Présentation
Il se trouve que sur mon lieu de travail actuel, j'ai dû me familiariser avec cette technologie. Je vais commencer par un petit historique. Lors du prochain rallye, notre équipe a été informée que nous devons créer une intégration avec un système bien connu . L'intégration signifiait que ce système bien connu nous enverrait des requêtes via HTTP à un point de terminaison spécifique, et nous, curieusement, renvoyons les réponses sous la forme d'un message SOAP. Tout semble simple et trivial. Il suit ce qui est nécessaire ...
Défi
Créez 3 services. Le premier est le service de mise à jour de base de données. Ce service, lorsque de nouvelles données arrivent d'un système tiers, met à jour les données dans la base de données et génère un certain fichier CSV pour les transférer vers le système suivant. Le point de terminaison du deuxième service est appelé - le service de transport FTP, qui reçoit le fichier transféré, le valide et le place dans le stockage de fichiers via FTP. Le troisième service, le service de transfert de données au consommateur, fonctionne de manière asynchrone avec les deux premiers. Il reçoit une demande d'un système externe tiers, pour recevoir le fichier discuté ci-dessus, prend le fichier de réponse terminé, le modifie (met à jour l'id, la description, les champs linkToFile) et envoie la réponse sous la forme d'un message SOAP. Autrement dit, le tableau d'ensemble est le suivant: les deux premiers services ne commencent leur travail que lorsque les données à mettre à jour sont arrivées. Le troisième service fonctionne en permanence car il y a beaucoup de consommateurs d'informations, environ 1000 demandes de réception de données par minute. Les services sont disponibles en permanence et leurs instances sont situées dans des environnements différents, tels que test, démo, préprod et prod. Voici un schéma du travail de ces services. Je vais immédiatement expliquer que certains détails sont simplifiés pour éviter une complexité inutile.

Approfondissement technique
Lors de la planification d'une solution au problème, nous avons d'abord décidé de créer des applications java en utilisant le framework Spring, l'équilibreur Nginx, la base de données Postgres et d'autres choses techniques et pas très importantes. Comme le temps de développer une solution technique nous a permis d'envisager d'autres approches pour résoudre ce problème, mes yeux sont tombés sur la technologie Apache NIFI, à la mode dans certains milieux. Je dois dire tout de suite que cette technologie nous a permis de remarquer ces 3 services. Cet article décrira le développement d'un service de transport de fichiers et d'un service de transfert de données à un consommateur, cependant, si l'article arrive, j'écrirai sur un service de mise à jour des données dans la base de données.
Qu'est ce que c'est
NIFI est une architecture distribuée pour le chargement et le traitement parallèles rapides de données, un grand nombre de plug-ins pour les sources et les transformations, les configurations de version et bien plus encore. Un bon bonus est qu'il est très facile à utiliser. Les processus triviaux, tels que getFile, sendHttpRequest et autres, peuvent être représentés sous forme de carrés. Chaque carré représente un certain processus, dont l'interaction peut être vue dans la figure ci-dessous. Une documentation plus détaillée sur l'interaction de l'optimisation des processus est écrite ici. , pour ceux qui sont en russe - ici . La documentation décrit parfaitement comment décompresser et exécuter NIFI, ainsi que comment créer des processus, ce sont des carrés
L'idée d'écrire un article est née après une longue recherche et structuration des informations reçues dans quelque chose de conscient, ainsi que le désir de faciliter la vie des futurs développeurs.
Exemple
Un exemple de la façon dont les carrés interagissent les uns avec les autres est considéré. Le schéma général est assez simple: nous obtenons une requête HTTP (en théorie, avec un fichier dans le corps de la requête. Pour démontrer les capacités de NIFI, dans cet exemple, la requête démarre le processus de réception du fichier du PF local), puis nous renvoyons la réponse que la requête a été reçue, le processus de réception du fichier de FH puis le processus de déplacement via FTP vers FH. Il vaut la peine d'expliquer que les processus interagissent les uns avec les autres via le soi-disant flowFile. Il s'agit de l'entité de base dans NIFI qui stocke les attributs et le contenu. Le contenu est les données représentées par le fichier de flux. En gros, si vous avez reçu un fichier d'un carré et que vous le transférez dans un autre, le contenu sera votre fichier.
