Il y a un an, j'ai commencé à travailler à temps plein chez Bloomberg. Et puis j'ai décidé d'écrire cet article. J'ai pensé que je serais plein d'idées que je pourrais jeter sur papier le moment venu. Mais en l'espace d'un mois, j'ai réalisé que tout ne serait pas si simple: j'ai déjà commencé à oublier ce que j'ai appris. Soit la connaissance était si bien acquise que mon esprit m'a fait croire que je la savais toujours, soit ils ont juste volé hors de ma tête.
1C'est l'une des raisons pour lesquelles j'ai commencé à tenir un journal. Chaque jour, entrant dans des situations intéressantes, je les décrivais. Et tout cela grâce au fait que j'étais assis à côté d'un programmeur de premier plan. J'ai pu observer de près son travail et j'ai vu à quel point c'était différent de ce que je ferais. Nous avons beaucoup programmé ensemble, ce qui a rendu mes observations encore plus faciles. De plus, notre équipe ne condamne pas «l'espionnage» des personnes écrivant du code. Quand il m'a semblé qu'il se passait quelque chose d'intéressant, je me suis retourné et j'ai regardé. Grâce à l'augmentation constante, j'ai toujours été au courant de ce qui se passait.
J'ai passé un an à côté d'un programmeur de premier plan. Voilà ce que j'ai appris.
Table des matières
Écriture de code
Comment nommer les choses dans le code
L'une de mes premières tâches a été de travailler sur React UI. Nous avions un composant principal qui contenait tous les autres composants. J'aime ajouter un peu d'humour au code, et je voulais nommer le composant principal de
GodComponent . Le moment est venu de revoir le code, et j'ai compris pourquoi il est si difficile de donner des noms.
Chaque morceau de code que j'ai baptisé a acquis un objectif implicite.
GodComponent ? C'est le composant qui récupère toutes les ordures que je ne veux pas mettre au bon endroit. Il contient tout. Nommez-le
LayoutComponent , et l'avenir, je déciderais que ce composant attribue une disposition. Qu'il ne contient pas d'état.
Une autre leçon importante que j'ai apprise est que si quelque chose semble trop gros, comme un
LayoutComponent avec un tas de logique métier, il est temps de le refactoriser, car il ne devrait pas y avoir de logique métier ici. Et dans le cas du nom
GodComponent présence de la logique métier n'aura pas d'importance.
Besoin de nommer les clusters? Les appeler après les services qui s'exécutent sur eux sera une excellente idée jusqu'à ce que vous exécutiez autre chose sur ces clusters. Nous leur avons donné un nom en l'honneur de notre équipe.
La même chose s'applique aux fonctions.
doEverything() est un nom terrible avec de nombreuses conséquences. Si la fonction fait tout, il sera sacrément difficile de tester ses différentes parties. Quelle que soit la taille de cette fonction, elle ne vous semblera jamais trop étrange, car elle devrait tout faire. Alors changez le nom. Refact.
Un nom significatif a un inconvénient. Soudain, le nom sera trop significatif et cachera une sorte de nuance? Par exemple, la
fermeture de sessions ne ferme pas la connexion à la base de données lorsque
session.close() appelée dans SQLAlchemy. J'aurais dû lire la documentation et éviter ce bug, plus à ce sujet dans la section
vélo .
De ce point de vue, nommer des fonctions comme
x ,
y ,
z au lieu de
count() ,
close() ,
insertIntoDB() ne nous permet pas de leur donner une certaine signification et me fait surveiller attentivement ce que font ces fonctions.
2Je n'ai jamais pensé que j'écrirais sur les principes de nommer plus d'une ligne de texte.
Code hérité et prochain développeur
Avez-vous déjà regardé le code et il vous semble étrange? Pourquoi as-tu écrit ça? Cela n'a aucun sens.
J'ai eu la chance de travailler avec une base de code héritée. Ceci, vous le savez, avec des commentaires comme "Décommentez le code lorsque Mahomet comprend la situation." Que fais tu ici? Qui est Mohammed?
