J'avais peur de la mise en cache. Je ne voulais vraiment pas grimper et découvrir ce que c'était, j'ai immédiatement imaginé des choses de luto-entreprise dans le compartiment moteur que seul le gagnant de l'olympiade de mathématiques pouvait comprendre. Il s'est avéré que ce n'est pas le cas. La mise en cache s'est avérée être très simple, compréhensible et incroyablement facile à mettre en œuvre dans n'importe quel projet.
Dans cet article, je vais essayer d'expliquer la mise en cache aussi simple que je comprends maintenant. Vous apprendrez comment implémenter la mise en cache en 1 minute, comment mettre en cache par clé, définir la durée de vie du cache et bien d'autres choses que vous devez savoir si vous avez été invité à mettre en cache quelque chose dans votre projet de travail, et vous ne voulez pas brouiller le visage.
Pourquoi dis-je "confié"? Parce que la mise en cache, en règle générale, il est logique de l'appliquer dans de grands projets très chargés, avec des dizaines de milliers de demandes par minute. Dans de tels projets, afin de ne pas surcharger la base de données, ils mettent généralement en cache les appels du référentiel. Surtout s'il est connu que les données d'un système maître sont mises à jour à une certaine fréquence. Nous n'écrivons pas nous-mêmes de tels projets, nous y travaillons. Si le projet est petit et ne menace pas les surcharges, alors, bien sûr, il vaut mieux ne rien mettre en cache - toujours de nouvelles données sont toujours meilleures que celles mises à jour périodiquement.
Habituellement, dans les postes de formation, le locuteur rampe d'abord sous le capot, commence à se plonger dans les tripes de la technologie, ce qui dérange beaucoup le lecteur, et ce n'est qu'alors, lorsqu'il a feuilleté une bonne moitié de l'article et n'a rien compris, qu'il raconte comment cela fonctionne. Tout sera différent avec nous. Tout d'abord, nous le faisons fonctionner, et de préférence, avec le moins d'effort, puis, si vous êtes intéressé, vous pouvez regarder sous le capot du cache, regarder à l'intérieur du bac lui-même et affiner la mise en cache. Mais même si vous ne le faites pas (et cela commence par le point 6), votre mise en cache fonctionnera comme ça.
Nous allons créer un projet dans lequel nous analyserons tous les aspects de la mise en cache que j'ai promis. À la fin, comme d'habitude, il y aura un lien vers le projet lui-même.
0. Création d'un projet
Nous allons créer un projet très simple dans lequel nous pouvons extraire l'entité de la base de données. J'ai ajouté Lombok, Spring Cache, Spring Data JPA et H2 au projet. Cependant, seul Spring Cache peut être supprimé.
plugins { id 'org.springframework.boot' version '2.1.7.RELEASE' id 'io.spring.dependency-management' version '1.0.8.RELEASE' id 'java' } group = 'ru.xpendence' version = '0.0.1-SNAPSHOT' sourceCompatibility = '1.8' configurations { compileOnly { extendsFrom annotationProcessor } } repositories { mavenCentral() } dependencies { implementation 'org.springframework.boot:spring-boot-starter-cache' implementation 'org.springframework.boot:spring-boot-starter-data-jpa' compileOnly 'org.projectlombok:lombok' runtimeOnly 'com.h2database:h2' annotationProcessor 'org.projectlombok:lombok' testImplementation 'org.springframework.boot:spring-boot-starter-test' }
Nous n'aurons qu'une seule entité, appelons-la Utilisateur.
@Entity @Table(name = "users") @Data @NoArgsConstructor @ToString public class User implements Serializable { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; @Column(name = "name") private String name; @Column(name = "email") private String email; public User(String name, String email) { this.name = name; this.email = email; } }
Ajoutez le référentiel et le service:
public interface UserRepository extends JpaRepository<User, Long> { } @Slf4j @Service public class UserServiceImpl implements UserService { private final UserRepository repository; public UserServiceImpl(UserRepository repository) { this.repository = repository; } @Override public User create(User user) { return repository.save(user); } @Override public User get(Long id) { log.info("getting user by id: {}", id); return repository.findById(id) .orElseThrow(() -> new EntityNotFoundException("User not found by id " + id)); } }
Lorsque nous entrons dans la méthode de service get (), nous écrivons à ce sujet dans le journal.
