Bonjour à tous. Dans cet article, je vais vous expliquer pourquoi nous avons choisi Kafka il y a neuf mois à Avito, et ce que c'est. Je vais partager l'un des cas d'utilisation - un courtier de messages. Et enfin, parlons des avantages que nous avons retirés de l'application de l'approche Kafka as a Service.
Le problème

Tout d'abord, un peu de contexte. Il y a quelque temps, nous avons commencé à nous éloigner de l'architecture monolithique, et maintenant, à Avito, il existe déjà plusieurs centaines de services différents. Ils ont leurs propres référentiels, leur propre pile technologique et sont responsables de leur part de la logique métier.
Un des problèmes avec un grand nombre de services est la communication. Le service A souhaite souvent connaître les informations du service B. Dans ce cas, le service A accède au service B via une API synchrone. Le service B veut savoir ce qui se passe avec les services G et D, et ceux-ci, à leur tour, sont intéressés par les services A et B. Lorsqu'il existe de nombreux services «curieux», les connexions entre eux se transforment en une boule emmêlée.
De plus, à tout moment, le service A peut devenir indisponible. Et que faire dans ce cas, le service B et tous les autres services qui lui sont liés? Et si vous devez effectuer une chaîne d'appels synchrones consécutifs pour terminer une opération commerciale, la probabilité d'échec de l'ensemble de l'opération devient encore plus élevée (et elle est d'autant plus élevée que cette chaîne est longue).
Sélection de technologies

OK, les problèmes sont clairs. Vous pouvez les éliminer en créant un système de messagerie centralisé entre les services. Désormais, chacun des services suffit pour connaître uniquement ce système de messagerie. De plus, le système lui-même doit être tolérant aux pannes et évolutif horizontalement, ainsi qu'en cas d'accident, accumuler un tampon d'appel pour leur traitement ultérieur.
Choisissons maintenant la technologie sur laquelle la remise des messages sera mise en œuvre. Pour ce faire, comprenez d'abord ce que nous attendons d'elle:
- Les messages entre services ne doivent pas être perdus;
- Les messages peuvent être dupliqués
- les messages peuvent être stockés et lus sur une profondeur de plusieurs jours (tampon persistant);
- les services peuvent souscrire aux données qui les intéressent;
- plusieurs services peuvent lire les mêmes données;
- Les messages peuvent contenir une charge utile détaillée et en masse (transfert d'état transporté par événement);
- Parfois, vous avez besoin d'une garantie de commande de message.
Il était également essentiel pour nous de choisir le système le plus évolutif et le plus fiable à haut débit (au moins 100 000 messages à quelques kilo-octets par seconde).
À ce stade, nous avons dit au revoir à RabbitMQ (difficile à maintenir stable à des vitesses élevées), PGT de SkyTools (pas assez rapide et mal évolutif) et NSQ (non persistant). Toutes ces technologies sont utilisées dans notre entreprise, mais elles ne convenaient pas à la tâche à accomplir.
Ensuite, nous avons commencé à chercher de nouvelles technologies pour nous - Apache Kafka, Apache Pulsar et NATS Streaming.
Le premier à laisser tomber Pulsar. Nous avons décidé que Kafka et Pulsar sont des solutions assez similaires. Et malgré le fait que Pulsar soit testé par de grandes entreprises, il est plus récent et offre une latence plus faible (en théorie), nous avons décidé de laisser Kafka parmi les deux, comme standard de facto pour de telles tâches. Nous reviendrons probablement à Apache Pulsar à l'avenir.
Et il restait deux candidats: NATS Streaming et Apache Kafka. Nous avons étudié les deux solutions en détail, et les deux se sont montrées à la hauteur. Mais à la fin, nous avions peur de la jeunesse relative de NATS Streaming (et du fait que l'un des principaux développeurs, Tyler Treat, ait décidé de quitter le projet et de démarrer le sien - Liftbridge). Dans le même temps, le mode de clustering de NATS Streaming ne permettait pas une forte mise à l'échelle horizontale (ce n'est probablement plus un problème après l'ajout du mode de partitionnement en 2017).
Cependant, NATS Streaming est une technologie intéressante écrite en Go et prise en charge par la Cloud Native Computing Foundation. Contrairement à Apache Kafka, il n'a pas besoin de Zookeeper pour fonctionner (il sera peut-être possible de dire la même chose à propos de Kafka bientôt ), car à l'intérieur il implémente RAFT. Dans le même temps, NATS Streaming est plus facile à administrer. Nous n'excluons pas qu'à l'avenir, nous reviendrons sur cette technologie.
Néanmoins, Apache Kafka est devenu notre gagnant aujourd'hui. Lors de nos tests, il s'est avéré assez rapide (plus d'un million de messages par seconde pour la lecture et l'écriture avec un volume de messages de 1 kilo-octet), suffisamment fiable, bien évolutif et une expérience éprouvée dans la vente par les grandes entreprises. De plus, Kafka soutient au moins plusieurs grandes sociétés commerciales (par exemple, nous utilisons la version Confluent), et Kafka a un écosystème développé.
Donnez votre avis sur Kafka
Avant de commencer, je recommande immédiatement un excellent livre - "Kafka: Le guide définitif" (il est également dans la traduction russe, mais les termes brisent un peu le cerveau). Vous y trouverez les informations nécessaires à une compréhension de base de Kafka et même un peu plus. La documentation Apache elle-même et le blog Confluent sont également bien écrits et faciles à lire.
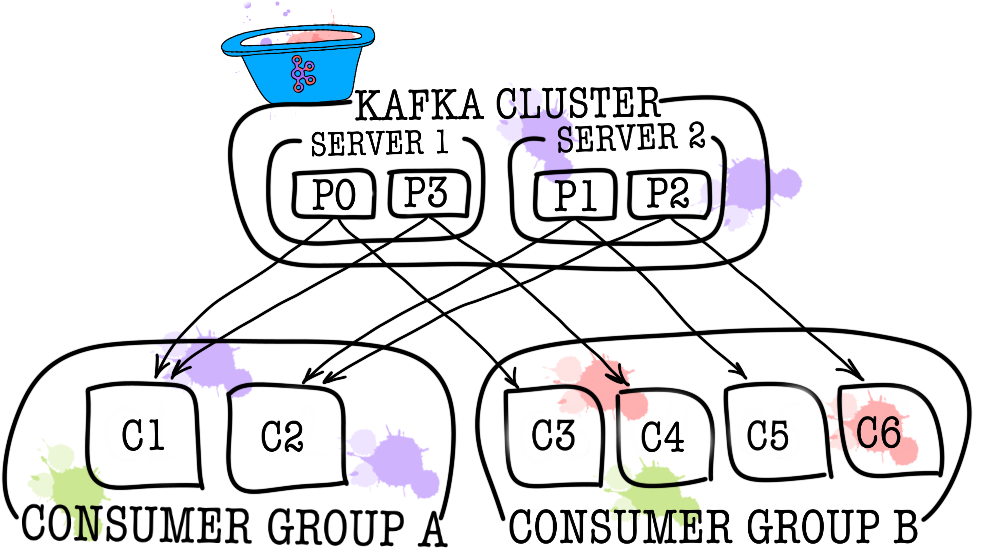
Alors, regardons comment Kafka est une vue à vol d'oiseau. La topologie de base de Kafka se compose de producteur, consommateur, courtier et gardien de zoo.
Courtier

Un courtier est responsable du stockage de vos données. Toutes les données sont stockées sous forme binaire, et le courtier sait peu de choses sur ce qu'elles sont et quelle est leur structure.
Chaque type d'événement logique est généralement situé dans son propre sujet distinct (sujet). Par exemple, un événement de création d'annonce peut tomber dans le sujet item.created et un événement de sa modification peut tomber dans item.changed. Les sujets peuvent être considérés comme des classificateurs d'événements. Au niveau de la rubrique, vous pouvez définir des paramètres de configuration tels que:
- le volume de données stockées et / ou leur âge (retention.bytes, retention.ms);
- facteur de redondance des données (facteur de réplication);
- taille maximale d'un message (max.message.bytes);
- le nombre minimum de répliques cohérentes auxquelles les données peuvent être écrites sur le sujet (min.insync.replicas);
- la possibilité de basculement vers une réplique en retard non synchrone avec perte potentielle de données (unclean.leader.election.enable);
- et bien d'autres ( https://kafka.apache.org/documentation/#topicconfigs ).
À son tour, chaque sujet est divisé en une ou plusieurs partitions (partition). C'est dans la partition que les événements finissent par tomber. S'il y a plus d'un courtier dans le cluster, les partitions seront réparties également entre tous les courtiers (autant que possible), ce qui vous permettra de faire évoluer la charge d'écriture et de lecture dans un sujet sur plusieurs courtiers à la fois.
Sur disque, les données de chaque partition sont stockées sous forme de fichiers de segments, par défaut égaux à un gigaoctet (contrôlés via log.segment.bytes). Une caractéristique importante est que les données sont supprimées des partitions (lorsque la rétention est déclenchée) uniquement par segments (vous ne pouvez pas supprimer un événement d'une partition, vous pouvez supprimer uniquement le segment entier et uniquement inactif).
Zookeeper
Zookeeper agit en tant que référentiel de métadonnées et coordinateur. C'est lui qui peut dire si les courtiers sont vivants (vous pouvez le regarder à travers les yeux d'un gardien grâce à la commande zookeeper-shell ls /brokers/ids ), lequel des courtiers est le contrôleur ( get /controller ), si les partitions sont en état synchrone avec leurs répliques ( get /brokers/topics/topic_name/partitions/partition_number/state ). De plus, le producteur et le consommateur se rendront d'abord auprès du gardien de zoo pour savoir sur quel courtier quels sujets et quelles partitions sont stockés. Dans les cas où un facteur de réplication supérieur à 1 est spécifié pour le sujet, le gardien de zoo indiquera quelles partitions sont des leaders (ils seront écrits et lus à partir de). En cas de panne d'un courtier, c'est dans le gardien de zoo que les informations sur les nouvelles partitions de leader seront enregistrées (à partir de la version 1.1.0 de manière asynchrone, ce qui est important ).
Dans les anciennes versions de Kafka, zookeeper était également responsable du stockage des décalages, mais maintenant ils sont stockés dans une rubrique spéciale __consumer_offsets sur le courtier (bien que vous puissiez toujours utiliser zookeeper à ces fins).
La façon la plus simple de transformer vos données en citrouille est simplement la perte d'informations avec zookeeper. Dans un tel scénario, il sera très difficile de comprendre quoi et où lire.
Producteur
Le producteur est le plus souvent un service qui écrit directement des données dans Apache Kafka. Le producteur sélectionne un sujet dans lequel ses messages thématiques seront stockés et commence à y écrire des informations. Par exemple, un producteur peut être un service publicitaire. Dans ce cas, il enverra des événements tels que «annonce créée», «annonce mise à jour», «annonce supprimée», etc. à des sujets thématiques. Chaque événement est une paire clé-valeur.
Par défaut, tous les événements sont distribués par les partitions de partition avec round-robin si la clé n'est pas définie (ordre perdu), et via MurmurHash (clé) si la clé est présente (commande dans la même partition).
Il convient immédiatement de noter ici que Kafka garantit l'ordre des événements dans une seule partition. Mais en fait, ce n'est souvent pas un problème. Par exemple, vous pouvez à coup sûr ajouter toutes les modifications d'une même annonce à une partition (préservant ainsi l'ordre de ces modifications dans l'annonce). Vous pouvez également transmettre un numéro de séquence dans l'un des champs d'événement.
Consommateur
Le consommateur est responsable de la récupération des données d'Apache Kafka. Si vous revenez à l'exemple ci-dessus, le consommateur peut être un service de modération. Ce service sera abonné au sujet du service d'annonce et lorsqu'une nouvelle publicité apparaîtra, il la recevra et analysera sa conformité avec certaines politiques spécifiées.
Apache Kafka se souvient des événements récents que le consommateur a reçus (la __consumer__offsets service __consumer__offsets est utilisée pour cela), garantissant ainsi qu'en cas de lecture réussie, le consommateur ne recevra pas le même message deux fois. Néanmoins, si vous utilisez l'option enable.auto.commit = true et donnez entièrement le travail de suivi de la position du consommateur dans le sujet à Kafka, vous pouvez perdre des données . Dans le code de production, la position du consommateur est le plus souvent contrôlée manuellement (le développeur contrôle le moment où la validation de l'événement de lecture doit se produire).
Dans les cas où un consommateur ne suffit pas (par exemple, le flux de nouveaux événements est très important), vous pouvez ajouter quelques consommateurs supplémentaires en les reliant dans le groupe de consommateurs. Le groupe de consommateurs est logiquement exactement le même consommateur, mais avec la distribution des données entre les membres du groupe. Cela permet à chacun des participants de prendre leur part de messages, augmentant ainsi la vitesse de lecture.
Résultats des tests

Ici, je n'écrirai pas beaucoup de texte explicatif, je partage juste les résultats. Les tests ont été effectués sur 3 machines physiques (12 CPU, 384GB RAM, 15k SAS DISK, 10GBit / s Net), des brokers et zookeeper ont été déployés dans lxc.
Test de performance
Au cours des tests, les résultats suivants ont été obtenus.
- La vitesse d'enregistrement de messages de 1 Ko en même temps par 9 producteurs - 1 300 000 événements par seconde.
- Vitesse de lecture de messages de 1 Ko en même temps par 9 consommateurs - 1 500 000 événements par seconde.
Test de tolérance aux pannes
Lors des tests, les résultats suivants ont été obtenus (3 courtiers, 3 gardiens).
- Une résiliation anormale de l'un des courtiers n'entraîne pas la suspension ou l'inaccessibilité du cluster. Le travail se poursuit comme d'habitude, mais les autres courtiers ont une grosse charge.
- La terminaison anormale de deux courtiers dans le cas d'un cluster de trois courtiers et min.isr = 2 conduit à l'inaccessibilité du cluster pour l'écriture, mais pour la lisibilité. Si min.isr = 1, le cluster reste disponible pour la lecture et l'écriture. Cependant, ce mode contredit l'exigence d'une haute sécurité des données.
- L'arrêt anormal de l'un des serveurs Zookeeper n'entraîne pas l'arrêt ou l'inaccessibilité du cluster. Le travail se poursuit normalement.
- Une interruption anormale de deux serveurs Zookeeper conduit à une inaccessibilité du cluster jusqu'à ce qu'au moins l'un des serveurs Zookeeper soit restauré. Cette affirmation est vraie pour un cluster Zookeeper de 3 serveurs. En conséquence, après des recherches, il a été décidé d'augmenter le cluster Zookeeper à 5 serveurs pour augmenter la tolérance aux pannes.
Kafka en tant que service

Nous nous sommes assurés que Kafka est une excellente technologie qui nous permet de résoudre l'ensemble de tâches pour nous (implémenter un courtier de messages). Néanmoins, nous avons décidé d'interdire aux services d'accéder directement à Kafka et de le fermer par-dessus avec le service de bus de données. Pourquoi avons-nous fait ça? Il y a en fait plusieurs raisons.
Data-bus a pris en charge toutes les tâches liées à l'intégration avec Kafka (implémentation et configuration des consommateurs et des producteurs, surveillance, alerte, journalisation, mise à l'échelle, etc.). Ainsi, l'intégration avec le courtier de messages est aussi simple que possible.
Le bus de données a permis d'abstraire d'une langue ou d'une bibliothèque spécifique pour travailler avec Kafka.
Le bus de données a permis à d'autres services de s'abstraire de la couche de stockage. Peut-être qu'à un moment donné, nous changerons Kafka en Pulsar, et personne ne remarquera rien (tous les services ne connaissent que l'API du bus de données).
Le bus de données a pris en charge la validation des schémas d'événements.
L'utilisation de l'authentification par bus de données est implémentée.
Sous le couvert du bus de données, nous pouvons, sans temps d'arrêt, mettre à jour discrètement les versions de Kafka, conduire de manière centralisée les configurations des producteurs, consommateurs, courtiers, etc.
Le bus de données nous a permis d'ajouter des fonctionnalités dont nous avons besoin qui ne sont pas dans Kafka (comme l'audit de sujet, la surveillance des anomalies dans le cluster, la création de DLQ, etc.).
Le bus de données permet une mise en œuvre centralisée du basculement pour tous les services.
Pour le moment, pour commencer à envoyer des événements au courtier de messages, connectez simplement une petite bibliothèque à votre code de service. C’est tout. Vous avez la possibilité d'écrire, de lire et de mettre à l'échelle avec une seule ligne de code. L'implémentation entière vous est cachée, seuls quelques bâtons comme la taille du lot ressortent. Sous le capot, le service de bus de données augmente le nombre nécessaire d'instances de producteurs et de consommateurs dans Kubernetes et leur ajoute la configuration nécessaire, mais tout cela est transparent pour votre service.
Bien sûr, il n'y a pas de solution miracle, et cette approche a ses limites.
- Le bus de données doit être pris en charge seul, contrairement aux bibliothèques tierces.
- Le bus de données augmente le nombre d'interactions entre les services et le courtier de messages, ce qui entraîne une baisse des performances par rapport à Kafka nu.
- Tout ne peut pas être caché si simplement aux services, nous ne voulons pas dupliquer les fonctionnalités de KSQL ou de Kafka Streams dans le bus de données, vous devez donc parfois autoriser les services à aller directement.
Dans notre cas, les avantages l'emportaient sur les inconvénients, et la décision de couvrir le courtier de messages avec un service distinct était justifiée. Au cours de l'année de fonctionnement, nous n'avons eu aucun accident ni problème grave.
PS Merci à ma petite amie, Ekaterina Oblyalyaeva, pour les photos sympas de cet article. Si vous les avez aimés, il y a encore plus d'illustrations.