Je peux changer de rôle et penser à la personne qui recevra ensuite mon code, cela lui paraîtra-t-il étrange? Une révision partielle de votre code aide vos collègues à réviser votre code. Cela m'a amené à réfléchir au contexte: je dois me souvenir du contexte dans lequel mon équipe travaille.
Si j'oublie ce code, y reviens plus tard et ne peux pas restaurer le contexte, je dirai: «Qu'est-ce qu'ils ont fait? C'est stupide ... Ah, attends, je l'ai fait. "
Et ici, la documentation et les commentaires du code entrent en jeu.
Documentation et commentaires en code
Ils aident à maintenir le contexte et à transmettre les connaissances. Comme Lee l'a dit dans
Comment construire un bon logiciel :
La valeur principale du logiciel n'est pas dans le code créé, mais dans les connaissances accumulées par les personnes qui ont créé ce logiciel
Vous disposez d'un point de terminaison API client ouvert que personne ne semble avoir jamais utilisé. Doit-il simplement être supprimé? D'une manière générale, il s'agit d'un devoir technique. Et si je vous dis que dans l'un des pays 10 journalistes envoient leurs reportages à ce point final une fois par an? Comment le vérifier? Si cela n'est pas mentionné dans la documentation (il l'était), il n'y a aucun moyen de le vérifier. Nous n'avons pas vérifié. Ils l'ont enlevé, et quelques mois plus tard est venu ce moment très annuel. Dix journalistes n'ont pas pu envoyer leurs rapports importants car le point final n'existait plus. Et des personnes connaissant les produits ont déjà quitté l'équipe. Bien sûr, maintenant dans le code, il y a des commentaires expliquant pourquoi cela est nécessaire.
Autant que je sache, chaque équipe se bat avec la documentation. Et avec la documentation, non seulement par code, mais aussi par les processus qui lui sont associés.
Nous n'avons pas encore trouvé la solution parfaite. Personnellement, j'aime la façon dont Antirez a divisé les commentaires dans le code
en différents types de valeurs .
Atomic s'engage
Si vous devez revenir en arrière (et vous en avez besoin. Voir le chapitre
Test ), cette validation aura-t-elle un sens en tant que module unique?
Comment supprimer en toute confiance le code moche
J'étais très désagréable de supprimer le code moche ou obsolète. Il me semblait que tout ce qui était écrit il y a des siècles est sacré. J'ai pensé: "Ils avaient quelque chose en tête quand ils ont écrit comme ça." Il s'agit d'une confrontation entre tradition et culture d'une part, et réflexion à la manière du «principe primaire» d'autre part. C'est la même chose que la suppression du point final annuel. J'ai appris une leçon spéciale.
3J'essaierais de contourner le code et les principaux développeurs essaieraient de le traverser. Effacez-le. Une expression if inaccessible? Ouais, on efface. Qu'ai-je fait? Je viens d'écrire ma fonction dessus. Je n'ai pas réduit la dette technique. Quoi qu'il en soit, je viens d'augmenter la complexité du code et le transfert. Il sera encore plus difficile pour la prochaine personne d'assembler les morceaux de l'image.
Empiriquement, je suis arrivé à la conclusion: il y a un code que vous ne comprenez pas, mais il y a un code que vous ne contacterez certainement jamais. Effacez le code que vous ne contactez pas et soyez prudent avec le code que vous ne comprenez pas.
Examen du code
Un examen du code est un excellent outil pour l'auto-éducation. Il s'agit d'une boucle de rétroaction externe montrant comment ils écriraient le code et comment vous l'avez écrit. Quelle est la différence? D'une manière meilleure qu'une autre? Je me suis posé des questions à ce sujet à chaque avis: «Pourquoi ont-ils écrit de cette façon? Et s'il ne pouvait pas trouver une réponse appropriée, alors il est allé demander.