Connectez-vous au projet Spring Cache.
@SpringBootApplication @EnableCaching
Le projet est prêt.
1. Mise en cache du résultat de retour
Que fait Spring Cache? Spring Cache met simplement en cache le résultat de retour pour des paramètres d'entrée spécifiques. Voyons ça. Nous mettrons l'annotation @Cacheable sur la méthode de service get () pour mettre en cache les données retournées. Nous donnons à cette annotation le nom «utilisateurs» (nous analyserons plus en détail pourquoi cela se fait séparément).
@Override @Cacheable("users") public User get(Long id) { log.info("getting user by id: {}", id); return repository.findById(id) .orElseThrow(() -> new EntityNotFoundException("User not found by id " + id)); }
Afin de vérifier comment cela fonctionne, nous écrirons un test simple.
@RunWith(SpringRunner.class) @SpringBootTest public abstract class AbstractTest { }
@Slf4j public class UserServiceTest extends AbstractTest { @Autowired private UserService service; @Test public void get() { User user1 = service.create(new User("Vasya", "vasya@mail.ru")); User user2 = service.create(new User("Kolya", "kolya@mail.ru")); getAndPrint(user1.getId()); getAndPrint(user2.getId()); getAndPrint(user1.getId()); getAndPrint(user2.getId()); } private void getAndPrint(Long id) { log.info("user found: {}", service.get(id)); } }
Une petite digression, pourquoi j'écris habituellement AbstractTest et en hérite tous les tests.Si la classe a sa propre annotation @SpringBootTest, le contexte est re-levé pour une telle classe à chaque fois. Étant donné que le contexte peut augmenter pendant 5 secondes, voire 40 secondes, cela en tout cas inhibe considérablement le processus de test. En même temps, il n'y a généralement pas de différence de contexte et lorsque vous exécutez chaque groupe de tests dans la même classe, il n'est pas nécessaire de redémarrer le contexte. Si nous mettons une seule annotation, disons, sur une classe abstraite, comme dans notre cas, cela nous permet de ne soulever le contexte qu'une seule fois.
Par conséquent, je préfère réduire le nombre de contextes soulevés lors des tests / assemblages, si possible.
Que fait notre test? Il crée deux utilisateurs, puis les extrait de la base de données 2 fois. Comme nous nous en souvenons, nous avons mis l'annotation @Cacheable, qui mettra en cache les valeurs renvoyées. Après avoir reçu l'objet de la méthode get (), nous sortons l'objet dans le journal. De plus, nous enregistrons des informations sur chaque visite de l'application dans la méthode get ().
Exécutez le test. C'est ce que nous obtenons dans la console.
getting user by id: 1 user found: User(id=1, name=Vasya, email=vasya@mail.ru) getting user by id: 2 user found: User(id=2, name=Kolya, email=kolya@mail.ru) user found: User(id=1, name=Vasya, email=vasya@mail.ru) user found: User(id=2, name=Kolya, email=kolya@mail.ru)
Comme nous le voyons, les deux premières fois, nous sommes vraiment allés à la méthode get () et avons en fait obtenu l'utilisateur de la base de données. Dans tous les autres cas, il n'y a pas eu d'appel réel à la méthode, l'application a pris les données mises en cache par clé (dans ce cas, c'est id).