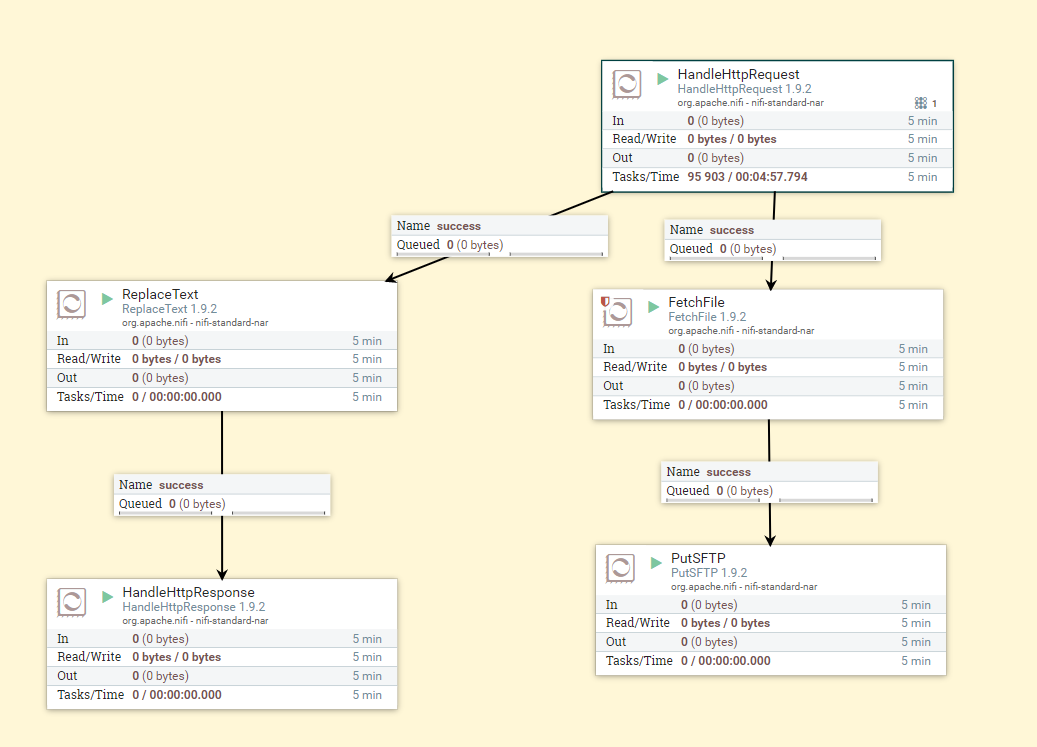
Comme vous pouvez le voir, cette figure illustre le processus global. HandleHttpRequest - accepte les demandes, ReplaceText - génère un corps de réponse, HandleHttpResponse - renvoie une réponse. FetchFile - reçoit un fichier du stockage de fichiers et le transfère vers le carré PutSftp - place ce fichier sur FTP à l'adresse spécifiée. Maintenant, plus sur ce processus.
Dans ce cas, la demande est le début de tout. Voyons ses options de configuration.
