Beaucoup utilisent des outils spécialisés pour créer des procédures d'extraction, de transformation et de chargement de données dans des bases de données relationnelles. Le processus des outils de travail est enregistré, des erreurs sont enregistrées.
En cas d'erreur, le journal contient des informations indiquant que l'outil n'a pas pu terminer la tâche et les modules (souvent java) où ils se sont arrêtés. Dans les dernières lignes, vous pouvez trouver une erreur de base de données, par exemple, une violation d'une clé de table unique.
Pour répondre à la question, quel rôle jouent les informations d'erreur ETL, j'ai classé tous les problèmes qui se sont produits dans le référentiel assez volumineux au cours des deux dernières années.

Caractéristiques du stockage où le classement a été effectué:
- 20 sources de données connectées
- 10,5 milliards de lignes sont traitées quotidiennement
- qui sont agrégées jusqu'à 50 millions de lignes,
- les données traitent 140 paquets en 700 étapes (une étape correspond à une requête SQL)
- serveur - base de données X5 à 4 nœuds
Les erreurs de base de données incluent par exemple un manque d'espace, une connexion déconnectée, une suspension de session, etc.
Les erreurs logiques incluent les violations des clés de table, les objets invalides, le manque d'accès aux objets, etc.
L'ordonnanceur peut ne pas démarrer au bon moment, il peut se bloquer, etc.
Les erreurs simples ne nécessitent pas beaucoup de temps pour être corrigées. Avec la plupart d'entre eux, un bon ETL peut se débrouiller seul.
Les erreurs compliquées nécessitent d'ouvrir et de vérifier les procédures de travail avec les données, de rechercher des sources de données. Souvent, il est nécessaire de tester les modifications et le déploiement.
Ainsi, la moitié de tous les problèmes sont liés à la base de données. 48% de toutes les erreurs sont de simples erreurs.
La troisième partie de tous les problèmes est associée à un changement de logique ou de modèle de stockage, plus de la moitié de ces erreurs sont complexes.
Et moins d'un quart de tous les problèmes sont liés au planificateur de tâches, dont 18% sont de simples erreurs.
En général, 22% de toutes les erreurs qui se sont produites sont complexes; les corriger nécessite le plus d'attention et de temps. Ils surviennent environ une fois par semaine. Alors que de simples erreurs se produisent presque tous les jours.
De toute évidence, la surveillance des processus ETL sera alors efficace lorsque l'emplacement de l'erreur est indiqué aussi précisément que possible dans le journal et qu'un temps minimum est nécessaire pour trouver la source du problème.
Suivi efficace
Que voulais-je voir dans le processus de surveillance ETL?
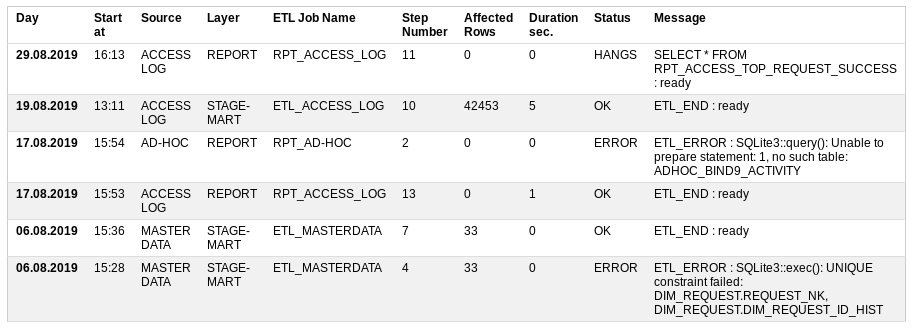
Commencer à - quand a commencé
Source - une source de données
Couche - quel niveau de stockage charge,
ETL Job Name est une procédure de chargement qui se compose de nombreuses petites étapes,
Numéro de l'étape - le numéro de l'étape à effectuer,
Lignes affectées - combien de données ont déjà été traitées,
Durée sec - combien de temps il faut pour exécuter,
Statut - si tout va bien ou non: OK, ERREUR, COURANT, SUSPENDUS
Message - Le dernier message réussi ou la description de l'erreur.
En fonction de l'état des entrées, vous pouvez envoyer un e-mail. lettre aux autres participants. S'il n'y a pas d'erreurs, la lettre n'est pas nécessaire.
