
Dans cet article, je voudrais proposer une alternative au style de conception de test traditionnel en utilisant des concepts de programmation fonctionnelle dans Scala. Cette approche a été inspirée par de nombreux mois de douleur dus au maintien de dizaines de tests échoués et à un désir ardent de les rendre plus simples et plus compréhensibles.
Même si le code est en Scala, les idées proposées conviennent aux développeurs et aux ingénieurs d'assurance qualité qui utilisent des langages prenant en charge la programmation fonctionnelle. Vous pouvez trouver un lien Github avec la solution complète et un exemple à la fin de l'article.
Le problème
Si vous avez déjà dû faire face à des tests (peu importe lesquels: tests unitaires, intégratifs ou fonctionnels), ils ont probablement été écrits sous la forme d'un ensemble d'instructions séquentielles. Par exemple:
D'après mon expérience, cette façon d'écrire des tests est préférée par la plupart des développeurs. Notre projet compte environ un millier de tests à différents niveaux d'isolement, et tous ont été écrits dans un tel style jusqu'à tout récemment. Au fur et à mesure que le projet progressait, nous avons commencé à remarquer de graves problèmes et des ralentissements dans la maintenance de ces tests: les corriger prendrait au moins le même temps que l'écriture du code de production.
Lors de l'écriture de nouveaux tests, nous avons toujours dû trouver des moyens de préparer les données à partir de zéro, généralement en copiant et en collant les étapes des tests voisins. En conséquence, lorsque le modèle de données de l'application changerait, le château de cartes s'effondrerait et nous devions réparer chaque test qui échouait: dans le pire des cas - en plongeant profondément dans chaque test et en le réécrivant.
Lorsqu'un test échoue «honnêtement» - c'est-à-dire en raison d'un bug réel dans la logique métier - comprendre ce qui s'est mal passé sans débogage est impossible. Parce que les tests étaient si difficiles à comprendre, personne n'avait toujours la connaissance complète de la façon dont le système est censé se comporter.
Toute cette douleur, à mon avis, est un symptôme des deux problèmes les plus profonds de cette conception de test:
- Il n'y a pas de structure claire et pratique pour les tests. Chaque test est un flocon de neige unique. Le manque de structure conduit à la verbosité, qui consomme beaucoup de temps et démotive. Des détails insignifiants détournent l'attention de ce qui est le plus important - l'exigence que le test affirme. Le copier-coller devient la principale approche pour écrire de nouveaux cas de test.
- Les tests n'aident pas les développeurs à localiser les défauts; ils signalent seulement qu'il y a un problème quelconque. Pour comprendre l'état dans lequel le test est exécuté, vous devez le tracer dans votre tête ou utiliser un débogueur.
Modélisation
Pouvons-nous faire mieux? (Alerte spoiler: nous le pouvons.) Voyons quel type de structure ce test peut avoir.
val db: Database = Database.forURL(TestConfig.generateNewUrl()) migrateDb(db) insertUser(db, id = 1, name = "test", role = "customer") insertPackage(db, id = 1, name = "test", userId = 1, status = "new") insertPackageItems(db, id = 1, packageId = 1, name = "test", price = 30) insertPackageItems(db, id = 2, packageId = 1, name = "test", price = 20) insertPackageItems(db, id = 3, packageId = 1, name = "test", price = 40)
En règle générale, le code testé attend certains paramètres explicites (identifiants, tailles, montants, filtres, pour n'en nommer que quelques-uns), ainsi que certaines données externes (à partir d'une base de données, d'une file d'attente ou d'un autre service du monde réel). Pour que notre test fonctionne de manière fiable, il a besoin d'un appareil - un état pour mettre le système, les fournisseurs de données, ou les deux.
Avec ce luminaire, nous préparons une dépendance pour initialiser le code sous test - remplir une base de données, créer une file d'attente d'un type particulier, etc.
val svc = new SomeProductionLogic(db) val result = svc.calculatePrice(packageId = 1)
Après avoir exécuté le code sous test sur certains paramètres d'entrée, nous recevons une sortie - à la fois explicite (retournée par le code sous test) et implicite (les changements d'état).
result shouldBe 90
Enfin, nous vérifions que la sortie est conforme aux attentes, en terminant le test avec une ou plusieurs assertions .