Après le premier mois, j'ai commencé à trouver des erreurs dans le code de mes collègues (comme ils l'ont trouvé dans le mien). C'était une sorte de folie. La revue est devenue beaucoup plus intéressante pour moi, elle s'est transformée en un jeu qui me manquait, un jeu qui a amélioré mon "sens du code".
D'après mon expérience, vous n'avez pas à approuver le code tant que je ne comprends pas comment il fonctionne.
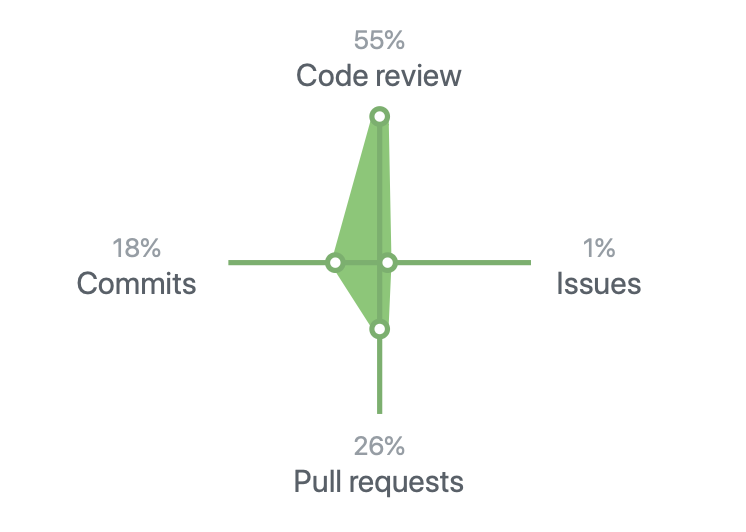 Mes statistiques github.
Mes statistiques github.Test
J'ai tellement aimé les tests qu'il est désagréable d'écrire du code dans une base de code sans tests.
Si votre application ne fait qu'une seule chose (comme tous mes projets scolaires), vous pouvez toujours tester manuellement. C'est exactement ce que j'ai fait. Mais que se passe-t-il si une application effectue 100 tâches différentes? Je ne veux pas passer une demi-heure à tester, et parfois je perds de vue quelque chose. Un cauchemar.
Les tests et l'automatisation des tests aident ici.
Je traite les tests comme de la documentation. Ceci est la documentation de mes idées sur le code. Les tests me disent comment j'imagine (ou quelqu'un d'autre avant moi) le fonctionnement du code et où quelque chose devrait mal tourner.
Aujourd'hui, quand j'écris des tests, j'essaye:
- Montrez comment utiliser la classe, la fonction ou le système de test.
- Montrez ce qui, à mon avis, pourrait mal tourner.
Du coup, je teste le plus souvent le comportement, mais pas l'implémentation (
voici un exemple que j'ai choisi lors des pauses chez Google).
Au paragraphe 2, je n'ai pas mentionné les sources de bugs.
Lorsque je remarque un bogue, je m'assure que le correctif dispose d'un test approprié (appelé test de régression) pour documenter les informations. C'est une autre raison pour laquelle quelque chose pourrait mal tourner.
5Bien sûr, la qualité de mon code s'améliore non pas parce que j'écris des tests, mais parce que j'écris du code. Mais la lecture des tests m'aide à mieux comprendre les situations et à écrire un meilleur code.
C'est la situation générale des tests.
Mais ce n'est pas le seul type de test que j'applique. Je parle des environnements de déploiement. Vous pouvez avoir des tests unitaires idéaux, mais si vous n'avez pas de tests système, quelque chose comme cela peut se produire:

Cela s'applique également au code bien testé: si vous n'avez pas les bibliothèques nécessaires sur votre ordinateur, alors tout se bloquera.
- Il y a des machines sur lesquelles vous développez (la source de tous les mèmes comme "Ça a fonctionné sur mon ordinateur!").
- Il y a des machines sur lesquelles vous testez (peuvent coïncider avec les précédentes).
