
Je suis chef d'équipe et ma tâche est d'assurer le travail productif de l'équipe. Ce n'est pas facile, car il n'y a pas de recette toute faite pour réussir. Bien sûr, il existe des méthodologies reconnues:
Agile ,
Lean ,
Value Stream Mapping . Ils donnent des lignes directrices et des valeurs communes, ce qui est déjà bon, mais ce ne sont que des lignes directrices. Et avec des solutions spécifiques, soyez gentils, tournez-vous. C'est pourquoi vous et le chef d'équipe.
Dans l'article, je dirai comment l'équipe et moi nous sommes progressivement formés et affinons maintenant régulièrement l'approche d'un travail efficace. Le point clé est que les outils sélectionnés sont réellement acceptés par toute l'équipe et ont pris racine dans le travail. Cela donne l'espoir que l'approche est utile.
Un peu de contexte
Chez True Engineering, nous sommes engagés dans le développement d'entreprise. Nous fabriquons un énorme produit pluriannuel auquel participent de nombreuses équipes. Plus précisément, notre équipe est composée de sept personnes: quatre développeurs, un chef d'équipe technique (écrit du code et beaucoup), un QA, un PM. Le produit sur lequel l'équipe travaille a deux ans. La condition technique - par les efforts de toute l'équipe - est presque exemplaire.
L'inconfort comme outil de diagnostic
Pour trouver et reconnaître les problèmes dans l'équipe, nous utilisons un outil assez simple - l'inconfort des participants.
Bien sûr, cela ne concerne pas une situation où une personne est climatisée et une autre est chaude. Je parle d'échecs dans le déroulement normal du travail.
Par exemple, la version a été tordue, bien que chacun ait bien fait son travail individuellement. Ou la stabilisation est en cours depuis deux semaines et l'équipe se déchire, même si nous avons nous-mêmes fait des estimations et que personne ne nous a dérangés pour bien faire. Ou l'entreprise n'a pas obtenu ce qu'elle attendait.
Comment agir dans une situation similaire:
- Arrêtez la panique et réalisez pourquoi nous sommes mal à l'aise en ce moment.
- Allez au fond de la cause profonde. Par exemple, en utilisant la technique Five Why ou tout simplement le bon sens.
- Décidez comment traiter le problème. Les lignes directrices pour choisir la bonne solution seront discutées à la fin de l'article. Ici, je note un point fondamentalement important: nous utilisons l'inconfort pour diagnostiquer les problèmes, mais cela ne signifie pas que la ligne directrice pour le choix des solutions est d'atteindre le confort. N'oubliez pas que la principale raison pour laquelle vous existez en équipe est la valeur commerciale. Personne n'a besoin d'une équipe heureuse qui n'apporte pas de résultats.
- Après un certain temps, réalisez une rétrospective. Si la décision n'a pas aidé, nous revenons au paragraphe 1 avec une nouvelle compréhension. Si cela peut aider, nous automatisons ou ajoutons à la liste de principes pour les futurs débutants. Aucun contrôle n'est plus nécessaire, les participants eux-mêmes adopteront l'approche du travail si c'est vraiment bon.
L'algorithme décrit est simple, mais les détails ne suffisent pas. Ensuite, je décrirai les principes que nous avons déduits en utilisant cette approche. Pour que l'article ne se transforme pas en mémoire, je ne décrirai que le résultat obtenu, et non toute l'histoire depuis la prise de conscience de la douleur jusqu'à son élimination.
Les principes sur lesquels nous construisons le processus
1. Nous créons et raccourcissons constamment les boucles de rétroaction
Toute interaction humaine avec le monde extérieur est construite sur la rétroaction, sans laquelle il est impossible de vérifier l'exactitude de l'action effectuée. Imaginez ce que serait notre vie si nous ne ressentions pas de douleur en sautant d'une hauteur de quatre mètres ou en attrapant une théière chauffée au rouge.
En cours de développement, la complétion de code peut servir d'exemple d'une bonne boucle de rétroaction courte - elle nous renseigne sur l'exactitude de l'action juste au moment de la saisie du code.
Maintenant, un exemple de l'absence d'une boucle de rétroaction: nous connaissons le problème avec les utilisateurs, mais nous ne pouvons pas le reproduire, nous n'avons pas de journaux, il n'y a aucun moyen de déployer rapidement le correctif et nous ne savons même pas quelle version est actuellement sur le prod. Vous ne souhaiterez pas l'ennemi.
Chaque action dans le processus de développement peut et doit donner un retour: construction, peluches, auto-tests réussis, tests effectués, une session de test avec l'entreprise, déploiement réussi, surveillance de la production - tous ces moyens sont pour détecter les erreurs et ajuster leurs autres actions.
