Bien que les réseaux de neurones aient commencé à être utilisés pour la synthèse de la parole il n'y a pas si longtemps ( par exemple ), ils ont déjà réussi à dépasser les approches classiques et chaque année, ils font l'expérience de tâches de plus en plus récentes.
Par exemple, il y a quelques mois, la mise en œuvre de la synthèse vocale en temps réel-Voice-Cloning est apparue. Essayons de comprendre de quoi il s'agit et réalisons notre modèle de phonème multilingue (russe-anglais).
Immeuble
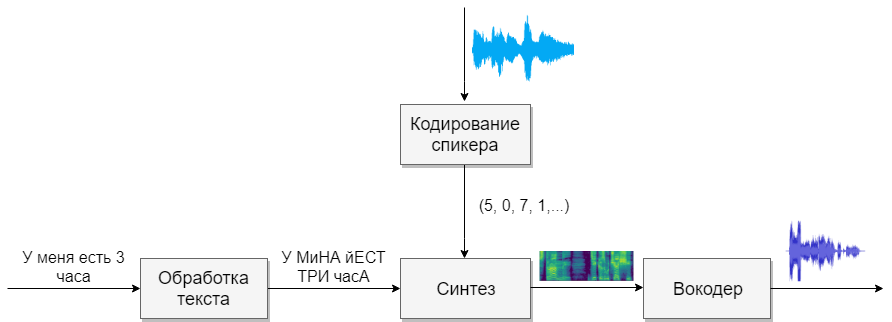
Notre modèle comprendra quatre réseaux de neurones. Le premier convertira le texte en phonèmes (g2p), le second convertira la parole que nous voulons cloner en un vecteur de signes (nombres). Le troisième synthétisera les spectrogrammes Mel sur la base des sorties des deux premiers. Et enfin, le quatrième recevra le son des spectrogrammes.
Jeux de données
Ce modèle a besoin de beaucoup de discours. Voici les bases qui vous aideront à cet égard.
Traitement de texte
La première tâche sera le traitement de texte. Imaginez le texte sous la forme dans laquelle il sera davantage exprimé. Nous représenterons les nombres en mots et ouvrirons des abréviations. En savoir plus dans l' article sur la synthèse . C'est une tâche difficile, alors supposons que nous avons déjà traité du texte (dans les bases de données ci-dessus, il a été traité).
La prochaine question à se poser est de savoir s'il faut utiliser l'enregistrement graphème ou phonème. Pour une voix monophonique et monolingue, un modèle de lettre convient également. Si vous souhaitez travailler avec un modèle multi-voix multi-voix, je vous conseille d'utiliser la transcription (Google aussi ).
G2p
Pour la langue russe, il existe une implémentation appelée russian_g2p . Il est construit sur les règles de la langue russe et fait bien face à la tâche, mais présente des inconvénients. Tous les mots ne soulignent pas et ne conviennent pas non plus à un modèle multilingue. Par conséquent, prenez le dictionnaire créé pour elle, ajoutez le dictionnaire pour la langue anglaise et alimentez le réseau neuronal (par exemple, 1 , 2 )
Avant de former le réseau, il convient de considérer les sons de différentes langues qui semblent similaires, et vous pouvez sélectionner un caractère pour eux, et pour lequel cela est impossible. Plus il y a de sons, plus le modèle est difficile à apprendre, et s'il y en a trop peu, le modèle aura un accent. N'oubliez pas de souligner les caractères individuels avec des voyelles accentuées. Pour la langue anglaise, le stress secondaire joue un petit rôle, et je ne le distinguerais pas.
Codage des haut-parleurs
Le réseau est similaire à la tâche d'identifier un utilisateur par la voix. En sortie, différents utilisateurs obtiennent différents vecteurs avec des nombres. Je suggère d'utiliser l'implémentation de CorentinJ elle-même, qui est basée sur l' article . Le modèle est un LSTM à trois couches avec 768 nœuds, suivi d'une couche entièrement connectée de 256 neurones, donnant un vecteur de 256 nombres.
