Dans un
article précédent, nous avons parlé d'essayer d'utiliser Watcher et présenté un rapport de test. Nous effectuons périodiquement de tels tests pour équilibrer et d'autres fonctions critiques d'un grand cloud d'entreprise ou d'opérateur.
La grande complexité du problème résolu peut nécessiter plusieurs articles pour décrire notre projet. Aujourd'hui, nous publions le deuxième article de la série sur l'équilibrage des machines virtuelles dans le cloud.
Quelques terminologies
VmWare a introduit l'utilitaire DRS (Distributed Resource Scheduler) pour équilibrer la charge de leur environnement de virtualisation.
Comme l'écrit
searchvmware.techtarget.com/definition/VMware-DRS«VMware DRS (Distributed Resource Scheduler) est un utilitaire qui équilibre la charge de calcul avec les ressources disponibles dans un environnement virtuel. L'utilitaire fait partie d'un package de virtualisation appelé VMware Infrastructure.
À l'aide de VMware DRS, les utilisateurs définissent les règles de distribution des ressources physiques entre les machines virtuelles (VM). L'utilitaire peut être configuré pour un contrôle manuel ou automatique. Les pools de ressources VMware peuvent être facilement ajoutés, supprimés ou réorganisés. Si vous le souhaitez, les pools de ressources peuvent être isolés entre différentes unités commerciales. Si la charge de travail d'une ou plusieurs machines virtuelles change considérablement, VMware DRS redistribue les machines virtuelles entre les serveurs physiques. Si la charge de travail globale est réduite, certains serveurs physiques peuvent être temporairement hors service et la charge de travail consolidée. »Pourquoi ai-je besoin d'équilibrage?
À notre avis, le DRS est une caractéristique indispensable du cloud, bien que cela ne signifie pas que le DRS doit être utilisé toujours et partout. Selon le but et les besoins du cloud, il peut y avoir des exigences différentes pour le DRS et les méthodes d'équilibrage. Il y a peut-être des situations où l'équilibre n'est pas du tout nécessaire. Ou même dangereux.
Pour mieux comprendre où et pour quels clients DRS sont nécessaires, tenez compte de leurs buts et objectifs. Les nuages peuvent être divisés en publics et privés. Voici les principales différences entre ces nuages et les objectifs des clients.
Nous tirons les conclusions suivantes pour nous-mêmes:
Pour les clouds privés fournis aux grandes entreprises, le DRS peut être appliqué sous réserve de restrictions:
- les règles de sécurité de l'information et d'affinité comptable pour l'équilibrage;
- la disponibilité d'une quantité suffisante de ressources en cas d'accident;
- les données de la machine virtuelle résident sur un système de stockage centralisé ou distribué;
- diversité temporelle des procédures d'administration, de sauvegarde et d'équilibrage;
- équilibrage uniquement dans l'ensemble des hôtes clients;
- équilibrer uniquement avec un fort déséquilibre, la migration la plus efficace et la plus sûre des machines virtuelles (après tout, la migration peut échouer);
- équilibrer des machines virtuelles relativement «silencieuses» (la migration de machines virtuelles «bruyantes» peut prendre très longtemps);
- équilibrage en tenant compte du «coût» - la charge sur le système de stockage et le réseau (avec des architectures personnalisées pour les gros clients);
- équilibrage en tenant compte du comportement individuel de chaque VM;
- l'équilibrage est souhaitable après les heures (nuit, week-end, vacances).
Pour les clouds publics qui fournissent des services aux petits clients, le DRS peut être utilisé beaucoup plus souvent, avec des fonctionnalités avancées:
- absence de restrictions de sécurité de l'information et de règles d'affinité;
- équilibrage dans le cloud;
- équilibrer à tout moment raisonnable;
- équilibrer n'importe quelle machine virtuelle;
- équilibrer les machines virtuelles «bruyantes» (pour ne pas interférer avec le reste);
- les données de la machine virtuelle se trouvent souvent sur des disques locaux;
- prise en compte des performances moyennes de stockage et de réseau (l'architecture cloud est unifiée);
- équilibrage selon des règles généralisées et des statistiques disponibles sur le comportement du centre de données.
Complexité du problème
La difficulté d'équilibrer est que le DRS doit fonctionner avec beaucoup de facteurs incertains:
- comportement des utilisateurs de chacun des systèmes d'information client;
- algorithmes pour le fonctionnement des serveurs de systèmes d'information;
- Comportement du serveur SGBD
- charge sur les ressources informatiques, le stockage, le réseau;
- l'interaction des serveurs entre eux dans la lutte pour les ressources cloud.