Il convient également de noter que le coût des erreurs augmente à mesure que vous avancez. Si nous avons publié un bug de production sur la production qui gâche les données, alors la tâche n'est pas seulement de le corriger, mais aussi de restaurer les données (si possible). Le coût de l'élimination tardive d'une telle erreur est très élevé, sans parler des conséquences pour l'entreprise.
Par conséquent, la présence d'un grand nombre de boucles de rétroaction rapides et informatives est vitale.
Vous trouverez ci-dessous les boucles que nous soutenons consciemment et raccourcissons si possible. Je suppose que la plupart d'entre vous le savent. Mais les avez-vous vraiment et travaillez-vous?
- La possibilité d'exécuter et d'exécuter un projet localement.
- Conçu pour échouer rapidement .
- Construction CI rapide et informative.
- Révision constante du code et utilisation du code via des demandes d'extraction.
- Disponibilité des autotests. Les tests sont des messages d'erreur rapides, stables et informatifs.
- Déploiement automatique, car le manuel sera effectué moins fréquemment.
- Versions fréquentes au lieu d'accumuler et de publier une version une semaine après avoir terminé les tâches.
- Journaux informatifs, surveillance, outils de diagnostic. Accédez à eux depuis toute l'équipe.
- La possibilité de filtrer et de visualiser graphiquement les journaux.
- Surveillance continue des indicateurs techniques et fonctionnels du système dans le cadre du travail quotidien.
- Etude empirique du système - Google Analytics, analyse des données accumulées dans le système.
- Le stockage de l'historique des modifications des données au lieu de l'état final, le cas échéant.
- Travail serré et conjoint de Dev, Ops, QA, business au lieu de «jeter par-dessus la clôture» des résultats de l'étape précédente.
- Mener des rétrospectives régulières à la fois au sein de l'équipe et avec l'entreprise.
- Rétroaction régulière de l'entreprise. Encore mieux, les commentaires de l'utilisateur final.
- La capacité d'observer le travail des utilisateurs "sur le terrain".
- La possibilité d'observer l'utilisateur qui voit votre système pour la première fois.
En général, la rétroaction elle-même doit être accrocheuse. Comme, par exemple, une version cassée.
Ce qui est remarquable, parfois un très petit changement suffit pour une amélioration radicale.
Par exemple, vous écrivez des journaux dans
ELK . Ils sont structurés, analysés, accessibles au public - tout va bien. Mais à quelle fréquence le développeur passe-t-il pendant le débogage? Probablement pas.
Si des messages de niveau d'avertissement et supérieur sont affichés directement dans l'EDI, il y a une chance de remarquer, par exemple, un temps d'exécution de requête affaissé. Même s'il n'est pas lié à la tâche en cours. Il est possible de remarquer le problème plus tôt et le coût de sa résolution sera plus faible.
2. Toute activité laisse des artefacts publics
Les artefacts doivent être exactement publics. Et utile.
Grâce à ce principe, nous minimisons le
facteur bus , fournissons une compréhension unifiée de la situation, travaillons (et fakapim) consciemment, en tirant constamment des conclusions.
Certaines pratiques sont évidentes et généralement acceptées: messages informatifs des validations, connexion des validations avec les tâches, description du test, définition de Terminé.
Il y a des points moins évidents:
- Vous ne pouvez pas "tout bousiller", l'échec doit être réalisé. Si l'analyse révèle des exigences mal pensées, le raffinement délibéré deviendra un artefact pour tous. Si le problème est dans l'architecture du système, l'artefact sera le devoir technique décrit avec un terme clair pour la mise en service.
- La quantité de connaissances dans le courrier, les messageries instantanées, les têtes devrait être minimale. Toutes les améliorations sont reflétées dans la base de connaissances ou dans le traqueur de tâches. Ainsi, lorsque le testeur accepte la tâche, les nouvelles exigences pour lui ne seront plus d'actualité. Lorsqu'une entreprise accepte un résultat, tout le monde comprend ce qu'elle doit obtenir. Cet état transforme le travail en un flux continu. Fournissez-le (découvrez les détails, mettez à jour la base de connaissances et la description des tâches) - la tâche de chaque participant au processus.
- Les résultats du test ne sont pas seulement «J'ai vérifié, tout va bien», mais une liste accessible au public des cas de test réussis, qui a été compilée et discutée avant le test, et non pendant ou après. La liste peut être étudiée et complétée par chaque participant au processus.
