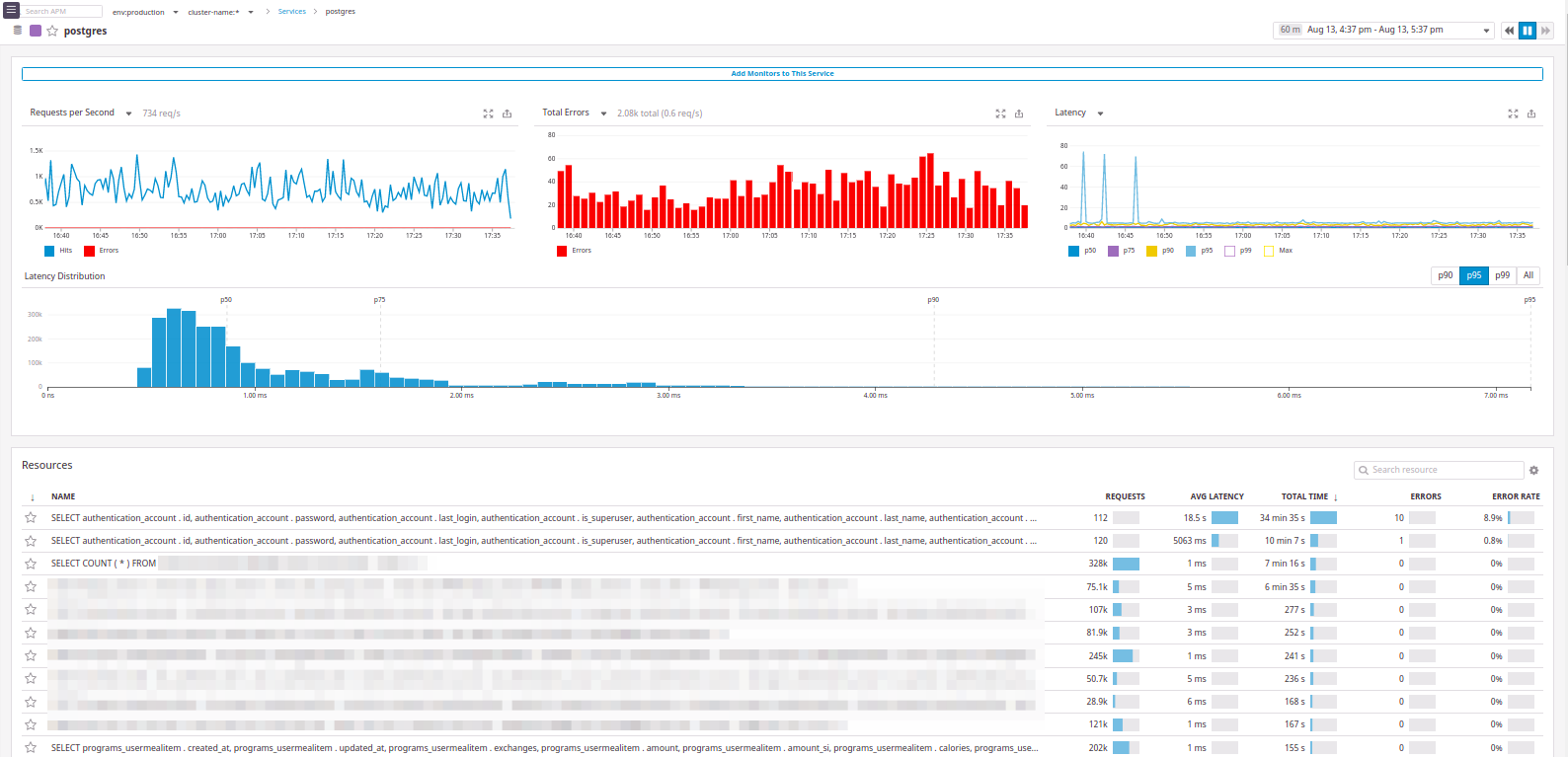
En fait, il y a tout ce que nous voulions:
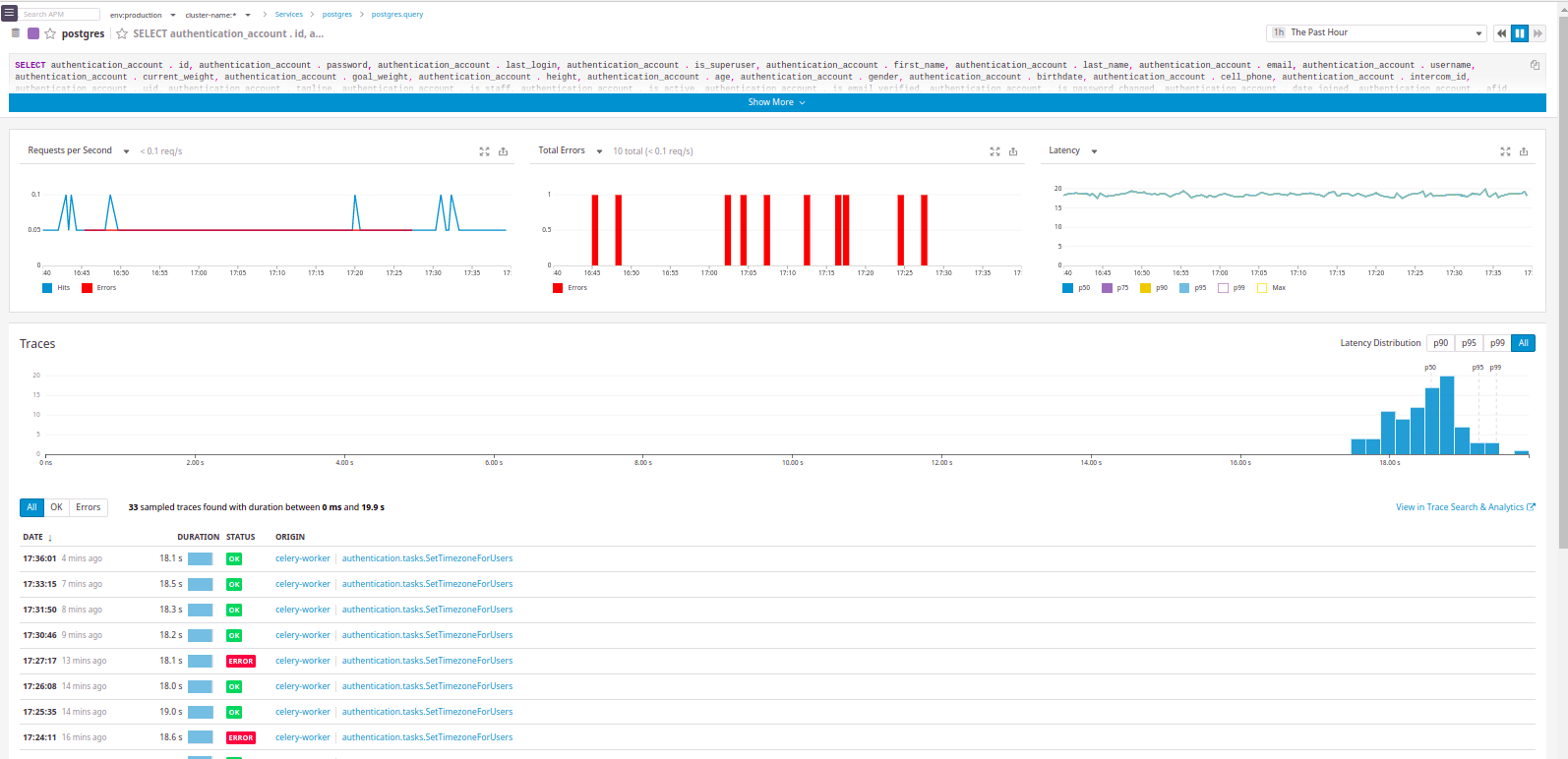
On peut voir de quel "service" la demande provient.