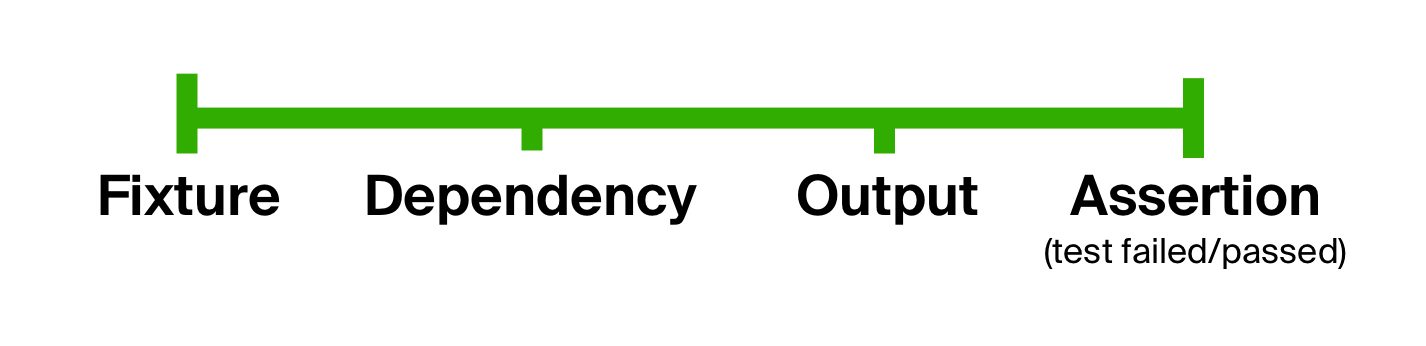
On peut conclure que les tests se composent généralement des mêmes étapes: préparation des entrées, exécution du code et assertion des résultats. Nous pouvons utiliser ce fait pour nous débarrasser du premier problème de nos tests , c'est-à-dire une forme trop libérale, en divisant explicitement le corps d'un test en étapes. Une telle idée n'est pas nouvelle, comme on peut le voir dans les tests de style BDD ( développement axé sur le comportement ).
Qu'en est-il de l'extensibilité? Toute étape du processus de test peut, à son tour, contenir n'importe quelle quantité d'intermédiaires. Par exemple, nous pourrions prendre une grande et compliquée étape, comme construire un luminaire, et le diviser en plusieurs, enchaînés les uns après les autres. De cette façon, le processus de test peut être extensible à l'infini, mais en fin de compte toujours composé des mêmes quelques étapes générales.

Exécution de tests
Essayons d'implémenter l'idée de diviser le test en étapes, mais d'abord, nous devons déterminer quel type de résultat nous aimerions voir.
Dans l'ensemble, nous aimerions que la rédaction et la maintenance des tests deviennent moins laborieuses et plus agréables. Moins un test contient d'instructions explicites non uniques, moins il faudrait y apporter de modifications après avoir changé de contrat ou refactorisé, et moins il faudrait de temps pour lire le test. La conception du test doit favoriser la réutilisation des extraits de code courants et décourager le copier-coller insensé. Il serait également intéressant que les tests aient une forme unifiée. La prévisibilité améliore la lisibilité et fait gagner du temps. Par exemple, imaginez combien de temps encore faudrait-il aux aspirants scientifiques pour apprendre toutes les formules si les manuels les faisaient écrire librement dans un langage commun, par opposition aux mathématiques.
Ainsi, notre objectif est de cacher tout ce qui est gênant et inutile, en ne laissant que ce qui est d'une importance cruciale pour la compréhension: ce qui est testé, quelles sont les entrées et les sorties attendues.
Revenons à notre modèle de structure du test.
Techniquement, chaque étape peut être représentée par un type de données, et chaque transition - par une fonction. Pour passer du type de données initial au type final, il est possible d'appliquer chaque fonction au résultat de la précédente. En d'autres termes, en utilisant la composition des fonctions de préparation des données (appelons-les prepare ), l'exécution de code ( execute ) et la vérification du résultat attendu ( check ). L'entrée pour cette composition serait la toute première étape - le luminaire. Appelons la fonction résultante d'ordre supérieur la fonction de cycle de vie de test .