L'expérience a montré qu'un réseau formé en anglais parle bien le russe. Cela simplifie considérablement la vie, car la formation nécessite beaucoup de données. Je recommande de prendre un modèle déjà formé et de se recycler en anglais à partir de VoxCeleb et LibriSpeech, ainsi que de tout le discours russe que vous trouvez. L'encodeur n'a pas besoin d'annotation textuelle des fragments de parole.
La formation
- Exécutez
python encoder_preprocess.py <datasets_root> pour traiter les données - Exécutez "visdom" dans un terminal séparé.
- Exécutez
python encoder_train.py my_run <datasets_root> pour entraîner l'encodeur
La synthèse
Passons à la synthèse. Les modèles que je connais n'obtiennent pas de son directement du texte, car c'est difficile (trop de données). Premièrement, le texte produit un son sous forme spectrale, et alors seulement le quatrième réseau se traduira par une voix familière. Par conséquent, nous comprenons d'abord comment la forme spectrale est associée à la voix. Il est plus facile de comprendre le problème inverse de la façon d'obtenir un spectrogramme à partir du son.
Le son est divisé en segments de 25 ms par incréments de 10 ms (valeur par défaut dans la plupart des modèles). Ensuite, en utilisant la transformée de Fourier pour chaque pièce, le spectre est calculé (oscillations harmoniques, dont la somme donne le signal d'origine) et présenté sous la forme d'un graphique, où la bande verticale est le spectre d'un segment (en fréquence), et à l'horizontale - une séquence de segments (dans le temps). Ce graphique est appelé un spectrogramme. Si la fréquence est codée de façon non linéaire (les fréquences inférieures sont meilleures que les fréquences supérieures), alors l'échelle verticale changera (nécessaire pour réduire les données), alors ce graphique est appelé le spectrogramme Mel. C'est ainsi que fonctionne l'audition humaine, que nous entendons une légère déviation aux basses fréquences mieux qu'aux fréquences supérieures, donc la qualité du son ne souffrira pas
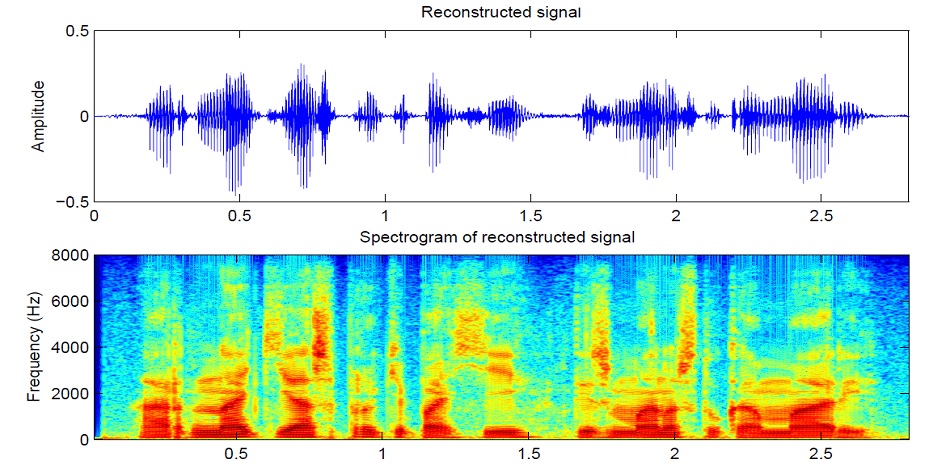
Il existe plusieurs bonnes implémentations de synthèse de spectrogrammes telles que Tacotron 2 et Deepvoice 3 . Chacun de ces modèles a ses propres implémentations, par exemple 1 , 2 , 3 , 4 . Nous utiliserons (comme CorentinJ) le modèle Tacotron de Rayhane-mamah.