Il ne sera pas superflu de rappeler que Datadog s'intègre parfaitement à NGINX Ingress et permet un suivi de bout en bout à partir du moment où une demande arrive dans le cluster, et vous permet également d'accepter des métriques statsd, de collecter des journaux et des métriques hôtes.
Un énorme avantage de Datadog est que son prix
comprend l' infrastructure de surveillance, l'APM, la gestion des journaux et le test des synthétiques, c'est-à-dire Vous pouvez choisir un plan de manière flexible.
2. Atatus
L'équipe d'Atatus affirme que son service est "le même que New Relic, mais meilleur". Voyons voir si c'est vraiment le cas.
La barre de titre est vraiment la même, mais il n'a pas été possible de déterminer le Redis et le memcached utilisés dans l'application.
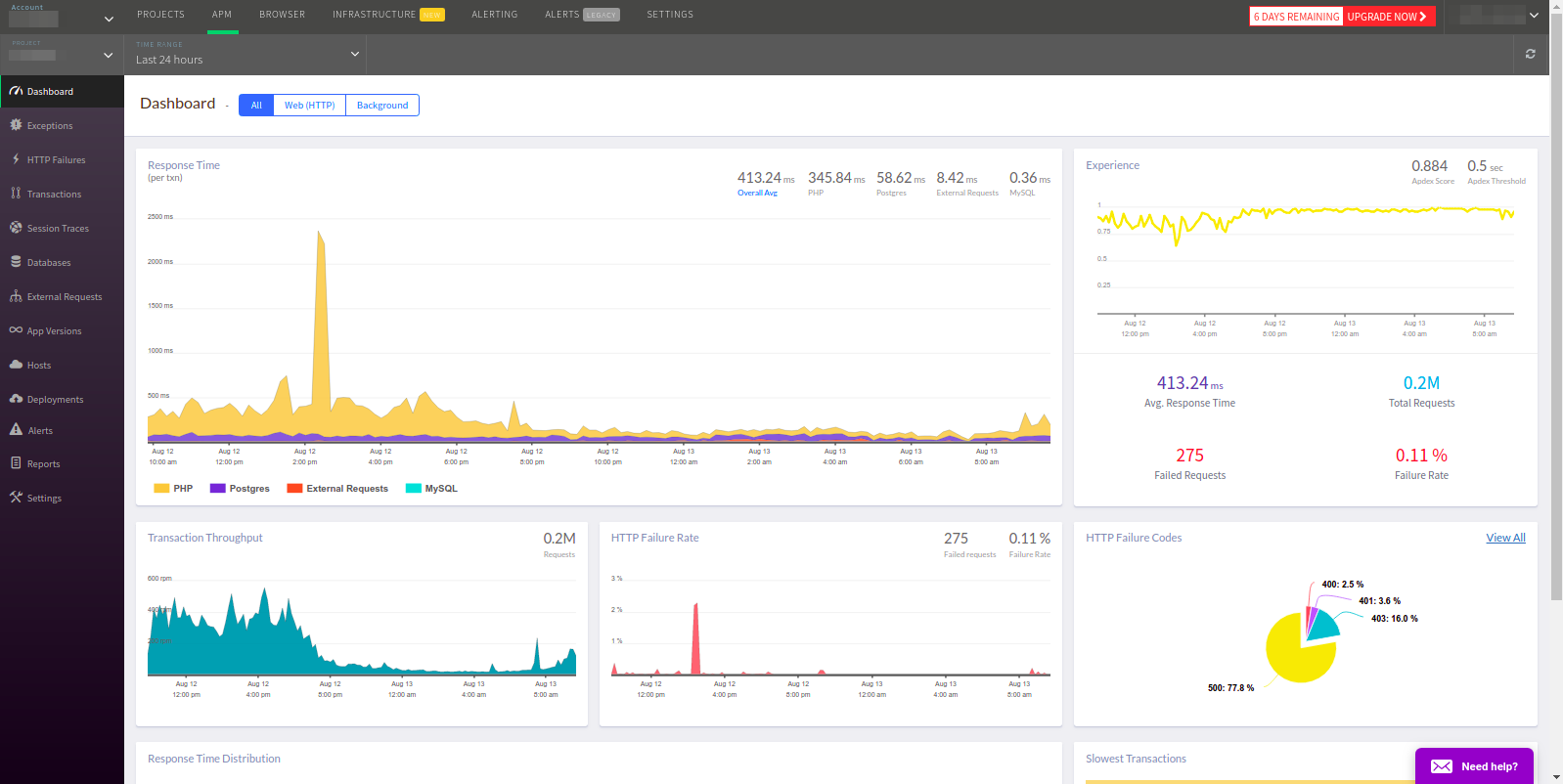