Tester la fonction de cycle de vie def runTestCycle[FX, DEP, OUT, F[_]]( fixture: FX, prepare: FX => DEP, execute: DEP => OUT, check: OUT => F[Assertion] ): F[Assertion] =
Une question se pose, d'où viennent ces certaines fonctions? Eh bien, en ce qui concerne la préparation des données, il n'y a qu'un nombre limité de façons de le faire - remplir une base de données, se moquer, etc. Ainsi, il est pratique d'écrire des variantes spécialisées de la fonction de prepare partagées entre tous les tests. En conséquence, il serait plus facile de créer des fonctions de cycle de vie de test spécialisées pour chaque cas, ce qui masquerait les mises en œuvre concrètes de la préparation des données. Étant donné que l'exécution et les assertions de code sont plus ou moins uniques pour chaque test (ou groupe de tests), l' execute et la check doivent être écrites à chaque fois explicitement.
Fonction de test du cycle de vie adaptée pour les tests d'intégration sur une base de données En déléguant toutes les nuances administratives à la fonction de cycle de vie du test, nous avons la possibilité d'étendre le processus de test sans toucher à un test donné. En utilisant la composition des fonctions, nous pouvons interférer à n'importe quelle étape du processus et extraire ou ajouter des données.
Pour mieux illustrer les capacités d'une telle approche, résolvons le deuxième problème de notre test initial - le manque d'informations supplémentaires pour identifier les problèmes. Ajoutons la journalisation de l'exécution du code retournée. Notre journalisation ne changera pas le type de données; cela ne produit qu'un effet secondaire - la sortie d'un message sur la console. Après l'effet secondaire, nous le renvoyons tel quel.
Test de la fonction de cycle de vie avec journalisation def logged[T](implicit loggedT: Logged[T]): T => T = (that: T) => {
Avec cette simple modification, nous avons ajouté la journalisation de la sortie du code exécuté dans chaque test . L'avantage de ces petites fonctions est qu'elles sont faciles à comprendre, à composer et à éliminer en cas de besoin.

En conséquence, notre test ressemble maintenant à ceci:
val fixture: SomeMagicalFixture = ???
Le corps du test est devenu concis, le montage et les contrôles peuvent être réutilisés dans d'autres tests, et nous ne préparons plus la base de données manuellement nulle part. Un seul petit problème subsiste ...
Préparation du luminaire
Dans le code ci-dessus, nous travaillions en supposant que le luminaire nous serait donné de quelque part. Étant donné que les données sont l'ingrédient essentiel des tests maintenables et simples, nous devons aborder la façon de les rendre facilement.
Supposons que notre magasin en cours de test possède une base de données relationnelle de taille moyenne (par souci de simplicité, dans cet exemple, il n'a que 4 tables, mais en réalité, il peut en avoir des centaines). Certaines tables contiennent des données référentielles, d'autres des données métier, et tout cela peut être logiquement regroupé en une ou plusieurs entités complexes. Les relations sont liées avec des clés étrangères , pour créer un Bonus , un Package est nécessaire, qui à son tour a besoin d'un User , etc.

Les solutions de contournement et les hacks ne conduisent qu'à une incohérence des données et, par conséquent, à des heures et des heures de débogage. Pour cette raison, nous n'apportons aucune modification au schéma.
Nous pourrions utiliser certaines méthodes de production pour le remplir, mais même sous un examen superficiel, cela soulève beaucoup de questions difficiles. Qu'est-ce qui préparera les données des tests pour ce code de production? Devrions-nous réécrire les tests si le contrat de ce code change? Que se passe-t-il si les données proviennent entièrement d'un autre endroit et qu'aucune méthode n'est utilisée? Combien de demandes faudrait-il pour créer une entité qui dépend de bien d'autres?
Base de données remplissant le test initial insertUser(db, id = 1, name = "test", role = "customer") insertPackage(db, id = 1, name = "test", userId = 1, status = "new") insertPackageItems(db, id = 1, packageId = 1, name = "test", price = 30) insertPackageItems(db, id = 2, packageId = 1, name = "test", price = 20) insertPackageItems(db, id = 3, packageId = 1, name = "test", price = 40)
Les méthodes auxiliaires dispersées, comme celles de notre tout premier exemple, sont le même problème sous une apparence différente. Ils nous confient la responsabilité de gérer les dépendances que nous essayons d'éviter.
