Bonjour à tous. Il reste quelques jours avant le début du cours de Machine Learning . En prévision du début des cours, nous avons préparé une traduction utile qui intéressera à la fois nos étudiants et tous les lecteurs de blog. Et aujourd'hui, nous partageons avec vous la dernière partie de cette traduction.

Tracés de dépendance partielle
Les graphiques de dépendance partielle (graphiques de dépendance partielle ou graphiques PDP, PD) montrent une influence insignifiante d'une ou deux caractéristiques sur le résultat prévu du modèle d'apprentissage automatique (
JH Friedman 2001 ). PDP peut montrer la relation entre la cible et les entités sélectionnées à l'aide de graphiques 1D ou 2D.
Comment ça marche?
Les PDP sont également calculés après la formation du modèle. Dans le problème du football dont nous avons discuté ci-dessus, il y avait de nombreux signes, tels que des passes décisives, des tentatives de marquer au but, des buts marqués, etc. Commençons par regarder une ligne. Disons que la ligne est une équipe qui avait le ballon 50% du temps, qui a fait 100 passes décisives, 10 tentatives de marquer et 1 but.
Nous agissons en entraînant notre modèle et en calculant la probabilité que l'équipe ait un joueur qui a reçu «l'homme du jeu», qui est notre variable cible. Ensuite, nous sélectionnons la variable et changeons continuellement sa valeur. Par exemple, nous calculerons le résultat, à condition que l'équipe ait marqué 1 but, 2 buts, 3 buts, etc. Toutes ces valeurs sont reflétées dans le graphique, à la fin nous obtenons un graphique de la dépendance des résultats prévus aux buts marqués.
La bibliothèque utilisée en Python pour construire PDP est appelée la boîte à outils du tracé de dépendance partielle python ou simplement PDPbox .
from matplotlib import pyplot as plt from pdpbox import pdp, get_dataset, info_plots
Interprétation
- L'axe des Y représente le changement de prévision dû à ce qui avait été prédit dans l'original ou dans la valeur la plus à gauche.
- La zone bleue indique l'intervalle de confiance.
- Pour le graphique des buts marqués, nous voyons qu'un but marqué augmente la probabilité de recevoir un prix «Homme du jeu», mais après un certain temps, la saturation se produit.
Nous pouvons également visualiser la dépendance partielle de deux entités en même temps à l'aide de graphiques 2D.
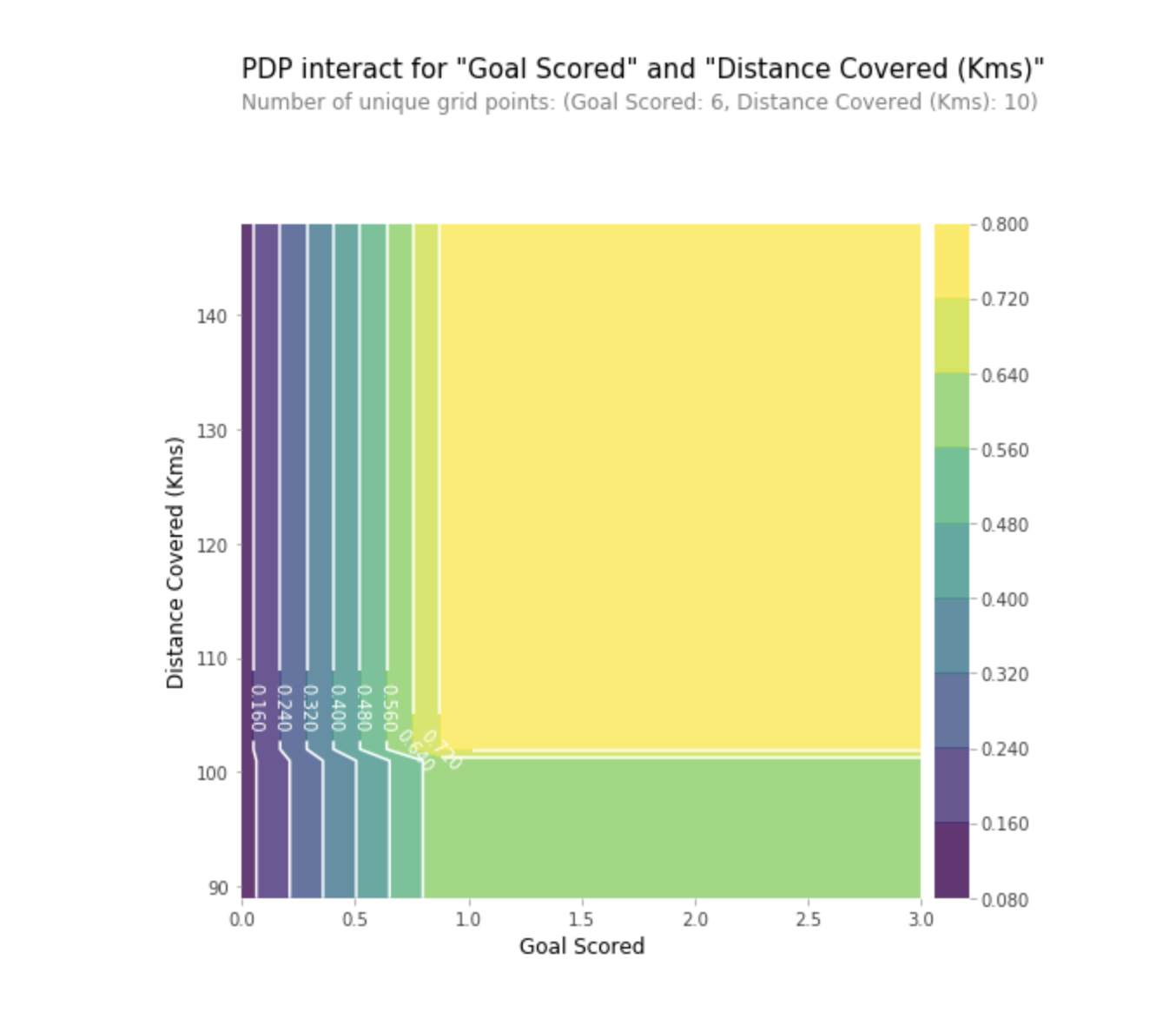 Pratique
PratiqueValeurs SHAP
SHAP signifie explication additive SHapley. Cette méthode permet de diviser la prévision en parties pour révéler l'importance de chaque caractéristique. Il est basé sur le Vector Shapley, un principe utilisé dans la théorie des jeux pour déterminer dans quelle mesure chaque joueur contribue à son succès dans un jeu conjoint (https://medium.com/civis-analytics/demystifying-black-box-models-with-shap- analyse de valeur-3e20b536fc80). Trouver un compromis entre précision et interprétabilité peut souvent être un équilibre difficile, mais les valeurs SHAP peuvent fournir les deux.
Comment ça marche?
Et encore une fois, revenons à l'exemple du football, où nous voulions prédire la probabilité qu'une équipe ait un joueur qui a remporté le prix «Homme du jeu». SHAP - les valeurs interprètent l'influence d'une certaine valeur d'une caractéristique par rapport à la prévision que nous aurions faite si cette caractéristique avait pris une valeur de base.
SHAP - les valeurs sont calculées à l'aide de la bibliothèque Shap , qui peut être facilement installée à partir de PyPI ou conda.
SHAP - les valeurs montrent à quel point ce trait particulier a changé notre prédiction (par rapport à la façon dont nous aurions fait cette prédiction avec une valeur de base de ce trait). Supposons que nous voulions savoir quelles seraient les prévisions si l'équipe marquait 3 buts, au lieu d'un montant de base fixe. Si nous pouvons répondre à cette question, nous pouvons suivre les mêmes étapes pour les autres signes comme suit:
sum(SHAP values for all features) = pred_for_team - pred_for_baseline_values
Par conséquent, la prévision peut être présentée sous la forme du graphique suivant:
 Voici le lien vers la vue d'ensemble.
Voici le lien vers la vue d'ensemble.Interprétation
L'exemple ci-dessus montre les signes, dont chacun contribue au mouvement de la sortie du modèle à la valeur de base (sortie statistique moyenne du modèle en utilisant l'ensemble de données d'apprentissage que nous lui avons transmis précédemment) vers la sortie finale du modèle. Les signes qui font progresser les prévisions ci-dessus sont affichés en rouge, et ceux qui diminuent leur précision sont indiqués ci-dessous.
- La valeur de base ici est de 0,4979, tandis que la prévision est de 0,7.
- Avec des
Goal Scores = 2, le trait a la plus grande influence sur l'amélioration des prévisions, tandis que - L'attribut de
ball possession a le plus fort effet d'abaisser la prévision finale.
Pratique
SHAP - les valeurs ont une justification théorique beaucoup plus profonde que ce que j'ai mentionné ici. Pour une meilleure compréhension du problème, suivez le
lien .
Utilisation avancée des valeurs SHAP
L'agrégation de plusieurs valeurs SHAP aidera à former une vue plus détaillée du modèle.
- Graphiques récapitulatifs SHAP
Pour avoir une idée des fonctionnalités les plus importantes pour le modèle, nous pouvons créer des valeurs SHAP pour chaque fonctionnalité et pour chaque échantillon. Le graphique récapitulatif montre quelles fonctionnalités sont les plus importantes, ainsi que leur plage d'influence sur l'ensemble de données.
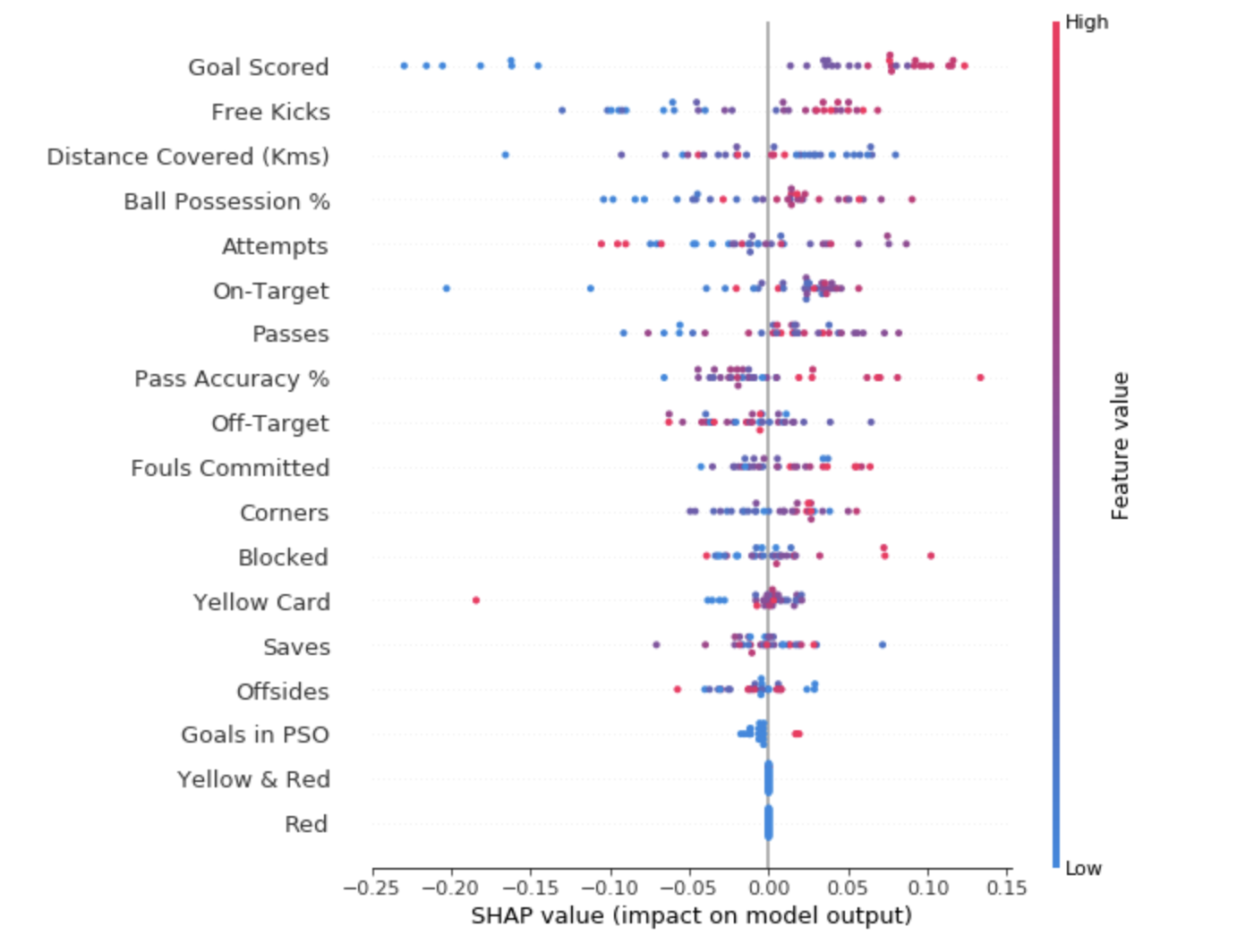
Pour chaque point:
- L'agencement vertical montre quel signe il reflète;
- La couleur indique si cet objet est hautement significatif ou faiblement significatif pour cette chaîne de jeu de données;
- L'agencement horizontal montre si l'influence de la valeur de cette caractéristique a conduit à une prévision plus précise ou non.
Le point dans le coin supérieur gauche signifie que l'équipe a marqué plusieurs buts, mais a réduit la probabilité d'une prévision réussie de 0,25.
- Tableau de contribution SHAP
Alors que le graphique récapitulatif SHAP fournit un aperçu général de chaque caractéristique, le graphique de dépendance SHAP montre comment la sortie du modèle dépend de la valeur de la caractéristique. Le graphique de dépendance de la contribution SHAP fournit un aperçu PDP similaire, mais ajoute plus de détails.
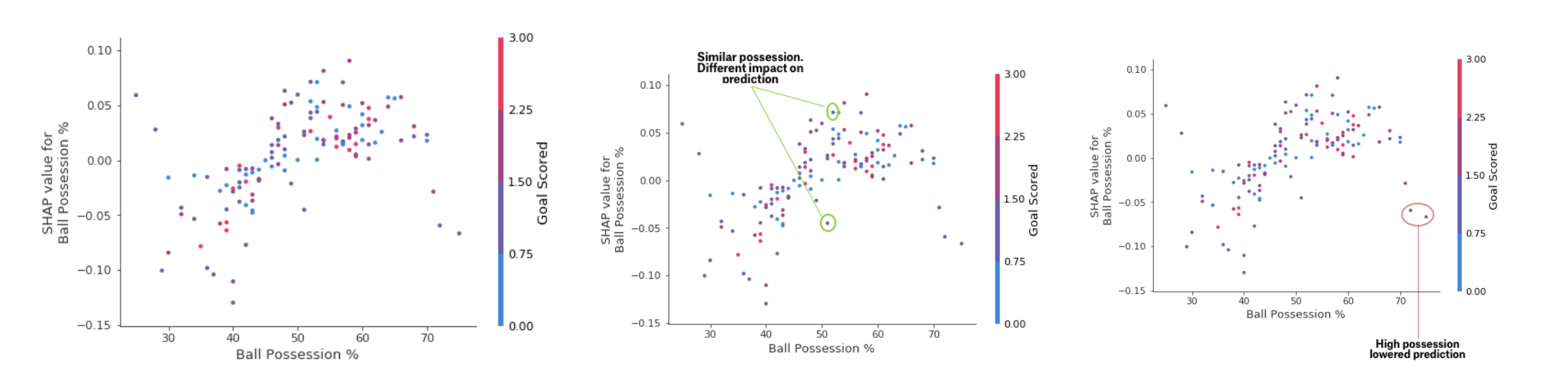 Tableau de dépendance des dépôts
Tableau de dépendance des dépôtsLes graphiques présentés ci-dessus indiquent que la présence d'une épée augmente les chances de l'équipe que c'est son joueur qui recevra une récompense. Mais si une équipe ne marque qu'un seul but, cette tendance change, car les arbitres peuvent décider que les joueurs de l'équipe gardent le ballon trop longtemps et marquent trop peu de buts.
PratiqueConclusion
L'apprentissage automatique ne devrait plus être une boîte noire. À quoi sert un bon modèle si nous ne pouvons pas expliquer les résultats de son travail aux autres? L'interprétabilité est devenue aussi importante que la qualité du modèle. Pour être accepté, il est impératif que les systèmes d'apprentissage automatique puissent fournir des explications claires de leurs décisions. Comme le disait Albert Einstein: "Si vous ne pouvez pas expliquer quelque chose dans un langage simple, vous ne le comprenez pas."
Sources:- "Apprentissage automatique interprétable: un guide pour rendre les modèles de boîte noire explicables." Christoph molnar
- Micro-cours d'explication de l'apprentissage automatique à Kaggle
Lire la première partie