APM sélectionne toutes les transactions par défaut, bien que seul le Web soit généralement nécessaire. Comme dans Datadog, il n'y a aucun moyen d'accéder au service souhaité depuis le panneau principal. De plus, les transactions sont répertoriées après les erreurs, ce qui pour APM ne semble pas très logique.
Dans les transactions Atatus, tout est aussi similaire à New Relic que possible. Moins - vous ne pouvez pas voir immédiatement la dynamique de chacun des contrôleurs. Vous devez le rechercher dans la table du contrôleur, en le triant par le
plus de temps consommé :

La liste habituelle des contrôleurs est disponible dans l'onglet
Explorer :
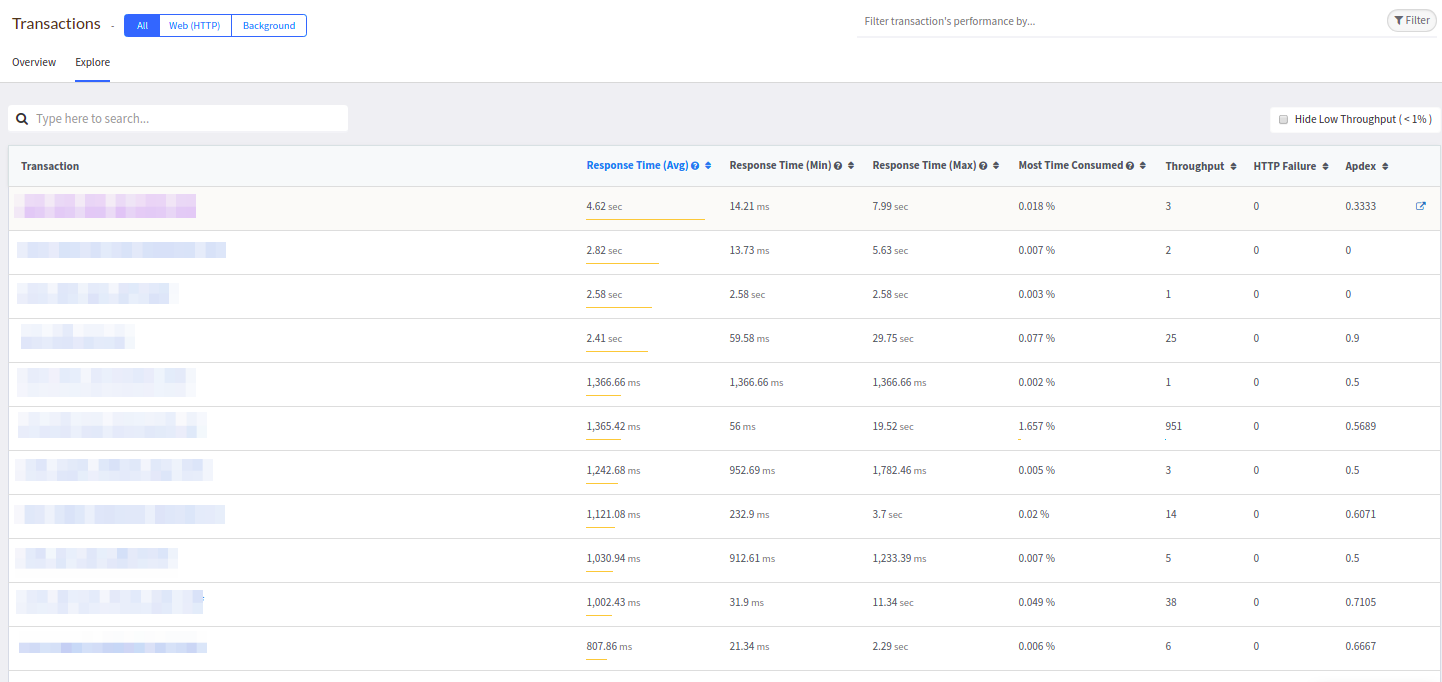
À certains égards, ce tableau ressemble à Datadog et ressemble plus à celui de New Relic.