Ainsi, en cas d'erreur, le lieu de l'incident est clairement indiqué.
Parfois, il arrive que l'outil de surveillance lui-même ne fonctionne pas. Dans ce cas, il est possible d'appeler directement une vue (vue) dans la base de données, sur la base de laquelle le rapport est construit.
Tableau de surveillance ETL
Pour implémenter la surveillance des processus ETL, une table et une vue suffisent.
Pour ce faire, vous pouvez retourner dans
votre petit référentiel et créer un prototype dans la base de données sqlite.
Tables DDLCREATE TABLE UTL_JOB_STATUS ( UTL_JOB_STATUS_ID INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT, SID INTEGER NOT NULL DEFAULT -1, LOG_DT INTEGER NOT NULL DEFAULT 0, LOG_D INTEGER NOT NULL DEFAULT 0, JOB_NAME TEXT NOT NULL DEFAULT 'N/A', STEP_NAME TEXT NOT NULL DEFAULT 'N/A', STEP_DESCR TEXT, UNIQUE (SID, JOB_NAME, STEP_NAME) ); INSERT INTO UTL_JOB_STATUS (UTL_JOB_STATUS_ID) VALUES (-1);
Soumission / rapport DDL CREATE VIEW IF NOT EXISTS UTL_JOB_STATUS_V AS WITH SRC AS ( SELECT LOG_D, LOG_DT, UTL_JOB_STATUS_ID, SID, CASE WHEN INSTR(JOB_NAME, 'FTP') THEN 'TRANSFER' WHEN INSTR(JOB_NAME, 'STG') THEN 'STAGE' WHEN INSTR(JOB_NAME, 'CLS') THEN 'CLEANSING' WHEN INSTR(JOB_NAME, 'DIM') THEN 'DIMENSION' WHEN INSTR(JOB_NAME, 'FCT') THEN 'FACT' WHEN INSTR(JOB_NAME, 'ETL') THEN 'STAGE-MART' WHEN INSTR(JOB_NAME, 'RPT') THEN 'REPORT' ELSE 'N/A' END AS LAYER, CASE WHEN INSTR(JOB_NAME, 'ACCESS') THEN 'ACCESS LOG' WHEN INSTR(JOB_NAME, 'MASTER') THEN 'MASTER DATA' WHEN INSTR(JOB_NAME, 'AD-HOC') THEN 'AD-HOC' ELSE 'N/A' END AS SOURCE, JOB_NAME, STEP_NAME, CASE WHEN STEP_NAME='ETL_START' THEN 1 ELSE 0 END AS START_FLAG, CASE WHEN STEP_NAME='ETL_END' THEN 1 ELSE 0 END AS END_FLAG, CASE WHEN STEP_NAME='ETL_ERROR' THEN 1 ELSE 0 END AS ERROR_FLAG, STEP_NAME || ' : ' || STEP_DESCR AS STEP_LOG, SUBSTR( SUBSTR(STEP_DESCR, INSTR(STEP_DESCR, '***')+4), 1, INSTR(SUBSTR(STEP_DESCR, INSTR(STEP_DESCR, '***')+4), '***')-2 ) AS AFFECTED_ROWS FROM UTL_JOB_STATUS WHERE datetime(LOG_D, 'unixepoch') >= date('now', 'start of month', '-3 month') ) SELECT JB.SID, JB.MIN_LOG_DT AS START_DT, strftime('%d.%m.%Y %H:%M', datetime(JB.MIN_LOG_DT, 'unixepoch')) AS LOG_DT, JB.SOURCE, JB.LAYER, JB.JOB_NAME, CASE WHEN JB.ERROR_FLAG = 1 THEN 'ERROR' WHEN JB.ERROR_FLAG = 0 AND JB.END_FLAG = 0 AND strftime('%s','now') - JB.MIN_LOG_DT > 0.5*60*60 THEN 'HANGS' WHEN JB.ERROR_FLAG = 0 AND JB.END_FLAG = 0 THEN 'RUNNING' ELSE 'OK' END AS STATUS, ERR.STEP_LOG AS STEP_LOG, JB.CNT AS STEP_CNT, JB.AFFECTED_ROWS AS AFFECTED_ROWS, strftime('%d.%m.%Y %H:%M', datetime(JB.MIN_LOG_DT, 'unixepoch')) AS JOB_START_DT, strftime('%d.%m.