"Consultant +" - un système de référence pour les avocats, les comptables, etc. Cela fonctionne de manière stable comme une montre. Dans cet article, il est suggéré de régler cette horloge un peu en fonction de vos besoins en termes de sortie de texte, à savoir: regardez comment vous pouvez traiter les informations de texte que le système donne avec python. En cours de route, travaillez avec les éléments de texte déclarés dans le titre.
Ombre sur la clôture
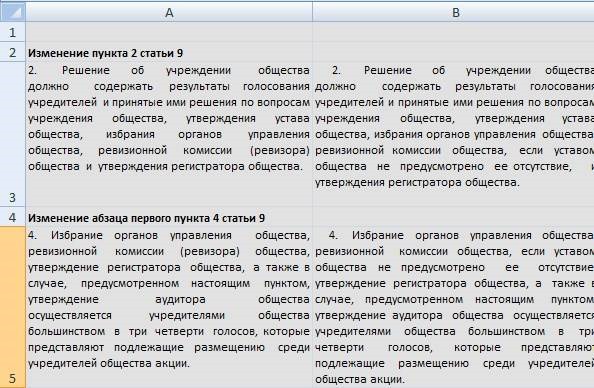
En tant qu'avocat qui travaille depuis longtemps avec le programme d'aide «Consultant +», je manquais toujours de la fonction habituelle dans ce système. Cette fonction était la suivante. Lorsqu'un changement apparaît dans l'acte réglementaire, les employés de K + affichent un aperçu des changements sous la forme de deux colonnes de texte:

La colonne de gauche est ce qu'elle était avant, la colonne de droite est la norme qui est maintenant en vigueur. Maintenant (il y a quelques années), la fonctionnalité a été mise à jour et les modifications sont mises
en évidence
en gras et immédiatement visibles. Tout cela est très pratique. Mais il y a des choses inconfortables.
Premièrement, certaines normes ne sont pas données, car leur volume est trop important pour les employés de K + et vous devez accéder aux liens système, et deuxièmement, vous ne pouvez pas simplement prendre et copier ces deux colonnes en les collant dans un tableau Excel ou Word standard.
Peut-être que cela a été fait intentionnellement pour que les utilisateurs travaillent plus activement avec le système, y compris pour ne rien transférer de là.
Il faut bien le réparer.
La tâche : répartir le texte en deux colonnes, là où c'est possible et où non - supprimez simplement la norme et mettez tout cela dans une feuille de calcul Excel. Dans le même temps, voyons comment vous pouvez changer la police, l'alignement et d'autres bagatelles dans le texte en utilisant python.
Pour un exemple qui nourrit notre futur programme, nous reprenons de K + les modifications de la loi "Sur JSC". Cette loi est souvent modifiée, il y aura donc du travail à faire.
Enregistrez les modifications dans un fichier txt normal (par exemple, l'édition de .txt). Vous obtenez quelque chose comme ceci:

Ainsi, il est clair que chaque modification est séparée de l'autre par une ligne continue, qui après enregistrement a pris la forme de nombreux «???». Il y a aussi une rubrique de changement à prendre en compte. Tout a l'air simple sauf pour certains points.
Alors, rencontrez des changements qui ont la forme suivante:

De plus, la question est aggravée par le fait que les changements individuels diffèrent considérablement en longueur.
Nous passons à K +.
Créez un nouveau fichier consult.py et ajoutez-y les premières lignes:
from __future__ import unicode_literals import codecs import openpyxl
Le module openpyxl est déjà familier, il vous permet de travailler avec Excel, mais les deux autres sont nouveaux. Leur fonction est de traiter correctement les caractères russes, qui sont souvent mal lus par les programmes.
À l'avance, créez un nouveau fichier Excel vide en dehors du programme, en le nommant par exemple revision2.xlsx. Nous allons ouvrir ce fichier avec notre programme et y écrire les données. Ce sera notre dossier final.
Ainsi, le programme ouvre le fichier Excel, le saisit:
wb = openpyxl.load_workbook('2.xlsx') sheet=wb.get_active_sheet() x=1 y=0 test=[] test2=[] test3=[]
Aussi ci-dessus, nous créons 3 listes vides où nous collecterons des données: test, test2, test3.
Ensuite, dans la variable «a», nous mettrons tout ce qui peut se présenter sous la forme du nom du changement. En y - il y aura une ligne de division. C'est la même longueur:
a=('','','','','','','') y='?????????????????????????????????????????????????????????????????????????'
Maintenant, la partie amusante.
with open ('.txt',encoding='cp1251') as f: lines = (line.strip() for line in f) for line in lines: if line.startswith(''): continue col1=line[:35] col2=line[39:] col3=line[35:39] if line.startswith(a): sheet.cell(row=x, column=1).value=line
Nous avons ouvert le fichier .txt encodé cp1251. Chaque ligne a été débarrassée des espaces de la fin et du début par la méthode de la bande.
Si la ligne commence par le mot «ancien», nous la sautons. Pourquoi devons-nous conserver «l'ancien» et le «nouveau», cela est déjà clair. Ensuite, nous divisons la ligne: du début à 35 caractères et de 39 caractères à la fin. Autrement dit, nous éliminons l'écart au milieu:

Nous mettons le contenu de l'espace au milieu de la ligne en col3, car il peut ne pas s'agir d'un espace si la modification est écrite sur une ligne d'affilée:

De plus, si la ligne commence par l'en-tête de modification (nous avons écrit ces en-têtes dans la variable a), nous écrivons immédiatement cette ligne pour exceller sans fractionnement et ajoutons la ligne - x + = 1 (ou x = x + 1). Lignes vides, que nous rencontrons, nous manquons.
Considérez l'extrait de code suivant:
if len(col2)==0:
Si la longueur de 2 parties de la chaîne est 0, c'est-à-dire qu'elle n'existe pas, alors test2 obtient la première partie de la chaîne. S'il y a un espace dans la ligne, mais que la deuxième partie de la ligne est absente, alors la première et la deuxième partie de la ligne, respectivement, tombent dans test et test2.
S'il y a un espace dans la ligne et que la ligne n'est pas vide et que sa longueur est supérieure à 60 caractères, elle est ajoutée à test3.
Si la ligne est vide, c'est-à-dire que nous avons effectué tout le changement, nous écrivons tout ce que nous avons collecté dans les cellules Excel, vérifiant simultanément le vide dans le test (afin qu'il ne soit pas vide) et la durée du test3.
Enfin, enregistrez le fichier Excel:
wb.save('2.xlsx')
Styles, police et alignement du texte en python
Ajoutez de la beauté à notre table.
En particulier, nous allons faire en sorte que lors de la sortie des données, les en-têtes de changement soient mis en évidence en gras, et le texte lui-même soit plus petit et formaté pour une lecture facile.
Python vous permet de le faire. Pour ce faire, nous devons ajouter et modifier le code aux endroits où nous enregistrons les résultats dans un fichier Excel:
from openpyxl.styles import Font, Color,NamedStyle, Alignment
al= Alignment(horizontal="justify", vertical="top") ft = Font(name='Calibri', size=9) ft2 = Font(name='Calibri', size=9,bold=True)
if line.startswith(a): sheet.cell(row=x, column=1).value=line
if line==y:
if len(test3)>0:
En fait, nous n'avons ajouté que les méthodes applicables .font et .alignment.
L'ensemble du programme a pris la forme:
Code from __future__ import unicode_literals import codecs import openpyxl from openpyxl.styles import Font, Color,NamedStyle, Alignment """ 1. Consultant+ , .txt ????????????????????????????????????????????????????????????????????????? 15 1 48 15) 15) excel . word - txt : .txt : 2.xlsx """
Donc, à la fin, après avoir traité le fichier par le programme, nous avons un tableau assez décent avec des changements dans la loi:
Le programme peut être téléchargé à partir du lien -
ici .
Un exemple de fichier pour le traitement par le programme est
ici .