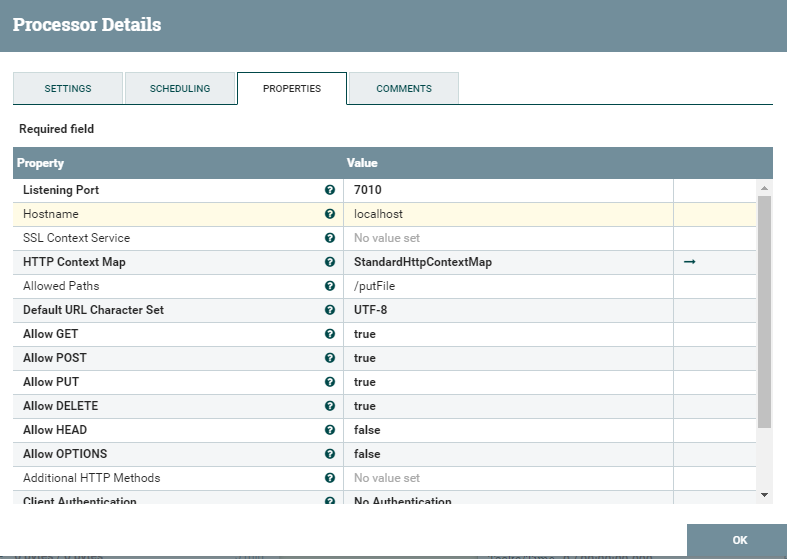
Tout ici est assez trivial à l'exception de StandartHttpContextMap - c'est un service qui vous permet d'envoyer et de recevoir des demandes. Vous pouvez voir plus de détails et même des exemples
ici Ensuite, consultez les options de configuration du carré ReplaceText. Il vaut la peine de prêter attention à ReplacementValue - c'est ce qui reviendra à l'utilisateur sous la forme d'une réponse. Dans les paramètres, vous pouvez régler le niveau de journalisation, les journaux peuvent être consultés {là où nifi a été déballé} /nifi-1.9.2/logs, il existe également des paramètres d'échec / de réussite - en fonction de ces paramètres, vous pouvez contrôler l'ensemble du processus. Autrement dit, dans le cas d'un traitement de texte réussi, le processus d'envoi d'une réponse à l'utilisateur est invoqué, et dans l'autre cas, nous nous engageons simplement à l'échec du processus.
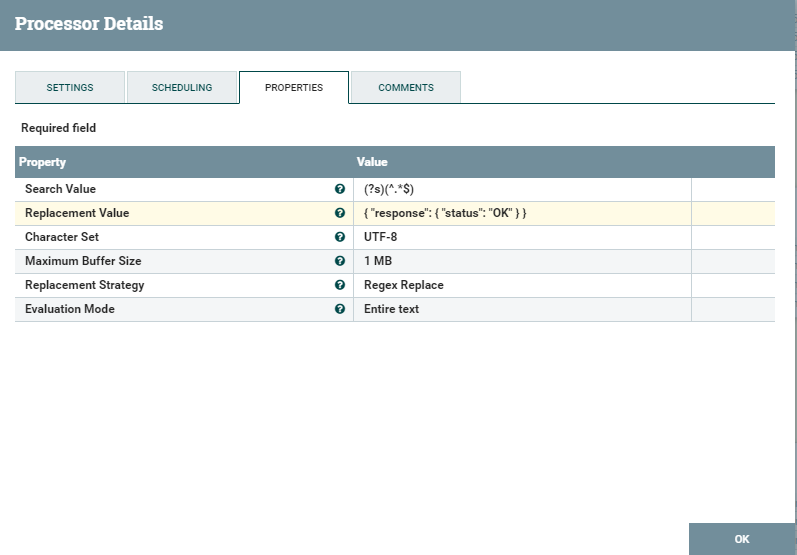
Les propriétés HandleHttpResponse n'ont rien de spécial à part le statut pour la création de réponse réussie.
Nous avons trié la demande avec la réponse - passons à la réception du fichier et au placement sur le serveur FTP. FetchFile - reçoit le fichier au chemin spécifié dans les paramètres et le transfère au processus suivant.