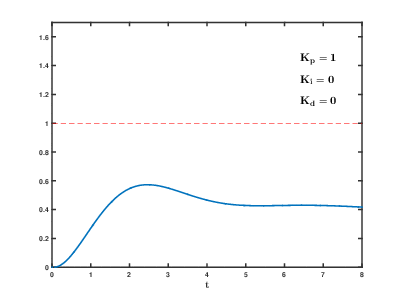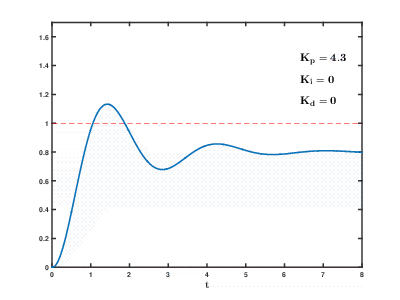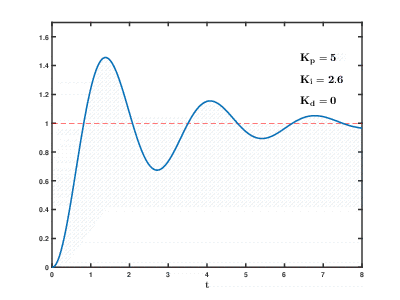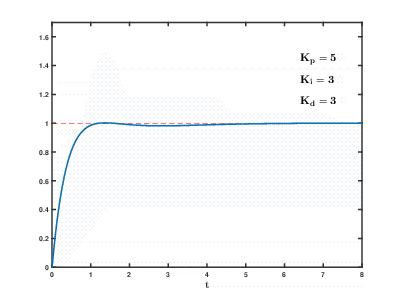
La charge d'un grand nombre de serveurs d'applications virtuelles et de bases de données sur les ressources cloud se produit au fil du temps, les conséquences peuvent se produire et se chevaucher avec des effets imprévisibles après des temps imprévisibles. Même pour contrôler des processus relativement simples (par exemple, pour contrôler un moteur, un système de chauffage de l'eau à la maison), les systèmes de contrôle automatique doivent utiliser des algorithmes de rétroaction de
différenciation proportionnelle-intégrale complexes.

Notre tâche est beaucoup plus compliquée, et il existe un risque que le système ne puisse pas équilibrer la charge aux valeurs établies dans un délai raisonnable, même si les influences externes des utilisateurs ne se produisent pas.
Histoire de nos développements
Pour résoudre ce problème, nous avons décidé de ne pas repartir de zéro, mais de tirer parti de l'expérience existante et avons commencé à interagir avec des spécialistes qui ont de l'expérience dans ce domaine. Heureusement, notre compréhension des problèmes coïncidait complètement.
Étape 1
Nous avons utilisé un système basé sur la technologie des réseaux de neurones et avons essayé d'optimiser nos ressources sur cette base.
L'intérêt de cette étape était de tester la nouvelle technologie, et son importance était d'appliquer une approche non standard pour résoudre le problème où, toutes choses étant égales par ailleurs, les approches standard se sont pratiquement épuisées.
Nous avons démarré le système et nous sommes vraiment allés en équilibre. L'ampleur de notre cloud ne nous a pas permis d'obtenir des résultats optimistes annoncés par les développeurs, mais il était clair que l'équilibrage fonctionnait.
De plus, nous avions des limitations assez sérieuses:
- Pour former un réseau neuronal, les machines virtuelles doivent fonctionner sans changements importants pendant des semaines ou des mois.
- L'algorithme est conçu pour une optimisation basée sur l'analyse de données "historiques" antérieures.
- Pour former un réseau de neurones, une quantité suffisante de données et de ressources informatiques est nécessaire.
- L'optimisation et l'équilibrage peuvent être effectués relativement rarement - une fois toutes les quelques heures, ce qui n'est clairement pas suffisant.
Étape 2
Comme nous n'étions pas satisfaits de la situation, nous avons décidé de modifier le système, et pour cela de répondre à la
question principale - pour qui le faisons-nous?
D'abord pour les entreprises. Nous avons donc besoin d'un système qui fonctionne efficacement, avec ces restrictions d'entreprise qui ne font que simplifier la mise en œuvre.
La deuxième question est de
savoir ce que signifie le mot «opérationnel»? À la suite d'un court débat, nous avons décidé qu'il était possible de s'appuyer sur le temps de réponse de 5 à 10 minutes pour que les sauts à court terme n'introduisent pas le système en résonance.