Idéalement, nous aimerions une structure de données qui présenterait l'état de l'ensemble du système en un coup d'œil. Un bon candidat serait une table (ou un ensemble de données , comme en PHP ou Python) qui n'aurait rien de plus que des champs critiques pour la logique métier. S'il change, la maintenance des tests serait facile: nous modifions simplement les champs dans l'ensemble de données. Exemple:
val dataTable: Seq[DataRow] = Table( ("Package ID", "Customer's role", "Item prices", "Bonus value", "Expected final price") , (1, "customer", Vector(40, 20, 30) , Vector.empty , 90.0) , (2, "customer", Vector(250) , Vector.empty , 225.0) , (3, "customer", Vector(100, 120, 30) , Vector(40) , 210.0) , (4, "customer", Vector(100, 120, 30, 100) , Vector(20, 20) , 279.0) , (5, "vip" , Vector(100, 120, 30, 100, 50), Vector(10, 20, 10), 252.0) )
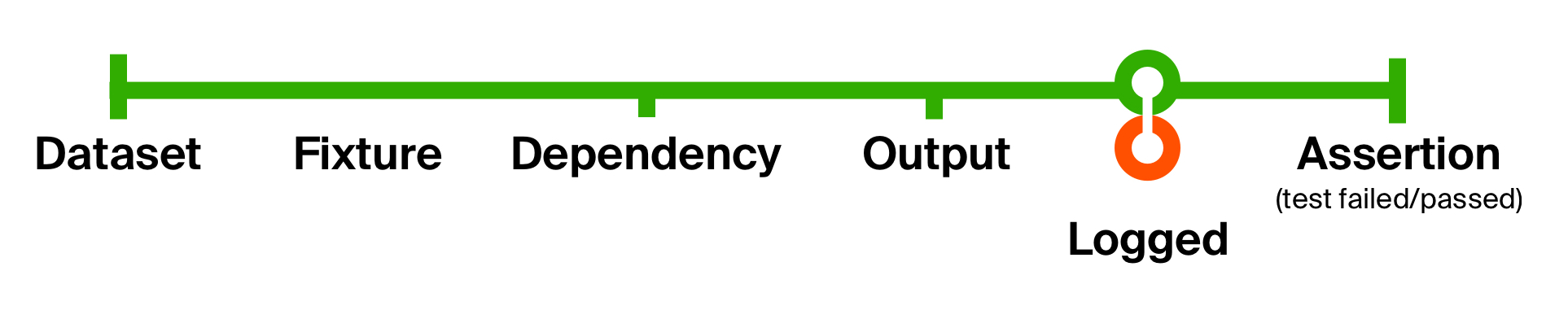
À partir de notre table, nous créons des clés - liens d'entité par ID. Si une entité dépend d'une autre, une clé pour cette autre entité est également créée. Il peut arriver que deux entités différentes créent une dépendance avec le même ID, ce qui peut entraîner une violation de clé primaire . Cependant, à ce stade, il est incroyablement bon marché de dédupliquer les clés - car elles ne contiennent que des ID, nous pouvons les placer dans une collection qui fait la déduplication pour nous, par exemple, un Set . Si cela s'avère insuffisant, nous pouvons toujours implémenter une déduplication plus intelligente en tant que fonction distincte et la composer dans la fonction de cycle de vie de test.
Clés (exemple) sealed trait Key case class PackageKey(id: Int, userId: Int) extends Key case class PackageItemKey(id: Int, packageId: Int) extends Key case class UserKey(id: Int) extends Key case class BonusKey(id: Int, packageId: Int) extends Key
La génération de fausses données pour les champs (par exemple, les noms) est déléguée à une classe distincte. Ensuite, en utilisant cette classe et les règles de conversion pour les clés, nous obtenons les objets Row destinés à être insérés dans la base de données.