3. Nous respectons mutuellement le droit à un travail concentré
L'importance du travail
dans le cours d'eau et les
conséquences de l'interruption , je crois, sont déjà bien connues. Par conséquent, je ne m'attarderai pas sur le problème en détail, mais je me tournerai immédiatement vers nos pratiques.
- Les écouteurs sont uniquement encouragés.
- La communication de travail est asynchrone. Ne distrayez pas votre collègue avec une petite question, posez-le dans le tracker de tâches (voir la section sur les artefacts accessibles au public).
- Parfois, il arrive des choses qui interrompent le mode de fonctionnement normal: un accident à la prod, des exigences incompréhensibles pour une tâche déjà mise en œuvre. Un signal peut être une discussion bruyante au bureau, à laquelle participent trois personnes ou plus. Si cette situation n'est pas résolue en quelques minutes, je nommerai une personne pour clarifier les détails. Le reste reprendra son fonctionnement normal jusqu'à ce que la personne responsable fournisse des informations pour une analyse plus approfondie.
4. Nous évitons le multitâche
Parce que le
multitâche ne fonctionne pas . Elle épuise seulement, pulvérise l'attention et reporte la réception du résultat.
Quelles pratiques aident:
- Limite de travaux en cours .
- Se concentrer sur le flux de valeur, pas sur les ressources. Par exemple, le premier développeur peut effectuer la tâche en une journée et le second en trois. Mais le premier ne sortira qu'après une semaine. Ainsi, le second prend la tâche au travail. Nous consacrerons plus de temps à la mise en œuvre, mais nous livrerons le résultat plus rapidement (trois jours au lieu d'une semaine et un jour) et passerons à la tâche suivante. Dans le même temps, nous n'essayons pas de «pousser le non-poussable» vers le premier développeur et ne sommes pas distraits par un travail «suspendu» dans son attente.
- Si plusieurs personnes sont impliquées dans une tâche et que le travail est terminé à 90%, alors l'objectif numéro un de l'équipe est de tout faire pour terminer les 10% restants. Ce n'est qu'après cela que nous continuons.
5. Nous prenons les décisions architecturales le plus tard possible
Ce n'est pas notre savoir-faire, mais l'
un des principes de base du lean manufacturing .
La décision prise et mise en œuvre limite la possibilité de nouveaux changements. Et si la décision est prise dans des conditions d'informations incomplètes (et c'est presque toujours le cas), les chances de prendre une mauvaise décision sont considérablement plus élevées.
Si le fait de ne pas prendre de décision ne bloque pas le travail et n'entraîne pas une croissance exponentielle de la dette technique, elle doit être reportée, laissant le système prêt pour toute décision future, lorsque nous disposerons de plus d'informations.
C'est la base du développement - nous ne construisons pas de «grandes» architectures avant le début du projet. Au lieu de cela, nous sécurisons le processus de refactoring (voir la section sur les boucles de rétroaction) et le transformons en une partie naturelle du processus.
De même, nous n'essayons pas de deviner les futures exigences du système ou de construire une solution universelle. La capacité de refactoriser en toute sécurité est plus universelle car elle permet d'apporter des modifications à l'avenir.
6. Le code est opérationnel à tout moment.
Bien sûr, cet état est inaccessible dans l'absolu, le système tombera périodiquement en panne après avoir effectué des modifications. Mais cela ne signifie pas que cette caractéristique ne doit pas être recherchée.
Lorsqu'une panne est une situation anormale et non une norme de vie, ses causes sont faciles à trouver. Il s'agit généralement du dernier commit. Par conséquent, la personne responsable est compréhensible, les étapes pour éliminer sont compréhensibles, il est clair lorsque nous retournons à un état stable.
La confiance qui en résulte dans le fonctionnement du système offre une occasion précieuse de se libérer à tout moment.
La deuxième valeur est que nous sommes plus confiants pour faire des promesses de disponibilité. Si nous divisons le travail en deux phases: «développement» et «stabilisation», il est difficile de donner une promesse concrète, car la «stabilisation» est un travail avec des problèmes que nous ne connaissons pas encore. Par conséquent, nous ne pouvons pas les évaluer avec précision.
Si la stabilisation va inextricablement avec le développement et qu'il y a tous les outils nécessaires pour cela, alors la situation est plus prévisible.
Comment nous maintenons une performance continue:
- Évident: révision de code, autotests, indicateurs de fonctionnalité.
- Toutes les modifications sont immédiatement déployées dans l'environnement de test. S'il est cassé, vous ne pourrez pas le réparer plus tard - le contrôle qualité est bloqué.