Chaque transaction peut être déployée et voir ce que l'application a fait:

Le panneau ressemble également plus à Datadog: il existe un certain nombre de demandes, une image globale des appels. Le volet supérieur fournit un onglet avec
des erreurs d'
échecs HTTP et des exemples de demandes de
traces de session lentes:

Si vous entrez dans une transaction, vous pouvez voir un exemple de trace, vous pouvez obtenir une liste de requêtes dans la base de données et voir les en-têtes de demande. Tout est similaire à New Relic:

En général, Atatus était satisfait des traces détaillées - sans le collage typique des appels New Relic dans un bloc de rappel:
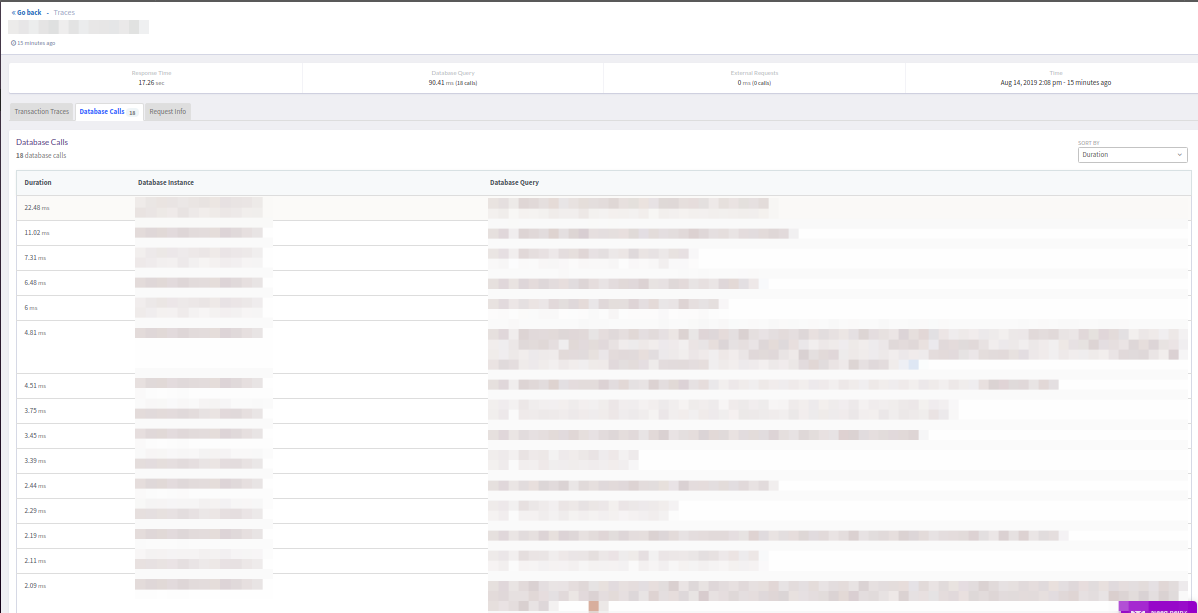
Cependant, il n'y a pas assez de filtre qui (comme dans New Relic) couperait les requêtes ultrarapides (<5 ms). En revanche, l'affichage de la réponse finale de la transaction (réussie ou erreur) était agréable.