%Y %H:%M', datetime(JB.MAX_LOG_DT, 'unixepoch')) AS JOB_END_DT, JB.MAX_LOG_DT - JB.MIN_LOG_DT AS JOB_DURATION_SEC FROM ( SELECT SID, SOURCE, LAYER, JOB_NAME, MAX(UTL_JOB_STATUS_ID) AS UTL_JOB_STATUS_ID, MAX(START_FLAG) AS START_FLAG, MAX(END_FLAG) AS END_FLAG, MAX(ERROR_FLAG) AS ERROR_FLAG, MIN(LOG_DT) AS MIN_LOG_DT, MAX(LOG_DT) AS MAX_LOG_DT, SUM(1) AS CNT, SUM(IFNULL(AFFECTED_ROWS, 0)) AS AFFECTED_ROWS FROM SRC GROUP BY SID, SOURCE, LAYER, JOB_NAME ) JB, ( SELECT UTL_JOB_STATUS_ID, SID, JOB_NAME, STEP_LOG FROM SRC WHERE 1 = 1 ) ERR WHERE 1 = 1 AND JB.SID = ERR.SID AND JB.JOB_NAME = ERR.JOB_NAME AND JB.UTL_JOB_STATUS_ID = ERR.UTL_JOB_STATUS_ID ORDER BY JB.MIN_LOG_DT DESC, JB.SID DESC, JB.SOURCE;
SQL Vérification de la possibilité d'obtenir un nouveau numéro de session SELECT SUM ( CASE WHEN start_job.JOB_NAME IS NOT NULL AND end_job.JOB_NAME IS NULL AND NOT ( 'y' = 'n' ) THEN 1 ELSE 0 END ) AS IS_RUNNING FROM ( SELECT 1 AS dummy FROM UTL_JOB_STATUS WHERE sid = -1) d_job LEFT OUTER JOIN ( SELECT JOB_NAME, SID, 1 AS dummy FROM UTL_JOB_STATUS WHERE JOB_NAME = 'RPT_ACCESS_LOG' AND STEP_NAME = 'ETL_START' GROUP BY JOB_NAME, SID ) start_job ON d_job.dummy = start_job.dummy LEFT OUTER JOIN ( SELECT JOB_NAME, SID FROM UTL_JOB_STATUS WHERE JOB_NAME = 'RPT_ACCESS_LOG' AND STEP_NAME in ('ETL_END', 'ETL_ERROR') GROUP BY JOB_NAME, SID ) end_job ON start_job.JOB_NAME = end_job.JOB_NAME AND start_job.SID = end_job.SID
Caractéristiques de la table:
- le début et la fin de la procédure de traitement des données doivent être suivis des étapes ETL_START et ETL_END
- en cas d'erreur, l'étape ETL_ERROR doit être créée avec sa description
- la quantité de données traitées doit être mise en évidence, par exemple, avec des astérisques
- en même temps, la même procédure peut être démarrée avec le paramètre force_restart = y; sans lui, le numéro de session n'est attribué qu'à la procédure terminée
- en mode normal, vous ne pouvez pas exécuter la même procédure de traitement de données en parallèle
Les opérations nécessaires pour travailler avec la table sont les suivantes:
- obtenir le numéro de session de la procédure ETL pour démarrer
- insérer une entrée de journal dans une table
- obtenir le dernier enregistrement de procédure ETL réussi
Dans des bases de données telles qu'Oracle ou Postgres, ces opérations peuvent être implémentées avec des fonctions intégrées. Sqlite a besoin d'un mécanisme externe, et dans ce cas, il est
prototypé en PHP .
Conclusion
Ainsi, les messages d'erreur dans les outils de traitement des données jouent un rôle méga-important. Mais il est difficile de les appeler optimaux pour une recherche rapide des causes du problème. Lorsque le nombre de procédures approche la centaine, le suivi des processus devient un projet complexe.
L'article fournit un exemple de solution possible au problème sous la forme d'un prototype. Le prototype entier du petit référentiel est disponible dans les utilitaires gitlab
SQLite PHP ETL .