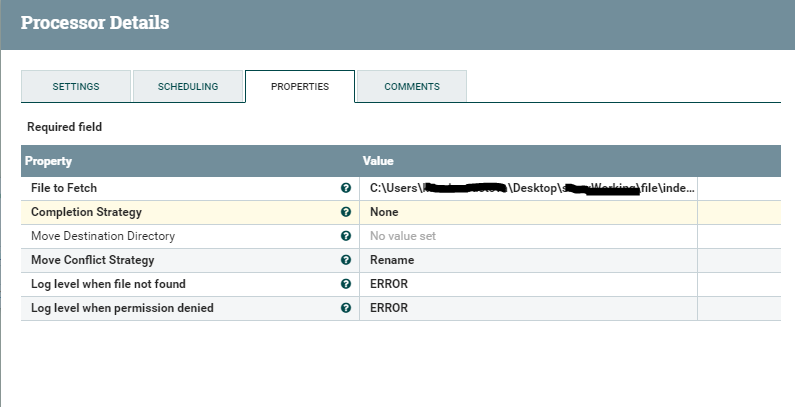
Et puis le carré PutSftp - met le fichier dans le stockage de fichiers. Les paramètres de configuration peuvent être vus ci-dessous.
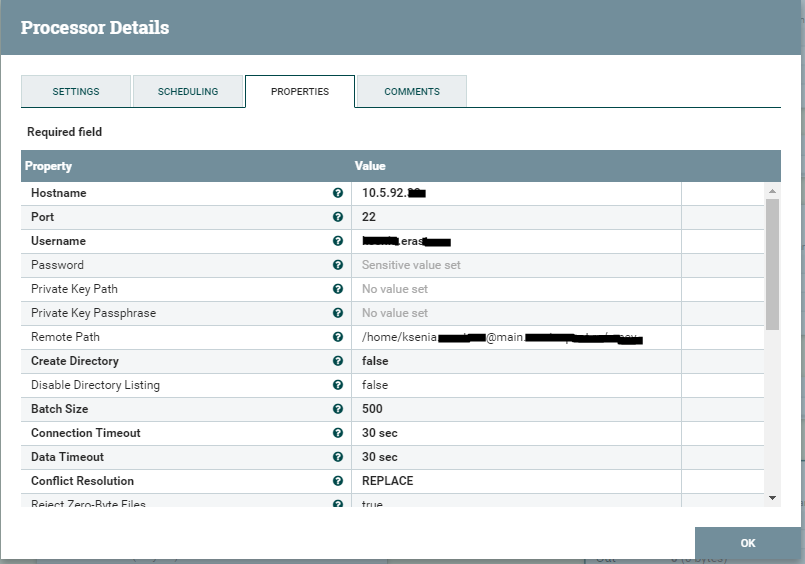
Il convient de prêter attention au fait que chaque carré est un processus distinct qui doit être démarré. Nous avons examiné l'exemple le plus simple qui ne nécessite aucune personnalisation compliquée. Ensuite, considérez le processus un peu plus compliqué, où nous écrivons un peu sur les rainures.
Exemple plus complexe
Le service de transfert de données au consommateur s'est avéré être un peu plus compliqué en raison du processus de modification du message SOAP. Le processus global est présenté dans la figure ci-dessous.

Ici, l'idée n'est pas non plus très compliquée: nous avons reçu une demande du consommateur selon laquelle il avait besoin de données, envoyé une réponse indiquant qu'il avait reçu un message, commencé le processus de réception du fichier de réponse, puis édité avec une certaine logique, puis transféré le fichier au consommateur sous la forme d'un message SOAP au serveur.
Je pense que cela ne vaut pas la peine de décrire à nouveau ces carrés que nous avons vu ci-dessus - nous irons directement aux nouveaux. Si vous avez besoin d'éditer un fichier et que les carrés ordinaires comme ReplaceText ne conviennent pas, vous devrez écrire votre propre script. Cela peut être fait en utilisant le carré ExecuteGroogyScript. Ses paramètres sont présentés ci-dessous.
