Ces dernières années,
la traduction automatique neuronale (NMP) utilisant les modèles "transformateurs" a connu un succès extraordinaire. Les IMF basées sur des réseaux de neurones profonds sont généralement formées du début à la fin dans des cas parallèles très volumineux de textes (paires de textes) uniquement sur la base des données elles-mêmes, sans qu'il soit nécessaire d'attribuer des règles linguistiques précises.
Malgré tous les succès, les modèles NMP peuvent être sensibles aux petits changements dans les données d'entrée, qui peuvent se manifester sous la forme de diverses erreurs - sous-traduction, sur-traduction, traduction incorrecte. Par exemple, la prochaine proposition allemande, le «transformateur» de modèle NMP de haute qualité se traduira correctement.
"Der Sprecher des Untersuchungsausschusses hat angekündigt, vor Gericht zu ziehen, falls sich die geladenen Zeugen weiterhin weigern sollten, eine Aussage zu machen."
(Traduction automatique: «Le porte-parole de la commission d'enquête a annoncé que si les témoins cités continuent de refuser de témoigner, il serait traduit en justice.»)
Traduction: un représentant du comité d'enquête a annoncé que si les témoins invités continuent de refuser de témoigner, il sera tenu responsable.
Cependant, lorsque vous apportez une petite modification à la phrase entrante, en remplaçant le mot geladenen par le synonyme vorgeladenen, la traduction change considérablement (et devient incorrecte):
"Der Sprecher des Untersuchungsausschusses hat angekündigt, vor Gericht zu ziehen, falls sich die vorgeladenen Zeugen weiterhin weigern sollten, eine Aussage zu machen."
(Traduction automatique: «Le comité d'enquête a annoncé qu'il serait traduit en justice si les témoins invités continuent de refuser de témoigner.»).
Traduction: le comité d'enquête a annoncé qu'il serait traduit en justice si des témoins invités continuaient de refuser de témoigner.
Le manque de stabilité des modèles NMP ne permet pas d'appliquer des systèmes commerciaux à des tâches dans lesquelles un niveau similaire d'instabilité est inacceptable. Par conséquent, la disponibilité de l'apprentissage de modèles de traduction durables n'est pas seulement souhaitable, mais souvent nécessaire. Dans le même temps, bien que la stabilité des réseaux de neurones soit activement étudiée par une communauté de chercheurs en vision par ordinateur, il existe peu de matériel sur les modèles NMP d'apprentissage stables.
Dans notre
article, «Traduction automatique durable avec double saisie contradictoire», nous proposons une approche qui utilise les exemples contradictoires générés pour améliorer la stabilité des modèles de traduction automatique pour les petits changements de saisie. Nous enseignons un modèle NMP stable pour surmonter les exemples compétitifs générés en tenant compte des connaissances sur ce modèle et afin de fausser ses prédictions. Nous montrons que cette approche améliore l'efficacité du modèle NMP dans les tests standard.
Formation sur modèle avec AdvGen
Un modèle NMP idéal devrait générer des traductions similaires pour différentes entrées présentant de légères différences. L'idée de notre approche est d'interférer avec le modèle de traduction en utilisant une contribution compétitive dans l'espoir d'augmenter sa stabilité. Cela se fait à l'aide de l'algorithme Adversarial Generation (AdvGen), qui génère des exemples compétitifs valides qui interfèrent avec le modèle, puis les introduisent dans le modèle pour la formation. Bien que cette méthode soit inspirée de l'idée de réseaux compétitifs génératifs (GSS), elle n'utilise pas un réseau discriminant, mais utilise simplement un exemple compétitif en formation, en fait, en diversifiant et en élargissant l'ensemble de formation.
La première étape consiste à outrager les données avec AdvGen. Nous commençons par utiliser un transformateur pour calculer la perte d'un transfert en fonction de l'offre entrante d'origine, de l'offre d'entrée cible et de l'offre de sortie cible. AdvGen sélectionne ensuite au hasard les mots de la phrase d'origine, en supposant leur distribution uniforme. Chaque mot a une liste correspondante de mots similaires, c'est-à-dire candidats de substitution. À partir de là, AdvGen sélectionne le mot le plus susceptible d'entraîner des erreurs dans la sortie du transformateur. Ensuite, cette phrase d'adversaire générée est renvoyée au transformateur, en commençant l'étape de défense.
 Tout d'abord, le modèle du transformateur est appliqué à la phrase entrante (en bas à gauche), puis la perte de translation est calculée avec la phrase de sortie cible (en haut en haut) et la phrase d'entrée cible (en milieu à droite, en commençant par «<sos>»). AdvGen accepte ensuite la phrase d'origine, la distribution de sélection de mots, les candidats de mots et la perte de traduction en entrée, et crée un exemple de code source contradictoire.
Tout d'abord, le modèle du transformateur est appliqué à la phrase entrante (en bas à gauche), puis la perte de translation est calculée avec la phrase de sortie cible (en haut en haut) et la phrase d'entrée cible (en milieu à droite, en commençant par «<sos>»). AdvGen accepte ensuite la phrase d'origine, la distribution de sélection de mots, les candidats de mots et la perte de traduction en entrée, et crée un exemple de code source contradictoire.Au stade de la défense, le code source contradictoire est renvoyé au transformateur. La perte de traduction est à nouveau comptabilisée, mais cette fois en utilisant la source d'entrée litigieuse. En utilisant la même méthode que précédemment, AdvGen utilise une phrase entrante ciblée, une distribution de sélection de mots calculée à partir de la matrice d'attention, des candidats au remplacement de mots et une perte de traduction pour créer un exemple de code source litigieux.