- Tester dans un flux continu immédiatement après la fin des tâches, tandis que le développeur se souvient de la tâche et du code et apporte rapidement des corrections.
- Nous ne faisons pas le travail en plusieurs parties. Si deux personnes sont nécessaires pour l'implémentation, alors elles travaillent par paires, dans une même branche, téléchargent le code dans la branche principale lorsqu'il est complètement prêt et couvert par des tests.
- Automatisation de la livraison et artefacts de livraison fixes qui n'ont pas besoin d'être «finis» manuellement.
- Chaque membre de l'équipe connaît les outils de diagnostic, sait comment travailler avec eux et sait comment effectuer des versions.
7. Nous sommes une équipe, pas un groupe de développement.
Que signifie «équipe»:
- Tout le code est examiné par au moins une personne. Si un problème grave est découvert, ils sont encouragés à s'asseoir ensemble et à faire de la programmation en binôme. Partager un livre, un article, une explication détaillée au lieu de diffuser des opinions personnelles n'a pas de prix.
- Au lieu de développer en morceaux avec une intégration ultérieure douloureuse du résultat, nous travaillons étroitement par paires lorsque cela est nécessaire.
- Nous ne transformons pas le réviseur en un outil pour vérifier les fautes de frappe, nous apportons une demande propre, petite et tirée à la révision.
- Nous ne jetons pas de tâches «à travers la clôture», mais nous remettons soigneusement le travail d'AQ, en vérifiant vous-même le chemin heureux. Nous aidons QA à comprendre quoi et comment tester, nous aidons à passer des scénarios de frontière (par exemple, briser artificiellement le système).
- QA, à son tour, étudie la structure interne du système, sait comment collecter tous les détails nécessaires (journaux, état des données) et obtenir un bug extrêmement informatif.
8. Nous hachons la queue
Afin de maximiser l'efficacité et la concentration des travaux en cours, nous éliminons les «dettes» liées aux travaux déjà effectués:
- Les tâches sont mises en vente le plus rapidement possible. Ce n'est qu'après cela que nous les considérons comme terminés.
- Nous éliminons constamment la dette technique afin qu'elle n'augmente pas au coût élevé de la réparation (une semaine) et ne bloque pas le travail, ruinant les plans de livraison de la fonctionnalité commerciale.
- Nous ne commençons pas les tâches que nous effectuerons «un jour», mais nous supprimons les tâches de longue durée. Une entreprise viendra certainement pour une tâche quand (si) le moment sera venu de le faire. Et juste au cas où, dans le tracker de tâches, vous pouvez restaurer la tâche supprimée. Mais cette fonction ne nous a jamais été utile.
- Branches de longue durée, code commenté, To-do-shki - tout cela est un code mort, dont la place est dans le panier.
- Les tests instables sont immédiatement corrigés ou supprimés et remplacés par des tests inférieurs.
- Nous suivons les tâches "rampantes".
Le dernier point mérite une explication distincte.
Je veux dire des tâches «rampantes» avec des coûts de main-d'œuvre initialement faibles, mais suspendues en cours pendant plusieurs jours ou semaines.
Pourquoi cela peut-il être:
- La tâche était initialement mal conçue, elle nécessitait déjà beaucoup de raffinements, les clarifications sont contradictoires ou incomplètes. Donc, nous arrêtons de perdre du temps, arrêtons de travailler sur la tâche et revenons à la déclaration.
- La tâche est dans un état d'attente d'un résultat de la part de quelqu'un. Par exemple, un service d'une autre équipe ou un raffinement d'une entreprise. Nous gardons de telles tâches sur un crayon et ne les laissons pas aller seules.
Il est difficile de se conformer à ce point. Tout d'abord, le «fluage» doit être réalisé. Ensuite, vous devez prendre une décision ferme et revenir en arrière dans le détail. C'est difficile pour le développeur car le temps a déjà été dépensé. Et bien sûr, une telle décision rencontrera la résistance de l'entreprise. Mais la pratique montre que cela réduit les chances de produire un résultat dont ni l'équipe, ni l'entreprise, ni les utilisateurs ne seront satisfaits.
Le graphique du temps de cycle aide à rechercher de telles tâches. Il montre le temps entre le moment de la mise au travail et l'achèvement. Si la tâche est «hors de la foule», alors c'est un candidat pour un examen attentif.