- Enfin, il y a des machines sur lesquelles vous déployez (elles ne doivent pas coïncider avec les machines sur lesquelles vous avez développé).
Si les environnements de test et de déploiement ne correspondent pas sur les machines, vous aurez des problèmes. Les environnements de déploiement aideront à éviter cela.
Nous faisons du développement local dans Docker sur notre ordinateur.
Nous avons un environnement de développement, ces ordinateurs sont équipés d'un ensemble de bibliothèques (et d'outils de développement), et ici nous installons le code écrit. Ici, il peut être testé avec tous les systèmes nécessaires. Nous avons également un environnement bêta / intermédiaire qui reproduit entièrement l'environnement opérationnel. Enfin, nous avons un environnement opérationnel - des machines qui exécutent du code pour nos clients.
L'idée est de détecter les erreurs qui ne sont pas apparues lors des tests unitaires et système. Par exemple, la différence d'API entre les systèmes demandeur et répondant. Je pense que dans le cas d'un projet personnel ou d'une petite entreprise, la situation peut être complètement différente. Tout le monde n'a pas la possibilité de créer sa propre infrastructure. Cependant, vous pouvez recourir à des services cloud tels que AWS et Azure.
Vous pouvez configurer des clusters individuels pour le développement et le fonctionnement. AWS ECS utilise des images Docker pour se déployer, de sorte que les processus dans différents environnements seront relativement cohérents. Il existe des nuances en termes d'intégration entre les différents services AWS. Appelez-vous le bon point de terminaison à partir du bon environnement?
Vous pouvez aller encore plus loin: téléchargez des images de conteneur alternatives pour d'autres services AWS et configurez un environnement local entièrement basé sur Docker-Compose. Cela accélère la boucle de rétroaction.
6 J'acquérirai peut-être plus d'expérience lorsque je créerai et lancerai mon projet parallèle.
Réduction des risques
Quelles mesures pouvez-vous prendre pour réduire votre risque de catastrophe? Si nous parlons d'un nouveau changement radical, comment pouvons-nous vérifier la durée minimale des temps d'arrêt, en cas de problème? "Nous n'avons pas besoin de déployer complètement le système à cause de tous ces nouveaux changements." Quoi vraiment? Et pourquoi n'y ai-je pas pensé!
L'architecture
Pourquoi parle-t-on d'architecture après avoir écrit du code et testé? Il peut être installé en premier, mais si je n'avais pas programmé et testé dans l'environnement que j'utilisais, je n'aurais probablement pas réussi à créer une architecture qui prenne en compte les caractéristiques de cet environnement.
7
Vous devez beaucoup réfléchir lors de la création d'une architecture.
- Comment les numéros seront-ils utilisés?
- Combien d'utilisateurs y aura-t-il? Combien leur nombre peut-il augmenter (le nombre de lignes dans la base de données en dépend)?
- Quels récifs peuvent se rencontrer?
Je dois transformer cela en une liste de contrôle appelée «Collection de réclamations». Pour l'instant je n'ai pas assez d'expérience, j'essaierai de le faire l'année prochaine chez Bloomberg. Ce processus est en grande partie contraire à Agile: combien pouvez-vous concevoir l'architecture avant de passer à l'implémentation? Tout est question d'équilibre, vous devez choisir quand et ce que vous ferez. Quand est-il sensé de se précipiter et quand - de prendre du recul? Bien sûr, la collecte des exigences ne revient pas à considérer toutes les questions. Je pense que cela vaut la peine si nous incluons les processus de développement dans la conception. Par exemple:
- Comment se déroulera le développement local?
- Comment allons-nous emballer et déployer?
- Comment procéderons-nous aux tests de bout en bout?
- Comment effectuerons-nous des tests de résistance du nouveau service?
- Comment garderons-nous des secrets?
- Intégration CI / CD?
Nous avons récemment développé un nouveau moteur de recherche pour
BNEF . C'était merveilleux de travailler dessus, j'ai organisé un développement local et découvert DPG (packages et leur déploiement), levant le déploiement de secrets.
