Il y a quelque temps, nous avons
annoncé une version publique et ouvert sous licence MIT le code source de
LuaVela - une implémentation de Lua 5.1, basée sur LuaJIT 2.0. Nous avons commencé à travailler dessus en 2015 et, début 2017, il a été utilisé dans plus de 95% des projets de l'entreprise. Maintenant, je veux revenir sur le chemin parcouru. Quelles circonstances nous ont poussés à développer notre propre implémentation d'un langage de programmation? Quels problèmes avons-nous rencontrés et comment les avons-nous résolus? En quoi LuaVela est-elle différente des autres fourches LuaJIT?
Contexte
Cette section est basée sur notre
rapport sur HighLoad ++. Nous avons commencé à utiliser activement Lua pour écrire la logique commerciale de nos produits en 2008. Au début, c'était de la vanille Lua, et depuis 2009 - LuaJIT. Le protocole RTB a établi un cadre serré pour le traitement de la demande, de sorte que la transition vers une mise en œuvre plus rapide de la langue était une solution logique et, à un certain point, nécessaire.
Au fil du temps, nous avons réalisé qu'il y avait certaines limites à l'architecture LuaJIT. La chose la plus importante pour nous était que LuaJIT 2.0 utilise strictement des pointeurs 32 bits. Cela nous a conduit à une situation où l'exécution sur Linux 64 bits limitait la taille de l'espace d'adressage virtuel de la mémoire de processus à un gigaoctet (dans les versions ultérieures du noyau Linux, cette limite était portée à deux gigaoctets):
void *ptr = mmap((void *)MMAP_REGION_START, size, MMAP_PROT, MAP_32BIT | MMAP_FLAGS, -1, 0);
Cette limitation est devenue un gros problème - en 2015, 1 à 2 gigaoctets de mémoire ont cessé d'être suffisants pour que de nombreux projets chargent les données avec lesquelles la logique a fonctionné. Il convient de noter que chaque instance de la machine virtuelle Lua est monothread et ne sait pas comment partager des données avec d'autres instances - cela signifie qu'en pratique, chaque machine virtuelle peut revendiquer une taille de mémoire ne dépassant pas 2 Go / n, où n est le nombre de flux de travail de notre serveur applications.
Nous sommes passés par plusieurs solutions au problème: nous avons réduit le nombre de threads dans notre serveur d'applications, essayé d'organiser l'accès aux données via LuaJIT FFI, testé la transition vers LuaJIT 2.1. Malheureusement, toutes ces options étaient soit économiquement désavantageuses, soit mal adaptées à long terme. Il ne nous restait plus qu'à tenter notre chance et bifurquer LuaJIT. À ce moment, nous avons pris des décisions qui ont largement déterminé le sort du projet.
Tout d'abord, nous avons immédiatement décidé de ne pas modifier la syntaxe et la sémantique du langage, en nous concentrant sur la suppression des limites architecturales de LuaJIT, ce qui s'est avéré être un problème pour l'entreprise. Bien sûr, au fur et à mesure du développement du projet, nous avons commencé à ajouter des extensions (nous en discuterons ci-dessous) - mais nous avons isolé toutes les nouvelles API de la bibliothèque de langues standard.
De plus, nous avons abandonné la multiplateforme pour ne prendre en charge que Linux x86-64, notre seule plate-forme de production. Malheureusement, nous n'avions pas suffisamment de ressources pour tester adéquatement la quantité gigantesque de changements que nous allions apporter à la plateforme.
Un coup d'œil sous le capot de la plateforme
Voyons d'où vient la restriction sur la taille des pointeurs. Pour commencer, le type de
nombre dans Lua 5.1 est (avec quelques mises en garde mineures) le type C double, qui à son tour correspond au type à double précision défini par la norme IEEE 754. Dans le codage de ce type 64 bits, la plage de valeurs est mise en évidence pour la présentation NaN. En particulier, comment toute valeur dans la plage [0xFFF8000000000000; 0xFFFFFFFFFFFFFFFF].
Ainsi, nous pouvons regrouper dans une seule valeur 64 bits soit un nombre «réel» à double précision, soit une entité qui, du point de vue du type double, sera interprétée comme NaN, et du point de vue de notre plateforme, ce sera quelque chose de plus significatif - par exemple, par le type d'objet (haut 32 bits) et un pointeur sur son contenu (bas 32 bits):
union TValue { double n; struct object { void *payload; uint32_t type; } o; };
Cette technique est parfois appelée marquage NaN (ou boxe NaN), et TValue décrit essentiellement comment LuaJIT représente les valeurs variables dans Lua. TValue a également une troisième hypostase utilisée pour stocker un pointeur sur une fonction et des informations pour rembobiner la pile Lua, c'est-à-dire qu'en dernière analyse, la structure des données ressemble à ceci:
union TValue { double n; struct object { void *payload; uint32_t type; } o; struct frame { void *func; uintptr_t link; } f; };
Le champ frame.link dans la définition ci-dessus est de type uintptr_t, car dans certains cas, il stocke un pointeur et dans d'autres, il s'agit d'un entier. Le résultat est une représentation très compacte de la pile de machines virtuelles - en fait, il s'agit d'un tableau TValue, et chaque élément du tableau est interprété de manière situationnelle soit comme un nombre, puis comme un pointeur typé vers un objet, ou comme des données sur le cadre de la pile Lua.
Regardons un exemple. Imaginez que nous avons commencé avec LuaJIT ce code Lua et défini un point d'arrêt à l'intérieur de la fonction d'impression:
local function foo(x) print("Hello, " .. x) end local function bar(a, b) local n = math.pi foo(b) end bar({}, "Lua")
À ce stade, la pile Lua ressemblera à ceci:

Et tout irait bien, mais cette technique commence à échouer dès que nous essayons de démarrer sur x86-64. Si nous fonctionnons en mode de compatibilité pour les applications 32 bits, nous nous appuyons sur la restriction mmap déjà mentionnée ci-dessus. Et les pointeurs 64 bits ne fonctionneront pas du tout. Que faire Pour résoudre le problème, j'ai dû:
- Étendez TValue de 64 à 128 bits: de cette façon, nous obtenons un vide «honnête» * sur une plate-forme 64 bits.
- Corrigez le code de la machine virtuelle en conséquence.
- Apportez des modifications au compilateur JIT.
Le volume total des changements s'est avéré très important et nous a assez éloignés du LuaJIT original. Il convient de noter que l'extension TValue n'est pas le seul moyen de résoudre le problème. Dans LuaJIT 2.1, nous sommes allés dans l'autre sens en implémentant le mode LJ_GC64. Peter Cawley, qui a énormément contribué au développement de ce mode de fonctionnement, en a pris connaissance lors d'une réunion à Londres. Eh bien, dans le cas de LuaVela, la pile du même exemple ressemble à ceci:
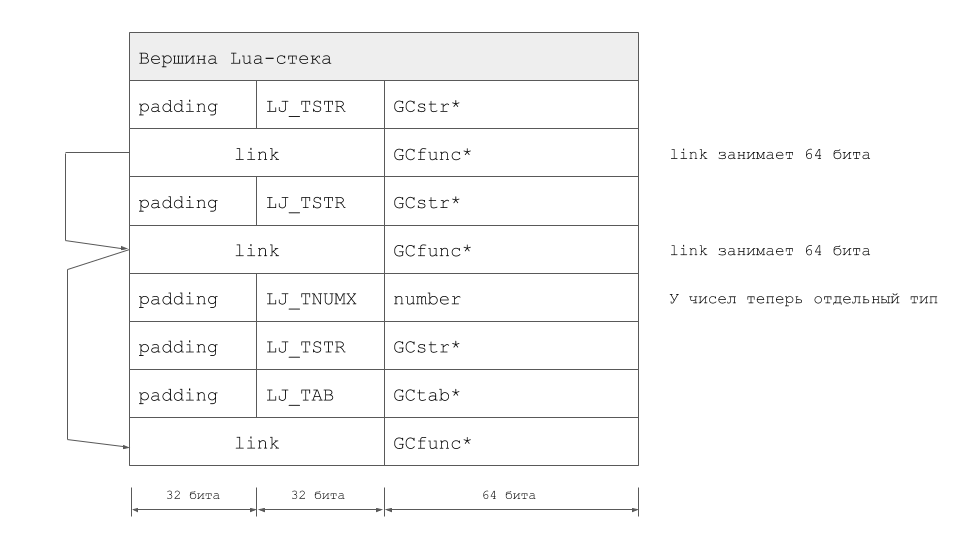
Premiers succès et stabilisation du projet
Après des mois de développement actif, il est temps d'essayer LuaVela au combat. À titre expérimental, nous avons choisi les projets les plus problématiques en termes de consommation de mémoire: la quantité de données avec laquelle ils devaient travailler, dépassait évidemment 1 gigaoctet, ils ont donc été contraints d'utiliser diverses solutions de contournement. Les premiers résultats sont encourageants: LuaVela est stable et présente de meilleures performances par rapport à la configuration LuaJIT utilisée dans ces mêmes projets.
Dans le même temps, la question des tests s'est posée. Heureusement, nous n'avons pas eu à repartir de zéro, car dès le premier jour de développement, en plus des serveurs de mise en scène, nous avions à notre disposition:
- Tests fonctionnels et d'intégration d'un serveur d'applications qui exécute la logique métier de tous les projets de l'entreprise.
- Tests de projets individuels.
Comme la pratique l'a montré, ces ressources étaient suffisantes pour déboguer et amener le projet dans un état stable minimum (ils ont fait un assemblage de dev - déployé en mise en scène - cela fonctionne et ne plante pas). En revanche, de tels tests à travers d'autres projets étaient totalement inadaptés à long terme: un projet d'une telle complexité que l'implémentation d'un langage de programmation ne peut pas avoir ses propres tests. De plus, le manque de tests directement dans le projet a purement techniquement compliqué la recherche et la correction des erreurs.
Dans un monde idéal, nous voulions tester non seulement notre implémentation, mais également disposer d'un ensemble de tests qui nous permettrait de le valider par rapport à la
sémantique du langage . Malheureusement, une certaine déception nous attend à ce sujet. Malgré le fait que la communauté Lua crée volontairement des fourches d'implémentations existantes, jusqu'à récemment, un ensemble similaire de tests de validation manquait. La situation a changé pour le mieux quand, fin 2018, François Perrad a
annoncé le projet lua-Harness.
Au final, nous avons résolu le problème des tests en intégrant les suites de tests les plus complètes et représentatives de l'écosystème Lua dans notre référentiel:
- Tests écrits par les créateurs du langage pour leur implémentation de Lua 5.1.
- Tests fournis par la communauté par l'auteur de LuaJIT, Mike Pall.
- harnais lua
- Un sous-ensemble des tests du projet MAD en cours d'élaboration par le CERN.
- Deux ensembles de tests que nous avons créés dans IPONWEB et qui continuent d'être remplis jusqu'à présent: l' un pour les tests fonctionnels de la plateforme, l' autre utilisant le framework cmocka pour tester l'API C et tout ce qui manque de test au niveau du code Lua.
L'introduction de chaque lot de tests nous a permis de détecter et de corriger 2-3 erreurs critiques - il est donc évident que nos efforts ont porté leurs fruits. Bien que le sujet des tests de runtimes de langage et des compilateurs (à la fois statiques et dynamiques) soit vraiment illimité, nous pensons avoir posé une base assez solide pour un développement stable du projet. Nous avons parlé des problèmes de test de notre propre implémentation de Lua (y compris des sujets tels que le travail avec des bancs de test et le débogage post-mortem) à deux reprises, à
Lua à Moscou 2017 et à
HighLoad ++ 2018 - tous ceux qui sont intéressés par les détails sont invités à regarder une vidéo de ces rapports. Eh bien, regardez le répertoire des
tests dans notre référentiel, bien sûr.
De nouvelles fonctionnalités
Ainsi, nous avions à notre disposition une implémentation stable de Lua 5.1 pour Linux x86-64, développée par les forces d'une petite équipe, qui «maîtrisait» progressivement l'héritage LuaJIT et accumulait une expertise. Dans de telles conditions, le désir d'étendre la plate-forme et d'ajouter des fonctionnalités qui ne sont ni dans vanilla Lua ni dans LuaJIT, mais qui nous aideraient à résoudre d'autres problèmes urgents, est devenu tout à fait naturel.
Une description détaillée de toutes les extensions est fournie dans la
documentation au format RST (utilisez cmake. && make docs pour construire une copie locale au format HTML). Une description complète des extensions de l'API Lua peut être trouvée
sur ce lien , et l'API C
ici . Malheureusement, dans un article de revue, il est impossible de parler de tout, alors voici une liste des fonctions les plus importantes:
- DataState - la possibilité d'organiser l'accès partagé à un objet à partir de plusieurs instances indépendantes de machines virtuelles Lua.
- La possibilité de définir un délai d'expiration pour la coroutine et d'interrompre l'exécution de ceux qui s'exécutent plus longtemps qu'elle.
- Un ensemble d'optimisations de compilateur JIT conçues pour lutter contre l'augmentation exponentielle du nombre de traces lors de la copie de données entre des objets - nous en avons parlé à HighLoad ++ 2017, mais il y a quelques mois à peine, nous avions de nouvelles idées de travail qui n'avaient pas encore été documentées.
- Nouvelle boîte à outils: Sampling Profiler. analyseur de sortie de débogage du compilateur dumpanalyze , etc.
Chacune de ces fonctionnalités mérite un article séparé - écrivez dans les commentaires celui dont vous souhaitez en savoir plus.
Ici, je veux parler un peu plus de la façon dont nous avons réduit la charge sur le ramasse-miettes.
Le scellement vous permet de rendre un objet inaccessible au ramasse-miettes. Dans notre projet typique, la plupart des données (jusqu'à 80%) à l'intérieur de la machine virtuelle Lua sont déjà des règles métier, qui sont une table Lua complexe. La durée de vie de cette table (minutes) est beaucoup plus longue que la durée de vie des demandes traitées (dizaines de millisecondes) et les données qu'elle contient ne changent pas pendant le traitement des requêtes. Dans une telle situation, cela n'a aucun sens de forcer le ramasse-miettes à récurer autour de cette énorme structure de données encore et encore. Pour ce faire, nous «scellons» récursivement l'objet et réorganisons les données de manière à ce que le garbage collector n'atteigne jamais l'objet «scellé» ou son contenu. Dans vanilla Lua 5.4, ce problème sera
résolu en prenant
en charge des générations d'objets dans le garbage collection générationnel.
Il est important de garder à l'esprit que les objets «scellés» ne doivent pas être inscriptibles. Le non-respect de cet invariant conduit à l'apparition de pointeurs pendants: par exemple, un objet "scellé" fait référence à un objet régulier, et un ramasse-miettes, sautant un objet "scellé" en traversant un tas, saute un objet régulier - à la différence qu'un objet "scellé" ne peut pas être libéré, et l'habituel peut. Ayant implémenté le support de cet invariant, nous obtenons essentiellement un support d'
immunité gratuit
pour les objets, dont l'absence est souvent déplorée à Lua. J'insiste sur le fait que les objets immuables et «scellés» ne sont pas la même chose. La deuxième propriété implique la première, mais pas l'inverse.
Je note également que dans Lua 5.1, l'immunité peut être implémentée à l'aide de métatables - la solution fonctionne assez bien, mais n'est pas la plus rentable en termes de performances. De plus amples informations sur le «scellement», l'immunité et la façon dont nous les utilisons dans la vie quotidienne se trouvent dans
ce rapport.
Conclusions
Pour le moment, nous sommes satisfaits de la stabilité et de l'ensemble des opportunités pour notre mise en œuvre. Et bien qu'en raison des limitations initiales, notre implémentation soit nettement inférieure à vanilla Lua et LuaJIT en termes de portabilité, elle résout bon nombre de nos problèmes - nous espérons que ces solutions sont utiles à quelqu'un d'autre.
De plus, même si LuaVela n'est pas adapté à la production, nous vous invitons à l'utiliser comme point d'entrée pour comprendre le fonctionnement de LuaJIT ou de sa fourche. En plus de résoudre des problèmes et d'étendre les fonctionnalités, au fil des ans, nous avons remanié une partie importante de la base de code et rédigé
des articles de formation sur la structure interne du projet - beaucoup d'entre eux s'appliquent non seulement à LuaVela, mais aussi à LuaJIT.
Merci de votre attention, nous attendons les demandes de pull!