2. Déclaration de la clé de mise en cache
Il existe des situations où plusieurs paramètres arrivent à la méthode mise en cache. Dans ce cas, il peut être nécessaire de déterminer le paramètre par lequel la mise en cache se produira. Nous ajoutons un exemple à une méthode qui enregistrera une entité assemblée par paramètres dans la base de données, mais si une entité du même nom existe déjà, nous ne l'enregistrerons pas. Pour ce faire, nous définirons le paramètre name comme clé de mise en cache. Cela ressemblera à ceci:
@Override @Cacheable(value = "users", key = "#name") public User create(String name, String email) { log.info("creating user with parameters: {}, {}", name, email); return repository.save(new User(name, email)); }
Écrivons le test correspondant:
@Test public void create() { createAndPrint("Ivan", "ivan@mail.ru"); createAndPrint("Ivan", "ivan1122@mail.ru"); createAndPrint("Sergey", "ivan@mail.ru"); log.info("all entries are below:"); service.getAll().forEach(u -> log.info("{}", u.toString())); } private void createAndPrint(String name, String email) { log.info("created user: {}", service.create(name, email)); }
Nous allons essayer de créer trois utilisateurs, pour deux dont le nom sera le même
createAndPrint("Ivan", "ivan@mail.ru"); createAndPrint("Ivan", "ivan1122@mail.ru");
et pour deux dont l'e-mail correspondra
createAndPrint("Ivan", "ivan@mail.ru"); createAndPrint("Sergey", "ivan@mail.ru");
Dans la méthode de création, nous enregistrons chaque fait que la méthode est appelée, et nous enregistrons également toutes les entités que cette méthode nous a renvoyées. Le résultat sera comme ceci:
creating user with parameters: Ivan, ivan@mail.ru created user: User(id=1, name=Ivan, email=ivan@mail.ru) created user: User(id=1, name=Ivan, email=ivan@mail.ru) creating user with parameters: Sergey, ivan@mail.ru created user: User(id=2, name=Sergey, email=ivan@mail.ru) all entries are below: User(id=1, name=Ivan, email=ivan@mail.ru) User(id=2, name=Sergey, email=ivan@mail.ru)
Nous voyons qu'en fait, l'application a appelé la méthode 3 fois et n'y est entrée que deux fois. Une fois qu'une clé correspondait à une méthode, elle renvoyait simplement une valeur mise en cache.
3. Mise en cache forcée. @CachePut
Il y a des situations où nous voulons mettre en cache la valeur de retour pour une entité, mais en même temps, nous devons mettre à jour le cache. Pour de tels besoins, l'annotation @CachePut existe. Il transmet l'application à la méthode, tout en mettant à jour le cache pour la valeur de retour, même s'il est déjà mis en cache.
Ajoutez quelques méthodes dans lesquelles nous enregistrerons l'utilisateur. Nous marquerons l'un d'eux avec l'annotation @Cacheable habituelle, la seconde avec @CachePut.
@Override @Cacheable(value = "users", key = "#user.name") public User createOrReturnCached(User user) { log.info("creating user: {}", user); return repository.save(user); } @Override @CachePut(value = "users", key = "#user.name") public User createAndRefreshCache(User user) { log.info("creating user: {}", user); return repository.save(user); }
La première méthode renverra simplement les valeurs mises en cache, la seconde forcera la mise à jour du cache. La mise en cache sera effectuée à l'aide de la clé # user.name. Nous écrirons le test correspondant.
@Test public void createAndRefresh() { User user1 = service.createOrReturnCached(new User("Vasya", "vasya@mail.ru")); log.info("created user1: {}", user1); User user2 = service.createOrReturnCached(new User("Vasya", "misha@mail.ru")); log.info("created user2: {}", user2); User user3 = service.createAndRefreshCache(new User("Vasya", "kolya@mail.ru")); log.info("created user3: {}", user3); User user4 = service.createOrReturnCached(new User("Vasya", "petya@mail.ru")); log.info("created user4: {}", user4); }
Selon la logique qui a déjà été décrite, la première fois qu'un utilisateur portant le nom «Vasya» est enregistré via la méthode createOrReturnCached (), nous recevrons alors une entité mise en cache et l'application n'entrera pas dans la méthode elle-même. Si nous appelons la méthode createAndRefreshCache (), l'entité mise en cache pour la clé nommée "Vasya" sera écrasée dans le cache. Exécutons le test et voyons ce qui sera affiché dans la console.