Lignes (exemple) object SampleData { def name: String = "test name" def role: String = "customer" def price: Int = 1000 def bonusAmount: Int = 0 def status: String = "new" } sealed trait Row case class PackageRow(id: Int, name: String, userId: Int, status: String) extends Row case class PackageItemRow(id: Int, packageId: Int, name: String, price: Int) extends Row case class UserRow(id: Int, name: String, role: String) extends Row case class BonusRow(id: Int, packageId: Int, bonusAmount: Int) extends Row
Les fausses données ne sont généralement pas suffisantes, nous avons donc besoin d'un moyen de remplacer des champs spécifiques. Heureusement, les lentilles sont exactement ce dont nous avons besoin - nous pouvons les utiliser pour parcourir toutes les lignes créées et modifier uniquement les champs dont nous avons besoin. Les verres étant des fonctions déguisées, nous pouvons les composer comme d'habitude, ce qui est leur point fort.
Lense (exemple) def changeUserRole(userId: Int, newRole: String): Set[Row] => Set[Row] = (rows: Set[Row]) => rows.modifyAll(_.each.when[UserRow]) .using(r => if (r.id == userId) r.modify(_.role).setTo(newRole) else r)
Grâce à la composition, nous pouvons appliquer différentes optimisations et améliorations à l'intérieur du processus: par exemple, nous pourrions regrouper des lignes par la table pour les insérer avec un seul INSERT pour réduire le temps d'exécution du test ou enregistrer l'intégralité de l'état de la base de données.
Fonction de préparation du luminaire def makeFixture[STATE, FX, ROW, F[_]]( state: STATE, applyOverrides: F[ROW] => F[ROW] = x => x ): FX = (extractKeys andThen deduplicateKeys andThen enrichWithSampleData andThen applyOverrides andThen logged andThen buildFixture) (state)
Enfin, le tout nous fournit un appareil. Dans le test lui-même, rien de plus n'est affiché, à l'exception du jeu de données initial - tous les détails sont masqués par la composition de la fonction.

Notre suite de tests ressemble maintenant à ceci:
val dataTable: Seq[DataRow] = Table( ("Package ID", "Customer's role", "Item prices", "Bonus value", "Expected final price") , (1, "customer", Vector(40, 20, 30) , Vector.empty , 90.0) , (2, "customer", Vector(250) , Vector.empty , 225.0) , (3, "customer", Vector(100, 120, 30) , Vector(40) , 210.0) , (4, "customer", Vector(100, 120, 30, 100) , Vector(20, 20) , 279.0) , (5, "vip" , Vector(100, 120, 30, 100, 50), Vector(10, 20, 10), 252.0) ) "If the buyer's role is" - { "a customer" - { "And the total price of items" - { "< 250 after applying bonuses - no discount" - { "(case: no bonuses)" in calculatePriceFor(dataTable, 1) "(case: has bonuses)" in calculatePriceFor(dataTable, 3) } ">= 250 after applying bonuses" - { "If there are no bonuses - 10% off on the subtotal" in calculatePriceFor(dataTable, 2) "If there are bonuses - 10% off on the subtotal after applying bonuses" in calculatePriceFor(dataTable, 4) } } } "a vip - then they get a 20% off before applying bonuses and then all the other rules apply" in calculatePriceFor(dataTable, 5) }
Et le code d'assistance:
L'ajout de nouveaux cas de test dans le tableau est une tâche triviale qui nous permet de nous concentrer sur la couverture de plus de cas marginaux et non sur l'écriture de code standard.
Réutilisation de la préparation des luminaires sur différents projets
D'accord, nous avons donc écrit beaucoup de code pour préparer des appareils dans un projet spécifique, en passant un certain temps dans le processus. Et si nous avons plusieurs projets? Sommes-nous condamnés à réinventer le tout à partir de zéro à chaque fois?
Nous pouvons résumer la préparation du luminaire sur un modèle de domaine concret. Dans le monde de la programmation fonctionnelle, il existe un concept de typeclasses . Sans entrer dans les détails, elles ne sont pas comme des classes dans la POO, mais plutôt comme des interfaces dans la mesure où elles définissent un certain comportement d'un certain groupe de types. La différence fondamentale est qu'ils ne sont pas hérités mais plutôt instanciés comme des variables. Cependant, comme pour l'héritage, la résolution des instances de classe de types se produit au moment de la compilation . En ce sens, les classes de types peuvent être appréhendées comme les méthodes d'extension de Kotlin et C # .