Le panneau
Bases de données vous aidera à examiner les demandes de bases de données externes effectuées par l'application. Permettez-moi de vous rappeler qu'Atatus n'a trouvé que PostgreSQL et MySQL, bien que Redis et memcached soient également impliqués dans le projet.
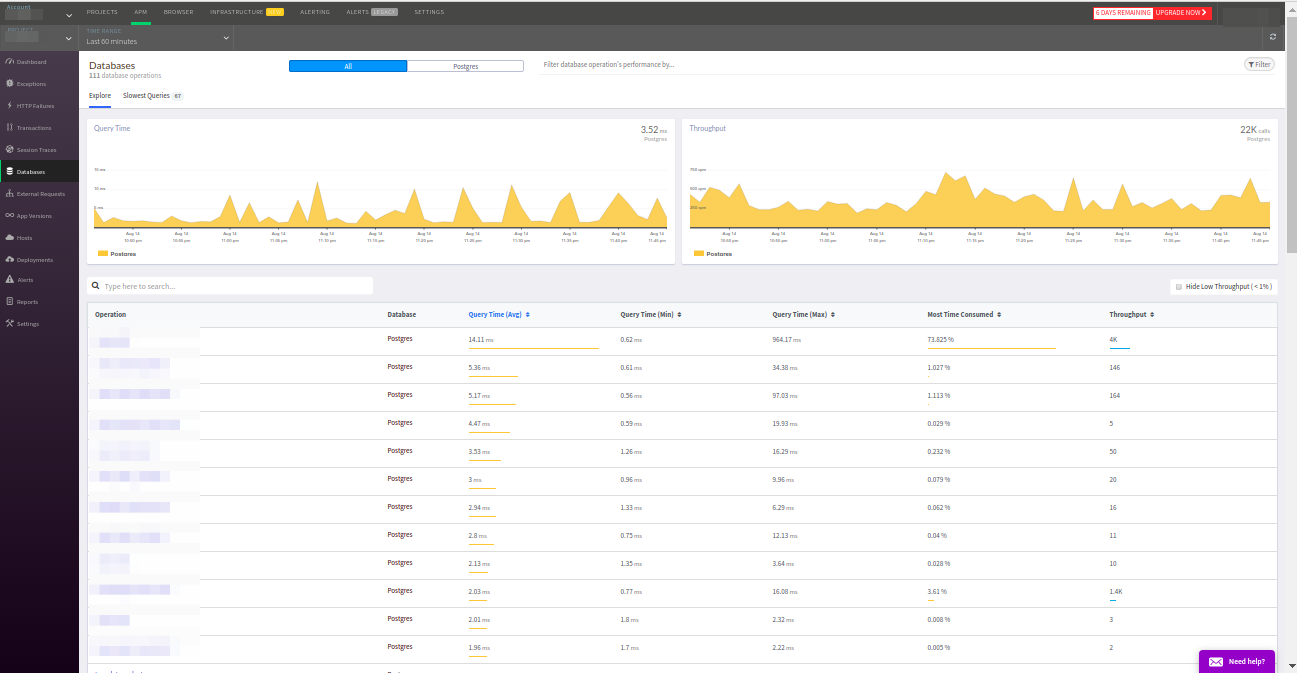
Les demandes sont triées selon les critères habituels: fréquence de réponse, temps de réponse moyen, etc. Je voudrais également noter l'onglet avec les requêtes les plus lentes - c'est très pratique. De plus, les données de cet onglet pour PostgreSQL ont coïncidé avec les données de l'extension
pg_stat_statements - un excellent résultat!