 Au stade de la défense, le code source contradictoire devient l'entrée du transformateur et les pertes de translation sont calculées. En utilisant la même méthode que précédemment, AdvGen crée un exemple de code source litigieux basé sur l'entrée cible.
Au stade de la défense, le code source contradictoire devient l'entrée du transformateur et les pertes de translation sont calculées. En utilisant la même méthode que précédemment, AdvGen crée un exemple de code source litigieux basé sur l'entrée cible.Enfin, la peine accusatoire est réinjectée dans le transformateur et la perte de stabilité est calculée sur la base de l'exemple source accusatoire, de l'exemple d'entrée cible accusatoire et de la peine cible. Si l'intervention dans le texte a conduit à des pertes importantes, elles sont minimisées pour que lorsque les modèles rencontrent des perturbations similaires, elle ne répète pas la même erreur. En revanche, si la perturbation entraîne de petites pertes, rien ne se passe, ce qui suggère que le modèle est déjà capable de faire face à de telles perturbations.
Performance du modèle
Nous démontrons l'efficacité de notre approche en l'appliquant aux tests de traduction standard du chinois vers l'anglais et de l'anglais vers l'allemand. Nous obtenons une amélioration significative de la traduction de 2,8 et 1,6 points BLEU, respectivement, par rapport au modèle concurrent du transformateur, et obtenons un nouveau record de qualité de traduction.
 Comparaison des modèles de transformateurs sur des tests standard
Comparaison des modèles de transformateurs sur des tests standardEnsuite, nous évaluons les performances de notre modèle sur un ensemble de données bruyant en utilisant une procédure similaire à celle décrite pour AdvGen. Nous prenons des données d'entrée pures, par exemple, celles utilisées dans les tests standard des traducteurs, et sélectionnons au hasard les mots que nous remplaçons par des mots similaires. Nous constatons que notre modèle présente une stabilité améliorée par rapport à d'autres modèles récents.
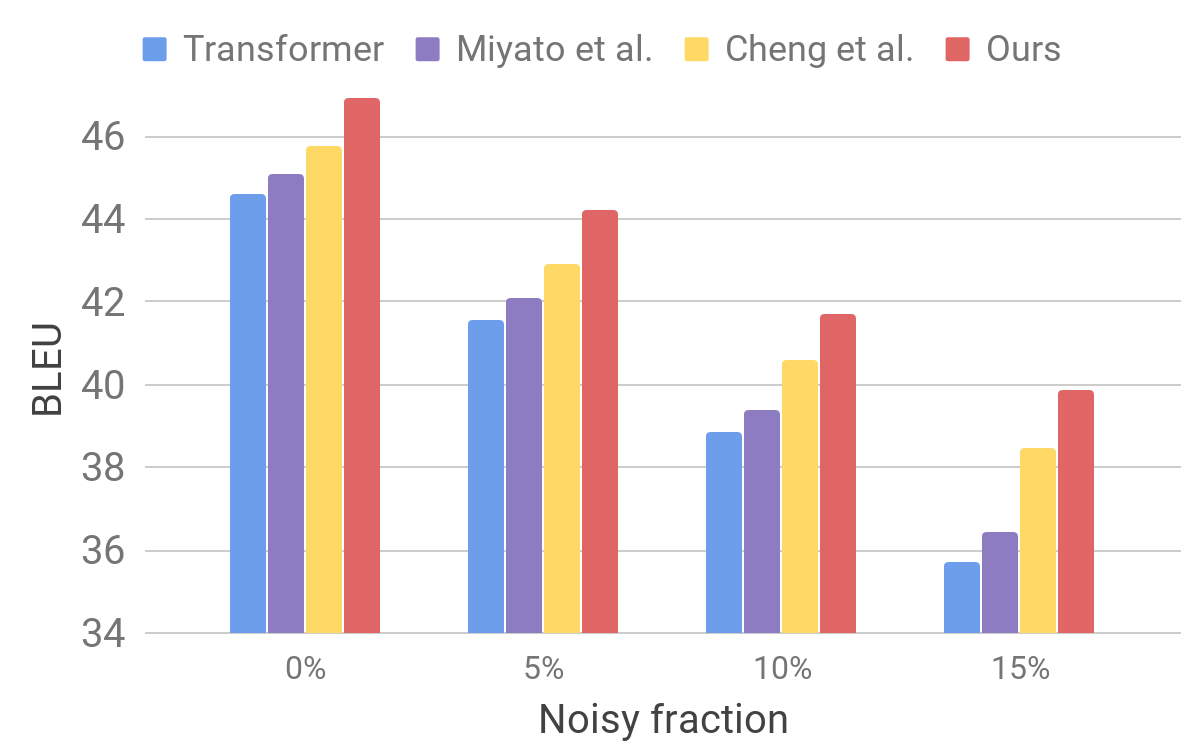 Comparaison du transformateur et d'autres modèles sur des données d'entrée artificiellement bruyantes
Comparaison du transformateur et d'autres modèles sur des données d'entrée artificiellement bruyantesCes résultats montrent que nos méthodes sont capables de surmonter les petites perturbations survenant dans la phrase entrante et d'améliorer l'efficacité de la généralisation. Il est en avance sur les modèles de traduction concurrents et atteint une efficacité de traduction record sur des tests standard. Nous espérons que notre modèle de traducteur deviendra une base stable pour améliorer les résultats de la résolution de bon nombre des problèmes suivants, en particulier ceux qui sont sensibles ou intolérants aux textes d'entrée imparfaits.