Qui aurait pensé que le déploiement de secrets sur une prod pourrait être si simple:
- Ils ne peuvent pas être placés dans le code, car quelqu'un peut les remarquer
- Les stocker comme variable d'environnement car la spécification propose 12 facteurs d'application? Pas une mauvaise idée, mais comment les mettre là? (Aller à la prod pour remplir les variables d'environnement à chaque démarrage de la voiture est une douleur)
- Les déployer en tant que fichiers? Mais d'où viendront-ils et comment les remplir?
Nous ne voulons pas tout faire manuellement.
En conséquence, nous sommes arrivés à une base de données avec un contrôle d'accès basé sur les rôles (seuls nous et nos ordinateurs pouvons communiquer avec la base de données). Notre code reçoit des secrets de la base de données au démarrage. Cette approche est bien reproduite dans le cadre des environnements de développement, de transfert et d'exploitation; les secrets sont stockés dans des bases de données appropriées.
Encore une fois, avec des services cloud comme AWS, la situation peut être complètement différente. Vous n'avez pas besoin de vous occuper des secrets d'une manière ou d'une autre. Obtenez un compte pour votre rôle, entrez les secrets dans l'interface et votre code les trouvera quand ils seront nécessaires. Cela simplifie grandement tout, mais je suis heureux d'avoir acquis de l'expérience, grâce à laquelle je peux apprécier cette simplicité.
Nous créons de l'architecture, sans oublier la maintenance
La conception du système est inspirante. Et l'escorte? Pas trop. Mon voyage dans le monde des escortes m'a conduit à la question: pourquoi et comment les systèmes se dégradent-ils? La première partie de la réponse n'est pas liée au déclassement de tous obsolètes, mais seulement à l'ajout d'un nouveau. La tendance à ajouter plutôt qu'à supprimer (cela ne rappelle-t-il rien?). La deuxième partie est la conception avec l'objectif ultime à l'esprit. Un système qui, avec le temps, commence à faire ce à quoi il n'était pas destiné, ne fonctionnera pas nécessairement aussi bien qu'un système initialement conçu pour les mêmes tâches. Il s'agit d'une approche de style pas en arrière, pas de trucs et astuces.
Je connais au moins trois façons de réduire le taux de dégradation.
- Logique métier et infrastructure distinctes: l'infrastructure se dégrade généralement - la charge augmente, les frameworks deviennent obsolètes, des vulnérabilités zero-day apparaissent, etc.
- Créez des processus pour une assistance future. Appliquez les mêmes mises à jour pour les anciens et les nouveaux bits. Cela évitera les différences entre l'ancien et le nouveau et gardera tout le code dans un état «moderne».
- Assurez-vous de jeter tout ce qui est inutile et ancien.
Déploiement
Vais-je regrouper des fonctionnalités ou les déployer une à la fois? Selon le processus en cours, si vous les regroupez, attendez les problèmes. Demandez-vous pourquoi vous souhaitez regrouper des fonctionnalités?
- Le déploiement prend beaucoup de temps?
- La révision de code n'est-elle pas trop amusante?
Quelle que soit la raison, cette situation doit être corrigée. Je connais au moins deux problèmes liés à l'emballage:
- Vous bloquez vous-même toutes les fonctionnalités si l'une d'elles a un bug.
- Vous augmentez le risque de problèmes.
Quel que soit le processus de déploiement que vous choisissez, vous voulez toujours que vos voitures soient comme du bétail, pas comme des animaux de compagnie. Ils ne sont pas uniques. Vous savez exactement ce qui est exécuté sur chaque machine, comment les recréer en cas de décès. Vous ne serez pas contrarié si une voiture meurt, vous en prenez une nouvelle. Vous les faites paître, vous ne grandissez pas.