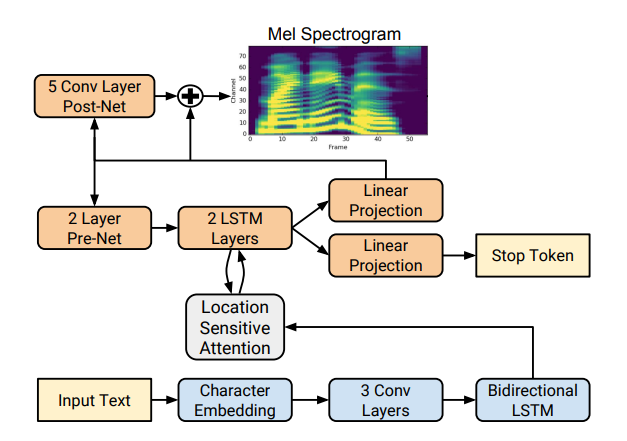
Tacotron est basé sur le réseau seq2seq avec un mécanisme d'attention. Lisez les détails dans l' article .
La formation
N'oubliez pas d'éditer utils / symboles.py si vous synthétisez non seulement la parole anglaise, hparams.p, mais aussi preprocess.py.
La synthèse nécessite beaucoup de son clair et bien marqué provenant de différents haut-parleurs. Ici, une langue étrangère n'aidera pas.
- Exécutez
python synthesizer_preprocess_audio.py <datasets_root> pour créer un son et des spectrogrammes traités - Exécutez
python synthesizer_preprocess_embeds.py <datasets_root> pour encoder le son (obtenir les signes d'une voix) - Exécutez
python synthesizer_train.py my_run <datasets_root> pour entraîner le synthétiseur
Vocoder
Maintenant, il ne reste plus qu'à convertir les spectrogrammes en sons. Pour cela, le dernier réseau est le vocodeur. La question se pose, si les spectrogrammes sont obtenus à partir du son en utilisant la transformée de Fourier, est-il possible d'obtenir à nouveau le son en utilisant la transformation inverse? La réponse est oui et non. Les oscillations harmoniques qui composent le signal d'origine contiennent à la fois l'amplitude et la phase, et nos spectrogrammes contiennent uniquement des informations sur l'amplitude (dans le but de réduire les paramètres et de travailler avec les spectrogrammes), donc si nous faisons la transformée de Fourier inverse, nous obtenons un mauvais son.
Pour résoudre ce problème, ils ont inventé un algorithme Griffin-Lim rapide. Il fait la transformée de Fourier inverse du spectrogramme, obtenant un "mauvais" son. Il effectue ensuite une conversion directe de ce son et reçoit un spectre qui contient déjà un peu d'informations sur la phase, et l'amplitude ne change pas au cours du processus. Ensuite, la transformation inverse est reprise et un son plus net est obtenu. Malheureusement, la qualité de la parole générée par un tel algorithme laisse beaucoup à désirer.
Il a été remplacé par des vocodeurs neuronaux tels que WaveNet , WaveRNN , WaveGlow et autres. CorentinJ a utilisé le modèle WaveRNN de fatchord

Pour le prétraitement des données, deux approches sont utilisées. Soit obtenir des spectrogrammes à partir du son (en utilisant la transformée de Fourier), ou du texte (en utilisant le modèle de synthèse). Google recommande une deuxième approche.
La formation
- Exécutez
python vocoder_preprocess.py <datasets_root> pour synthétiser les spectrogrammes - Exécutez
python vocoder_train.py <datasets_root> pour vocoder
Total
Nous avons obtenu un modèle de synthèse vocale multilingue qui peut cloner une voix.
Exécutez la boîte à outils: python demo_toolbox.py -d <datasets_root>
Des exemples peuvent être entendus ici
Conseils et conclusions
- Besoin de beaucoup de données (> 1000 votes,> 1000 heures)
- La vitesse de fonctionnement n'est comparable au temps réel que dans la synthèse d'au moins 4 phrases
- Pour l'encodeur, utilisez le modèle pré-formé pour la langue anglaise, un peu de recyclage. Elle va bien
- Un synthétiseur formé sur des données "propres" fonctionne mieux, mais clone moins bien qu'un synthétiseur formé sur un volume plus important, mais des données sales
- Le modèle ne fonctionne bien que sur les données sur lesquelles j'ai étudié
Vous pouvez synthétiser votre voix en ligne en utilisant colab , ou voir mon implémentation sur github et télécharger mes poids .