creating user: User(id=null, name=Vasya, email=vasya@mail.ru) created user1: User(id=1, name=Vasya, email=vasya@mail.ru) created user2: User(id=1, name=Vasya, email=vasya@mail.ru) creating user: User(id=null, name=Vasya, email=kolya@mail.ru) created user3: User(id=2, name=Vasya, email=kolya@mail.ru) created user4: User(id=2, name=Vasya, email=kolya@mail.ru)
Nous voyons que user1 a réussi à écrire dans la base de données et le cache. Lorsque nous essayons d'enregistrer à nouveau l'utilisateur avec le même nom, nous obtenons le résultat mis en cache du premier appel (user2, pour lequel l'id est le même que user1, ce qui nous dit que l'utilisateur n'a pas été écrit, et ce n'est qu'un cache). Ensuite, nous écrivons le troisième utilisateur via la deuxième méthode, qui, même avec le résultat mis en cache, appelle toujours la méthode et écrit un nouveau résultat dans le cache. Il s'agit de user3. Comme nous pouvons le voir, il a déjà un nouvel identifiant. Après quoi, nous appelons la première méthode, qui prend le nouveau cache ajouté par user3.
4. Suppression du cache. @CacheEvict
Parfois, il devient nécessaire de mettre à jour certaines données dans le cache. Par exemple, une entité a déjà été supprimée de la base de données, mais elle est toujours accessible à partir du cache. Pour maintenir la cohérence des données, nous devons au moins ne pas stocker les données supprimées dans le cache.
Ajoutez quelques méthodes supplémentaires au service.
@Override public void delete(Long id) { log.info("deleting user by id: {}", id); repository.deleteById(id); } @Override @CacheEvict("users") public void deleteAndEvict(Long id) { log.info("deleting user by id: {}", id); repository.deleteById(id); }
Le premier supprimera simplement l'utilisateur, le second le supprimera également, mais nous le marquerons avec l'annotation @CacheEvict. Ajoutez un test qui créera deux utilisateurs, après quoi l'un sera supprimé via une méthode simple et le second via une méthode annotée. Après cela, nous obtiendrons ces utilisateurs via la méthode get ().
@Test public void delete() { User user1 = service.create(new User("Vasya", "vasya@mail.ru")); log.info("{}", service.get(user1.getId())); User user2 = service.create(new User("Vasya", "vasya@mail.ru")); log.info("{}", service.get(user2.getId())); service.delete(user1.getId()); service.deleteAndEvict(user2.getId()); log.info("{}", service.get(user1.getId())); log.info("{}", service.get(user2.getId())); }
Il est logique que puisque notre utilisateur est déjà mis en cache, la suppression ne nous empêchera pas de l'obtenir, car il est mis en cache. Voyons les journaux.
getting user by id: 1 User(id=1, name=Vasya, email=vasya@mail.ru) getting user by id: 2 User(id=2, name=Vasya, email=vasya@mail.ru) deleting user by id: 1 deleting user by id: 2 User(id=1, name=Vasya, email=vasya@mail.ru) getting user by id: 2 javax.persistence.EntityNotFoundException: User not found by id 2
Nous voyons que l'application est passée en toute sécurité à la méthode get () et Spring a mis en cache ces entités. Ensuite, nous les avons supprimés par différentes méthodes. Nous avons supprimé le premier de la manière habituelle, et la valeur en cache est restée, donc lorsque nous avons essayé de placer l'utilisateur sous l'ID 1, nous avons réussi. Lorsque nous avons essayé d'obtenir l'utilisateur 2, la méthode a renvoyé une exception EntityNotFoundException - il n'y avait pas un tel utilisateur dans le cache.
5. Paramètres de regroupement. @Caching
Parfois, une seule méthode nécessite plusieurs paramètres de mise en cache. L'annotation @Caching est utilisée à ces fins. Cela peut ressembler à ceci:
@Caching( cacheable = { @Cacheable("users"), @Cacheable("contacts") }, put = { @CachePut("tables"), @CachePut("chairs"), @CachePut(value = "meals", key = "#user.email") }, evict = { @CacheEvict(value = "services", key = "#user.name") } ) void cacheExample(User user) { }
C'est le seul moyen de regrouper les annotations. Si vous essayez d'accumuler quelque chose comme
@CacheEvict("users") @CacheEvict("meals") @CacheEvict("contacts") @CacheEvict("tables") void cacheExample(User user) { }
alors IDEA vous dira que ce n'est pas le cas.
6. Configuration flexible. Cachemanager
Enfin, nous avons découvert le cache, et il a cessé d'être quelque chose d'incompréhensible et effrayant pour nous. Regardons maintenant sous le capot et voyons comment nous pouvons configurer la mise en cache en général.
Pour de telles tâches, il existe un CacheManager. Il existe où que se trouve Spring Cache. Lorsque nous avons ajouté l'annotation @EnableCache, un tel gestionnaire de cache sera automatiquement créé par Spring. Nous pouvons vérifier cela si nous enveloppons automatiquement ApplicationContext et l'ouvrons au point d'arrêt. Parmi les autres bacs, il y aura un bean cacheManager.
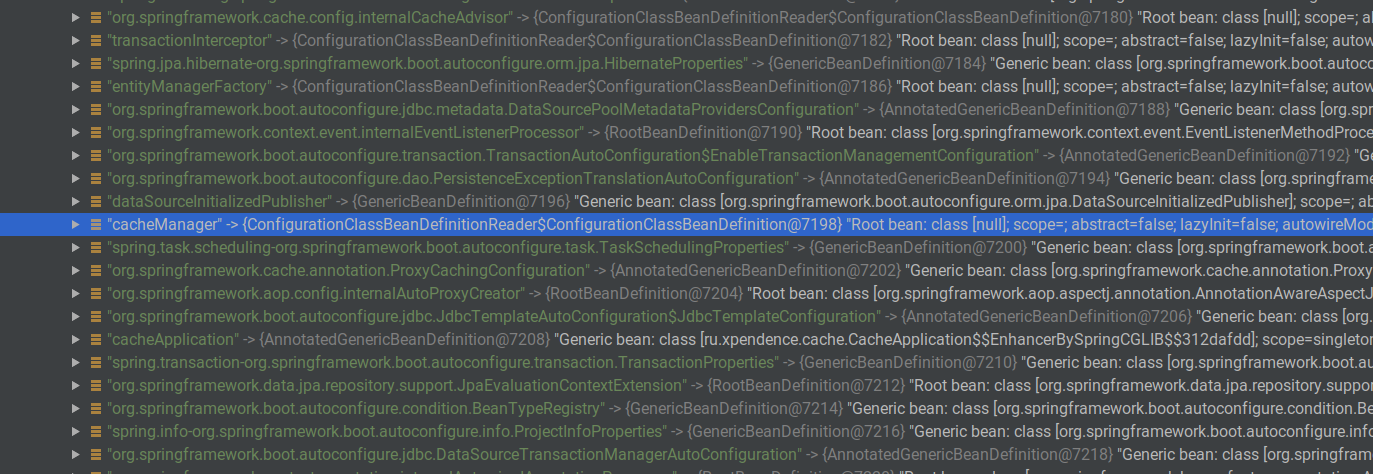
J'ai arrêté l'application au stade où deux utilisateurs avaient déjà été créés et placés dans le cache. Si nous appelons le bean dont nous avons besoin via Evaluate Expression, nous verrons qu'il existe vraiment un tel bean, il a un ConcurentMapCache avec la clé "users" et la valeur ConcurrentHashMap, qui contient déjà des utilisateurs en cache.

À notre tour, nous pouvons créer notre gestionnaire de cache, avec Habr et les programmeurs, puis le peaufiner à notre goût.
@Bean("habrCacheManager") public CacheManager cacheManager() { return null; }
Il ne reste plus qu'à choisir le gestionnaire de cache que nous utiliserons, car ils sont nombreux. Je ne listerai pas tous les gestionnaires de cache, il suffira de savoir qu'il y en a:
- SimpleCacheManager est le gestionnaire de cache le plus simple, pratique pour l'apprentissage et les tests.
- ConcurrentMapCacheManager - Initialise paresseusement les instances renvoyées pour chaque demande. Il est également recommandé pour tester et apprendre à travailler avec le cache, ainsi que pour certaines actions simples comme la nôtre. Pour un travail sérieux avec le cache, l'implémentation ci-dessous est recommandée.
- JCacheCacheManager , EhCacheCacheManager , CaffeineCacheManager sont de sérieux gestionnaires de cache «partenaires partenaires» qui sont personnalisables de manière flexible et effectuent des tâches d'un très large éventail d'actions.
Dans le cadre de mon humble article, je ne décrirai pas les gestionnaires de cache des trois derniers. Au lieu de cela, nous allons examiner plusieurs aspects de la configuration d'un gestionnaire de cache en utilisant ConcurrentMapCacheManager comme exemple.
Recréons donc notre gestionnaire de cache.
@Bean("habrCacheManager") public CacheManager cacheManager() { return new ConcurrentMapCacheManager(); }
Notre gestionnaire de cache est prêt.
7. Configuration du cache. Durée de vie, taille maximale, etc.
Pour ce faire, nous avons besoin d'une bibliothèque Google Guava assez populaire. J'ai pris le dernier.
compile group: 'com.google.guava', name: 'guava', version: '28.1-jre'
Lors de la création du gestionnaire de cache, nous redéfinissons la méthode createConcurrentMapCache, dans laquelle nous appellerons CacheBuilder depuis Guava. Dans le processus, il nous sera demandé de configurer le gestionnaire de cache en initialisant les méthodes suivantes:
- maximumSize - la taille maximale des valeurs que le cache peut contenir. En utilisant ce paramètre, vous pouvez trouver une tentative pour trouver un compromis entre la charge sur la base de données et la RAM JVM.
- refreshAfterWrite - durée après l'écriture de la valeur dans le cache, après quoi elle sera automatiquement mise à jour.
- expireAfterAccess - la durée de vie de la valeur après le dernier appel.
- expireAfterWrite - durée de vie de la valeur après l'écriture dans le cache. C'est le paramètre que nous allons définir.
et d'autres.
Nous définissons dans le gestionnaire la durée de vie de l'enregistrement. Afin de ne pas attendre longtemps, réglez 1 seconde.
@Bean("habrCacheManager") public CacheManager cacheManager() { return new ConcurrentMapCacheManager() { @Override protected Cache createConcurrentMapCache(String name) { return new ConcurrentMapCache( name, CacheBuilder.newBuilder() .expireAfterWrite(1, TimeUnit.SECONDS) .build().asMap(), false); } }; }
Nous écrivons un test correspondant à ce cas.
@Test public void checkSettings() throws InterruptedException { User user1 = service.createOrReturnCached(new User("Vasya", "vasya@mail.ru")); log.info("{}", service.get(user1.getId())); User user2 = service.createOrReturnCached(new User("Vasya", "vasya@mail.ru")); log.info("{}", service.get(user2.getId())); Thread.sleep(1000L); User user3 = service.createOrReturnCached(new User("Vasya", "vasya@mail.ru")); log.info("{}", service.get(user3.getId())); }
Nous enregistrons plusieurs valeurs dans la base de données et si les données sont mises en cache, nous n'enregistrons rien. Tout d'abord, nous enregistrons deux valeurs, puis nous attendons 1 seconde jusqu'à ce que le cache disparaisse, après quoi nous enregistrons une autre valeur.
creating user: User(id=null, name=Vasya, email=vasya@mail.ru) getting user by id: 1 User(id=1, name=Vasya, email=vasya@mail.ru) User(id=1, name=Vasya, email=vasya@mail.ru) creating user: User(id=null, name=Vasya, email=vasya@mail.ru) getting user by id: 2 User(id=2, name=Vasya, email=vasya@mail.ru)
Les journaux montrent que nous avons d'abord créé un utilisateur, puis nous en avons essayé un autre, mais comme les données ont été mises en cache, nous les avons obtenues du cache (dans les deux cas, lors de l'enregistrement et lors de la récupération de la base de données). Ensuite, le cache a mal tourné, car un enregistrement nous parle de la sauvegarde réelle et de la réception réelle de l'utilisateur.
8. Pour résumer
Tôt ou tard, le développeur est confronté à la nécessité d'implémenter la mise en cache dans le projet. J'espère que cet article vous aidera à comprendre le sujet et à examiner les problèmes de mise en cache avec plus d'audace.
Github du projet ici:
https://github.com/promoscow/cache