Quand quelque chose tourne mal
En cas de problème - et c'est le cas - il existe une règle d'or: minimiser l'impact sur les clients. En cas d'échecs, mon premier désir a toujours été de le réparer. Cela ne semble pas être la solution optimale. Au lieu de réparer, même si cela peut être fait sur une seule ligne, vous devez d'abord revenir en arrière. Revenez à l'état de fonctionnement précédent. C'est le moyen le plus rapide de ramener les clients à une version fonctionnelle. Ce n'est qu'alors que je découvre quel est le problème et le règle.
Il en va de même pour la machine «endommagée» de votre cluster: éteignez-la, marquez-la comme inaccessible, avant de découvrir ce qui lui est arrivé. Je trouve étrange combien mon désir naturel et mes instincts contredisent la solution optimale.
Je pense que cet instinct a également conduit au fait que j'ai corrigé les bugs plus longtemps. Parfois, je me rendais compte que quelque chose ne fonctionnait pas, parce que le code que j'avais écrit était en quelque sorte faux, et je grimpais dans la nature, en regardant chaque ligne. Quelque chose comme une recherche «d'abord en profondeur». Et quand il s'est avéré que le problème est survenu en raison d'un changement de configuration, c'est-à-dire que je ne l'ai pas vérifié en premier lieu, cette situation m'a perturbé. J'ai perdu beaucoup de temps à chercher un bug.
Depuis lors, j'ai appris à chercher «en premier» et donc déjà «en premier» afin d'exclure des raisons de niveau supérieur. Que puis-je confirmer exactement avec les ressources actuelles?
- La voiture fonctionne-t-elle?
- Le code est-il installé correctement?
- Y a-t-il une configuration?
- <Configuration spécifique au code>, par exemple si le routage est correctement défini?
- La version du schéma est-elle correcte?
- Et puis je plonge dans le code.
Nous pensions que nginx n'était pas installé correctement, mais il s'est avéré que la configuration était désactivée
Bien sûr, je n'ai pas besoin de le faire à chaque fois. Parfois, un simple message d'erreur suffit pour passer immédiatement au code. Lorsque je ne peux pas déterminer la cause, j'essaie de minimiser le nombre de changements de code afin de trouver la raison. Moins il y a de changements, plus vite je peux trouver la véritable racine du problème. De plus, j'ai maintenant un mémo pour les bugs qui m'a sauvé plus d'une heure en pensant "qu'est-ce que j'ai raté?" Parfois, j'oublie les vérifications les plus simples, telles que la configuration du routage, le schéma correspondant et les versions de service, etc. C'est une autre étape dans la maîtrise de la pile technologique que j'utilise, et ce que vous gagnez uniquement avec l'expérience, c'est l'intuition pour déterminer ce qui ne fonctionne pas exactement.
Vélo
Cet article ne peut pas être complet sans histoire. , . SQLAlchemy. BNEF , . . SQLAlchemy, , Solr. - .
«MYSQL server has gone away.» . , , . , . , . , ?
, ? , , . , ,
__exit__() session.close() .
, , . . . . .
Session.close() MySQL- SQLAlchemy , NullPool. . , , . : StackOverflow (, !) , , SQL- . , . , , (), .
«» , 1 8. , , — .
, .
, . , , . , .
, , , . , . , . «
?! , ? ».
, : , . , , . , , . , . — ? , , . . , -, , , , , .. .
. , , ? (, AWS CloudWatch Grafana). .
. , , 50 %, — . ? . , — (, ?).
. , , , , ? ? , ?
, . , . — - .
Conclusion
. , , , . , - !
. , !
, . , — How to Build Good Software .
. : ! , .
- ?
- ? , ? , ?
- . , ? ?
- (utils) (, , , ) , « »?
- ?
- , , - ?
- — API , ?
- ? , .
- , , . , , .
- PR: « , , 52 , , , , , ». ?
- . ?
- ?
- ?
- . , ? - ? , ?
- ,
x() , y() z(), x() , y() z() . , WYSIATI .
- .
- . , ?
- , - , , . , .
- , , Docker- AWS.
- .