La troisième question est quelle taille du nombre équilibré de serveurs choisir?
Cette question a été décidée d'elle-même. En règle générale, les clients ne rendent pas les agrégats de serveurs très volumineux, ce qui est conforme aux recommandations de l'article pour limiter les agrégats à 30 à 40 serveurs.
De plus, en segmentant le pool de serveurs, nous simplifions la tâche de l'algorithme d'équilibrage.
La quatrième question est de savoir à quel point un réseau de neurones nous convient avec son long processus d'apprentissage et son équilibre rare? Nous avons décidé de l'abandonner au profit d'algorithmes opérationnels plus simples afin d'obtenir le résultat en quelques secondes.
Une description du système utilisant de tels algorithmes et de ses défauts peut être trouvée
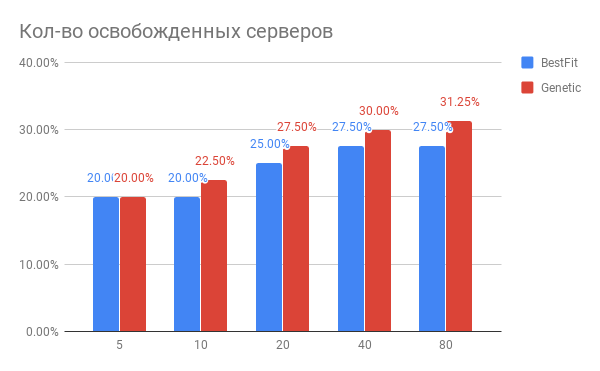
ici.Nous avons implémenté et lancé ce système et obtenu des résultats encourageants.Il analyse désormais régulièrement la charge du cloud et donne des recommandations sur le déplacement des machines virtuelles, qui sont largement correctes. Même maintenant, il est clair que nous pouvons obtenir une libération de 10 à 15% des ressources pour les nouvelles machines virtuelles avec une amélioration de la qualité des machines existantes.

Lorsqu'un déséquilibre est détecté par la RAM ou le CPU, le système donne des commandes au planificateur Tionics pour effectuer une migration en direct des machines virtuelles requises. Comme le montre le système de surveillance, la machine virtuelle est passée d'un hôte (supérieur) à un autre (inférieur) et a libéré de la mémoire sur l'hôte supérieur (surligné en cercles jaunes), l'occupant respectivement sur l'hôte inférieur (surligné en cercles blancs).
Maintenant, nous essayons d'évaluer plus précisément l'efficacité de l'algorithme actuel et essayons de trouver d'éventuelles erreurs dans celui-ci.
Étape 3
Il semblerait que vous puissiez vous calmer là-dessus, attendre une efficacité prouvée et clore le sujet.
Mais les opportunités d'optimisation évidentes suivantes nous poussent à mener une nouvelle phase.
- Les statistiques, par exemple, ici et ici, montrent que les performances des systèmes à deux et à quatre processeurs sont nettement inférieures à celles des monoprocesseurs. Cela signifie que tous les utilisateurs reçoivent des rendements nettement inférieurs des CPU, RAM, SSD, LAN, FC achetés dans des systèmes multiprocesseurs par rapport à ceux à processeur unique.
- Les planificateurs de ressources eux-mêmes peuvent travailler avec de graves erreurs, voici l'un des articles sur ce sujet.
- Les technologies offertes par Intel et AMD pour surveiller la RAM et le cache permettent d'étudier le comportement des machines virtuelles et de les placer de telle manière que les voisins bruyants n'interfèrent pas avec les machines virtuelles silencieuses.
- Extension de l'ensemble des paramètres (réseau, stockage, priorité de la machine virtuelle, coût de la migration, sa préparation à la migration).
Total
Le résultat de nos travaux sur l'amélioration des algorithmes d'équilibrage a permis de conclure sans ambiguïté qu'en raison des algorithmes modernes, il est possible d'obtenir une optimisation significative des ressources (25-30%) des centres de données et d'améliorer la qualité du service client.
L'algorithme basé sur les réseaux de neurones est, bien sûr, une solution intéressante qui a besoin d'être développée, et en raison des restrictions existantes, il ne convient pas pour résoudre de tels problèmes sur des volumes caractéristiques des nuages privés. Dans le même temps, dans des clouds publics de taille significative, l'algorithme a montré de bons résultats.
Nous vous en dirons plus sur les capacités des processeurs, des planificateurs et de l'équilibrage de haut niveau dans les articles suivants.