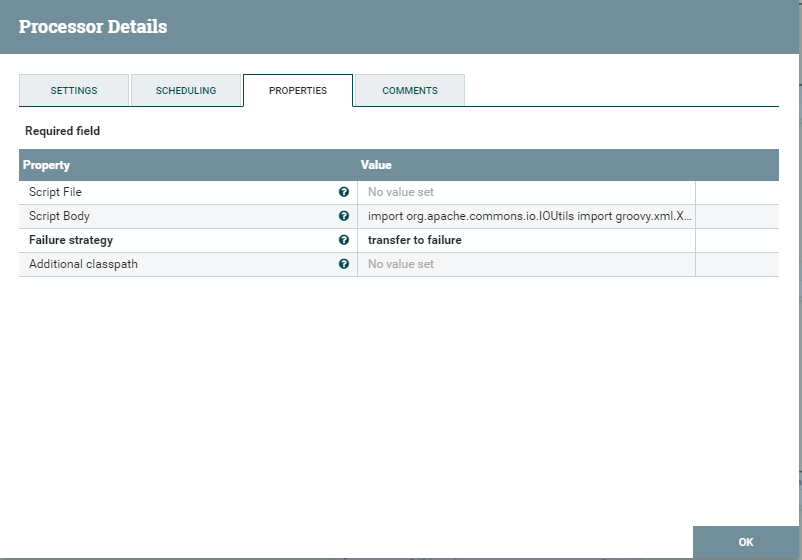
Il y a deux options pour charger le script dans ce carré. La première consiste à charger le fichier de script. La seconde consiste à insérer un script dans scriptBody. Pour autant que je sache, le carré executeScript prend en charge plusieurs JP - l'un d'eux est groovy. Je suis décevant pour les développeurs java - vous ne pouvez pas écrire de scripts dans de tels carrés en java. Pour ceux qui veulent vraiment - vous devez créer votre propre carré personnalisé et le jeter dans le système NIFI. Toute cette opération s'accompagne de danses assez longues au tambourin, dont nous ne traiterons pas dans le cadre de cet article. J'ai choisi un langage groovy. Vous trouverez ci-dessous un script de test qui met simplement à jour de manière incrémentielle l'ID dans le message SOAP. Il est important de le noter. Vous prenez le fichier de flowFile, le mettez à jour, n'oubliez pas que vous en avez besoin, mis à jour, remettez-le là. Il convient également de noter que toutes les bibliothèques ne sont pas connectées. Il peut arriver que vous deviez toujours importer l'une des bibliothèques. L'inconvénient est que le script de ce carré est assez difficile à faire ses débuts. Il existe un moyen de se connecter à la JVM NIFI et de démarrer le processus de débogage. Personnellement, j'ai exécuté une application locale et simulé l'obtention d'un fichier à partir d'une session. Le débogage a également été effectué localement. Les erreurs qui se produisent lors du chargement d'un script sont assez faciles à google et sont écrites par NIFI dans le journal.
import org.apache.commons.io.IOUtils import groovy.xml.XmlUtil import java.nio.charset.* import groovy.xml.StreamingMarkupBuilder def flowFile = session.get() if (!flowFile) return try { flowFile = session.write(flowFile, { inputStream, outputStream -> String result = IOUtils.toString(inputStream, "UTF-8"); def recordIn = new XmlSlurper().parseText(result) def element = recordIn.depthFirst().find { it.name() == 'id' } def newId = Integer.parseInt(element.toString()) + 1 def recordOut = new XmlSlurper().parseText(result) recordOut.Body.ClientMessage.RequestMessage.RequestContent.content.MessagePrimaryContent.ResponseBody.id = newId def res = new StreamingMarkupBuilder().bind { mkp.yield recordOut }.toString() outputStream.write(res.getBytes(StandardCharsets.UTF_8)) } as StreamCallback) session.transfer(flowFile, REL_SUCCESS) } catch(Exception e) { log.error("Error during processing of validate.groovy", e) session.transfer(flowFile, REL_FAILURE) }
En fait, la personnalisation des extrémités carrées. Ensuite, le fichier mis à jour est transféré vers le carré, qui est engagé dans l'envoi du fichier au serveur. Voici les paramètres de ce carré.