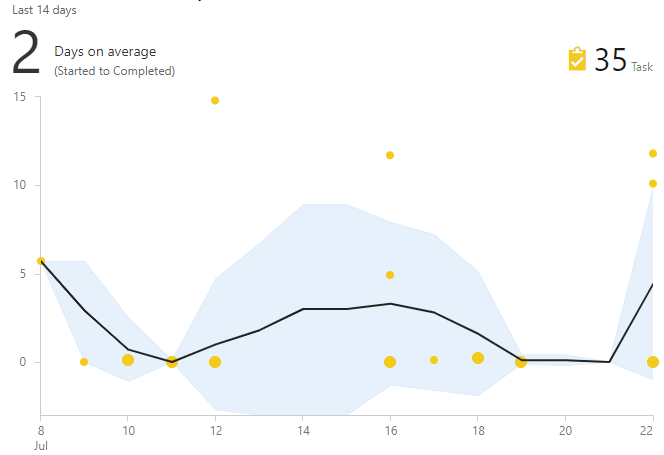
Comment choisir des solutions utiles
Malheureusement, je n'ai pas de recette prête à l'emploi. L'efficacité de l'équipe est une tâche heuristique, ce qui signifie qu'elle n'a pas de solutions garanties.
Mais il y a encore une liste de contrôle. Le voici:
- J'ai écrit à ce sujet au début de l'article et je le répète ici: le fait que nous utilisons l'inconfort pour diagnostiquer les problèmes ne signifie pas que nous nous efforçons d'être à l'aise pour prendre des décisions. N'oubliez pas l'objectif principal - augmenter la valeur pour l'entreprise.
- Lors de l'analyse des problèmes, n'oubliez pas que tous les participants ont de bonnes intentions . Si votre pensée est basée sur une croyance paranoïaque que quelqu'un vous fait du mal intentionnellement, alors prendre une bonne décision est très difficile.
- N'essayez pas de tout casser et de reconstruire. Déplacez-vous par petites étapes, en apportant des changements progressivement. Attendez que les modifications apportées donnent des résultats, puis introduisez-en de nouvelles.
- S'il n'y a pas de solution claire, avancez par petites étapes, évaluez constamment le résultat et essayez différentes options. Une boucle de rétroaction claire et une réflexion constante sont un outil de développement inépuisable pour vous et l'équipe.
- Forgez le fer pendant qu'il est chaud. Ne retardez pas l'analyse avant la rétrospective - l'équipe oubliera déjà ce qui se passait. Il vaut mieux en venir à une rétrospective avec un problème déjà reconnu et des solutions toutes faites qui restent à peser avec l'équipe et à choisir la meilleure.
- La décision doit être prise par toute l'équipe. Aucune plantation d'en haut ne fonctionnera et les tentatives de contrôle ne sont qu'une illusion.
- Ne pas inculquer aux gens des tâches atypiques pour leurs activités quotidiennes. Vous rencontrerez mille explications plausibles pour lesquelles la promesse n'a pas été faite, mais vous n'obtiendrez pas le résultat.
- L'effet de la décision doit être tangible. Vous réussirez rarement à formuler une décision sur les caractéristiques de SMART , mais une manière consciente d'évaluer le résultat doit exister. Au moins sur la base de "maintenant cela se produit moins souvent".
- Essayez d'enregistrer régulièrement ce qui fait le plus mal maintenant. Si après six mois, vous relisez les enregistrements avec le sourire en pensant «il y avait une boîte», alors vous êtes sur la bonne voie.
Conclusion
En conclusion, discutons des faiblesses de l'approche.
Tout d'abord, cette approche fonctionne pour rechercher des optimisations locales; il n'est pas possible de construire avec lui une stratégie de développement du produit et de l'ensemble de l'entreprise. Bien sûr, la prise de conscience des problèmes est meilleure que la merde et la brûlure inconscientes au travail, mais ce n'est que la première étape.
Je vous demande aussi, ne prenez pas une liste de principes toute faite, prenez l'outil avec lequel elle a été créée. Voici pourquoi:
Notre liste n'est pas complète. Il ne contient que ce que nous avons déjà mis en œuvre dans notre travail quotidien.
L'équipe ne prend pas de principes fondamentaux, dont elle ne s'est pas rendu compte, par la douleur de leur absence. Au lieu d'idées de travail, vous obtiendrez un croque-mitaine que tout le monde transportera au bureau pendant un certain temps, puis mettra de la poussière dans un coin.
Notre liste est spécifique. Par exemple, si la dette technique du projet est ignorée depuis cinq ans et comparable à la dette publique américaine, il sera alors très difficile de bénéficier du principe d'extermination constante de la dette technique. Il est juste de l'admettre: une dette de cette taille ne sera jamais remboursée. Et concentrez-vous sur des solutions qui contribuent vraiment à améliorer la situation.
Comment améliorez-vous le processus? Et quels principes avez-vous déjà adoptés dans votre travail?