Pour enregistrer un objet, nous n'avons pas besoin de savoir ce qu'il contient, ses champs et ses méthodes. Tout ce qui nous importe, c'est d'avoir un log() comportements log() avec une signature particulière. L'extension de chaque classe avec une interface Logged serait extrêmement fastidieuse et même impossible dans de nombreux cas - par exemple, pour les bibliothèques ou les classes standard. Avec les classes de caractères, c'est beaucoup plus facile. Nous pouvons créer une instance d'une classe de type appelée Logged, par exemple, pour un appareil pour la consigner dans un format lisible par l'homme. Pour tout le reste qui n'a pas d'instance de Logged nous pouvons fournir une solution de secours: une instance de type Any qui utilise gratuitement une méthode standard toString() pour enregistrer chaque objet dans sa représentation interne.
Un exemple de la classe de types Logged et ses instances trait Logged[A] { def log(a: A)(implicit logger: Logger): A }
Outre la journalisation, nous pouvons utiliser cette approche tout au long du processus de fabrication des luminaires. Notre solution propose une manière abstraite de faire des montages de base de données et un ensemble de classes de types pour aller avec. C'est le projet qui utilise la responsabilité de la solution pour implémenter les instances de ces classes de type pour que tout fonctionne.
Lors de la conception de cet outil de préparation de luminaire, j'ai utilisé les principes SOLID comme boussole pour m'assurer qu'il est maintenable et extensible:
- Le principe de responsabilité unique : chaque classe de type décrit un et un seul comportement d'un type.
- Le principe ouvert / fermé : nous ne modifions aucune des classes de production; à la place, nous les étendons avec des instances de typeclasses.
- Le principe de substitution de Liskov ne s'applique pas ici car nous n'utilisons pas d'héritage.
- Le principe de ségrégation des interfaces : nous utilisons de nombreuses classes de caractères spécialisées par opposition à une classe globale.
- Le principe d'inversion des dépendances : la fonction de préparation des luminaires ne dépend pas des types concrets, mais plutôt des classes de types abstraites.
Après avoir vérifié que tous les principes sont satisfaits, nous pouvons supposer en toute sécurité que notre solution est suffisamment maintenable et extensible pour être utilisée dans différents projets.
Après avoir écrit la fonction de cycle de vie des tests et la solution pour la préparation des luminaires, qui est également indépendante d'un modèle de domaine concret sur une application donnée, nous sommes tous prêts à améliorer tous les tests restants.
Conclusion
Nous sommes passés du style de conception de test traditionnel (étape par étape) au style fonctionnel. Le style étape par étape est utile dès le début et dans les projets de plus petite taille, car il ne limite pas les développeurs et ne nécessite aucune connaissance spécialisée. Cependant, lorsque le nombre de tests devient trop important, un tel style a tendance à tomber. L'écriture de tests dans le style fonctionnel ne résoudra probablement pas tous vos problèmes de test, mais cela pourrait considérablement améliorer la mise à l'échelle et la maintenance des tests dans les projets, où il y en a des centaines ou des milliers. Les tests qui sont écrits dans le style fonctionnel se révèlent plus concis et axés sur les éléments essentiels (tels que les données, le code sous test et le résultat attendu), pas sur les étapes intermédiaires.
De plus, nous avons exploré à quel point la composition fonctionnelle et les classes de caractères peuvent être puissantes dans la programmation fonctionnelle. Avec leur aide, il est assez simple de concevoir des solutions en pensant à l'extensibilité et à la réutilisabilité.
Depuis l'adoption du style il y a plusieurs mois, notre équipe a dû faire des efforts d'adaptation, mais au final, nous avons apprécié le résultat. Les nouveaux tests sont écrits plus rapidement, les journaux rendent la vie beaucoup plus confortable et les ensembles de données sont pratiques pour vérifier chaque fois qu'il y a des questions sur les subtilités de certaines logiques. Notre équipe vise à passer progressivement tous les tests à ce nouveau style.
Lien vers la solution et un exemple complet peut être trouvé ici: Github . Amusez-vous avec vos tests!