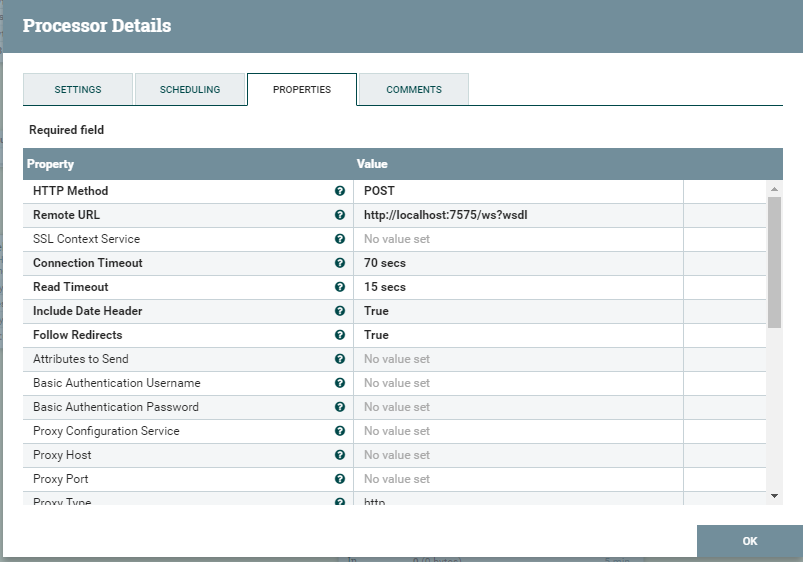
Nous décrivons la méthode par laquelle le message SOAP sera transmis. Nous écrivons où. Ensuite, vous devez indiquer que c'est exactement SOAP.
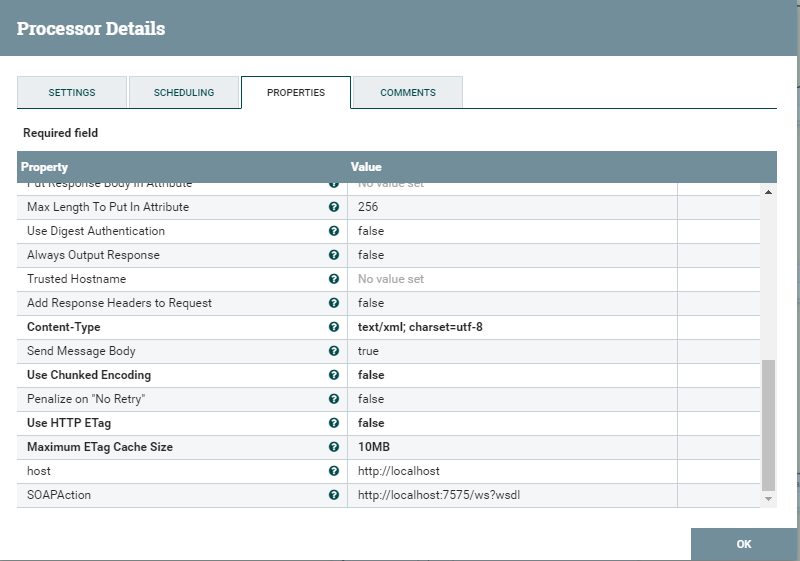
Ajoutez des propriétés telles que l'hôte et l'action (soapAction). Enregistrez, vérifiez. Plus de détails sur la façon d'envoyer des demandes SOAP peuvent être trouvés ici.
Nous avons examiné plusieurs utilisations des processus NIFI. Comment ils interagissent et quels avantages réels ils ont. Les exemples considérés sont des tests et sont légèrement différents de ce qui est réel au combat. J'espère que cet article sera un peu utile pour les développeurs. Merci de votre attention. Si vous avez des questions - écrivez. Je vais essayer de répondre.