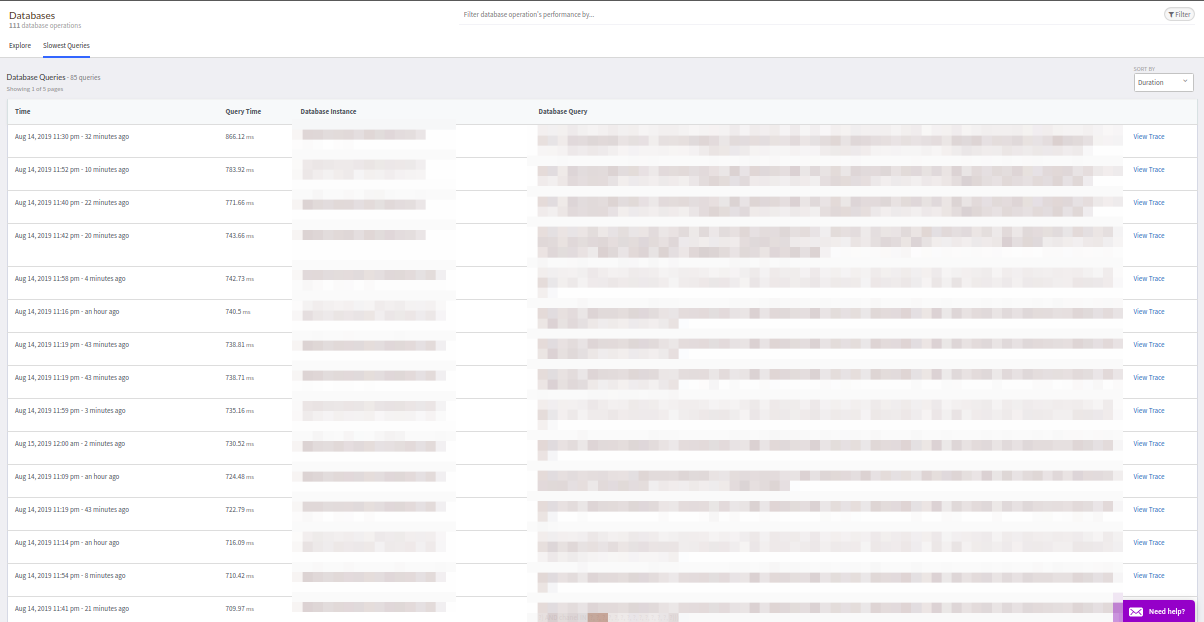
L'onglet
Demandes externes est identique à Bases de données.
Conclusions
Les deux outils présentés ont bien fonctionné dans le rôle d'APM. Chacun d'eux peut offrir le minimum nécessaire. Résumez brièvement nos impressions comme suit:
Datadog
Avantages:
- barème tarifaire pratique (l'APM coûte 31 USD par hôte);
- bien joué avec Python;
- possibilité d'intégration avec OpenTracing
- Intégration Kubernetes
- Intégration avec NGINX Ingress.
Inconvénients:
- Le seul APM qui a causé l'inaccessibilité de l'application en raison d'une erreur de module (predis)
- outils auto PHP faibles;
- définition en partie étrange des services et de leur finalité.
Atatus
Avantages:
- instrumentation profonde de PHP;
- Nouvelle interface utilisateur de type relique.
Inconvénients:
- ne fonctionne pas sur les anciens systèmes d'exploitation (Ubuntu 12.05, CentOS 5);
- outils automatiques faibles;
- prise en charge de seulement deux langues (Node.js et PHP);
- fonctionnement lent de l'interface.
Compte tenu du prix Atatus de 69 USD par mois et par serveur, nous préférerions utiliser Datadog, qui s'intègre parfaitement à nos besoins (applications web en K8) et possède de nombreuses fonctionnalités utiles.
PS
Lisez aussi dans notre blog: