Une fois, en explorant les profondeurs d'Internet, je suis tombé sur une vidéo où une personne entraîne un serpent en utilisant un algorithme génétique. Et je voulais la même chose. Mais juste prendre tout de même et écrire en python ne serait pas intéressant. Et j'ai décidé d'utiliser une approche plus moderne pour la formation des systèmes d'agents, à savoir Q-network. Mais commençons par le début.
Formation de renforcement
En apprentissage automatique, RL (Reinforcement Learning) est assez différent des autres domaines. La différence est que l'algorithme ML classique est déjà formé sur les données finies, tandis que le RL, pour ainsi dire, crée ces données pour lui-même. L'idée de RL est qu'en plus de l'algorithme lui-même, qui est appelé un agent, il existe un environnement dans lequel cet agent est placé. À chaque étape, l'agent doit effectuer une action (action), et l'environnement répond avec une récompense (récompense) et son état (état), sur la base desquels l'agent exécute l'action.
Dqn
Il devrait y avoir une explication du fonctionnement de l'algorithme, mais je vais laisser un lien vers où les gens intelligents l'expliquent.
Mise en œuvre de serpent
Après avoir compris c rl, nous devons créer un environnement dans lequel nous placerons l'agent. Heureusement, il n'est pas nécessaire de réinventer la roue, car une entreprise comme open-ai a déjà écrit la bibliothèque du gymnase, avec laquelle vous pouvez écrire votre propre environnement. Dans la bibliothèque, ils sont déjà en grand nombre. Des jeux Atari simples aux modèles 3D complexes. Mais parmi tout cela, il n'y a pas de serpent. Par conséquent, nous procédons à sa création.
Je ne décrirai pas tous les moments de création d'un environnement en salle de gym, mais je ne montrerai que la classe principale, dans laquelle il faut implémenter plusieurs fonctions.
import gym class Env(gym.Env): def __init__(self): pass def step(self, action): """ . , """ def reset(self): """ """ def render(self, mode='human'): """ """
Mais pour mettre en œuvre ces fonctions, nous devons trouver un système de récompenses et sous quelle forme nous donnerons des informations sur l'environnement.
Condition
Dans la vidéo, un homme a donné au serpent la distance du mur, le serpent et la pomme dans 8 directions. Ce sont 24 chiffres. J'ai décidé de réduire la quantité de données, mais je les complique un peu. Tout d'abord, je combinerai la distance entre les murs et la distance avec le serpent. Autrement dit, nous lui dirons la distance à l'objet le plus proche qui peut tuer lors d'une collision. Deuxièmement, il n'y aura que 3 directions et elles dépendront de la direction de déplacement du serpent. Par exemple, au démarrage, le serpent lève les yeux, nous lui indiquerons donc la distance par rapport aux murs supérieur, gauche et droit. Mais lorsque la tête du serpent se tourne vers la droite, nous signalerons déjà la distance vers les murs droit, supérieur et inférieur. Par souci de simplicité, je vais vous donner une photo.

J'ai aussi décidé de jouer avec la pomme. Nous présenterons des informations à ce sujet sous la forme de coordonnées (x, y) dans le système de coordonnées, qui prend naissance à la tête du serpent. Le système de coordonnées changera également son orientation derrière la tête du serpent. Après la photo, je pense que ça devrait définitivement devenir clair.
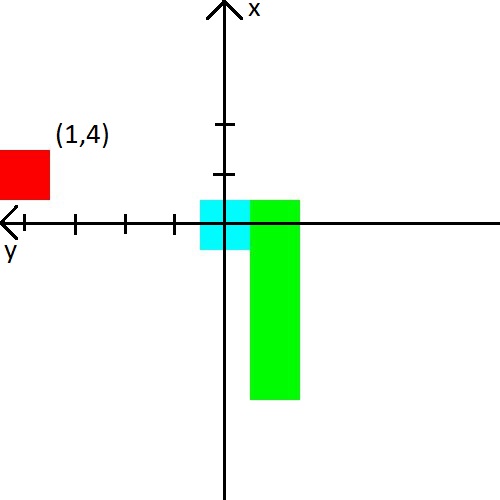
Récompense
Si vous pouvez proposer une sorte de fonctionnalités avec l'état et espérer que le réseau de neurones le découvrira, alors avec le prix, tout sera plus compliqué. Cela dépend d'elle si l'agent apprendra et s'il apprendra ce que nous voulons.
Je donnerai immédiatement le système de récompense avec lequel j'ai obtenu un entraînement stable.
- À chaque étape, la récompense est de -0,25.
- À la mort -10.
- À la mort, jusqu'à 15 étapes -100.
- Lorsque vous mangez une pomme carrée ( nombre de pommes mangées ) * 3.5.
Et donnez également des exemples de ce qui mène à un mauvais système de récompense.
- Si vous ne donnez pas une récompense suffisamment petite pour la mort dans les premières étapes, le serpent préférera tuer contre le mur. C’est plus facile que de chercher des pommes :)
- Si vous donnez une récompense positive pour les étapes, alors le serpent commencera à tourner sans fin. Parce qu'à son avis, ce sera plus rentable que de chercher des pommes.
- Et bien d'autres cas où le serpent n'apprendra tout simplement pas.
Eh bien, un exemple de ce que le serpent a appris dans 2000 épisodes Résumé
Le principal intérêt de l'écriture du serpent était de voir comment le serpent apprend en connaissant si peu son environnement. Et elle a bien étudié, puisque le taux moyen de pommes mangées a atteint 23, ce qui, il me semble, n'est pas très mauvais. Par conséquent, l'expérience peut être considérée comme réussie.
Code source